Elasticsearch Head插件应用及IK中文分词
1. 关于Elasticsearch Head插件
直接通过RESTful方式操作Elasticsearch比较繁琐,安装Head插件,即可对Elasticsearch进行图形化的操作,做到所见即所得。
2. 下载和安装Head插件
2.1 下载并解压
https://github.com/mobz/elasticsearch-head 下载elasticsearch-head-master并解压。
2.2 安装构建组件
npm install ‐g grunt‐cli
2.3 安装依赖
npm install
2.4 解决跨域问题
修改elasticsearch的配置文件elasticsearch.yml,增加以下两行:
http.cors.enabled: true
http.cors.allow‐origin: "*"
2.5 启动
npm start
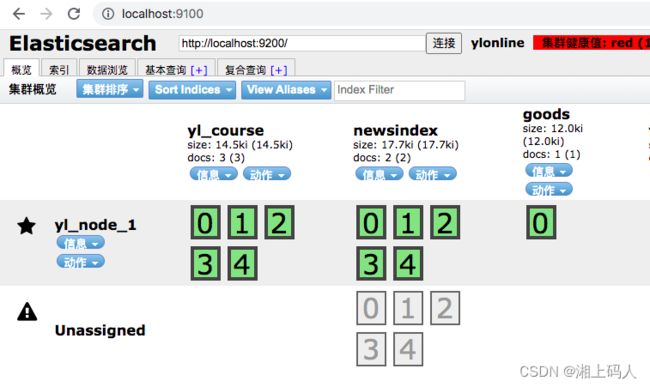
3. 新增索引
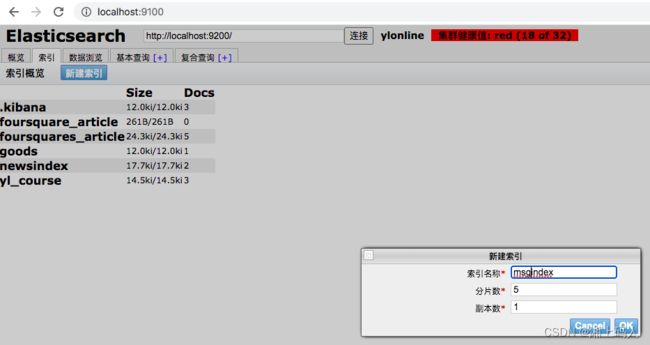
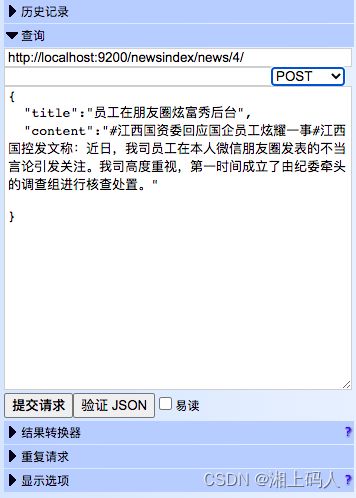
4. 查询文档记录
提交方式选择GET
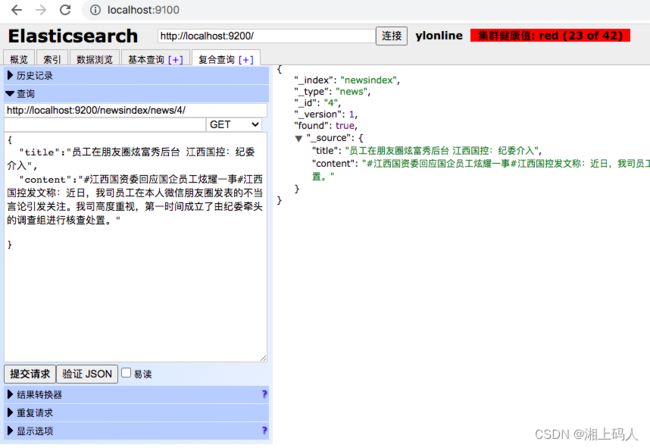
5. 新增文档记录
提交方式选择INPUT
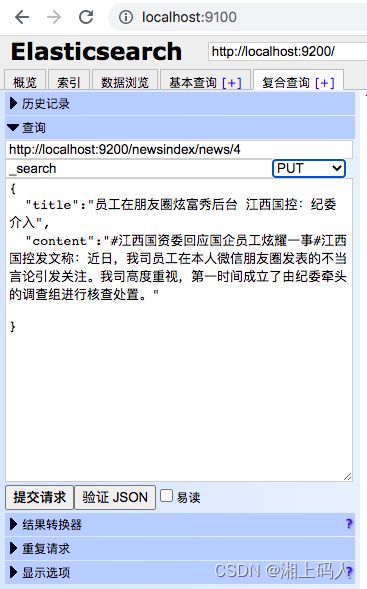
6. 修改
提交方式选择INPUT或POST,如果ID已存在,则新建一个版本。
7. Elasticsearch分词
7.1 自带中文分词
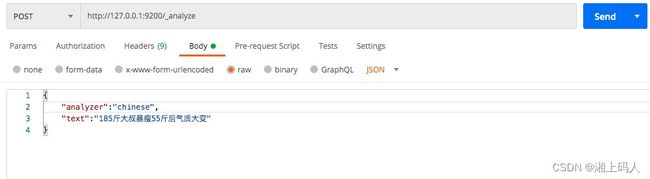
Elasticsearch自带中文分词只是将句子分成单个的字,满足不了中文分词的需求。
{
"tokens": [
{
"token": "185",
"start_offset": 0,
"end_offset": 3,
"type": "<NUM>",
"position": 0
},
{
"token": "斤",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "大",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "叔",
"start_offset": 5,
"end_offset": 6,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "暴",
"start_offset": 6,
"end_offset": 7,
"type": "<IDEOGRAPHIC>",
"position": 4
},
{
"token": "瘦",
"start_offset": 7,
"end_offset": 8,
"type": "<IDEOGRAPHIC>",
"position": 5
},
{
"token": "55",
"start_offset": 8,
"end_offset": 10,
"type": "<NUM>",
"position": 6
},
{
"token": "斤",
"start_offset": 10,
"end_offset": 11,
"type": "<IDEOGRAPHIC>",
"position": 7
},
{
"token": "后",
"start_offset": 11,
"end_offset": 12,
"type": "<IDEOGRAPHIC>",
"position": 8
},
{
"token": "气",
"start_offset": 12,
"end_offset": 13,
"type": "<IDEOGRAPHIC>",
"position": 9
},
{
"token": "质",
"start_offset": 13,
"end_offset": 14,
"type": "<IDEOGRAPHIC>",
"position": 10
},
{
"token": "大",
"start_offset": 14,
"end_offset": 15,
"type": "<IDEOGRAPHIC>",
"position": 11
},
{
"token": "变",
"start_offset": 15,
"end_offset": 16,
"type": "<IDEOGRAPHIC>",
"position": 12
}
]
}
7.2 IK分词器
IK分词是一款相对简单的中文分词器,应用简单,比较流行,当前最新版本是v8.2.3。
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v8.2.3,下载elasticsearch-analysis-ik-8.2.3.zip,解压并将文件名更新成ik,放到elasticsearch/plugins目录下,重启elasticsearch。
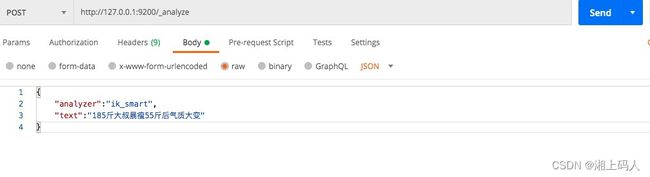
IK提供了两个分词算法ik_smart、ik_max_word,ik_smart为最小切分,ik_max_word是最细颗粒度划分。
ik_smart最小切分:
{
"tokens": [
{
"token": "185斤",
"start_offset": 0,
"end_offset": 4,
"type": "TYPE_CQUAN",
"position": 0
},
{
"token": "大叔",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 1
},
{
"token": "暴",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 2
},
{
"token": "瘦",
"start_offset": 7,
"end_offset": 8,
"type": "CN_CHAR",
"position": 3
},
{
"token": "55斤",
"start_offset": 8,
"end_offset": 11,
"type": "TYPE_CQUAN",
"position": 4
},
{
"token": "后",
"start_offset": 11,
"end_offset": 12,
"type": "CN_CHAR",
"position": 5
},
{
"token": "气质",
"start_offset": 12,
"end_offset": 14,
"type": "CN_WORD",
"position": 6
},
{
"token": "大变",
"start_offset": 14,
"end_offset": 16,
"type": "CN_WORD",
"position": 7
}
]
}
ik_max_word最细颗粒度划分
{
"tokens": [
{
"token": "185",
"start_offset": 0,
"end_offset": 3,
"type": "ARABIC",
"position": 0
},
{
"token": "斤",
"start_offset": 3,
"end_offset": 4,
"type": "COUNT",
"position": 1
},
{
"token": "大叔",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 2
},
{
"token": "暴",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 3
},
{
"token": "瘦",
"start_offset": 7,
"end_offset": 8,
"type": "CN_CHAR",
"position": 4
},
{
"token": "55",
"start_offset": 8,
"end_offset": 10,
"type": "ARABIC",
"position": 5
},
{
"token": "斤",
"start_offset": 10,
"end_offset": 11,
"type": "COUNT",
"position": 6
},
{
"token": "后",
"start_offset": 11,
"end_offset": 12,
"type": "CN_CHAR",
"position": 7
},
{
"token": "气质",
"start_offset": 12,
"end_offset": 14,
"type": "CN_WORD",
"position": 8
},
{
"token": "大变",
"start_offset": 14,
"end_offset": 16,
"type": "CN_WORD",
"position": 9
}
]
}
7.2 自定义分词
1.在elasticsearch/plugins/ik/config目录下新建ylup.dic文件,输入:海普优然科技公司
2.修改ik/config目录下的,IKAnalyzer.cfg.xml文件
<properties>
<comment>IK Analyzer 扩展配置comment>
<!‐‐这里配置自定义的扩展字典 ‐‐>
<entry key="ext_dict">ylup.dicentry>
<!‐‐这里停止自定义的扩展字典‐‐>
<entry key="ext_stopwords">entry>
properties>
3.重启elasticsearch,即可发现将“海普优然科技公司”视为一个词。