MIT6.828学习之Lab4_Part A: Multiprocessor Support and Cooperative Multitasking
代码运行流程简述
-
进入mp_init(),通过mpconfig()找到
MP configuration table与MP,根据MP configuration table了解cpu的总数、它们的APIC IDs和LAPIC单元的MMIO地址等配置信息 -
进入lapic_init(),根据MP配置表找到的lapic的
MMIO地址,完成lapic的初始化操作(感觉这里完成的是BSP的lapic的初始化) -
BSP申请大内核锁,然后进入
boot_aps()去启动其他CPU。在boot_aps中,找到AP的入口地址,以及AP的初始栈地址。 -
进入lapic_startap(),将
STARTUP IPIs(处理器之间中断)以及一个初始CS:IP地址即AP入口地址发送到相应AP的LAPIC单元 -
进入
mpentry.S完成相应CPU的寄存器初始化,启动分页机制,初始化栈,并调用mp_main -
进入
mp_main。完成当前CPU的lapic、用户环境、trap的初始化,就算该CPU启动完成。然后想通过sched_yield()调度一个进程而申请大内核锁,但此时BSP还保持着大内核锁,所以其他CPU都pause等待。 -
BSP启动所有CPU后,
继续执行i386_init中的代码,开始创建环境,然后执行轮转调度程序sched_yield(),从刚创建的进程中调度一个进程执行,并释放大内核锁 -
BSP释放大内核锁后,其他pause的CPU就
有一个可以申请到大内核锁,调度一个进程执行,其他接着pause。等该CPU在env_run中释放大内核锁后就又可以有一个CPU申请到大内核锁,就这样一个一个开始执行进程。 -
当CPU没有环境可执行时,就会进入
sched_halted()里被halted,当最后那个CPU进入这个函数时,不会被halted,而是开始执行monitor。
实验过程
在本实验室的第一部分中,您将首先将JOS扩展到在多处理器系统(multiprocessor system)上运行,然后实现一些新的JOS内核系统调用,以允许用户级环境创建额外的新环境。您还将实现协作循环调度(cooperative round-robin scheduling),允许内核在当前环境自愿放弃CPU(or exits)时从一个环境切换到另一个环境。在稍后的Part C中,您将实现抢占式调度,它允许内核在经过一段时间后从环境中重新控制CPU,即使环境不合作。
Multiprocessor Support
我们将使JOS支持“对称多处理机”(symmetric multiprocessing, SMP),这是一种多处理器模型,其中所有cpu都具有对系统资源(如内存和I/O总线)的等效访问权。虽然SMP中的所有cpu在功能上都是相同的,但是在引导过程中它们可以分为两种类型:引导处理器(bootstrap processor, BSP)负责初始化系统和引导启动操作系统;只有在操作系统启动并运行之后,BSP才会激活应用程序处理器(the application processors, APs)。哪个处理器是BSP由硬件和BIOS决定。到目前为止,所有现有的JOS代码都在BSP上运行。
在SMP系统中,每个CPU都有一个相应的local APIC (LAPIC) unit(本地高级中断控制器单元)。LAPIC单元负责在整个系统中传输中断。LAPIC还为其连接的CPU提供唯一的标识符。在本实验室中,我们利用了LAPIC单元的以下基本功能(in kern/lapic.c):
- 读取LAPIC标识符(
APIC ID)来判断我们的代码当前运行在哪个CPU上(参见cpunum())。 - 将
STARTUP处理器间中断( interprocessor interrupt, IPI)从BSP发送到APs,以打开其他cpu(参见lapic_startap())。 - 在Part C,我们编写LAPIC的内置计时器来触发
时钟中断,以支持抢占式的多任务处理(参见lapic_init())。
一个处理器使用memory-mapped I/O (MMIO)访问它的LAPIC。在MMIO中,物理内存的一部分与一些I/O设备寄存器是硬连线的,所以用于访问内存的load/store指令也可以用于访问设备寄存器。你已经在物理地址0xA0000(我们用这个地址去写入VGA display buffer)上见到一个I/O hole了。LAPIC放在从物理地址0xFE000000(离4GB仅差32MB)开始的一个hole中,所以对于我们去使用在KERNBASE处常用的直接映射,这地址太高了。JOS虚拟地址映射在MMIOBASE上留下了一个4MB的间隔,让我们有地方去映射像这样的设备。因为后面的labs引入了更多的MMIO区域,你会写一个简单函数从这个区域中分配空间并且映射设备内存到它。
Exercise 1. 在kern/pmap.c中实现mmio_map_region。要了解如何使用它,请查看kern/lapic.c中lapic_init的开头。在运行mmio_map_region测试之前,您还必须做完下一个练习。
static uintptr_t base = MMIOBASE;
uintptr_t oldbase=base;
int len;
if(size % PGSIZE != 0)
len = size / PGSIZE +1;
else
len = size / PGSIZE;
if(base + len * PGSIZE > MMIOLIM || base + len * PGSIZE < base)
panic("this reservation have overflowed MMIOLIM!\n");
// 老是忘记以前的函数,真是醉了
boot_map_region(kern_pgdir,base,ROUNDUP(size, PGSIZE),pa, PTE_PCD|PTE_PWT|PTE_W);
base += ROUNDUP(size, PGSIZE); //just like nextfree in boot_alloc!
return (void *)oldbase;
好吧,我知道这样写得有点蠢,但是好歹是对的,而且是自己写的,所以,不改了。。。
Application Processor Bootstrap
在启动APs之前,BSP应该首先收集关于多处理器系统的信息,例如cpu的总数、它们的APIC IDs和LAPIC单元的MMIO地址。kern/mpconfig.c中的mp_init()函数通过读取驻留在BIOS内存区域中的MP configuration table来检索此信息。
boot_aps()函数(在kern/init.c中)驱动AP引导进程。APs以real mode启动,非常类似于the bootloader在boot/boot.S中启动的方式。因此,boot_aps()将AP entry code(kern/mpentry.S)复制到在实模式中可寻址(addressable)的内存位置。与引导加载程序不同,我们可以控制AP将从何处开始执行代码;我们将entry code复制到0x7000 (MPENTRY_PADDR),但是任何未使用的、页面对齐的低于640KB(0xA0000以下)的物理地址都可以。
然后,boot_aps()一个接一个地激活APs,通过将STARTUP IPIs(处理器之间中断)发送到相应AP的LAPIC单元,以及一个初始CS:IP地址,AP应该从这个地址开始运行它的入口代码(在我们的示例中是MPENTRY_PADDR)。kern/mpentry.S中的入口代码与boot/boot.S里的非常相似。经过一些简单的设置之后,它将AP置于启用分页(paging enabled)的保护模式,然后调用C setup routine mp_main()(也在kern/init.c中)。boot_aps()等待AP在其struct CpuInfo的cpu_status字段中发出CPU_STARTED标志的信号,然后再唤醒下一个AP。
Exercise 2. 在kern/init.c中读取boot_aps()和mp_main()以及kern/mpentry.S中的汇编代码。确保您理解APs引导期间的控制流传输(
control flow transfer)。然后修改kern/pmap.c中实现的page_init(),以避免将MPENTRY_PADDR页面添加到空闲列表中,这样我们就可以安全地复制并运行该物理地址上的AP引导代码(AP bootstrap code)。您的代码应该通过更新后的check_page_free_list()测试(但是可能无法通过更新后的check_kern_pgdir()测试,我们将很快对其进行修复)。
else if(i*PGSIZE == MPENTRY_PADDR){
pages[i].pp_ref = 1;
}
AP entry code是从[mpentry_start, mpentry_end]放到物理地址MPENTRY_PADDR(0x7000)处的,大小我测了一下,mpentry_end - mpentry_start是小于4KB的,一页物理页就能装下:
code = KADDR(MPENTRY_PADDR);
memmove(code, mpentry_start, mpentry_end - mpentry_start);
cprintf("mpentry_start:%08x, mpentry_end:%08x\n",mpentry_start, mpentry_end);
//结果是mpentry_start:f0105144, mpentry_end:f01051be
"任何未使用的、页面对齐的低于640KB的物理地址都可以"这句话误导了我,我还以为低于640KB的物理页都得设为不空闲,原来是都可以放,但是本实验中确定放到0x7000处。
Question
1.比较kern/mpentry.S与boot/boot.S。记住kern/mpentry.S 被编译并链接到KERNBASE之上去运行,就像内核中的其他一样,宏MPBOOTPHYS的目的是什么呢?为什么它在kern/mpentry.S中很重要,但是在boot/boot.S不那么重要?换句话说,如果它在kern/mpentry.S中被忽略会引起什么错误呢?
提示:回顾我们在lab1中讨论的the link address和the load address的不同之处
答:(猜的)可以看到,在这里用到了宏MPBOOTPHYS。入口代码被放在物理地址MPENTRY_PADDR,这是the load address,但是由于BSP已经开启分页模式了,所以这里入口代码的the link address却是在KERNBASE之上,所以我们直接用宏MPBOOTPHYS来计算入口代码的绝对地址。
# - it uses MPBOOTPHYS to calculate absolute addresses(计算绝对地址) of its
# symbols(符号), rather than relying on the linker(链接器) to fill them
# Jump to next instruction, but in 32-bit code segment.
# Switches processor into 32-bit mode.
ljmpl $(PROT_MODE_CSEG), $(MPBOOTPHYS(start32))
Per-CPU State and Initialization
当写一个多处理器OS,区分每个处理器私有的per-CPU state和整个系统共享的global state是很重要的。kern/cpu.h定义了大部分per-CPU状态,包括struct CpuInfo,里面存着per-CPU变量。cpunum()总是返回调用它的CPU的ID,可以被用作数组(如cpus[])的索引值。或者,宏thiscpu是当前CPU的struct CpuInfo的简写。
这里是你应该熟悉的per-CPU state:
-
Per-CPU kernel stack
因为多个CPUs可以同时陷入到内核,每个处理器需要一个单独的内核堆栈,以防止它们相互干扰执行。数组percpu_kstack [NCPU][KSTKSIZE]为NCPU的内核堆栈保留空间。
在Lab2中,您映射了bootstack称为BSP内核堆栈的物理内存,该内核堆栈位于KSTACKTOP之下。相似的,在这个lab中,你会映射每个CPU的内核栈到这个区域,并使用保护页面(guard pages)作为它们之间的缓冲区(buffer)。CPU 0的堆栈仍然会从KSTACKTOP向下增长;CPU 1的堆栈将在CPU 0的堆栈底部以下启动KSTKGAP字节,以此类推。inc/memlayout.h显示了映射布局。 -
Per-CPU TSS and TSS descriptor
还需要per-CPU的任务状态段(task state segment,TSS),以便指定每个CPU的内核栈位于何处。CPU i的TSS存在cpus[i].cpu_ts中,相应的TSS描述符定义在GDT条目的gdt[(GD_TSS0 >> 3) + i]中。定义在kern/trap.c中的全局ts变量将不再有用 -
Per-CPU current environment pointer
因为每个CPU可以同时运行不同用户程序,我们可以重新定义符号curenv成cpus[cpunum()].cpu_env(or thiscpu->cpu_env),它将指向当前CPU上正在执行的environment。 -
Per-CPU system registers
所有寄存器,包括系统寄存器,都是CPU私有的。因此,初始化这些寄存器的指令,例如lcr3(), ltr(), lgdt(), lidt(), etc.,都必须在每个CPU上执行一次。函数env_init_percpu()和trap_init_percpu()就是为这个定义的。
除了这些,如果在之前的labs里,在你解决challenge问题时,你已经添加了任何额外的per-CPU state或者执行了任何附加的CPU-specific初始化(比如,在CPU寄存器中设置新的bits),确保复制它们到这里的每个CPU中
Exercise 3 修改在kern/pmap.c中的
mem_init_mp()去映射从KSTACKTOP开始的per-CPU栈,如inc/memlayout.h所示。每个stack的大小都是KSTKSIZE字节加未映射保护页(guard pages)的KSTKGAP字节。你的代码应该通过新的检测check_kern_pgdir()。
for(int i=0; i<NCPU; i++){
uint32_t kstacktop_i = KSTACKTOP - i*(KSTKSIZE + KSTKGAP);
//PADDR(&percpu_kstacks[i])这里确实不太会写,boot_map_region也忘了。。。
boot_map_region(kern_pgdir,kstacktop_i-KSTKSIZE,KSTKSIZE,PADDR(&percpu_kstacks[i]),PTE_W);
}
Exercise 4 在kern/trap.c中的
trap_init_percpu()中的代码初始化BSP的TSS和TSS描述符。它在Lab3中是这么做的,但是当运行在其他CPUs上时是不正确的。改变代码以至于它可以工作在所有的CPUs上。(注意:你的新代码不应该再使用全局ts变量)
void trap_init_percpu(void){
int i = cpunum();
thiscpu->cpu_ts.ts_esp0 = KSTACKTOP - i*(KSTKSIZE + KSTKGAP);
thiscpu->cpu_ts.ts_ss0 = GD_KD;
thiscpu->cpu_ts.ts_iomb = sizeof(struct Taskstate);//防止未经授权的环境执行IO(0不是正确的值!)
// Initialize the TSS slot of the gdt.
// 为什么这里还藏着一个ts啊,啊啊啊啊!
gdt[(GD_TSS0 >> 3) + i] = SEG16(STS_T32A, (uint32_t) (&thiscpu->cpu_ts),
sizeof(struct Taskstate) - 1, 0);
gdt[(GD_TSS0 >> 3) + i].sd_s = 0;
// Load the TSS selector (like other segment selectors, the
// bottom three bits are special; we leave them 0)
ltr(GD_TSS0 + (i<<3)); //最后3bits是特殊的,举一反三
// Load the IDT
lidt(&idt_pd);
}
有一个ts没看见就没改,结果在运行用户程序yield.c时通过int $30(系统调用)陷入内核态时一直在triple fault,都快要绝望了,唉,真是来不得半点马虎。
当完成上述exercises时,在QEMU运行JOS用4 CPUs使用 make qemu CPUS=4 (or make qemu-nox CPUS=4),你会见到下面这样的输出:
Physical memory: 66556K available, base = 640K, extended = 65532K
check_page_alloc() succeeded!
check_page() succeeded!
check_kern_pgdir() succeeded!
check_page_installed_pgdir() succeeded!
SMP: CPU 0 found 4 CPU(s)
enabled interrupts: 1 2
SMP: CPU 1 starting
SMP: CPU 2 starting
SMP: CPU 3 starting
Locking
我们当前代码在mp_main()中初始化AP后会自旋(spin)。在让AP更进一步操作前,我们需要首先处理当多个CPUs同时运行内核代码时的竞争条件(race conditions)。最简单的方法是用一个big kernel lock。大内核锁时一个单一的全局锁,它在一个environment进入内核模式时被持有,在这个environment返回用户态时被释放。在这种模式下,用户模式中environments可以在任何可用CPUs上并发运行,但是不能超过一个environment运行在内核模式。任何其他想进入内核模式的environments都必须等待。
kern/spinlock.h中声明了大内核锁kernel_lock。它也提供了lock_kernel() 和 unlock_kernel()函数,简单的去获取或释放这锁。你应该在这四个位置应用大内核锁:
- 在
i386_init()中,在BSP唤醒其他CPUs前获取大内核锁 - 在
mp_main()中,在初始化AP后获取锁,然后调用sched_yield()去在该AP上启动运行environments - 在
trap()中,当从用户模式陷入内核模式时获取这锁。可以检查tf_cs的地位去确定是从用户模式陷入的还是在内核模式陷入的。 - 在
env_run()中,在切换到用户模式前释放这锁。不要太早或者太晚这样做,否则你会经历races或者deadlocks(竞争或死锁?)。
Exercise 5 像上面描述的这样去应用大内核锁,通过在合适位置去调用
lock_kernel()和unlock_kernel()
这里就是要求加上这两个函数而已,比较简单,唯一让我有点困惑的就是env_run()里的unlock_kernel(),不要太早也不要太晚,是把它放到env_pop_tf前,还是干脆放到env_pop_tf里的内联汇编语句前?我都试了一下,都是OK的。所以这里唯一要知道的就是JOS中只能有一个环境在内核态或者说同一时间只有一个CPU可以运行内核代码。
如何测试你的锁是否正确?现在还不行!但在完成下一个练习中的调度程序后你就可以测试了。
Question
2.似乎使用大内核锁保证的是同一时间只有一个CPU可以运行内核代码。为什么每个CPU仍需要单独的内核栈?描述一下使用共享的内核栈会导致什么错误,即使是有着大内核锁的保护。
答:我认为内核栈保存着trapframe,以便内核处理结束后能够返回用户程序正确位置继续执行,如果用共享的内核栈,当多个程序都完成保存现场操作同时要求陷入内核时,就可能会破坏未能获得大内核锁的用户程序的trapframe,导致无法正确返回。
Round-Robin Scheduling
在这个lab中你得下一个任务是修改JOS内核使它能以”round-robin"(轮转)的方式在多个环境中切换。Round-robin scheduling(轮转调度程序)在JOS中是这样工作的:
- kern/sched.c中的
sched_yield()函数负责选择一个新environment去运行。它以循环的方式在envs[]数组中顺序搜索,从刚才在运行的环境之后开始(或者当之前没有运行环境时,就从这个数组的开头开始),选择它找到的第一个状态是REN_RUNNABLE(见inc/env.h)的环境,然后调用env_run()去跳转到执行那个环境。 - sched_yield()一定不能在同一时间在两个CPUs上运行同一个环境。它会说一个环境正在运行在某个CPU上(可能是当前CPU),因为那个环境状态是
ENV_RUNNING - 我们已经为你完成了一个系统调用,
sys_yield(),用户环境会调用它去调用内核的sched_yield()函数,并且自愿放弃CPU给另一个环境
Exercise 6 像描述的那样在
sched_yield()中完成轮换调度程序。不要忘记修改syscall()去dispatch(分派)到sys_yield()
确保在mp_main中调用sched_yield()
修改kern/init.c去创造三个(甚至更多)全部运行程序user/yield.c的环境
运行make qemu。你应该看见终止之前这些环境在彼此之间来回切换了五次,如下所示:
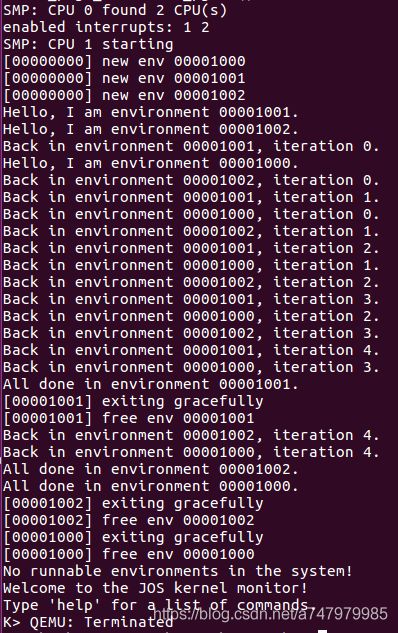
在几个CPUS下也测试一下:make qemu CPUS=2... Hello, I am environment 00001000. Hello, I am environment 00001001. Hello, I am environment 00001002. Back in environment 00001000, iteration 0. Back in environment 00001001, iteration 0. Back in environment 00001002, iteration 0. Back in environment 00001000, iteration 1. Back in environment 00001001, iteration 1. Back in environment 00001002, iteration 1. ...在yield程序退出之前,系统中不会有可运行的环境,调度程序应该调用JOS内核监视器。如果这些都没有发生,那么在继续前请修复你的代码。
void sched_yield(void){
int i=0,j;
//cprintf("i:%d cpu:%d\n",i,cpunum());
if(cpus[cpunum()].cpu_env)
i=ENVX(cpus[cpunum()].cpu_env->env_id);
//cprintf("i:%d\n",i);
for(j=(i+1)%NENV; j!=i; j=(j+1)%NENV)
if(envs[j].env_status == ENV_RUNNABLE)
env_run(&envs[j]);
//我上面那个循环写的有点问题,如果不加下面这个判断,就少判断了env[i]的状态
//这样当所有用户环境只剩env[i]的状态是ENV_RUNNABLE时,cpu无法运行env[i]也无法halt,就一直在循环
if(j==i && envs[j].env_status == ENV_RUNNABLE)
env_run(&envs[j]);
if(curenv && curenv->env_status == ENV_RUNNING){
//cprintf("i:%d cpu:%d id:%08x\n",i,cpunum(),cpus[cpunum()].cpu_env->env_id);
env_run(curenv);
}
//cprintf("j:%d cpunum:%d env_id:%08x j_id:%08x\n",j,cpunum(),cpus[cpunum()].cpu_env->env_id,envs[j].env_id);
// sched_halt never returns
sched_halt();
}
Question
3.在你的env_run()实现中,你应该调用lcr3()。调用lcr3()之前和之后,你的代码引用了(至少应该引用)变量e,即env_run的参数。加载%cr3寄存器后,MMU使用的寻址上下文(addressing context)将立即更改。但是虚拟地址(即e)具有相对于给定address context的意义——地址上下文指定虚拟地址映射到的物理地址。为什么指针e在寻址开关前后都可以被dereferenced?
答:在env_setup_vm()里面,我们初始化了e的虚拟地址空间,所有环境的地址空间的内核部分都是一样的,而在我们的设定中,所有UTOP以上的地址空间内容都相同。在memlayout.h中可以看到,ENVS正好在UTOP上面,所以lcr3之前或者之后,e的地址都没有变,所以可以被dereferenced。
每当内核从一个环境切换到另一个,它必须保证老环境的寄存器被保存好,以便以后可以正确的恢复它们。为什么?这些保存操作发生在哪里?
答:我们先找到哪些地方调用了sched_yield():
env_destroy in env.c (lab2\kern) : env_free(curenv) 时sched_yield();
i386_init in init.c (lab2\kern) : 创建完环境后想启动一个时 sched_yield();
mp_main in init.c (lab2\kern) : 刚启动一个cpu,所以想启动一个环境时 sched_yield();
sys_yield in syscall.c (lab2\kern) : sched_yield();
trap in trap.c (lab2\kern) : curenv->env_status == ENV_DYING 时 sched_yield();
trap in trap.c (lab2\kern) : 内核处理完后回不了curenv 时 sched_yield();
好奇怪,我这调用sched_yield()的地方都是些用不着保存之前环境寄存器状态的情况。。。只有最后那个位置回不了curenv时要重新调度时好像需要保存。这些寄存器值应该是在环境陷入内核态时形成trapframe保存在对应CPU的内核栈中,当从内核态退出的时候pop出来到对应CPU的寄存器中就行。
System Calls for Environment Creation
尽管你的内核现在能够在多个用户级环境间运行和切换,但它仍仅限于运行内核最初设置好的环境。你将实现必要的JOS系统调用去允许用户环境去创造和启动其他新用户环境。
Unix提供fork()系统调用作为其进程创建原语(primitive)。Unix的fork()复制调用进程(the parent)的整个地址空间以创造一个新进程(the child)。从用户空间可以观察到的这两个程序唯一的区别是它们的进程IDs和它们的父进程IDs不相同(由getpid和getppid返回)。在父进程中,fork()返回子进程的进程ID,当在子进程中,fork()返回0。 默认的,每个进程有它自己的私有地址空间,并且进程对内存的修改是其他进程不可见的。
你将提供一组不同的,更加原始的JOS系统调用,用于创建新的用户模式环境。使用这些系统调用,除了创建其他样式的环境之外,你将能完全在用户空间实现类Unix的fork()。你要写的新JOS系统调用应该是这样的:
- sys_exofork:
这个系统调用创建一个几乎是空白的新环境:没有任何东西映射在它的地址空间的用户部分,它也是不可运行的。在调用sys_exofork时,新环境与父环境具有相同的寄存器状态。在父环境中,sys_exofork会返回新创建环境的envid_t(如果环境分配失败,则返回一个负的错误代码)。在子环境中,它会返回0。(因为子环境开始被标记为不可运行,所以sys_exofork实际上不会在子环境中返回,直到在父环境通过标记子环境可运行来明确允许) - sys_env_set_status:
设置指定环境的status为 ENV_RUNNABLE 或 ENV_NOT_RUNNABLE。这个系统调用通常用于标记一个地址空间和寄存器状态已经被完全初始化后的新环境准备好去运行。 - sys_page_alloc:
分配一个物理页并且映射到一个给定环境地址空间的给定虚拟地址上。 - sys_page_map:
将一个物理页的映射(并不是物理页的内容)从一个环境的地址空间中复制到另一个环境,保留一个内存共享安排以至于新老映射都引用物理内存的同一页。 - sys_page_unmap:
取消映射到一个给定环境的给定虚拟地址上的物理页
对于所有上面接受环境IDs的系统调用,JOS内核支持这样的约定:值0表示“当前环境”。本公约由在kern/env.c中的envid2env()执行。
我们已经在测试程序user/dumbfork.c中提供了一个非常原始的类Unix fork()的实现。这个测试程序使用上述系统调用去创建和运行一个复制了它地址空间的子环境。然后像在之前的练习中一样,这两个环境会使用sys_yield来回切换。父环境在10次迭代后退出,子环境则在20次迭代后退出。
Exercise 7. 在
kern/syscall.c中实现上面描述的系统调用,并且确保syscall()调用它们。你将需要使用kern/pmap.c和kern/env.c中的不同函数,尤其是envid2env()。目前为止,每当你调用envid2env(),都要在checkperm参数中传一个1。确保检查了所有无效系统调用参数,在这种情况下返回-E_INVAL。用user/dumbfork测试你的JOS内核,在继续前确保它工作正常。
sys_exofork() 分配一个新环境作为当前环境的子环境,并设置子环境寄存器状态即env_tf与父环境相同,子环境状态为ENV_NOT_RUNNABLE。个人认为这个最难。因为fork()在子环境中返回为0,而返回值通常时保存在%eax中的,所以要设置childenv->env_tf.tf_regs.reg_eax=0,不然就会一直panic:bad environment,因为子环境的envid不存在。
static envid_t sys_exofork(void)
{
struct Env *e;
int r = env_alloc(&e, curenv->env_id);
if(r != 0)
return r;
e->env_status = ENV_NOT_RUNNABLE;
memcpy(&e->env_tf,&curenv->env_tf,sizeof(e->env_tf));
// 子环境的返回值为0,这个我确实知道,但是怎么也想不到得这么写,卡了好久
e->env_tf.tf_regs.reg_eax = 0;
return e->env_id; //这里得特别注意啊,要返回id的
// LAB 4: Your code here.
//panic("sys_exofork not implemented");
}
sys_env_set_status() 设置id为envid的环境的状态为status,很简单
static int sys_env_set_status(envid_t envid, int status)
{
struct Env *e;
//什么叫envid不存在?就是envid2env返回-E_BAD_ENV时说明它不存在
int r =envid2env(envid, &e, 1);
if(r != 0)
return r;
if(e->env_status != ENV_RUNNABLE && e->env_status != ENV_NOT_RUNNABLE)
return -E_INVAL;
e->env_status = status;
return 0;
// LAB 4: Your code here.
panic("sys_env_set_status not implemented");
}
sys_page_alloc() 分配一个物理页并映射在虚拟地址va处,权限为perm。按照提示一条条写,不难
static int sys_page_alloc(envid_t envid, void *va, int perm)
{
//envid doesn't currently exist
struct Env *e;
int r = envid2env(envid, &e, 1);
//cprintf("envid:%d\n",envid);
if(r != 0)
return r;
//va >= UTOP, or va is not page-aligned
if((uintptr_t)va % PGSIZE !=0 || (uintptr_t)va >= UTOP)
return -E_INVAL;
//PTE_U | PTE_P must be set
if((perm & (PTE_U | PTE_P)) ==0)
return -E_INVAL;
//PTE_AVAIL | PTE_W may or may not be set, but no other bits may be set
if( perm & ~PTE_SYSCALL )
return -E_INVAL;
//there's no memory to allocate the new page, or to allocate any necessary page tables
struct PageInfo *pp;
pp = page_alloc(1); //参数为1就是初始化页面内容为0。
if(!pp)
return -E_NO_MEM;
//If page_insert() fails, remember to free the page
r = page_insert(e->env_pgdir, pp, va, perm);
if(r != 0){
page_free(pp);
return r;
}
return 0;
// LAB 4: Your code here.
panic("sys_page_alloc not implemented");
}
sys_page_map() 复制srcenv的地址空间的虚拟地址srcva上的映射到dstenv的地址空间的虚拟地址dstva处
static int sys_page_map(envid_t srcenvid, void *srcva, envid_t dstenvid, void *dstva, int perm)
{
//envid doesn't currently exist
struct Env *srce, *dste;
int src =envid2env(srcenvid, &srce, 1);
if(src != 0)
return src;
int dst =envid2env(dstenvid, &dste, 1);
if(dst != 0)
return dst;
//va >= UTOP, or va is not page-aligned
if((uintptr_t)srcva % PGSIZE !=0 || (uintptr_t)srcva >= UTOP)
return -E_INVAL;
if((uintptr_t)dstva % PGSIZE !=0 || (uintptr_t)dstva >= UTOP)
return -E_INVAL;
//PTE_U | PTE_P must be set
if((perm & (PTE_U | PTE_P)) ==0)
return -E_INVAL;
//PTE_AVAIL | PTE_W may or may not be set, but no other bits may be set
if( perm & ~PTE_SYSCALL )
return -E_INVAL;
//if (perm & PTE_W), but srcva is read-only
struct PageInfo *srcpp;
pte_t *srcpte;
srcpp = page_lookup(srce->env_pgdir, srcva, &srcpte);
if(((*srcpte & PTE_W) == 0) && (perm & PTE_W) )
return -E_INVAL;
int r = page_insert(dste->env_pgdir, srcpp, dstva, perm);
if(r != 0)
return r;
return 0;
// LAB 4: Your code here.
panic("sys_page_map not implemented");
}
sys_page_unmap() 取消envid地址空间的虚拟地址va上映射的物理页
static int sys_page_unmap(envid_t envid, void *va)
{
// Hint: This function is a wrapper around page_remove().
struct Env *e;
int r =envid2env(envid, &e, 1);
if(r != 0)
return r;
//va >= UTOP, or va is not page-aligned
if((uintptr_t)va % PGSIZE !=0 || (uintptr_t)va >= UTOP)
return -E_INVAL;
page_remove(e->env_pgdir, va);
return 0;
// LAB 4: Your code here.
panic("sys_page_unmap not implemented");
}
最后syscall() 里完成dispatch。这里也是不难的,参数的话可以看看lib/syscall.c里是怎么调用的,如下:
...
case (SYS_exofork):
return sys_exofork();
case (SYS_env_set_status):
return sys_env_set_status(a1,a2);
case (SYS_page_alloc):
return sys_page_alloc(a1, (void *)a2, a3);
case (SYS_page_map):
return sys_page_map(a1,(void *)a2,a3,(void *)a4,a5);
case (SYS_page_unmap):
return sys_page_unmap(a1,(void *)a2);
...
//首先看看lib/syscall.c的syscall()
static inline int32_t syscall(int num, int check, uint32_t a1, uint32_t a2, uint32_t a3, uint32_t a4, uint32_t a5)
//以sys_page_alloc为例,第一个参数是系统调用号,第二个参数是check,从第三个参数开始就是a1, a2,...,a5
//不过调用的时候记得类型转换
int sys_page_alloc(envid_t envid, void *va, int perm){
return syscall(SYS_page_alloc, 1, envid, (uint32_t) va, perm, 0, 0);
}
到这已经完成了这个lab的Part A部分。确保当你运行make grade时它能通过所有Part A的测试,然后像往常一样用make handin命令上交它。如果你想要弄明白一个特定测试用例失败的原因,运行./grade-lab4 -v,它将向你展示内核构建的输出并为每个测试运行QEMU,直到一个测试fails。当一个测试fails时,脚本将停止,然后您可以检查jos.out看看内核实际打印了什么。
问题(猜的)
-
cpu 0是什么,cpu 1,2,3,4是什么?BSP在启动了MP之后是不是也做为了MP中的一个?
答:我在i386_init里boot_aps之前输出了以下cpunum(),发现输出的是0,说明BSP就是CPU 0。cpu 1,2,3,4就是BSP启动的MP,当这些处理器都启动了之后,BSP就通过i386_init 里的sched_yield()去调度一个进程执行并释放大内核锁,这时BSP就跟其他CPU一样一样的了。 -
percpu_kstacks到底保存着什么?
答:我在下面输出了一下,当CPUS=4的时候,percpu_kstacks[]={f022d000,f0235000,f023d000,f0245000}。感觉只是为即将新启动的CPU提供一个初始化栈指针,以便它调用mp_main()函数时能有地方存状态。 -
什么时候给的env_id呢,我怎么不知道?
答:在env_alloc()里给的 -
两个CPU是怎么同时工作的?如果同时申请执行内核代码,那么一个进入,剩下那个是在当前进程卡住还是执行其他进程?
答:我感觉两个CPU在启动后就各自调用sched_yield()去调用一个环境运行,通过ioapic来统筹所有cpu的工作,每个cpu都通过自己的lapic接收或者发送中断到ioapic。多个CPU同时申请执行内核代码时,一个成功申请到大内核锁,剩下的就简单的pause等待大内核锁释放,至于下一个是谁申请到,应该在xchg有个顺序吧。因为://在spin_lock中 // The xchg is atomic. // It also serializes(序列化的), so that reads after acquire are not // reordered before it. while (xchg(&lk->locked, 1) != 0) asm volatile ("pause"); -
每一次申请大内核锁,为什么要在那申请,都是什么时候解开的?
首先要明白,大内核锁的作用是一次只能有一个CPU执行内核代码。所以
(1)在boot_aps前申请,这样BSP启动的其他CPU不会干扰BSP的工作;
(2)在mp_main中调用sched_yield之前申请,这样,一次只有一个CPU可以执行轮转调度,而不会出现分配一个环境给多个CPU的情况。
(3)在trap中,当CPU在sched_yield中被halted时申请,当是从用户模式陷入进来时在执行内核工作前申请。因为从可能多个程序从用户模式陷入,这样在执行内核操作前就得先申请大内核锁保护,避免破坏其他程序的trapframe等信息。
(4)解开的话就是在env_run里,因为此时已经执行完了内核操作,要回到用户态了,所以把大内核锁释放掉。好像没有看到其他地方有释放大内核锁的操作。 -
怎么进入mpentry.S的?什么时候进?
答:在boot_aps中给出了AP的入口地址MPENTRY_PADDR,还给了每个CPU的初试栈地址mpentry_start。然后进入lapic_startap里去设置好入口地址,并发送STARTUP IPIs,所以就进入了mpentry.S中。但我跟不了这个过程,不知道为什么。 -
为什么好多lapic.c中的操作都执行两次?
-
虚拟地址,物理地址,到底是怎么转换?还有LMA与VMA?因为有时候就是通过页表,有时候又可以通过+/- KERNBASE,所以我乱了。
答:想不到Lab4了跟同学聊了好几次才想明白这么简单一问题,真是汗颜。。。
boot_map_region(kern_pgdir, KERNBASE, 0x100000000-KERNBASE, 0, PTE_W|PTE_P);虚拟地址跟物理地址确实是通过页表建立了映射。之所以能通过+/-KERNBASE那是因为无论在kern_pgdir还是所有env_pgdir中,内存空间的KERNBASE以上的区域都是被映射在[0,256M)的物理页上,所以无论通过页表还是+/-KERNBASE都可以通过虚拟地址找准那个物理页,懂了吧,傻。
至于LMA与VMA。我之前还以为LMA是物理地址,因为是叫实际加载的地址,我忽略了它的全称是load memory address,实际加载到内存中的地址,所以LMA是虚拟地址。LMA跟VMA大多数情况是一样的,当不同的时候,就把LMA指向的物理页内容复制到VMA指向的物理页中。至于什么时候不同,不太懂,网上的例子说涉及到flash时不太一样,等遇到了再说 -
当启动MP后,哪个来执行i386_init,剩下的CPU都被阻塞吗?我有种感觉,其实在boot_aps前已经启动了所有CPU,所以根本没有进到mpentry.S中,不然,我设断点在boot_aps、lapic_startap、mpentry_start根本阻止不了QEMU往下运行
我一开始还以为是我运行gdb时没有设置CPUS=2,所以它确实不会进boot_aps,但是后面我设置了还是不行,就真的不懂了。 -
在所有用户环境都exit之后,CPU也会被halted,那是哪个来执行的monitor呢?

答:在sched_halt()里可以看到,当CPU因目前没有可执行的程序进入这个函数,并且当前没有其他任何CPU还在执行程序(因为i==NENV),那么当前CPU就会执行monitor,而不会被halted
参考
PIC(Programmable Interrupt Controller)
Linux APIC 详细分析
APIC的那些事儿
MIT6.828 Lab4 PartA
谢谢乾卦的JOS4-1里的注释