万字解析MySQL索引原理——InnoDB索引结构与读取
1. 前言
以下对InnoDB索引的结构与读取方式进行了整理,分析MySQL索引使SQL语句执行加速的原理,针对使用InnoDB 5.6版本的MySQL。
2. InnoDB索引结构与读取方式总结
InnoDB索引结构与读取方式总结可总结如下:
-
InnoDB的索引使用B+树结构,非叶子节点保存指向非叶子节点或叶子节点的指针,在叶子节点保存真正的数据,叶子节点在最低的同一层级,相互之间形成了双向链表。
-
B+树中的记录是有序的,在B+树中查找一条记录的时间复杂度为O(logbn),b为B+树的内部节点的最大子节点数量。
-
InnoDB在磁盘和内存之间一次传输多少数据的单位为页,页大小默认为16KB。
-
InnoDB的索引分为聚簇索引与二级索引,聚簇索引中包含了整行的数据,二级索引包含二级索引对应的列及聚簇索引的键。
-
在MySQL 8.0之前的版本,索引记录以升序存储;在MySQL 8.0之后的版本中,索引记录支持以升序或降序存储。
-
InnoDB的索引B+树的叶子节点保存的数据格式为页,页的文件页头中包含了指向上一页与下一页的指针,即页之间构成了双向链表结构。
-
一页至少包含两条记录,记录的额外字节(记录头)中包含指向页中下一条记录的指针,即一页中的记录构成了单向链表。
-
页中的页目录使得对页中的记录进行搜索时,可以进行二分查找。
-
索引键前缀的长度默认值为767个字节,索引键前缀的长度及记录中可变长度列存储位置由行格式及innodb_large_prefix变量决定。
-
页分裂与页合并发生的时机与MERGE_THRESHOLD参数值有关,频繁发生时可能对性能产生影响。
-
Buffer Pool与Change Buffer分别对索引的读/写操作进行缓存,可以减少I/O次数,提高效率。
3. 索引的实现位置与作用
参考《High Performance MySQL, 3rd Edition》。
索引在存储引擎层实现,不是在MySQL Server层实现。
索引的作用如下:
-
索引可以减少MySQL服务器需要检查的数据量;
-
索引帮助MySQL服务器避免排序及使用临时表;
-
索引将随机I/O转换为顺序I/O。
4. InnoDb索引结构
4.1. InnoDb索引使用B+树还是B树
在MySQL 5.6参考手册中,关于索引结构的表述均使用“B-tree”。参考MySQL内部手册 https://dev.mysql.com/doc/internals/en/innodb-fil-header.html ,InnoDB索引使用的结构为B+树。
4.2. MySQL如何使用索引
参考 https://dev.mysql.com/doc/refman/5.6/en/mysql-indexes.html 。
索引用于快速查找具有特定列值的行。如果没有索引,MySQL必须从第一行开始,通读整个表以找到相关的行。表越大,花费越多。如果表中有相关列的索引,MySQL可以快速确定要在数据文件中间查找的位置,而不必查看所有数据。这比顺序读取每一行要快得多。
大多数MySQL索引(PRIMARY KEY,UNIQUE,INDEX和FULLTEXT)存储在B+树中。
4.3. B+树
参考 https://en.m.wikipedia.org/wiki/B%2B_tree 、 https://en.wikibooks.org/wiki/Algorithm_Implementation/Trees/B%2B_tree 、 https://en.m.wikipedia.org/wiki/B-tree。
B+树是平衡的N叉树,每个节点的子节点数量是可变的,通常数量很大。B+树由根节点、内部节点和叶子节点组成。根节点可以是叶子节点,也可以具有两个或更多叶子节点。
B+树是B树的变体。在B+树中,所有数据都保存在叶子节点中。内部节点仅包含key和树指针。所有叶子处于相同的最低水平。叶子节点也作为链表链接在一起,便于范围查询。
B+树中的数据是有序的。B+树的主要价值在于存储数据,以便在面向块的存储环境(尤其是文件系统)中进行有效的检索。B+树具有很高的扇出度(指向节点中子节点的指针数量,通常为100或更多),这减少了在树中找到一个元素所需的I/O操作数量。
B+树的内部节点的最大子节点数量,称为order或分支因子(branching factor, b)。
对于order为b的B+树,插入一条记录的时间复杂度为O(logbn)。
查询一条记录的时间复杂度为O(logbn)。
使用范围内出现的k个元素执行范围查询时间复杂度为O(logbn + k)。
B+树的示例如下所示:
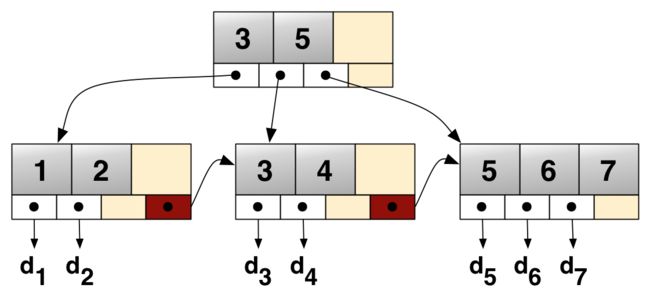
4.4. 聚簇索引(Clustered Index)与二级索引(Secondary Index)
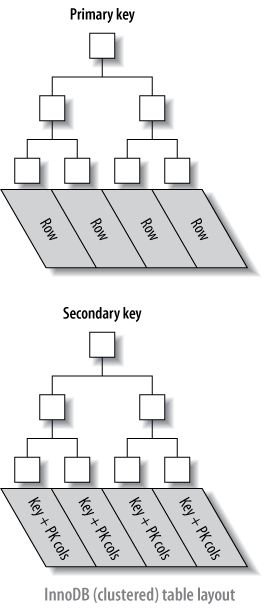
代表整个表的B+树索引称为聚簇索引,根据主键列进行组织。聚簇索引数据结构的节点包含该行中所有列的值。二级索引结构的节点包含索引列和主键列的值。
参考 https://dev.mysql.com/doc/refman/5.6/en/innodb-index-types.html 。
每个InnoDB表都有一个称为聚簇索引的特殊索引,其中存储了行的数据。 通常,聚簇索引与主键的含义相同。为了在查询、插入或其他数据库操作中获得最佳性能,必须了解InnoDB如何使用聚簇索引对每个表的最常见的查找和DML操作进行优化。
当在数据库表定义了主键时,InnoDB会将其作为聚簇索引使用。请为创建的数据库表都定义主键。如果数据库表没有逻辑上唯一且非空的列或一组列,请增加一个新的自增长且值会自动填充的列。
如果没有为表定义主键,MySQL会找到第一个所有键列都非空的唯一索引,InnoDB会将它用作聚簇索引。
如果表没有主键或合适的唯一索引,InnoDB会在包含行ID值的合成列内部生成名为GEN_CLUST_INDEX的隐藏聚簇索引。行按InnoDB分配给此类表中的行的ID排序。行ID是一个6字节的字段,随着新行的插入而单向增加。因此,通过行ID排序的列在物理上按插入顺序排列。
除聚簇索引之外的所有索引都称为二级索引。 在InnoDB中,二级索引中的每条记录都包含该行的主键列以及二级索引指定的列。 InnoDB使用此主键值来搜索聚簇索引中的行。
关于聚簇索引与二级索引中保存的内容,也可参考 https://dev.mysql.com/doc/refman/5.6/en/innodb-row-format.html 。
参考《High Performance MySQL, 3rd Edition》关于聚簇索引与二级索引的示意图:
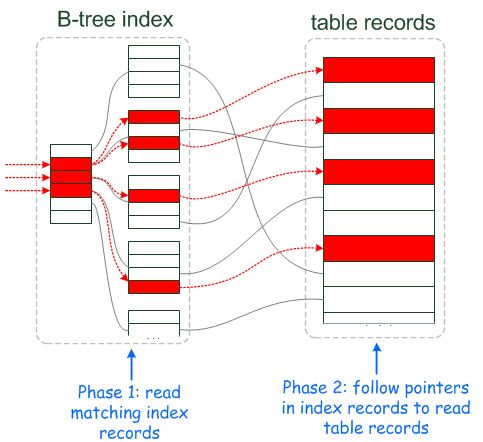
以下为通过二级索引读取对应的聚簇索引,即行数据的示意图,图片来源 https://mariadb.com/kb/en/index-condition-pushdown/+image/index-access-2phases :
4.5. 索引的顺序
4.5.1. MySQL 8.0之前的版本
在MySQL 8.0之前的版本中,索引记录以升序存储。
参考 https://dev.mysql.com/doc/refman/5.6/en/create-index.html (5.7描述相同)。
创建索引时可以ASC或DESC结尾。这些关键字可用于将来的扩展,以指定升序或降序索引值存储。目前,它们已被解析但被忽略;索引值始终以升序存储。
4.5.2. MySQL 8.0之后的版本
在MySQL 8.0之后的版本中,索引记录支持以升序或降序存储。
参考 https://dev.mysql.com/doc/refman/8.0/en/create-index.html 。
创建索引时可以ASC或DESC结尾,以指定索引值是以升序还是降序存储。如果未指定,则默认值为升序。
参考 https://dev.mysql.com/doc/refman/8.0/en/descending-indexes.html 。
MySQL(8.0)支持降序索引(descending index),索引定义中的DESC不再被忽略,会导致键值以降序存储。以前,索引可以以相反的顺序进行扫描,但会降低性能。降序索引可以按向前的顺序进行扫描,这样效率更高。
使用降序索引后,使得当最有效的扫描顺序混合了某些升序列和其他降序列时,优化器也能使用多列索引(multiple-column indexes),即联合索引(composite indexes)。
参考 https://dev.mysql.com/doc/relnotes/mysql/8.0/en/news-8-0-1.html 。
MySQL从8.0.1版本开始支持降序索引。
4.6. InnoDB索引B+树结构
4.6.1. 页(page)
参考 https://dev.mysql.com/doc/refman/5.6/en/glossary.html#glos_page 。
页是表示InnoDB在磁盘(数据文件)和内存(缓冲池,buffer pool)之间一次传输多少数据的单位。 一个页可以包含一行或多行,取决于每一行中的数据量。如果一行不能完全容纳在单个页中,则InnoDB会设置其他指针式数据结构,以便有关该行的信息可以存储在一页中。
参考 https://dev.mysql.com/doc/internals/en/innodb-page-structure.html 。
InnoDB将所有记录存储在固定大小的单位内,该单位通常称为页,有时称为块。
4.6.2. 页大小
参考 https://dev.mysql.com/doc/refman/5.6/en/glossary.html#glos_page_size 。
对于MySQL 5.5及以下版本,每个InnoDB页的大小固定为16 KB。该值表示一个平衡:足够大以容纳大多数行的数据,但足够小以最小化将不需要的数据传输到内存的性能开销。其他值未经测试或支持。
从MySQL 5.6开始,InnoDB实例的页大小可以是4KB,8KB或16KB,由innodb_page_size配置选项控制。从MySQL 5.7.6开始,InnoDB还支持32KB和64KB页大小。对于32KB和64KB页大小,不支持ROW_FORMAT = COMPRESSED,最大记录大小为16KB。
页大小在创建MySQL实例时设置,此后保持不变。相同的页大小适用于所有InnoDB表空间,包括system tablespace,file-per-table tablespaces,以及general tablespaces。
较小的页大小可以帮助使用块大小较小的存储设备提高性能。
参考 https://dev.mysql.com/doc/refman/5.6/en/innodb-parameters.html#sysvar_innodb_page_size 。
innodb_page_size系统变量用于指定InnoDB表空间页大小。
innodb_page_size只能在初始化MySQL实例之前进行配置,之后不能进行更改。如果未指定任何值,则使用默认页大小初始化实例。
innodb_page_size默认值为16KB。
4.6.3. 页的物理结构
以下描述页在磁盘存储时的物理结构。
参考 https://dev.mysql.com/doc/internals/en/innodb-page-overview.html 。
InnoDB页包含以下7个部分:
| 内容 |
|---|
| Fil Header |
| Page Header |
| Infimum + Supremum Records |
| User Records |
| Free Space |
| Page Directory |
| Fil Trailer |
Fil Header可以称为“File Page Header”。
4.6.3.1. 文件页头(Fil Header)
文件页头中包含了指向上一页与下一页的指针,即页之间构成了双向链表结构。
参考 https://dev.mysql.com/doc/internals/en/innodb-fil-header.html 。
文件页头中包含8个部分,其中FIL_PAGE_PREV为按键顺序的上一页的偏移量,FIL_PAGE_NEXT为按键顺序的下一页的偏移量。
FIL_PAGE_PREV与FIL_PAGE_NEXT是页的后退和前进的指针。 以下为两层B+树的示例,说明上述指针。
--------
- root -
--------
|
----------------------
| |
| |
-------- --------
- leaf - <--> - leaf -
-------- --------
B+树的根页中的条目指向叶子页(如上图中的竖线“|”),叶子页也可以互相指向(如上图中水平双向指针“<–>”),这个特性使InnoDB可以在叶子页之间导航,不必返回到根级别。
4.6.3.2. 页面头(Page Header)
参考 https://dev.mysql.com/doc/internals/en/innodb-page-header.html 。
页面头中包含名为“PAGE_N_DIR_SLOTS”的部分,大小为2字节,代表了页目录(Page Directory)中目录插槽的数量,初始值为2(下确界/上确界,即 Infimum/Supremum Records初始时分别对应一个插槽)。
名为“PAGE_BTR_SEG_LEAF”的部分,为B+树中的叶子页的文件段头。
名为“PAGE_BTR_SEG_TOP”的部分,为B+树中的非叶子页的文件段头。
PAGE_BTR_SEG_LEAF与PAGE_BTR_SEG_TOP包含索引节点文件段的信息:表空间ID(space ID)、页编号(page number)、字节偏移(byte offset)。
4.6.3.3. 下确界/上确界(Infimum/Supremum Records)
参考 https://dev.mysql.com/doc/internals/en/innodb-infimum-and-supremum-records.html 。
“Infimum”和“Supremum”是数学术语,指有序集合的外边界。下确界(infimum )是最大下界(GLB,Greatest Lower Bound),小于可能的最小键值。上确界是最小上限(LUB,Least Upper Bound),大于可能的最大键值。
首次创建索引时,InnoDB会在根页中自动设置一个下确界记录和一个上确界记录,并且永远不会删除。它们在导航时是有用的屏障,因此“获取前一个”操作不会通过开头,“获取下一个操作”不会通过结尾。同样,下确界可以是临时记录锁定的虚拟目标。
下确界记录和上确界记录可以视为索引页开销的一部分。最初它们都存在于根页上,随着索引的增长,下确界记录将存在于第一或最小叶子页上,下确界记录将存在于最后或最大键页上。
4.6.3.4. 用户记录(User Records)
用户记录中保存了用户插入数据库表的各行的记录数据,记录在存储时在物理上没有按照键的顺序排序,记录获取后的逻辑结构中按照键的顺序排序。
参考 https://dev.mysql.com/doc/internals/en/innodb-user-records.html 。
在页的用户记录部分中,可以找到用户插入的所有记录(record)。
InnoDB不想根据B树的键顺序插入新行(这会涉及到大量数据转移,代价很大),因此 InnoDB会在现有行的结尾之后(在可用空间部分的顶部)或已删除行剩余的空间插入新行。
根据B+树的定义,记录必须按键值顺序访问 ,因此每个记录中都有一个记录指针(Extra Bytes中的“next”字段,可参考后续对于记录的描述部分) ,该指针指向键顺序中的下一个记录,即 记录是单向链表 。 InnoDB在搜索时可以按键顺序访问行。
4.6.3.5. 页目录(Page Directory)
页目录使得对页中的记录进行搜索时,可以进行二分查找。对比顺序链表查找元素的时间复杂度O(n),提高到接近O(logn)(实际情况需要更复杂的分析与计算)。
参考 https://dev.mysql.com/doc/internals/en/innodb-page-directory.html 。
页的页目录部分具有可变数量的记录指针。有时记录指针称为“插槽”或“目录插槽”。与其他DBMS不同,InnoDB不是每个页中的每个记录上都有一个插槽。InnoDB保留了一个稀疏目录。在满的页中,每六个记录有一个插槽。
插槽可以跟踪记录的逻辑顺序(键的排序,不是按堆位置的顺序)。因此,如果记录为“A”“B”“F”“D”,则插槽将为(指向“A”的指针)(指向“B”的指针)(指向“D”的指针)(指向“F”的指针)。因为插槽是按键顺序排列的,并且每个插槽都有固定的大小,因此 很容易通过插槽对页上的记录进行二分查找。
由于页目录没有为每个记录提供一个插槽,因此二分查找只能给出一个大概的位置,之后InnoDB必须跟随“下一个”记录指针。InnoDB的“稀疏插槽”策略也占用记录的“额外字节”部分中的n_owned字段:n_owned表示由于之前的记录没有自己的插槽,当前记录已通过了多少个记录。(即n_owned代表了有插槽的当前记录,及其之前没有插槽的记录的总记录数)
4.6.4. 行格式
参考 https://dev.mysql.com/doc/refman/5.6/en/innodb-row-format.html 。
表的行格式决定了行的物理存储方式,会影响查询和DML操作的性能。
InnoDB存储引擎支持四种行格式:REDUNDANT,COMPACT,DYNAMIC和COMPRESSED(冗余,紧凑,动态和压缩)。
InnoDB表的默认行格式为COMPACT。
可以使用CREATE TABLE或ALTER TABLE语句中的ROW_FORMAT表选项显式定义表的行格式。示例如下:
CREATE TABLE t1 (c1 INT) ROW_FORMAT=COMPACT;
要创建使用DYNAMIC或COMPRESSED行格式的表,必须将innodb_file_format变量设置为Barracuda,并且必须启用innodb_file_per_table变量。如果未启用innodb_strict_mode,则将使用默认的COMPACT行格式创建InnoDB表。
为了查看表的行格式,可使用“SHOW TABLE STATUS”或查询INFORMATION_SCHEMA.INNODB_TABLES表。示例如下:
SHOW TABLE STATUS IN test1;
SELECT NAME, ROW_FORMAT FROM INFORMATION_SCHEMA.INNODB_SYS_TABLES WHERE NAME='test1/t1';
4.6.5. 记录的物理结构
以下描述记录在磁盘存储时的物理结构。
参考 https://dev.mysql.com/doc/internals/en/innodb-overview.html 。
关于“原点”(Origin)的说明:
记录的“原点”(Origin)或“零点”(Zero Point)是字段内容(Field Contents)的第一个字节,不是字段开始偏移量(Field Start Offsets)的第一个字节。如果有指向记录的指针,则该指针指向“原点”(Origin)。因此记录的前两部分(Field Start Offsets、Extra Bytes)通过对指针进行减操作来寻址,只有记录的第三部分(Field Contents)通过对指针进行加操作来寻址。
记录的物理结构包括以下三部分:
- 字段起始偏移量(Field Start Offsets)
参考 https://dev.mysql.com/doc/internals/en/innodb-field-start-offsets.html 。
字段起始偏移量包含了“字段开始的位置”信息的数字列表,其中每个条目都是相对于下一个字段开始处相对“原点”(Origin)的位置。条目的顺序是反的,即第一个字段的偏移量在列表的末尾。
- 额外字节(Extra Bytes)
参考 https://dev.mysql.com/doc/internals/en/innodb-extra-bytes.html 。
额外字节是一个固定的6字节头。(参考 https://dev.mysql.com/doc/refman/5.6/en/innodb-row-format.html ,REDUNDANT行格式的记录头为6字节)
在记录头中包含名为“deleted_flag”,大小为1比特,为1时代表记录已被删除。
在记录头中包含名为“n_owned”,大小为4比特,代表该记录拥有的记录数(在页目录中会使用)。
在记录头中包含名为“next”的部分,大小为2字节,为 指向页中下一条记录的指针 (对应前文“记录是单向链表”)。
- 字段内容(Field Contents)
参考 https://dev.mysql.com/doc/internals/en/innodb-field-contents.html 。
记录的“字段内容”部分包含所有数据。字段按照定义顺序存储。
字段之间没有标记(marker),并且记录的末尾没有标记或填充符(filler)。
InnoDB在开始时会自动添加三个“系统列”(“system columns”)以进行内部管理。这些系统列是行ID(row ID),事务ID(transaction ID)和回滚指针(rollback pointer),它们的值现在不再重要,可视为三个黑盒。
4.6.6. COMPACT行格式的记录结构
参考 https://dev.mysql.com/doc/refman/5.6/en/innodb-row-format.html 。
COMPACT行格式的部分存储特征如下:
每个索引记录都包含一个5字节的记录头,该记录头之前可以有一个可变长度的头。记录头用于将连续的记录链接在一起,并用于行级锁定。
记录头后跟着非NULL列的数据内容。
聚簇索引中的记录包含所有用户定义列的字段。还有一个6字节的事务ID字段(transaction ID)和一个7字节的滚动指针字段(roll pointer)。
每个二级索引记录中,包含在聚簇索引定义的,不在二级索引中的所有主键列。
以下参考 https://blog.jcole.us/2013/01/10/the-physical-structure-of-records-in-innodb/ ,图片来源 https://github.com/jeremycole/innodb_diagrams 。
4.6.6.1. 聚簇索引-叶子(leaf)页记录格式
聚簇索引-叶子页记录格式示例如下所示:
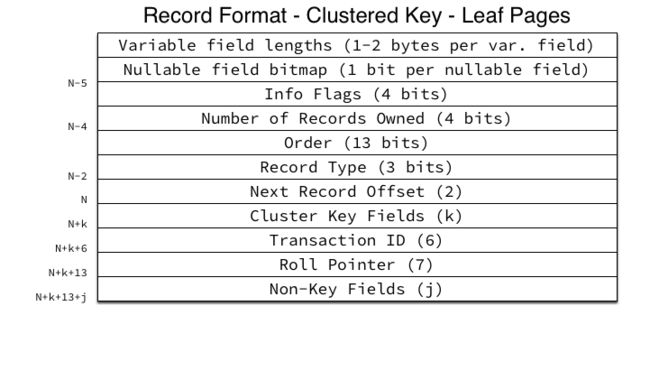
聚簇索引-叶子页记录的Cluster Key Fields保存了聚簇键字段。
聚簇索引-叶子页记录的Non-Key Fields保存所有非索引键字段(Non-Key Fields,即所有非PRIMARY KEY字段的实际行数据)。
4.6.6.2. 聚簇索引-非叶子(non-leaf)页记录格式
聚簇索引-非叶子页记录格式示例如下所示:
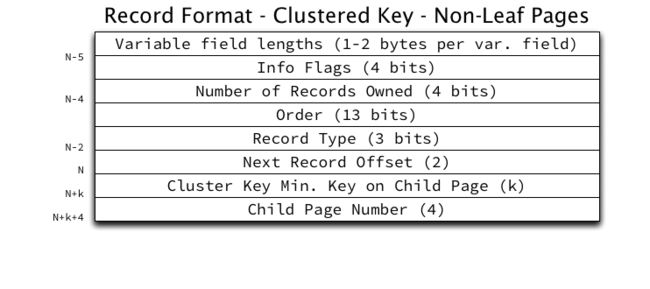
聚簇索引-非叶子页记录的Cluster Key Min保存了孩子页中键的最小值。
B+树的非叶子节点不保存实际的数据,因此聚簇索引-非叶子页记录不包含非索引键字段,在Child Page Number中保存了孩子页的序号(指向孩子页的指针)。
4.6.6.3. 二级索引-叶子页记录格式
二级索引-叶子页记录格式示例如下所示:

二级索引-叶子页记录的Secondary Key Fields保存了二级索引键字段。
二级索引-叶子页记录的Cluster Key Fields保存了二级索引键对应的聚簇索引键字段。
4.6.6.4. 二级索引-非叶子页记录格式
二级索引-非叶子页记录格式示例如下所示:

二级索引-非叶子页记录的Secondary Key Min保存了孩子页中键的最小值。
二级索引-非叶子页记录的Child Page Number保存了孩子页的序号(指向孩子页的指针)。
4.6.7. InnoDB索引B+树逻辑结构
以下描述页被读取到内存后的逻辑结构。
参考 https://blog.jcole.us/2013/01/10/btree-index-structures-in-innodb/ 。
页被称为“叶子”页或“非叶子”页(在某些情况下也称为“内部”或“节点”页)。叶子页包含实际的行数据。非叶子页仅包含指向其他非叶子页或叶子页的指针。树是平衡的,因此树的所有分支具有相同的深度。
InnoDB为树中的每个页分配一个“级别”:叶子页被分配为级别0,级别在树上递增。根页的级别基于树的深度。
对于叶子页和非叶子页,每个记录(包括下确界和上确界系统记录)都包含“下一条记录”指针,该指针存储下一条记录(在页内)的偏移量。链表从下确界开始, 并按键升序链接所有记录 ,在上确界终止。记录在页内没有进行物理排序(插入时会占用任意可用空间);它们的唯一顺序源自它们在链表中的位置。
4.6.7.1. 叶子页
叶子页的简化示例如下所示:
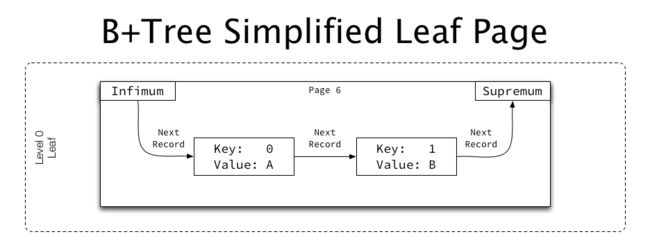
叶子页包含非索引键值,作为每个记录中包含的“数据”的一部分。
4.6.7.2. 非叶子页
非叶子页的简化示例如下所示:
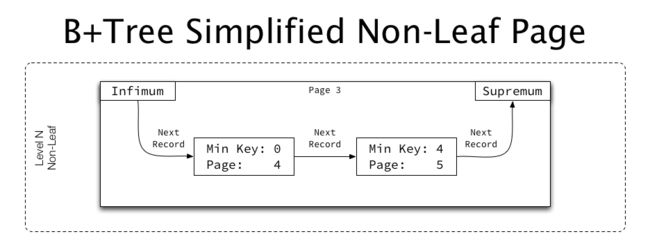
非叶子页的结构与叶子页类似,但非叶子节点不包含非索引键字段(Non-Key Fields),保存的“数据”是孩子页的页编号。
非叶子页也没有保存具体的键,而是保存孩子页中最小的键值。
4.6.7.3. B+树层级示例
InnoDB索引B+树层级简化示例如下所示:
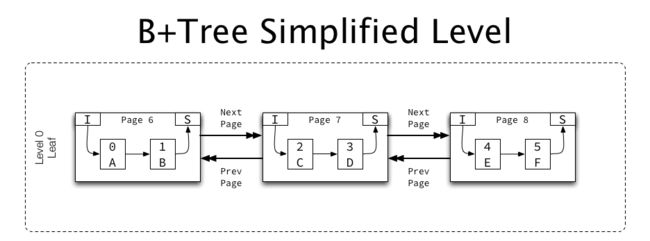
大多数索引包含多个页,因此多个页按升序和降序链接在一起。
每个页(在FIL header中)都包含指向“上一页”和“下一页”的指针,对于索引页,它们用于形成同一级别的页的双向链表。
4.6.7.4. B+树结构示例
InnoDB索引B+树结构简化示例如下所示:
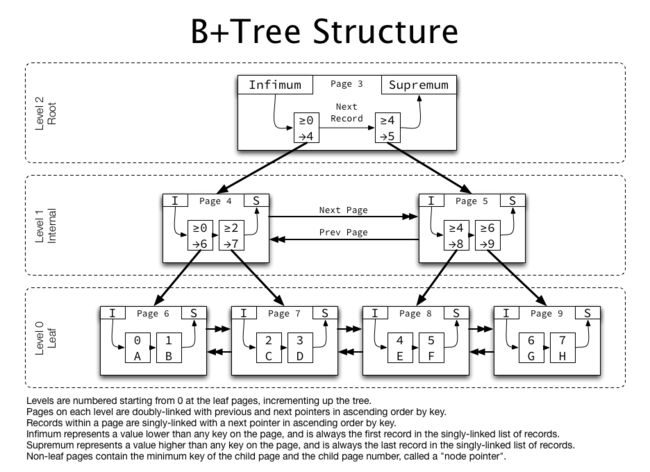
每个级别的所有页都相互双向链接,并且在每个页内,记录按升序单向链接。非叶子页包含“指针”(包含孩子页编号),而不是非索引键的行数据。
4.6.8. 页目录结构示例
参考 https://blog.jcole.us/2013/01/14/efficiently-traversing-innodb-btrees-with-the-page-directory/ 。
4.6.8.1. 页目录的用意
索引页中的所有记录都按升序在单向链表中链接在一起。 对于可能包含数百条记录的页,遍历链表的代价很大:必须比较每个记录的键,并且这需要在B+树的每个级别上进行,直到在叶子页找到要查找的记录为止。
页目录使用以下方法,极大地优化了以上搜索场景:提供一个固定宽度的数据结构,该结构具有按顺序指向每4-8条记录中的1条的直接指针。可用于对每个页中的记录进行传统的二分查找。由于页目录实际上是一个数组,当记录按升序链接时,也可以按升序或降序遍历。
4.6.8.2. 页目录物理结构
页目录物理结构示例如下:

插槽数量(页目录长度)在页面头的第一个字段中指定。页目录始终包含一个下确界和上确界系统记录的条目(因此最小大小为2个条目,即插槽),并且可能包含0个或多个其他条目,每4-8个系统记录对应一个插槽。
当某条记录在页目录中代表了另一条记录时,则称为某条记录“拥有”(“own”)另一条记录。页目录中的每个条目都“拥有”该页目录中的上一个条目之间的记录,直到其自身为止。每个记录“拥有”的记录数存储在每个记录之前的记录头中。
4.6.8.3. 页目录逻辑结构
页目录逻辑结构如下图下半部分所示(包含一页中键值从0至23的24个记录),红色虚线代表了页目录中的插槽与页中记录的对应关系:
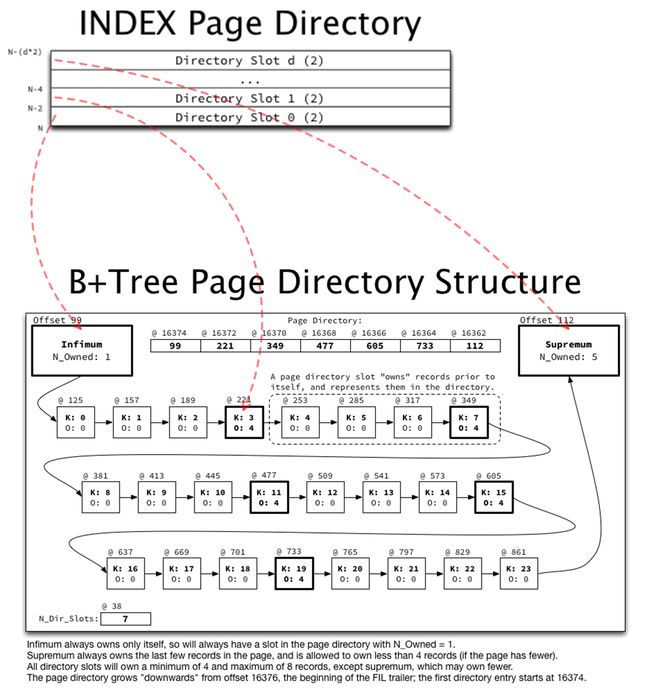
记录被单向链接,从下确界记录,到上确界记录,再到用户记录。
部分记录会被输入到页目录中,在图中以粗体显示,并在其顶部的页目录数组中注明其偏移量。
4.6.9. B+树树高与记录数
参考 https://blog.jcole.us/2013/01/10/btree-index-structures-in-innodb/ 。
以下为B+树索引效率的示例。
假设记录的填充是完美的(每页都满了,在实践中永远不会发生,但是对于讨论很有用)。在示例中,InnoDB中针对简单表的B+树索引能够在每个叶子页存储468条记录,或者在每个非叶子页存储1203条记录。 在以上条件下,索引B+树在给定的树高下可以是以下大小的最大值:
| 树高 | 非叶子页数量 | 叶子页数量 | 行数 | 大小(字节数) |
|---|---|---|---|---|
| 1 | 0 | 1 | 468 | 16.0 KiB |
| 2 | 1 | 1203 | > 563 thousand | 18.8 MiB |
| 3 | 1204 | 1447209 | > 677 million | 22.1 GiB |
| 4 | 1448413 | 1740992427 | > 814 billion | 25.9 TiB |
4.7. InnoDB限制
关于InnoDB限制的表、索引等限制,参考 https://dev.mysql.com/doc/refman/5.6/en/innodb-limits.html 。
- 列数量限制
一个表可以包含的最大列数量为1017(早期限制为1000,从MySQL 5.6.9开始增加到上述数量)。
- 二级索引数量限制
一个表可以包含的最大二级索引数量为64。
- 索引键前缀长度限制
默认情况下,索引键前缀(index key prefix)长度限制为767个字节。例如,假设使用utf8mb3字符集且每个字符最多3个字节,则在TEXT或VARCHAR类型的列使用超过255个字符的列前缀索引可能会达到此限制。启用innodb_large_prefix配置选项后,对于使用DYNAMIC或COMPRESSED行格式的InnoDB表,索引键前缀长度限制将提高到3072字节。
如果在创建MySQL实例时通过指定innodb_page_size选项将InnoDB页大小减小为8KB或4KB,则基于16KB页大小的3072个字节的限制,将按比例减小索引键的最大长度。即当页大小为8KB时,最大索引键长度为1536字节;当页大小为4KB时,最大索引键长度为768字节。
适用于索引键前缀的限制也适用于全列索引键(full-column index key)。
- 多列索引列数量限制
一个多列索引可以包含的最大列数量为16。
- 行大小限制
除页外(off-page)存储的可变长度列(variable-length column)外,最大行大小略小于页大小的一半。对于默认页大小16KB,最大行大小约为8000字节。如果在创建MySQL实例时通过指定innodb_page_size选项来减小页大小,则对于大小为8KB的页,最大行大小为4000字节,对于大小为4KB的页,最大行大小为2000字节。LONGBLOB和LONGTEXT列必须小于4GB,包括BLOB和TEXT列在内的总行大小必须小于4GB。
如果一行的长度少于一页的一半,则该行全部存储在当前页内。如果一行的长度超过半页,则将选择可变长度的列在外部的页外存储,直到该行适合半页为止。
根据以上限制可知, 一个InnoDB索引页中,至少会包含两条记录。
4.8. 记录中可变长度列存储位置
参考 https://dev.mysql.com/doc/refman/5.6/en/innodb-row-format.html 。
将列值存储在B+树索引节点中的规则包含例外情况,即可变长度列。可变长度列太长,无法容纳在B+树页上,而是存储在单独分配的磁盘页中,这些磁盘页称为溢出页(overflow page)。这些列称为页外列(off-page column)。页外列的值存储在溢出页的单向链表中,每个这样的列都有其自己的一个或多个溢出页的列表。根据列的长度,可变长度列值的全部或前缀存储在B+树中,以避免浪费存储空间并不得不读取单独的页。
- COMPACT与REDUNDANT行格式
使用COMPACT或REDUNDANT行格式时,将可变长度列保存在外部的页外存储,InnoDB在当前行中存储前768个字节,剩余部分存储在外部的溢出页中。每个此类列都有其自己的溢出页列表。长度为768字节的前缀附带一个20字节的值,该值存储列的真实长度,并指向溢出列表中存储的该列的剩余部分。
如果列值的长度小于或等于768个字节,则不使用溢出页,并且由于该值完全存储在B+树节点中,因此可以节省一些I/O。这对于较短的BLOB列值非常有效,但是可能导致B+树节点填充较多的数据而不是键值,从而降低效率。具有很多BLOB列的表可能导致B+树节点变得太满,并且包含的行太少,这使得整个索引的效率变低,相比行的长度更短或列值存储在页外的情况。
- DYNAMIC与COMPRESSED行格式
对于使用DYNAMIC行格式的表,InnoDB可以完全在页外存储长度很长的可变长度列值(对于VARCHAR,VARBINARY,BLOB和TEXT类型),聚簇索引记录仅包含指向溢出页的20字节指针。对于固定长度字段,若长度大于或等于768字节,会被编码为可变长度字段。
列是否存储在页外取决于页大小和行的总大小。当一行太长时,将选择最长的列进行页外存储,直到聚簇索引记录适合B+树页为止。小于或等于40个字节的TEXT和BLOB列存储在行中。
DYNAMIC和COMPRESSED行格式支持最大3072字节的索引键前缀。该功能由innodb_large_prefix变量控制,该变量默认情况下被禁用。
关于记录中可变长度列存储位置,也可参考 https://dev.mysql.com/doc/refman/5.6/en/innodb-file-space.html 。
4.9. 记录中的NULL列
- REDUNDANT行格式
当使用REDUNDANT行格式时,记录中包含一个指向该记录的每个字段的指针。如果记录中字段的总长度小于128个字节,则指针为1个字节;否则为两个字节。指针数组称为记录目录(record directory)。指针指向的区域是记录的数据部分。
NULL值在记录目录中保留一个或两个字节。当存储在可变长度列中时,NULL值在记录的数据部分中保留零字节。对于固定长度的列,该列的固定长度保留在记录的数据部分。为NULL值保留固定空间允许将列从NULL值更新为非NULL值,而不会引起索引页碎片。
- COMPACT、DYNAMIC与COMPRESSED行格式
当使用COMPACT、DYNAMIC或COMPRESSED行格式时,记录头的可变长度部分包含一个用于指示NULL列的位向量(bit vector)。如果索引中可为NULL的列数为N,则位向量占用CEILING(N/8)个字节(CEILING函数为向上舍入)。NULL列不占用此位向量以外的空间。记录头的可变长度部分还包含可变长度列的长度。每个长度占用一个或两个字节,取决于列的最大长度。如果索引中的所有列都不为NULL并且具有固定长度,那么记录头将没有可变长度部分。
4.10. 页分裂与页合并
参考 https://dev.mysql.com/doc/refman/5.6/en/index-page-merge-threshold.html 。
从MySQL 5.7.6开始,可以为索引页配置MERGE_THRESHOLD值。如果在删除行或通过UPDATE操作使行变短时,索引页的“页充满程度”(“page-full”)百分比低于MERGE_THRESHOLD值,则InnoDB会尝试将索引页与相邻的索引页合并。 MERGE_THRESHOLD的默认值为50(以前的硬编码值),最小值为1,最大值为50。
当索引页的“页充满程度”百分比低于50%(默认的MERGE_THRESHOLD设置)时,InnoDB会尝试将索引页与相邻页合并。如果两个页都接近50%充满,则页合并后可能会很快发生页分裂(page split)。如果页的合并与分裂行为频繁发生,则可能会对性能产生不利影响。
后续内容将对频繁页分裂对INSERT操作的影响进行对比验证。
5. InnoDB索引存储相关
5.1. file-per-table表空间
参考 https://dev.mysql.com/doc/refman/5.6/en/innodb-file-per-table-tablespaces.html 。
file-per-table空间包含单个InnoDB表的数据和索引,并存储在文件系统单独的数据文件中。
InnoDB默认在file-per-table表空间中创建表,由innodb_file_per_table变量控制,禁用innodb_file_per_table会导致InnoDB在系统表空间中创建表。
file-per-table表空间会创建在MySQL data目录的schema目录中的.ibd数据文件中。例如在名为“testdb”的schema中创建数据库表test_table,会在MySQL的data/testdb目录中创建test_table.ibd文件。
5.2. InnoDB索引物理结构
参考 https://dev.mysql.com/doc/refman/5.6/en/innodb-physical-structure.html 。
所有的InnoDB索引都是B+树,索引记录存储在树的叶子页中。索引页的默认大小为16KB。
可以在初始化MySQL实例之前设置innodb_page_size配置选项来定义MySQL实例中所有InnoDB表空间的页大小。定义实例的页大小后,只有在重新初始化实例时能够修改。支持的页大小为16KB,8KB和4KB。
5.3. InnoDB表元文件(.frm)
参考 https://dev.mysql.com/doc/refman/5.6/en/innodb-data-dictionary.html 、 https://dev.mysql.com/doc/refman/5.6/en/using-innodb-tables.html#innodb-frm-file 。
InnoDB数据字典包含用于跟踪对象(例如表,索引和表列)的元数据。
MySQL将表的数据字典信息存储在数据库目录中的.frm文件中。与其他MySQL存储引擎不同,InnoDB还将表在自身内部数据字段中的信息编码在系统表空间中。当MySQL删除表或数据库时,它将删除一个或多个.frm文件以及InnoDB数据字典中的相应条目。
6. InnoDB索引读取方式
6.1. Buffer Pool
Buffer Pool对索引的读操作进行缓存,可以减少I/O次数,提高效率。
参考 https://dev.mysql.com/doc/refman/5.6/en/innodb-buffer-pool.html 。
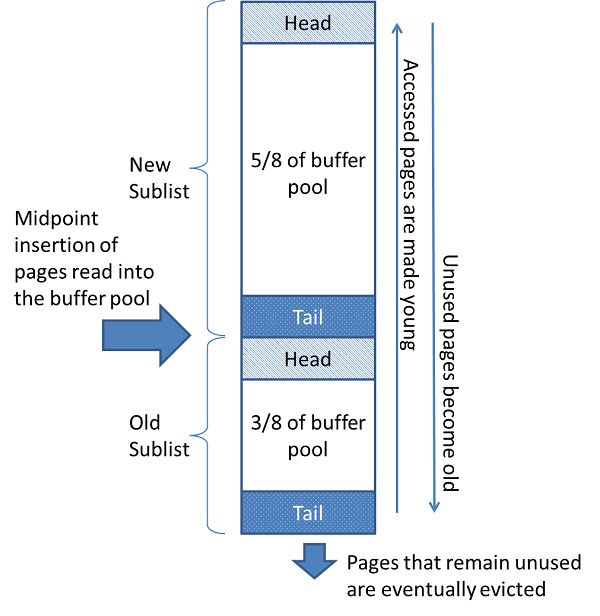
buffer pool是主内存中的一个区域,InnoDB在访问表和索引数据时会在其中进行缓存。buffer pool允许直接从内存中处理经常使用的数据,从而加快处理速度。在专用服务器上,通常将多达80%的物理内存分配给buffer pool。
为了提高大容量读取操作的效率,buffer pool被分为多个页,这些页可以潜在容纳多行。为了提高缓存管理的效率,buffer pool被实现为页的链表形式。很少使用的数据会从缓存中过期,使用LRU算法的变体。
参考 https://dev.mysql.com/doc/refman/5.6/en/innodb-buffer-pool-flushing.html 。
InnoDB在后台执行某些任务,包括从buffer pool中刷新脏页。 脏页是指已被修改但尚未写入磁盘数据文件的页。
Buffer Pool的示意图如下所示:
6.2. Change Buffer
Change Buffer对索引的写操作进行缓存,可以减少I/O次数,提高效率。
参考 https://dev.mysql.com/doc/refman/5.6/en/innodb-change-buffer.html 。
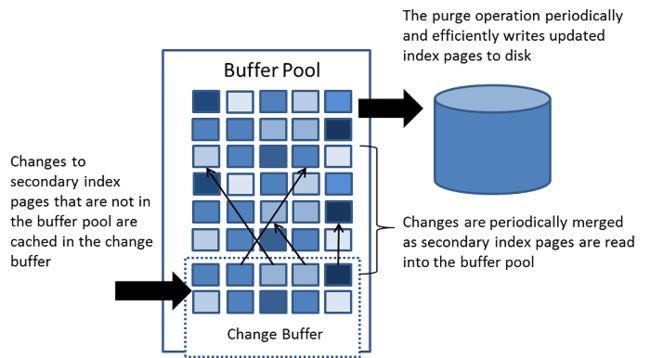
change buffer是一种特殊的数据结构,当二级索引页不在buffer pool中时,对二级索引页的修改进行缓存。被缓冲的修改可能由INSERT,UPDATE或DELETE等DML操作引起,在以后通过其他读取操作将页加载到buffer pool中时会被合并。
当对表执行INSERT,UPDATE和DELETE操作时,索引列的值(尤其是二级索引键值)通常处于未排序的顺序,需要大量的I/O才能使二级索引保持最新状态。当相关页不在buffer pool中时,change buffer会将修改缓存到二级索引条目中,通过不立即从磁盘读取页来避免昂贵的随机I/O操作。当页加载到buffer pool中时,缓冲的更改将合并,更新的页随后将刷新到磁盘。当服务器接近闲置时以及在缓慢关闭期间,InnoDB主线程会合并缓冲的更改。
可以使用innodb_change_buffering配置参数来控制InnoDB执行change buffer的范围。可以为插入(insert),删除操作(delete,最初将索引记录标记为删除)和清除操作(purge,物理删除索引记录)启用或禁用缓冲。更新(update)操作是插入和删除的组合。
默认的innodb_change_buffering值为all,即对上述插入,删除和清除操作进行缓冲。
Change Buffer的示意图如下所示:
参考 http://mysql.taobao.org/monthly/2015/07/01/ ,对于唯一二级索引(unique key),由于索引记录具有唯一性,因此无法缓存插入操作,但可以缓存删除操作。即Change Buffer对于唯一二级索引仅支持删除操作。
7. InnoDB架构图
参考 https://dev.mysql.com/doc/refman/5.6/en/innodb-architecture.html 。
InnoDB架构图如下所示,包含内存与磁盘中的结构:
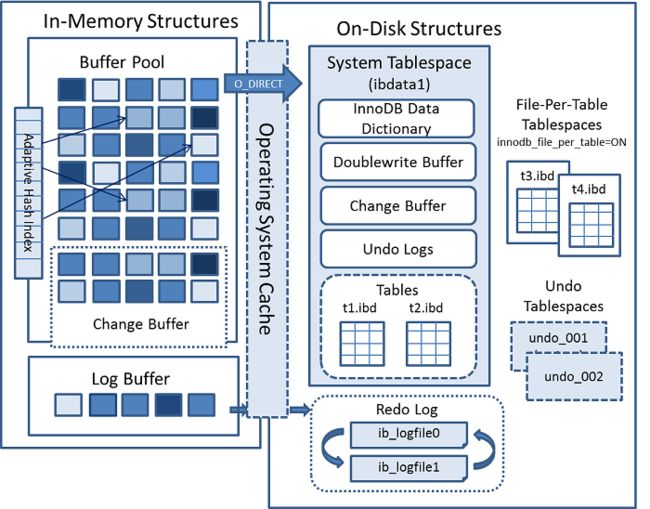
8. MySQL源码
MySQL源码地址为 https://github.com/mysql/mysql-server 。
MySQL的源码可与文档中的说明相互印证,示例如下:
https://github.com/mysql/mysql-server/blob/5.6/storage/innobase/include/btr0btr.ic 文件中定义了btr_page_set_next、btr_page_set_prev方法,分别用于设置下一个/上一个索引页字段。
https://github.com/mysql/mysql-server/blob/5.6/storage/innobase/btr/btr0btr.cc 文件中调用了btr_page_set_next、btr_page_set_prev方法,以上两个方法在调用时成对出现。
https://github.com/mysql/mysql-server/blob/5.6/storage/innobase/include/page0page.ic 文件中定义了page_rec_is_infimum方法,当输入参数为页中的下确界记录时,返回TRUE;调用当前文件中的page_rec_is_infimum_low方法。还定义了page_rec_is_supremum方法,当输入参数为页中的上确界记录时,返回TRUE;调用当前文件中的page_rec_is_supremum_low方法。
https://github.com/mysql/mysql-server/blob/5.6/storage/innobase/include/page0cur.ic 文件中定义了page_cur_is_before_first方法,当游标在页中第一个用户记录之前时,返回TRUE;调用上述page_rec_is_infimum方法。还定义了page_cur_is_after_last方法,当游标在页中最后一个用户记录之后时,返回TRUE;调用上述page_rec_is_supremum方法。
https://github.com/mysql/mysql-server/blob/5.6/storage/innobase/include/rem0rec.ic 文件中定义了rec_get_next_ptr方法,获取并返回同一页中下一条链接的记录的指针,调用当前文件中的rec_get_next_ptr_const方法。
9. 参考资料
以上参考的资料如下:
https://dev.mysql.com/doc/refman/5.6/en/
https://dev.mysql.com/doc/internals/en/
https://blog.jcole.us/innodb/
http://mysql.taobao.org/monthly/
《High Performance MySQL, 3rd Edition》