【Nebula】图数据库Nebula Graph
文章目录
- 1、图数据库
- 2、NebulaGraph 的数据模型
- 3、路径Path
-
- walk
- trail
- path
- 4、VID
-
- VID的特点
- VID的生成
- 5、NebulaGraph的服务架构
-
- Meta服务
- Graph服务
- Storage服务
- 6、Raft
1、图数据库
对于有内在联系的事务, 关系型数据库通常会提取实体之间的关系, 将关系单独存储到表或列中,而实体的类型和属性存储在其他列甚至其他表中,这使得数据管理费时费力。如下图中的顾客表、订单表、商品表…此时:
- 查询用户购买了哪些商品得join
- 该商品有哪些用户购买过得join
- 购买过该产品的用户还购买过哪些产品, 就得在几张表中来回穿梭了
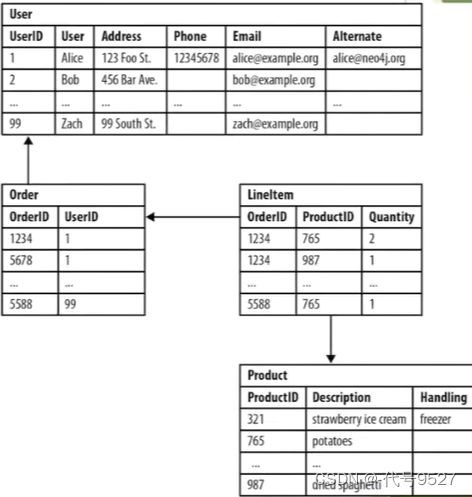
基于此, 图数据库诞生。图数据库是专门存储庞大的图形网络并从中检索信息的数据库。它可以将图中的数据高效存储为点(Vertex)和边(Edge),还可以将属性(Property)附加到点和边上。

而NebulaGraph 作为一个典型的图数据库,可以将丰富的关系通过边及其类型和属性自然地呈现。


例如雷先生是M公司的CEO, 投资了B公司和C公司, 同时还是D公司的董事会成员, 这些关系都可以直接存放在Nebula Graph中, 构成一个最简单的图模型。

关于Nebula Graph的应用场景有 :
- 实时推荐
- 知识图谱
- 大数据风控
- 网络安全
- 医疗数据分析
- 证券投资
- 金融风控…
2、NebulaGraph 的数据模型
图空间(Space):
- 图空间用于隔离不同团队或者项目的数据。
- 不同图空间的数据是相互隔离的(类比database),可以指定不同的存储副本数、权限、分片等
点(Vertex):
- 用来保存实体对象
- 点是用点标识符(VID)标识的,VID在同一图空间中唯一。VID 是一个 int64,或者 fixed_string(N)
- 每个点可以有 0(3.x版本)到多个 Tag
边(Edge):
- 边是用来连接点的,表示两个点之间的关系或行为
- 两点之间可以有多条边
- 边是有方向的,不存在无向边(图有无向图和有向图 , 但NebulaGraph 只支持有向边)
- 四元组 <起点 VID、Edge type、边排序值 (rank)、终点 VID> 用于唯一标识一条边。边没有 EID
- 一条边有且仅有一个 Edge type
- 一条边有且仅有一个 Rank,类型为 int64,默认值为 0
- Rank 可以用来区分 Edge type、起始点、目的点都相同的边。该值完全由用户自己指定
标签(Tag):
- Tag 由一组事先预定义的属性构成
边类型(Edge type):
- 一组事先预定义的属性
属性(Property):
- 属性是指以键值对(Key-value pair)形式表示的信息
3、路径Path
路径即一些边的序列。分为walk、trail、path三种:(图示如下,注意nebula中都是有向边)
walk
walk类的路径,遍历时点和边都可以重复。由此dutor走到Simon家可以:
- A–>B–>C
- A–>B–>D–>E–>C
- A–>B–>D–>A–>B–>C

trail
trail类型的路径遍历时只有点可以重复,边不可重复。此时dutor走到Simon家只能:
- A–>B–>C
- A–>B–>D–>E–>C

trail类型路径中,有两种特殊路径:cycle和circuit,二者的起点和终点一样:

不同的是:cycle只有起点和终点重复,而circuit还存在其他点:

对应在例子中,cycle路径为A–>B–>C–>F–>A

而circuit为:A–>B–>C–>D–>E–>C–>F–>A,两次经过C点

最后:MATCH、FIND PATH和GET SUBGRAPH语句采用的是trail类型路径
path
path类型的路径遍历时,点和边都不可以重复。此时dutor走到Simon家只能:
- A–>B–>C
- A–>B–>D–>E–>C

如果点是陆地,边是桥,那:
- walk就是你走过后,陆地和桥都在
- trail就是你走后,陆地还在,但桥不在了
- path就是你走后,身后的陆地和桥都消失了

路径长度的有限无限即边的数量有限或者无限。
4、VID
在一个图空间中,一个点由点的 ID 唯一标识,即 VID 或 Vertex ID。(vertex翻译:顶点)。
VID的特点
- VID 数据类型只可以为
定长字符串FIXED_STRING(。一个图空间只能选用其中一种 VID 类型。)或INT64 - 在同一个图空间中,VID必须唯一,其作用类似于关系型数据库中的主键(索引+唯一约束)
- VID的生成方式由用户自己指定,系统不提供自增ID或者UUID
- VID 相同的点,会被认为是同一个点
- VID 通常会被(LSM-tree 方式)索引并缓存在内存中,因此直接访问 VID 的性能最高
VID 相当于一个实体的唯一标号,例如一个人的身份证号。Tag 相当于实体所拥有的类型,例如"滴滴司机"和"老板"。不同的 Tag 又相应定义了两组不同的属性,例如"驾照号、驾龄、接单量、接单小号"和"工号、薪水、债务额度、商务电话"。
-
对同一个VID同时INSERT同一个TAG(均无IF NOT EXISTS参数),先写入的TAG被覆盖
-
对同一个VID同时INSERT,但是两个不同的TAG,则互不影响
-
VID 的数据类型必须在创建图空间CREATE SPACE时通过参数vid_type定义,且一旦定义无法修改
-
VID 必须在插入点时设置,且一旦设置无法修改
VID的生成
- (最优)通过有唯一性的主键或者属性来直接作为 VID,属性访问依赖于 VID
- 通过有唯一性的属性组合来生成 VID,属性访问依赖于属性索引
- 通过 snowflake 等算法生成 VID,属性访问依赖于属性索引
- 如果个别记录的主键特别长,但绝大多数记录的主键都很短的情况,不要将FIXED_STRING()的N设置成超大,这会浪费大量内存和硬盘,也会降低性能。此时可通过 BASE64,MD5,hash 编码加拼接的方式来生成
- 如果用 hash 方式生成 int64 VID:在有 10 亿个点的情况下,发生 hash 冲突的概率大约是 1/10。边的数量与碰撞的概率无关
5、NebulaGraph的服务架构
NebulaGraph 由三种服务构成:Graph 服务、Meta 服务和 Storage 服务,是一种存储与计算分离的架构。其中:
- Meta负责数据管理
- Graph 服务负责处理计算请求
- Storage 服务负责存储数据

Meta服务
Meta 服务是由 nebula-metad 进程提供:

架构如下:
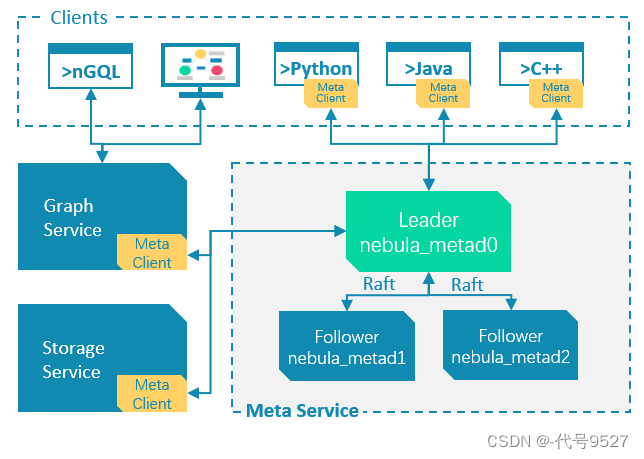
nebula-metad 进程中:
- 一个进程是 leader,其他进程都是 follower
- leader 是由多数派选举出来,只有 leader 能够对客户端或其他组件提供服务,其他 follower 作为候补,如果 leader 出现故障,会在所有 follower 中选举出新的 leader
- leader 和 follower 的数据通过 Raft 协议保持一致,因此 leader 故障和选举新 leader 不会导致数据不一致
Meta服务的功能:
- 管理用户账号:存储用户的账号和权限,客户端发起请求给Meta,它会检查账号和权限
- 管理分片:存储和管理分片的位置信息,并且保证分片的负载均衡
- 管理图空间:Meta存储看所有图空间的元数据,并跟踪数据变更(如增减删除图空间)
- 管理 Schema 信息:NebulaGraph 是强类型图数据库,它的 Schema 包括 Tag、Edge type、Tag 属性和 Edge type 属性
- 管理 TTL 信息:存储 TTL(Time To Live)定义信息,用于设置数据生命周期
Graph服务
Graph 服务主要负责处理查询请求,包括解析查询语句、校验语句、生成执行计划以及按照执行计划执行四个大步骤。

查询请求到达Graph服务后,依次经过以下模块:
- Parser:词法语法解析模块
- Validator:语义校验模块
- Planner:执行计划与优化器模块
- Executor:执行引擎模块
Storage服务
NebulaGraph中,元数据的存储在Meta服务,而具体数据的存储在Storage服务。Storage服务架构:

图存储的主要数据是点和边,NebulaGraph 将点或者边的信息存储为 key,同时将点或边的属性信息存储在 value 中
-
点存储:

相比 NebulaGraph 2.x 版本,3.x 版本在开启无 Tag 的点配置后,每个点多了一个不含 TagID 字段并且无 value 的 key

-
边存储:

以两个点和一条边为例,起点 SrcVertex 通过边 EdgeA 连接目的点 DstVertex,形成路径(SrcVertex)-[EdgeA]->(DstVertex):

两个点和一条边以6个键值对的形式保存在两个分片Partition X和Partition Y中:
- 点 SrcVertex 的键值保存在 Partition x 中
- 边 EdgeA 的第一份键值EdgeA_Out ,与 SrcVertex 一同保存在 Partition x 中。key 的字段有 Type、PartID(x)、VID(Src,即点 SrcVertex 的 ID)、EdgeType(
符号为正,代表边方向为出)、Rank(0)、VID(Dst,即点 DstVertex 的 ID)和 PlaceHolder。SerializedValue 即 Value,是序列化的边属性 - 点 DstVertex 的键值保存在 Partition y 中
- 边 EdgeA 的第二份键值 EdgeA_In ,在 Partition y 中,其中EdgeType字段
符号为负,代表边方向为入
6、Raft

分布式存储系统通常通过维护多个副本来进行容错,提高系统的可用性。要实现此目标,就必须要解决分布式存储系统的最核心问题:维护多个副本的一致性。

Raft协议的每个副本都会处于三种状态之一:Leader、Follower、Candidate
- Leader:所有请求的处理者,Leader副本接受client的更新请求,本地处理后再同步至多个其他副本
- Follower:请求的被动更新者,从Leader接受更新请求,然后写入本地日志文件
- Candidate:如果Follower副本在一段时间内没有收到Leader副本的心跳,则判断Leader可能已经故障,此时启动选主过程,此时副本会变成Candidate状态,直到选主结束
读写流程:
对于客户端的每个写入请求,Leader 会将该写入以 Raft-wal 的方式,将该条同步给其他 Follower,并只有在“超过半数”副本都成功收到 Raft-wal 后,才会返回客户端该写入成功。对于客户端的每个读取请求,都直接访问 Leader,而 Follower 并不参与读请求服务。
故障场景:
- 场景 1:考虑一个配置为单副本(图空间)的集群;如果系统只有一个副本时,其自身就是 Leader;如果其发生故障,系统将完全不可用。
- 场景 2:考虑一个配置为 3 副本(图空间)的集群;如果系统有 3 个副本,其中一个副本是 Leader,其他 2 个副本是 Follower;即使原 Leader 发生故障,剩下两个副本仍可投票出一个新的 Leader(以及一个 Follower),此时系统仍可使用;但是当这 2 个副本中任一者再次发生故障后,由于投票人数不足,系统将完全不可用。