Check-N-Run: a Checkpointing System for Training Deep Learning Recommendation Models | NSDI‘ 22
分布式机器学习论文分享 | Check-N-Run: a Checkpointing System for Training Deep Learning Recommendation Models | NSDI’ 22
这次和大家分享一篇刚刚放出的论文,来自于2022年NSDI (USENIX Symposium on Networked Systems Design and Implementation, CCF A类) 。该论文由Facebook主导,首次(据作者所述)针对大规模工业训练深度学习推荐系统的场景提出了一个检查点系统,在不损害测试准确率的情况下节省存储空间、存储带宽和网络带宽。该系统具有增量化和动态量化的设计,在大规模真实工业负载的实验中,该系统可以减少6-17x 带宽和__2.5-8x__ 存储空间。

作者简介
作者都是来自Facebook的,其中通讯作者Murali Annavaram还是USC (University of Southern California) 的教授。一作是Assaf Eisenman,近几年常在NSDI收录名单上看到他,现在他去了斯坦佛大学。
预备知识
为了使所有读者更好地理解论文的动机和核心设计,本节我们简要介绍一些有关推荐模型、检查点和检查点系统的预备知识。
推荐模型
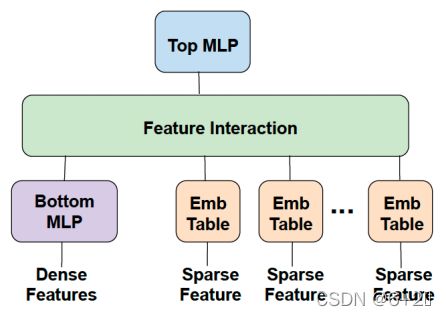
推荐系统根据用户过去的行为以及物品之间的联系等信息,为用户推荐更适合用户的物品。推荐系统的核心是训练大规模的推荐模型(可达TB级别),一般需要训练几天。值得一提的是,训练深度的推荐模型占用了Facebook工业集群超过80%的推理周期和超过50%的训练周期。
输入到推荐模型的原始数据包括稠密的特征信息(例如用户常购买的物品的信息)和海量稀疏的特征信息(例如用户不常购买的物品的信息),稠密的数据适用于一般的机器学习模型(例如多层感知机MLP),但如果直接用稀疏的特征数据训练机器学习模型,将吃力不讨好。因此对于海量的稀疏特征信息,推荐模型常使用embedding层,将高维稀疏的特征数据映射到低维空间中,得到稠密的表征信息。
检查点
检查点类似于电子游戏里的存档点,在机器学习中指的是某个时间点对训练过程的一次快照,保存在非易失存储中,主要包括模型各层的参数、优化器的状态、读取器的状态以及一些相关的指标(例如训练损失值和验证集准确率)。在真实工业场景下,检查点可用于快速从故障中恢复训练,以避免重新训练,浪费大量的资源。检查点还可用于在线训练(在训练的同时为用户提供推理服务)和迁移学习。
解耦的检查点系统
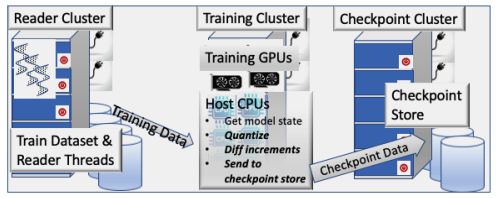
作者搭的检查点系统有多个训练集群,每个训练集群包括16个节点,每个节点有8个GPU和多核CPU,为了支持高性能训练,作者将训练集群解耦,集群里的GPU用来训练多个并行的复杂工业作业,CPU使用多进程并行处理多个模型快照,这种解耦式的训练集群创建一个检查点的时间几乎对训练速度没有影响(按照作者的实验,创建一个检查点只需要不到0.4%的训练时间)。同时,作者将读取数据和写入检查点到非易失存储的过程与训练过程解耦,将读取器和检查点存储在不同的集群中,进一步提高了训练的性能。
研究动机
训练失败
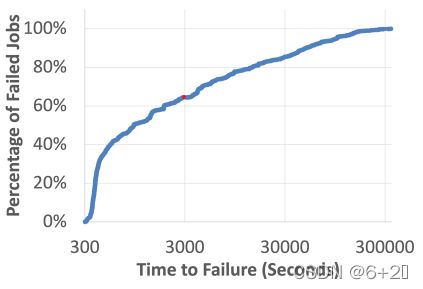
由于在Facebook的检查点系统中读取集群、训练集群和检查点集群是分散的,很难保证训练过程中的每一个步骤不会出错。作者统计了包括21个训练集群的系统中,一个月的训练失败作业的训练失败时间(开始训练至训练失败的时间)。 由图4所示,有效的检查点系统是训练正常进行的关键,尤其是对于长期运行的训练作业,如果缺少有效的检查点,将会花费大量的时间重新训练,甚至训练任务可能永远不会完成。
愈加庞大的推荐模型
作者发现过去两年Facebook训练的推荐模型大小增加了3×以上,越大的模型将会导致训练在集群中更分散,训练失败的概率会更高。同时不断增大的TB级别的推荐模型会导致检查点面临存储容量和带宽的瓶颈。
模型部分更新
作者观察Facebook最大的推荐模型在给定的训练时间内,只有一小部分的embedding向量被更新。图5显示了随训练样本数量的增加,模型更新部分占总模型大小的变化函数。从三个不同的初始点开始,该变化函数呈现相同的趋势。图六显示在给定的时间内,模型更新大小几乎不变。以上数据都表明,每次迭代中只有部分模型(部分embedding向量)更新。


核心设计
Check-N-Run是一个分布式检查点系统,支持对推荐模型进行大规模长期高性能的训练。图7展示了该系统各组件及其功能,核心为训练集群中的CPU上运行的组件。检查点的创建进程包括三个步骤(1)创建训练状态的内存快照(2)构建一个优化的检查点(3)将检查点写入存储,通常是检查点集群中的存储。这三个步骤都交由训练集训中的CPU来完成,GPU除了用于加速训练只用于检测哪些embedding向量变化了,这种解耦式设计尽可能减小了检查点对训练速度的影响。接下来我们介绍一下论文的核心设计,如何优化检查点的构建过程,即上述的第二步。

增量化
由于推荐模型训练过程中每次迭代只有部分模型更新,因此作者引入了增量检查点,并提出了3种类型的增量检查点,分别是One-Shot Incremental Checkpoint,Consecutive Incremental Checkpoint和Intermittent Incremental Checkpoint。
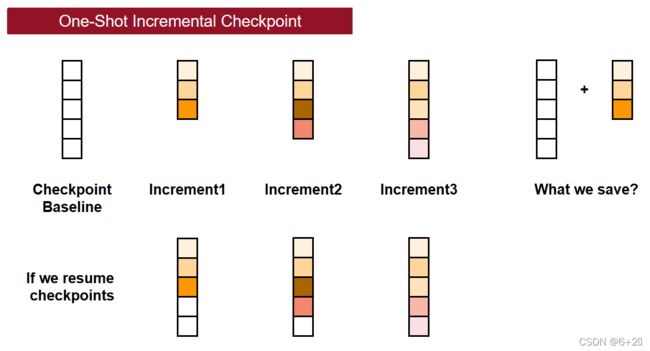


第一种One-Shot检查点,第一次记录一次包括所有embedding向量的完整基线,在这之后每个增量检查点只记录自基线以来所有修改的部分。如果需要从检查点恢复至训练状态,只需要同时读取基线和相应的单个时间点的增量检查点。
第二种Consecutive检查点,也记录一次完整基线,在这之后每个增量检查点只记录自上个检查点以来修改的部分。这种增量检查点一次只需要记录较少的部分,但如果需要从检查点恢复,需要同时读取基线以及自基线以来所有的增量检查点。因此这种类型的增量检查点实际更耗费存储空间,因为不同增量检查点很可能具有相同部分的副本,而任一增量检查点都不能删除。但Consecutive增量检查点适用于online训练。
第三种Intermittent增量检查点是第一种的改进版本,也是这篇论文所采取的设计。其改进的地方在于,一段时间后,系统会更新新的包括所有embedding向量的完整基线,这样后续的增量检查点都只需要维护较小的增量视图。作者提出了一个基于过去信息的增量大小预测器,当过去一段时间的增量累积量≈预测的未来一段时间的增量累积量时,Check-N-Run会创建新的完整基线,而不是创建增量检查点。
动态量化
量化(Quantization)原是信号处理的一种方法,在机器学习中被认为是一种有效的模型压缩方法。若把量化应用于创建检查点(本文讨论的是对embedding向量进行量化,即量化粒度为向量),可大幅度减小检查点的大小,从而节省存储空间和带宽,然而使用被量化后的检查点恢复至训练状态,可能会损失训练的精度。
作者致力于将由于量化导致的精度衰减限制在工业允许范围内(<0.01%),即几乎不损失精度。作者讨论了均匀量化和非均匀量化,认为非对称的均匀量化在工业上最可行,并认为量化所导致的精度损失主要来源于xmin与xmax的设置,因此作者提出了一种自适应的贪心搜索算法来高效地搜索次佳的设置。


实验结果
实验所采用的训练集群类似于Nvidia HGX,详细信息可见https://images.nvidia.com/content/pdf/hgx2-datasheet.pdf。
由于读取增量检查点时实际上读取的是完整的模型,因此Check-N-Run所造成的精度损失只会来源于量化,论文内的 Figure 14 说明梯度衰减与量化的幅度和消耗检查点的次数有关,Check-N-Run使用一种自适应的方法根据消耗检查点的次数寻找量化的幅度,使得精度衰减可以一直维持在<0.01%的范围内。
论文内的 Figure 15 和 Figure 16 分别说明了Intermittent增量检查点在带宽和存储空间上的优势。其中 Figure 15 第8个time interval内更新了新的完整基线,因此代表Intermittent增量检查点的红色直方突出来了。
论文内的 Figure 17 则说明了Check-N-Run的总体作用,即我们开头所讲的减少6-17x 带宽和2.5-8x 存储空间。



讨论
减少分布式系统中各组件的耦合是提高性能的关键。
要维护分布式系统的一致性,应确保操作的原子性。
深度学习模型确实是增量更新的,每次迭代只更新一部分。若我们能捕捉每次部分更新的规律,就会提高我们对深度学习模型的理解。