架构演进之路——通俗易懂
这是一个憨态写的文章
- 架构演进
-
- 架构拓展选型
- 实现横向拓展
-
- 反向代理
- 负载均衡
- 数据库危机
-
- 分库分表
- 微服务
- 缓存
- 消息队列
-
- 削峰填谷
- 异步提速
架构演进
有一天半夜心血来潮突然想做个涩清网站,做一下技术选型,前端找了个模板改了改,后台敲了两句代码,然后部署到服务器上:
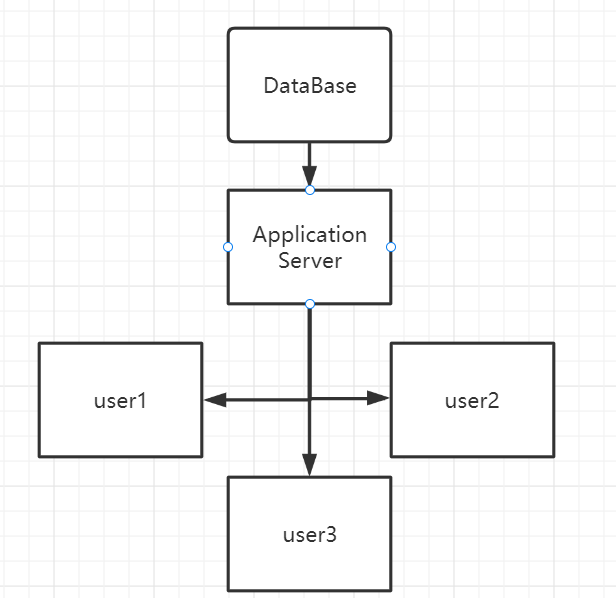
这个就是我们网站最初的架构了
- 一个处理业务逻辑的服务器
- 一个MySQL数据库持久化储存数据
- 每天十几个用户访问(可能还不到 ◑﹏◐)
- 再加上一个不大聪明的脑阔
日复一日,年复一年,这个'正规网站'运营的非常成功!用户越来越多,请求量也随之暴增,网站的速度越来越慢,而是你开始考虑对架构做改进!
于是你开始上百度:

求助大神:

这位大神 Java、前端 的功底深厚,面向对象的各种技能用得精通,编码姿势潇洒,闷骚至极,只是可惜,他还没有对象
架构拓展选型
通过大神口中了解到了,拓展分为两种拓展:
-
纵向拓展(也叫 垂直拓展)
其实就是把我们的网站放到更强大更 nb 的计算机上来运行,通过拓展这一个点的能力来支撑更大的请求。
这一类就是属于个人英雄主义派,就像蜘蛛侠一人逼停火车这样,英雄一人拯救世界
-
横向拓展(也叫 水平拓展)
横向拓展刚好与纵向拓展相反,主要是使用更多的普通计算机并行处理用户的请求,用更多的节点来支撑更大请求。
这一类就是认为个人是杂杂,认为大家团结一致,造个核弹飞过去直接世界核平了
在咱们 2021 年的今天已经没人谈纵向扩展这条路了,原因也十分简单,计算机性能越高,价格也是成倍上升(对于大部分平民玩家而言,完全遭不住)
而且单台计算机的性能本身就有上限(单台电脑的能力是极限的,所以我选择集群)
实现横向拓展
好的,现在定下来了走横向扩展着条路,那么要如何实现它呢?
于是你带上两张涩图去请教了大神:

玛莎卡,这就是所谓的‘知识付费’吗 (⓿_⓿)?
首先我们先来看看我们网站最原始的架构:
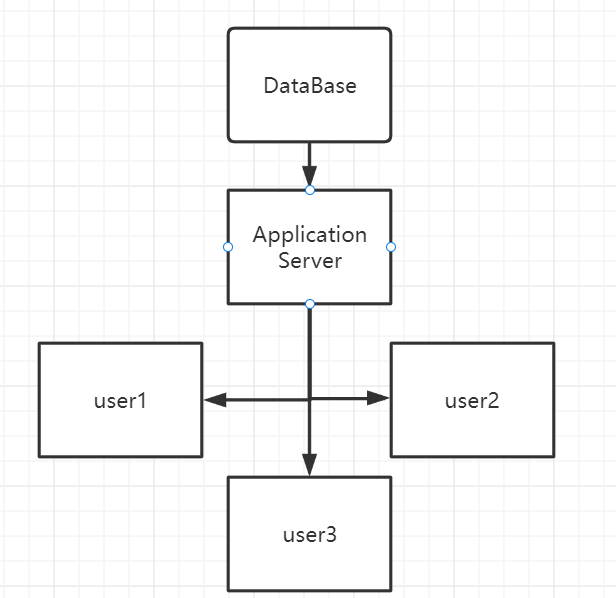
一个服务器处理业务逻辑
一个数据库持久化存储数据
还有一个不大聪明的脑阔 ≡(▔﹏▔)≡
其实我们这样的架构,这样做也没啥子问题,好用又简单。
但是缺点也非常明显,这种单台服务器架构如果想支持更多的用户,唯一的办法就是用更强的服务器,也就是说只能走横向拓展路线
反向代理
为了让网站支持更多的用户,为了爱与正义(爱与正义又是怎么冒出来的?),首先我们在用户与服务器之间添加一个反向代理

(在我们程序开发中加一层往往能解决很多问题,不行就加两层)
这个时候有人就要问了,这个反向代理有什么作用呢?
这里不详细说明反向代理,后面有空我单独出一篇文章说明,主要就简单讲讲它:
作用:
- 可以隐藏服务器原本的信息(例如ip地址等等),可以检查你的
服务器是否健康,把用户的请求转发到正确的服务器地址,检查用户是否有权限访问你的服务器 - 这意味着有了反向代理后,你永远不会与服务器直接通信。可以将它看作服务器的某种包装器。通过负载均衡和缓存,它们就可以有效保护 web免受攻击,并提供更好的 web 性能
- 某些反向代理可以缓存资源,意味着,如果你正在寻找的信息已经在缓存中,它不必浪费资源,试图再次获取它,它会直接发送给你,而不打扰服务器
有了反向代理这个工具,我们进一步引入它的好兄弟:负载均衡
负载均衡
负载均衡名字听起来听起来 高大上、牛掰哄哄 的,但其实是个很简单的概念:
每秒钟有 300 个请求需要处理,但是你的服务器只能够支持 1台 服务器,解决办法就是使用三台服务器并行处理,负载均衡的作用就是把这 300 个下单请求均匀分配到三台服务器上,假设请求增加了,也只需要拓展更多的服务器,因为
负载均衡会帮我们完成请求的分配
于是我们的架构就变成了下图这样:

ok,到处为止我们的架构就完成了横向拓展的第一步了,服务器终于可以并行处理请求承受更多的压力了,好耶!干饭去了
数据库危机
过了了很长一段时间,网站运营蒸蒸日上,随着用户增长,数据库表示遭不住了(哎妈呀,一下子又胖了100多MB,真吃不下了 >︿<。啊不是,你又扒我内裤干啥,查啥呢,啊不是,那是我收藏的种子,别乱动...... )
多台服务器都访问咱这一个数据库,到一定的请求之后,数据库表示压力太大了,遭不住了,直接奔溃了…
难道就没有什么解决办法吗?比如像拓展服务器一样拓展数据库这样不行吗?把数据库多复制出来几份一起玩、一起分担之类的。
答案是:不能!
其中最关键的问题就是数据一致性
这里说的数据一致性难题指的是:数据在多份副本中存储时,如何保障数据的一致性
在数据有多副本的情况下,如果网路、服务器或者软件出现故障,会导致部分副本写入失败。这就造成各个副本之间的数据不一致,数据内容冲突。实践中,导致数据不一致的情况有很多种,表现形式也很多样,比如更新返回操作失败,实际上数据在存储服务器已经更新成功
分库分表
为了解决这个问题,我们可以把原来的一个数据库拆分成多个,这里就涉及到了 分库分表

看到新的高端技术名词的你可能这样想:教练,我不想学了,我突然想开了,不想卷了,感觉找个富婆也挺好的
教练:我想想,嗯 … … 要不来我房间,我房间很大
(上面这该死的水印我找时间给干掉)
看文章的你:啊?
教练:啊啥啊?过来就行了
看文章的你(菊花一凉):我突然又想卷了
教练:你开悟了 (* ̄3 ̄)╭
好的,水完一段文字之后我们回到正题(╹ڡ╹ )


老样子,分库分表这边的话,也只是简单说两句,因为我们的主题是架构演进:
首先我们明确一下
分库分表之前的问题,也就是单库单表存在的问题
在用户和访问量比较少的时候,单库单表不存在问题。
但是随着网站的发展,用户量开始大量增加,业务也开始变得越来越复杂。
一张表的字段和数据还贼多,高达几千万数据,最难受的是这样的表还挺多。
扒说了,人家数据库血压直接一下子就飙上来了。试想一下,我们在一张几千万数据的表中查询数据,压力本身就大,如果这张表还需要关联查询,那真的是直接奔溃了
稍微总结一下上面的一段屁话:
- 单库太大:数据库里面的表太多,所在服务器磁盘空间装不下,IO次数多CPU忙不过来
- 单表太大:一张表的字段太多,数据太多。查询起来困难
而在我们的开发黄金手册(阿里巴巴开发手册)也有说明在什么样的情况推荐使用分库分表:
在实际开发中,也一般按照这个推荐来进行分库分表

进行了一通改造后,我们的架构变成了这样:

由一个数据库专门写入数据,数据写入之后会自动同步到其他数据库
熟悉 redis 的同学可能会觉得有点熟悉,玛莎卡!这不就是
主从复制吗!
哈哈,不错,这里直接上图:
一种自动同步到备机的
master/slaver 机制,master 以写为主,slaver 以读为主

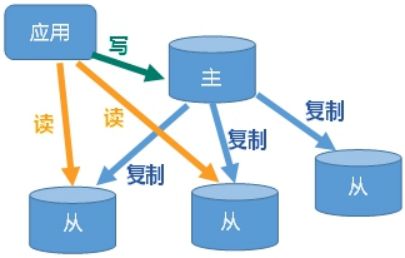
之后可以从这些数据库上读取数据,这样做,写入压力没有得到缓解,还是往一个数据库中写,但是现在可以通过读数据库来分摊数据读取的压力了
这就是数据库的主从复制(跟 redis 的主从模式不能说毫不相干,简直一模一样)
或者叫做读写分离模式,咋叫都行,比如像下面这样子叫:

你是不是变色了?

大部分网站里的数据的读取次数远比写入次数要多
比如
正在看这篇文章的你不打算点赞收藏评论一样读写分离正好适用于这种白嫖怪遍地横行的场景
微服务
到目前为止,我们在每一台扩展出来的服务器上运行和处理了所有的业务,比如下单、支付、上传、权限管理等等。
嗯,这不一定是件坏事,因为单一的服务器也以为这更低的复杂性,我们做开发的处理起来也不会那么头疼 …

随着网站的业务和规模不断增加,事情开始变得复杂和低效了 …
首先,不同的业务逻辑都部署在一台服务器上,但是它们对 cpu 和 内存 这些 硬件资源 的使用要求是不一样的。
不同的用户对不同的业务使用频率也是不一样的 …
那么这又会出现什么问题呢?
这就造成了比如你想扩展文件上传这个业务,本来多增加两台服务器就够了,但是因为登录业务跟其他业务部署到了同一台服务器,其他业务也被迫占用了服务器资源,所以不得不增加 20 台服务器(
会不会有点夸张了?夸张就对了,这才印象深刻)才可以达到原本只需要增加 2 台服务器的效果,一些本不需要扩展的业务也跟着进行了扩展,造成了资源的浪费!
看文章的你可能会这样想:
资源浪费?嗯哼,没关系啊,代码能跑不就行了,让老板多花点钱不就 …
一巴掌呼死你啊,现在的文章中的设定是你自己的网站架构啊,憨nou八嘎 (╯▔皿▔)╯
还有,刚从动漫中截图出来的表情包,可爱扒 (~ ̄▽ ̄)~
番名叫做 … 咳咳跑题了,我们继续



除了上面说的 对不必要的业务进行扩展造成资源浪费(自己抓重点总结一下啊混蛋) 这个问题外,还有,我们的开发团队也跟着网站的业务发展壮大,不同的团队负责不同的业务,某些团队开发已经完成了,但是另一些团队刚进行到一半,因为所有代码都部署在同一台服务器上,导致各个团队开发和部署之间相互依赖,剪不断理还乱!
可能到最后谁也理不清楚什么时间点才是合适的版本发布时机。
换一句话说就是:业务团队耦合度过高(自己总结一下啊,おバカさん)
上面问题的 解决方案就是引入微服务 ,微服务的想法也很简单,就是把你的网站拆解成若干个不同的功能单元,把它们部署成单独的、互相连接的小型服务,噔噔, 就是我们引入微服务之后的架构图了
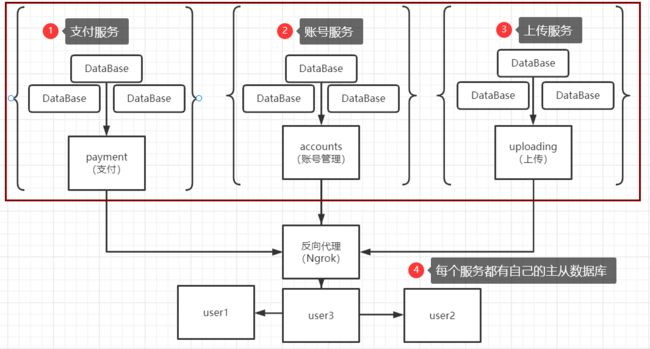
这样做有很多好处,做了解耦之后,空气都变得新鲜了!
这种感觉真是爽快,就像是穿着新内裤迎接新年来到的早晨一样爽呢~~(❁´◡`❁)
比如用户文件上传的业务压力太大?
那就直接拓展相应的微服务就好了
同时开发团队也可以独立工作了
每个团队负责维护自己业务的微服务
开发完成随时可以部署。更进一步,因为服务之间独立了,每个服务都会有自己的主从数据库。
现在的架构里负责 “写”的数据库也增加了,缓解了前面写数据都集中在一台数据库的尴尬局面

缓存
经过了上面的演进,我们的架构变成了现在的 微服务+读写分离
那么还有办法让业务服务器更好的工作吗?
有,答案就是让他少工作 … …
看文章的你:桥都骂得,我先来猜一下,让服务器少工作 … 那么应该就是——
教练:猜到了?
看文章的你:哈哈,就是让老板多买几台服务器来减少其他业务服务器的工作量对吧!哈哈,我真™是个天才,这就跟老板去申请,哇呜,年薪百万不是梦 …
教练:
这 ™ 不看标题又是个毛子操作



好吧这是我脑子想到的沙雕剧情(看见也不要吐槽,我会尴尬社死的),怎么可能有人这么傻对吧?
看到标题,很多人首先想到的应该就是大名鼎鼎的 Redis 了,嗯,这也没错,不过我首要介绍的是 CDN(悄悄告诉你,这个技术一般是用来缓存静态资源的)。
网站有很大一部分都是由静态资源构成的,这些资源长时间都不会改变,比如图片、视频、html、css 等文件,我们把这些长时间不变的资源缓存起来,而不是每次都通过业务服务器重新计算提供给用户,这些缓存服务器相当于一个独立的存储空间,它可以直接提供之前的计算结果,而不需要打扰更下层的服务器
一般在项目里,缓存这些静态资源的技术就是 CDN,内容分发网络

CDN 的提供商,在全球多个国家和区域都有缓存服务器。
这些服务器能从我们网站上获取静态资源并暂存下来,之后用户对这些静态资源的请求会根据他所在的地址会被转到最近的 CDN 服务器并获取数据。
由于缓存消除了重复计算,进一步提高了响应速度和用户体验,解放了后端业务服务器的压力,从而提高了网站支持的最大并发数。
当然缓存的使用远不止上面提到的静态资源,一些常用的计算结果和热点数据也可以缓存起来,虽然用到的技术不同(比如前面提到的 Redis,我们一般就往里面存储热点数据、查询结果等等缓存起来),但是消除重复计算的目的是一样的
消息队列
那么除了缓存之外,还有办法支持更多的用户吗?
有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?有吗?
啊这不会看标题还是咋样?
教练:啊不是,就是作者想水个字数而已
这样啊,那没事了
(‾◡◝)

削峰填谷
我们可以通过加上消息队列,一次只接受业务服务器能够承受的负荷请求,让其他排队慢慢处理。
假设一下请求量暴增 ,一下子来了 30 万,而我们的服务每秒只能处理 10 万请求,呜呜,扣扣马得尬(最后这句话的意思是:到此为止了吗)
但是有了 MQ 之后,这 30 万用户请求首先会放入 MQ 中,然后我们的服务,每秒会从 MQ 中拉取 10 万请求进行处理。
这个骚操作在我们的 MQ 中也有一个专业名词,叫做 削峰填谷
这个时候就有人要问呢?为毛子叫做 削峰填谷 呢?
我的理解是这样的:
某一天一下子请求量暴增 20 多万,服务器
血压飙升,我们称之为高峰期
(这图片是网上找的,看着帮助理解一下就行了)
使用了 MQ 之后,限制请求处理数为每秒 10 万,这样依赖,高峰期产生的数据势必会被挤压在 MQ 中,高峰就被 “削” 掉了,但是因为消息积压,在高峰期过后的一段时间内,消费的消息还是会维持在 10 万,直接到消费完积压的消息,这就叫做“填谷”。
如果你看到这里还没有理解的话,那我只能举一些残酷一点的例子了
晨波的你(高峰期,想要一发冲天的你),被你女朋友一菜刀削掉了(也不一定是女朋友,万一是舍友呢?)这就是削峰填谷


请求真正被处理完的速度取决于后面有多少台业务服务器
消息队列的好处是显而易见的,它解耦了请求本身的请求和处理过程
另外,当请求数瞬时增加,自动拓展服务器本身也需要时间,有了消息队列这个保护膜,可以让我们的系统里奔溃更远,离稳定更近
异步提速
MQ 除了削峰填谷这个优势之外,MQ 也还有其他很多强大的功能(感兴趣的话自己上网了解一哈),这里我就讲讲 削钉钉(削峰填谷) 和 异步提速
对比,能让你更轻松的理解知识,我们先了解一下 异步之前是个什么情况
有人委托 A 寄个邮件,于是 A 不远万里,跋山涉水送到收件人邮箱手中,然后再跑回来说已经送出去了(耗时 9999+ 秒)
等你回来委托人吐了口唾沫,效率低的一批,怎么办事的?这么就没消息我还以为你死了呢?我已经委托 B 寄邮件了,他只花了 5 秒左右就给我答复了
我们来看看B委托是如何做到快速响应的,这就是异步提速后的场景:
委托人将委托给 B 后
B 转身跟 C 说:把这个邮件送出去,只需成功不许失败
然后就跟委托人说,邮件已经送出去了(前后耗时 5 秒钟)
大概就是这个意思,目的就是让用户快速得到响应结果
等一下:


先不写了,不想写了,晚点再补,先干点其他事吧
最后扯几句吧,其实我也发现了前面讲的有些内容可能还不够到位,回头下一个版本我会好好优化的(虽然也没写完这个,哈哈)
所以下一个版本啥子时候出来呢?
我连宇宙的尽头在哪都不知道,怎么会知道这个?
™你不是作者吗?
是啊
。。。。。。。。
水到了 6000+ 字,欸嘿,好开心
还有一件开心的事,蟹蟹你能看到这里!ヾ(≧▽≦*)o
