day06| 242.有效的字母异位词,349. 两个数组的交集,202. 快乐数,1. 两数之和
一、哈希表
1.什么时候使用哈希表
1.当我们遇到了要快速判断一个元素是否出现在集合里的时候,就要考虑哈希法。如果在做面试题目的时候遇到需要判断一个元素是否出现过的场景也应该第一时间想到哈希法!
2.能将O(n)的枚举查询降到O(1)。
3.哈希函数 映射 索引。
4.遇到哈希碰撞,一般用拉链法和线性探测法解决。
5.拉链法就是要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。线性探测法要保证tableSize大于dataSize,依靠哈希表中的空位来解决碰撞问题。
2.常见的三种哈希结构
1.数组
2.set (集合)
3.map(映射)
3.三种哈希结构的区别
- 下面这两张来自代码随想录的图总结的很好。按照规律来看,需要重复的就用multi,不需要重复的就用unordered就可以了(效率高),原始set、map好像用不到。(下面的引用证明我考虑不完善,因为还要考虑有序)
当我们要使用集合来解决哈希问题的时候,优先使用unordered_set,因为它的查询和增删效率是最优的,如果需要集合是有序的,那么就用set,如果要求不仅有序还要有重复数据的话,那么就用multiset。

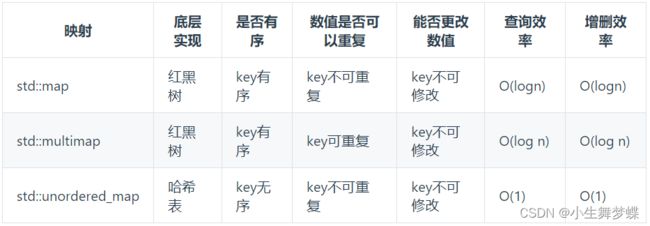
- 虽然实现底层是红黑树,但是给的接口还是key和value,所以依然可以称之为哈希法。
hash_set,hash_map 是C++11标准之前民间高手自发造的轮子,建议还是使用unordered_set比较好,功能一样。
二、242.有效的字母异位词
leetcode题目链接
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
示例 1: 输入: s = “anagram”, t = “nagaram” 输出: true
示例 2: 输入: s = “rat”, t = “car” 输出: false
说明: 你可以假设字符串只包含小写字母。
- 读完题意就想到这是一个判断一个字符是否出现过的场景,哈希表。发现可能有多次出现,复数,要不就是用multiset,要不就是用multimap。但是还有问题,怎么记录出现过几次呢?要记录的话是不是太麻烦了点,因为提前不知道这个单词是由多少个字母组成,动态的吗?没思路了。
- 看完这个动画灵机一动,感觉有点像使用栈判断符号是否合法的感觉。然后卡住我的是26个字母对应的ASCII码是多少记不住,后面发现不用记,s[i] - ‘a’ 一下就可以了,相对数值。
抄了一下第一个for循环看下数组怎么操作,后面两个for循环可以自己写出来。注意数组求长度要用sizeof()这些间接的方法,直接.size()是求不出来的(嗯,不方便)。
class Solution {
public:
bool isAnagram(string s, string t) {
int record[26] = {0};
for(int i=0; i<s.size(); i++){
record[s[i] - 'a']++;
}
for(int i=0; i<t.size(); i++){
record[t[i] - 'a']--;
}
for(int i=0; i<26; i++){
if(record[i] != 0){
return false;
}
}
return true;
}
};
三、349. 两个数组的交集
leetcode题目链接
题意:给定两个数组,编写一个函数来计算它们的交集。输出结果中的每个元素一定是唯一的。我们可以不考虑输出结果的顺序 。

- 交集就是判断是否出现过的场景,但是没想到怎么写。看题解去。
- unordered_set这东西居然可以用来去重(0^0),不知道是不是很常见的用法,但我此时大为震惊。
- 思路懂,但是不知道unordered_set有哪些接口,怎么用。所以直接抄的。
- 现在至少知道了find(),insert()以及vector和set的互相转换方法,另外没想到C++里也有int num : nums2这种取值表达,还以为只有Python里面有。
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set;
unordered_set<int> nums_set(nums1.begin(), nums1.end());
for(int num : nums2){
if(nums_set.find(num) != nums_set.end()){
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};
- 去看了一眼数组的解法,没有深入,但看基本用法是和上一题一样,存在就打一个record(数组值设为1),所以才要求当使用数组方法的时候,集合个数有限并且不能太大吧。
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set; // 存放结果,之所以用set是为了给结果集去重
int hash[1005] = {0}; // 默认数值为0
for (int num : nums1) { // nums1中出现的字母在hash数组中做记录
hash[num] = 1;
}
for (int num : nums2) { // nums2中出现话,result记录
if (hash[num] == 1) {
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};
四、202. 快乐数
leetcode题目链接
编写一个算法来判断一个数 n 是不是快乐数。
「快乐数」定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是 无限循环
但始终变不到 1。如果 可以变为 1,那么这个数就是快乐数。如果 n 是快乐数就返回 True ;不是,则返回 False 。

- 看这题目的时候我就在想,这不是应该算一道模拟题吗,只能按照题目要求往下模拟才知道最后是不是等于1(是不是快乐数),这和set这种集合哈希有什么关系。百思不得其解。而且对于int这种数字整型来说,把个位十位分开还得用除余,挺麻烦的感觉。直接看题解吧。
- 哈哈哈,容我先笑一笑,我投机取巧的写法,居然能通过全部用例。写完getSum()方法后,我就取循环求Sum,设了一个阈值500,500次之内取不到1我就判定不是快乐数,500之内能取到1就判定是快乐数,居然就能通过405个用例,还差一个用例就是当给的n为1的时候,本来应该是true但我的方法判定为false,于是我就单独列出来写在最前面,然后,就全通过了。
- 好吧,主要是因为一开始没想通怎么用Set做,代码随想录说**“不是快乐数就会无限循环”**这个条件非常重要,一开始我确实完全没有注意到。现在想想,大概就是每个num存进set里面,同时查(find()函数)当再次遇到该sum就确定不是快乐数。那我试试。
- 写出来了,如下代码,和代码随想录有点区别,其它的不重要,但是这个“if(nums_set.find(n) != nums_set.end())”这个条件我是参考了题解的,我还没搞懂这个find()是怎么使用的,是怎么个语法哎。再看看。
- 去百度了一下unordered_set的语法,这下看懂了,unordered_set.finid()的返回值和unordered_set.end()不一样则代表找到了,一样则代表没找到,所以找没找到要通过和end()的对比,如下图。怎么感觉挺绕的,直接返回bool值不好嘛。。。

class Solution {
public:
int getSum(int n){
int sum = 0;
while(n){
sum = sum + (n % 10)*(n % 10);
n = n / 10;
}
return sum;
}
bool isHappy(int n) {
if(n==1){
return true;
}
unordered_set<int> nums_set = {0};
while(n != 1){
n = getSum(n);
if(n == 1){
return true;
}
if(nums_set.find(n) != nums_set.end()){
return false;
}else{
nums_set.insert(n);
}
}
return false;
}
};
五、1. 两数之和
leetcode题目链接
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
- 暴力解法就不说了,这个题难在如何降低暴力解法O(n^2)的复杂度。看着题我就想用target减去数组得到新数组,再从新数组中寻找是否有和原数组相同的数。一开始思考为什么不能用set,写着写着发现需要记录下标和值两个数,所以得用map,当然,有重复就应该用multimap了,然后学习了一下map用法,知道了有first和second两个分别代表key和value。然后就写出了以下的解答。57个用例通过了47个,不通过的用例原因我也知道是因为6-3=3这种巧合。但是,不知道应该怎么改了。看题解吧。
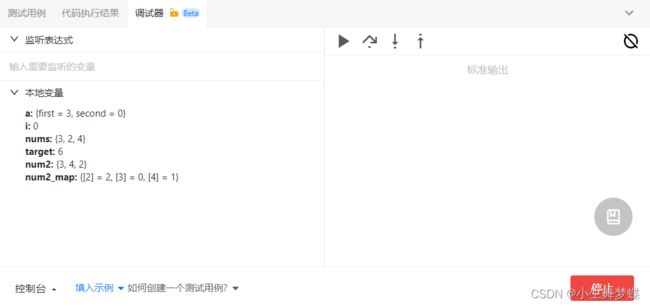
- 看了题解,倒是一遍也看懂了,就直接复制了。题解用的是unordered_map,这个影响不大,换成multimap也可以通过。
- 问题出现在另外的地方,我的代码(对,这里应该不算思路问题了,完全属于代码习惯问题),我的代码是先将全部的target-nums计算出来保存好,然后放进map里面再去查找,所以导致了查找到6-3=3这种的时候我的代码判断为找到了答案。但题解的代码写法,是直接开始找,找不到再保存,一次for循环完成所有逻辑,所以不会出现自己找到自己的现象。这种写法肯定是更好,要学,可能以后也会避免很多问题。
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
std::unordered_map <int,int> map;
for(int i = 0; i < nums.size(); i++) {
// 遍历当前元素,并在map中寻找是否有匹配的key
auto iter = map.find(target - nums[i]);
if(iter != map.end()) {
return {iter->second, i};
}
// 如果没找到匹配对,就把访问过的元素和下标加入到map中
map.insert(pair<int, int>(nums[i], i));
}
return {};
}
};
- 想把我自己的代码6-3=3的判定解决,可以解决,单独写这个条件,再次通过3个用例。
- 但是又出现了新问题,不满足题目中“数组中同一个元素在答案里不能重复出现”的要求,没解决,先不弄了,后面有机会再弄。
六、总结
哈希法,根据数组、set、map中三个的优劣势,判断在某个场景中应该选用哪一个。直接摘抄代码随想录里面的句子。
再来看一下使用数组和set来做哈希法的局限。
- 数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
- set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。所以set 也不能用。
参考资料
代码随想录