生成器知道鉴别器在无条件GANs中应该学习什么
文章目录
- Abstract
- 1. Introduction
- 2. Dense semantic supervision in unconditional GANs
-
- 2.1. Utilization of semantic label maps for discriminator【2.1.使用语义标签图作为鉴别器】
- 2.2. Analysis of generator feature maps生成器特征图分析
- 3. Generator-guided discriminator regularization
- 4. Experiments
-
- 4.1. Comparison with baselines
- 4.2. Analysis and ablation study
- 5. Related Work
- 6. Conclusion and limitation
- Acknowledgement.
- References
Abstract
最近的条件图像生成方法受益于密集监控,例如分割标签图,以实现高保真。然而,很少有人探索使用密集监控来无条件生成图像。在这里,我们探讨了密集监督在无条件生成中的有效性,并发现生成器特征映射可以替代成本高昂的语义标签映射。根据我们的经验证据,我们提出了一种新的generatorguided鉴别器正则化(GGDR),其中生成器特征映射监督鉴别器在无条件生成中具有丰富的语义表示。具体来说,我们采用U-Net架构作为鉴别器,该鉴别器经过训练以预测给定虚假图像作为输入的生成器特征图。在多个数据集上的大量实验表明,我们的GGDR在定量和定性方面不断提高基线方法的性能。代码位于:https://github.com/naver-ai/GGDR.
1. Introduction
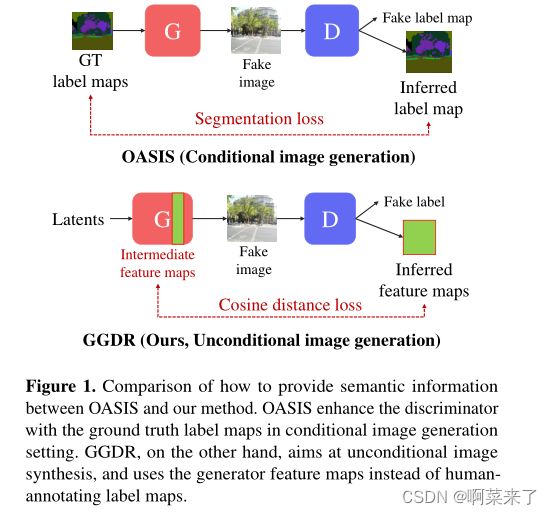
【图1.OASIS和我们的方法之间如何提供语义信息的比较。OASIS在条件图像生成设置中使用地面真值标签地图增强鉴别器。另一方面,GGDR旨在无条件图像合成,并使用生成器特征地图而不是人工注释标签地图】
在过去几年中,生成对抗网络(GAN)在各种计算机视觉任务中取得了很好的结果,包括图像[27-29]或视频生成[53,59,60,65]、翻译[7,20,31,34,73]、操作[3,15,22,30,36,50]和跨域翻译[18,35]。在遗传算法中,建立有效的鉴别器是发电质量的关键组成部分之一,因为生成器由鉴别器的反馈进行训练。现有研究提出了各种方法,通过数据增强[26,69-71]、梯度惩罚[42,43,46]和精心设计的架构[25,49],使鉴别器学习更好的表示。
改进鉴别器的一种简单而有效的方法是提供可用的附加注释,例如类标签[5,44]、位姿描述符[52]、法线图[62]和语义标签图[20,41,45,56]。在这些注释中,语义标签地图包含了丰富而密集的图像描述,并且经常用于条件场景生成。为了向鉴别器提供密集的语义信息,Pix2pix[20]和SPADE[45]将标签映射与输入图像连接起来,CC-FPSE[41]使用投影而不是连接来注入标签映射的嵌入。OASIS[56]通过使用辅助语义分割任务提供强大的监督,进一步增强了鉴别器,并实现了更好的性能。
尽管密集语义监督在条件生成中取得了成功,但很少在无条件环境中进行研究。密集的语义监督在这里也很有用,因为当数据具有多种复杂的布局图像。然而,在无条件生成中,大多数大型数据集没有成对的图像和语义标签图,因为收集它们需要大量的人工注释成本。因此,与条件设置不同,条件设置需要密集标签映射作为生成器输入,无条件图像生成假设没有密集映射,并且大多数研究使用仅从图像学习的鉴别器。
在本文中,我们证明了使用密集和丰富的语义信息引导鉴别器在无条件图像生成中也很有用,并提出了一种在利用语义监督的同时避免数据注释成本的方法。我们提出了生成器引导的鉴别器正则化(GGDR),其中生成器特征映射监督鉴别器具有丰富的语义表示。具体来说,我们重新设计了U-Net风格的鉴别器架构,并训练鉴别器在输入为生成图像时估计生成器特征图。如图1所示,GGDR与之前的工作不同之处在于,鉴别器由生成器特征图而不是人类注释的语义标签图监督。
为了证明我们提出的方法的合理性,我们首先比较了StyleGAN2[29]在向鉴别器提供和不提供地面真值分割地图的情况下的生成性能,并表明在无条件设置下,使用语义标签地图确实提高了生成性能(第2.1节)。然后,我们将生成器特征图可视化,并表明它们包含足够丰富的语义信息来指导鉴别器,从而取代了groundtruth标签图(第2.2节)。利用生成器特征映射,GGDR改进了鉴别器表示,这是提高生成性能的关键组件(第3节)。我们提供了彻底的比较,以证明GGDR持续改进了各种数据的基线模型。我们的方法可以很容易地附加到任何设置,而无需负担成本;只有3.7%的网络参数增加。我们的贡献可以总结如下:
1.我们研究了密集语义监督对无条件图像生成的有效性。
2.我们证明了生成器特征图可以作为人类注释语义标签图的有效替代。
3.我们提出了生成器引导的鉴别器正则化(GGDR),该正则化鼓励鉴别器利用生成器特征映射具有丰富的语义表示。
4.我们证明了GGDR在多个数据集上不断改进最先进的方法,特别是在发电多样性方面。
2. Dense semantic supervision in unconditional GANs
我们首先使用地面实况分割图进行了初步实验,以证明为鉴别器提供密集语义监督的有效性(第2.1节)。然后,我们研究生成器特征地图是否可以用作指南,而不是使用人工注释地面真实值标签地图,以避免昂贵的手动注释。我们可视化了生成器的内部特征图,并表明它们具有足够丰富的语义信息,可以用作伪语义标签(第2.2节)。

【图2.用于初步实验的具有辅助分割损失的鉴别器架构。】

【图3.在初步实验中,有和没有密集语义监督的ADE20K上的FID分数。】
2.1. Utilization of semantic label maps for discriminator【2.1.使用语义标签图作为鉴别器】
虽然在条件图像生成中使用语义标签地图是很自然的[41、45、56],但标签地图是否有利于无条件图像生成[26、28、29]的研究仍然不足。我们进行了初步实验来验证语义标签映射的效果。我们使用ADE20K场景解析基准数据集[72],该数据集由20210个成对图像和150个类别标签的语义标签地图注释组成,常用于评估条件生成模型。我们选择StyleGAN2[29]作为基线,这是无条件图像生成的标准模型,并应用自适应鉴别器增强[26]。为了为网络提供语义2监督,我们重新设计了鉴别器,以执行类似于OASIS[56]的额外分割任务。鉴别器的修改任务如图2所示。详细架构类似于图5,只是它对解码器输出进行上采样,直到达到图像大小。U-Net风格的译码器连接到鉴别器,并将分割损失应用到译码器的最后一层,以提供密集监督。分割损失是通常的交叉熵损失。由于地面真值标签地图不适用于生成的图像,我们仅激活真实图像的分割损失。
如图3所示,具有利用语义监督的鉴别器的模型(ADA with GT)优于基线(ADA w /o GT)。正如OASIS中所述,更强的语义监督似乎有助于鉴别器学习更多语义和空间感知的表示,并为生成器提供更有意义的反馈。我们的实验支持为鉴别器提供额外的语义指导可以提高无条件图像合成中的模型性能。然而,在无条件图像合成的数据集中,密集标签图是罕见的,手动收集它们非常耗时。在下一节中,我们将分析来自生成器的特征地图,作为地面真值标签地图的有效替代方案。

【(a) 生成器特征图可视化 】
【(b) 早期训练阶段的生成器特征图】
【 图4.使用kmeans(k=6)聚类对发电机特征图进行可视化。(a) StyleGAN2生成器特征图。可视化的特征图揭示了语义一致且有意义的区域,比如猫的耳朵。(b) 在早期训练阶段生成的图像及其32×32特征图。】
2.2. Analysis of generator feature maps生成器特征图分析
最近的研究表明,经过训练的GANs生成器的特征图包含丰富而密集的语义信息[9,11,63]。Collins等人[9]表明,将k-means聚类应用于生成器的特征图可以揭示对象的语义和部分,并使用聚类编辑图像。我们注意到,这些特征图是生成图像的丰富语义描述符,可以替代地面真值标签图。为了可视化每个特征图中捕获的信息,我们使用生成的一批图像在每一层上运行k-means算法。在这个实验中,我们将k=6。如图4(a)所示,像素是根据语义信息而不是除最后一个特征映射之外的低层特征进行聚类的。例如,人的头发有不同的颜色,但聚集在同一簇中。早期的特征图显示了粗略的对象位置,后一层的特征图包含详细的对象部分。可视化特征图看起来像伪语义标签图,可以被视为包含图像空间和语义信息的丰富描述。因此,我们选择生成器的特征映射作为语义标签映射的替代,以使用语义监督来引导鉴别器。生成器特征映射在我们的示例中很有用。首先,我们不需要完美的语义分割图,因为我们的目标是图像生成而不是语义分割。其次,特征图是生成所必需的中间副产品,因此获取它们是免费的,不需要其他人工注释。
与之前的工作[9、11、63]不同,我们的方法在训练期间利用生成器特征映射来提高生成性能本身。因此,有必要检查在训练过程中来自生成器的特征映射是否仍然具有语义指导意义。在图4(b)中,我们在训练期间可视化了生成器的特征图,以检查特征图在多早就具有语义意义。令人惊讶的是,得益于强大的现代GANs,我们可以观察到,即使在早期阶段,特征地图和相应生成的图像也捕捉到了对象的粗略形状和位置。因此,我们从训练开始就利用特征映射,但对于更复杂的数据,生成器需要更多迭代才能产生有意义的语义,可以选择何时附加目标函数。
3. Generator-guided discriminator regularization
基于我们的观察,我们提出了生成器引导的鉴别器正则化(GGDR),其中生成器特征映射监督鉴别器具有丰富的语义表示。整体框架如图5所示。
我们的鉴别器D的设计受到OASIS[56]的启发,其中采用U-Net编码器-解码器结构,最后一层预测语义标签映射。然而,与OASIS不同,我们利用生成器的特征图,而不是地面真相标签图。因此,在设计上有几个不同之处。首先,由于特征映射不再是离散的标签,我们不能像在OASIS中那样简单地将真/假类添加到解码器输出。因此,我们将解码器和对抗性损失分离开来。接下来,我们使用更紧凑、更轻的模块来减少额外的计算成本。对于每一层,我们将解码器和编码器层的输出串联起来,并运行一个线性1×1卷积层和上采样。我们堆叠解码器模块,直到解码器输出与目标生成器特征图具有相同的分辨率。虽然解码器很紧凑,但由于共享编码器可以提取语义信息,因此预测生成器特征图就足够了。
同时,编码器部分仍然是共享的,因此它通过语义和对抗损失进行训练。对于对抗性损失,我们采用非饱和对抗性损失[13]:

接下来,我们计算解码器输出和目标特征映射之间的余弦距离损失。我们使用余弦距离损失,因为它给出了一个特定范围内的损失,即使在非规范化的特征向量之间,所以它很方便根据对抗性损失进行缩放。这里,我们表示l∈ {1,2,…,L}作为层索引,其中L是解码层的数量。我们的鉴别器D包含一个U-Net风格的解码器F(F⊂ D) 表示为F l的每一层的输出与相应的生成器特征映射G(z)l具有相同的分辨率。让我们将引导的目标层索引表示为t。我们的生成器引导鉴别器正则化(GGDR)定义为:

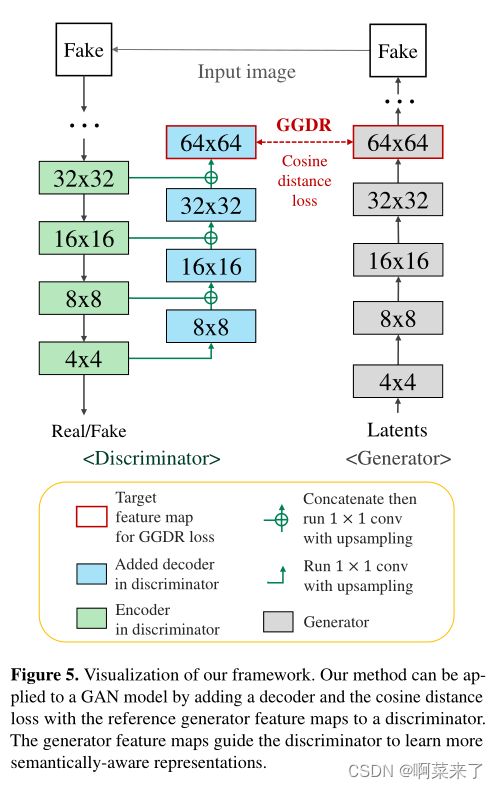
【图5.我们框架的可视化。我们的方法可以通过添加译码器将余弦距离损失和参考生成器特征映射应用到鉴别器来应用于GAN模型。生成器特征映射引导鉴别器学习更多语义感知表示】
我们的全部目标函数可以总结如下:

其中λreg是相对于对抗项的相对强度的超参数。注意,第2.2节中使用的k-means聚类仅用于可视化目的,我们直接比较原始特征图,而不进行任何聚类。我们期望Lggdr项增强D的语义表示。虽然生成器特征映射参与正则化损失,但我们不会使用Lggdr更新生成器以防止特征崩溃,这是一种使余弦距离为零的简单解决方案。
我们的框架简单且易于应用现有的GAN模型,并且不需要任何额外的注释。从生成器获取中间特征地图是免费的,因为生成器已经生成了这些地图,以便生成假图像。尽管简单,在下一节中,我们将展示我们的方法在各种数据集的无条件图像生成中的有效性。
表1.FFHQ上我们的FID分数和比较方法。我们对每个数据进行三次训练,并显示其均值和标准差。这些数字主要来自ADA[26],我们遵循他们的评估协议。

4. Experiments
我们验证了我们的GGDR在各种数据集上的有效性,包括CIFAR-10[37]、FFHQ[28]、LSUN cat、horse、church[64]、AFHQ[8]和景观[2]。CIFAR-10由10类50000个微小彩色图像组成。FFHQ包含70000张人脸图像,AFHQ包含约5000张每张猫、狗和野生动物的人脸图像。LSUN cat、horse和church分别由包含cat、HOUSE和church的场景组成,每个数据集使用了200000个图像。景观包含从Flickr[1]收集的4320幅景观图像。根据StyleGAN2和ADA[26],我们对FFHQ和小数据集应用了水平翻转。除AFHQ(512×512)和CIFAR-10(32×32)外,所有图像的大小均调整为256×256。对于GGDR丢失,我们选择发电机的64×64特征图作为引导图,但CIFAR-10除外,其中我们选择8×8特征图。在所有实验中,我们将拟议正则化的权重设置为λreg=10,并且不修改其他超参数。我们将R1正则化[42]应用于StyleGAN2和ADA模型。在ADA的情况下,我们将增强应用于生成器特征映射,使其与相应的伪图像一致。我们只使用几何运算和跳过颜色变换来增强特征图。
对于评估指标,我们使用了Fr´echet初始距离(FID)[16]和精度与召回[39]。FID测量真实图像和特征空间中生成样本之间的距离,精度和召回分数表示样本质量和种类。我们比较了50000张生成的图像和之前工作[26]之后的所有训练图像。对于CIFAR-10,我们也在之前的工作[26,54]之后使用初始分数(IS)[47]。
4.1. Comparison with baselines
我们将GGDR应用于StyleGAN2[29],这是无条件图像生成的标准模型之一。代替原始StyleGAN2设置,我们使用ADA[26]中使用的基线设置,该设置具有较少的参数和较短的训练迭代,但显示出相当的性能。对于小数据集,我们应用了自适应鉴别器增强(ADA)[26],它可以防止鉴别器的过度拟合,并在小数据集中显示出优越的性能。

【表2.CIFAR-10上我们的FID分数和比较方法。我们对均值和标准差进行了三次训练。我们从[54]中得出了扩散模型的数量。】
表1和表2表明,拟议的GGDR在指示合成图像整体质量的FID分数方面提高了基线的性能。根据ADA[26],我们在FFHQ上使用不同数量(2k、10k和140k)的训练图像进行了多次实验。我们在很大程度上借鉴了ADA[26]和NCSN++[54]的报告分数。在表1中,我们将我们在不同数量的训练图像中的方法与各种正则化方法WGAN-GP[14]、PA-GAN[67]、zCR[71]、AR[6]和ADA[26]进行了比较。在表中,使用我们的GGDR的StyleGAN2在具有完整训练图像的FFHQ上获得了最佳分数。在有足够数量的训练图像的情况下,基于数据增强的正则化方法显示出有限的改进或退化,而在我们的方法中,鉴别器从质量更好的生成器提供的更精确的语义图中学习。在大多数情况下,除FFHQ 2k设置外,GGDR显著提高了基线性能。我们猜想数据集太小,无法在生成器中学习语义上有意义的特征映射。由于生成器特征映射的质量直接影响我们方法中的鉴别器,因此当有足够数量的训练数据时,我们的方法更有效。然而,如表4所示,我们的方法在具有约5000张图像的数据集上显示了有效性,这些图像不太多。表2显示,我们的GGDR在FID和IS分数方面显著提高了ADA性能,并使其优于各种模型,包括ProGAN[25]、AutoGAN[12]、FSMR[33]和DDPM[17],与NCSN++[54]相当。
【表3.FFHQ、LSUN Cat、LSUN Horse和LSUN Church的比较。我们的方法在FID和召回方面改进了大型数据集中的StyleGAN2[29]。P和R表示精度和召回率。更低的FID和更高的精度和召回率意味着更好的性能。粗体数字表示每个数据集的最佳FID、P、R。】

【表4.AFHQ猫、狗、野生和景观的比较。我们的方法在FID和召回方面改进了小数据集中的ADA[26]。P和R表示精度和召回率。粗体数字表示模型中的最佳FID、P和R】

在表3和表4中,我们进行了大量实验,以验证在多种数据集上使用GGDR的性能改进。对于FFHQ和LSUN数据集,我们报告了UT[4]和极性[19]的分数,这是显示这些数据集改进的最先进模型。对于AFHQ和景观数据集,我们报告了ContraD[23]和FastGAN[40]的分数,这表明小尺寸数据集的图像合成有显著改进。除了FastGAN的分数来自ProjGAN[48]之外,我们从他们的论文中获得了数字。GGDR在FID分数方面持续改进基线,差距较大。在精度和召回指标方面,与基线相比,GGDR显著提高了召回率,这间接表明了我们方法的优势来自哪里。更好的回忆分数意味着我们的模型生成更多不同的图像,并且不容易出现模式崩溃。众所周知,将图像级标签合并到鉴别器可增强数据中类别的覆盖率,利用伪密集语义信息可促进生成图像中的语义多样性。

【图6。(a)AFHQ上有和没有GGDR的最差样本图像的定性比较。(b) 在有和没有GGDR丢失的情况下,对鉴别器中编码器的特征图进行k-均值聚类。从上到下,真实图像、8(k=3)和16(k=6)像素宽的特征地图。】
在图9和图8(a)中,我们展示了我们的方法在评估数据集上的一些选定结果。对于FFHQ和LSUN,我们使用GGDR可视化StyleGAN2,对于其他数据集,使用GGDR将ADA可视化。补充材料中显示了更多未经处理的图像。由于我们的方法倾向于提高查全率而不是查准率,因此在样本数量有限的情况下很难显示视觉效果的改善。相反,我们比较了图6(a)中最差的样本。我们遵循[38]的方法对样本进行排序,该方法使用初始[57]模型拟合高斯模型并排序通过使用它的对数似然。我们可以看到,我们方法中最差的样本仍然包含与ADA不同的对象。有趣的是[38]通过使用预训练模型作为鉴别器,报告了对最差样本的类似改进。我们推测生成器的特征图在其工作中与预训练模型起着类似的作用[38,48]。
4.2. Analysis and ablation study
所提出的GGDR使用GAN模型中生成器的中间特征映射来监督鉴别器,因此它取决于生成器特征映射的质量。在第2.2节中,我们证明了生成器的特征映射即使在早期阶段也包含有效的语义信息。除了可视化,我们在早期迭代中测量了FID,如图7(a)所示。为了检查初始化的效果,我们在LSUN Cat上进行了多次实验。在早期迭代中,GGDR会使用训练较少的特征映射和错误的初始化来干扰性能。然而,经过几千次迭代后,带有GGDR的StyleGAN2开始更快地收敛,并显示出更好的分数。
在表5中,我们进行了消融研究以调查解码器架构和特征映射分辨率的影响。在我们的实验中,我们选择64×64特征地图作为指导。如果我们使用不同尺寸的引导特征图,人们可能会好奇性能差异。如表5(a)所示,利用大而密集的特征图可以获得最佳的FID分数。同时,我们设计了一种具有1×1卷积滤波器和线性激活的紧凑解码器,用于快速训练和收敛。在表5(b)中,我们表明,改变解码器激活和内核大小对性能差异的影响可以忽略不计。

【(a) 早期培训阶段的FIDs 】
【(b) 下游任务结果 】
【图7。(a)在LSUN Cat的早期训练阶段使用GGDR进行的多个实验的FID分数图。(b) 使用经过和未经GGDR训练的冻结鉴别器验证ADE20K分割任务的像素精度。 】

【图8。(a)ADA和GGDR在CIFAR-10数据集上的随机样本。(b) 我们的鉴别器中解码器的特征图在真实图像(k=6)上的k-均值聚类。】

【表5.具有八个V100 GPU的LSUN Cat的烧蚀研究和计算成本。烧蚀研究(a)目标特征图大小和(b)解码器设计。(c) 有无GGDR的计算成本。】
为了分析GGDR的效果,我们可视化并比较了图6(b)中的原始鉴别器部分。我们如第2.2节所述运行k-means聚类。在GGDR丢失的情况下,共享编码器部分更倾向于学习高级特征对于这两个任务都很有用,因此其特征映射揭示了更具语义意义的集群。通过引导学习语义特征,我们的方法可以帮助鉴别器关注图像的显著部分,而不是无意义的特征。为了进一步分析,我们进行了下游实验,使用带或不带GGDR的鉴别器提取的特征训练浅层分割网络。如图7(b)所示,验证数据的准确性表明,具有GGDR的鉴别器在语义信息上具有更大的表示能力。同时,由于我们只对假图像进行训练,因此可能很好奇假图像的引导是否对真实图像仍然有效。在图8(b)中,我们将鉴别器解码器的输出显示在真实图像上。虽然我们方法的解码器使用假图像进行学习,但我们可以看到其特征很好地捕捉了真实图像的语义有意义区域。
在表5(c)中,我们显示了使用GGDR时的额外计算成本。我们可以看到,当参数增加3.7%,时间增加8.0%时,额外成本是边际的。对于这些测量,我们在具有八个V100 GPU的256×256数据集上运行StyleGAN2。
【图9.通过我们的方法生成的选择性样本。对于FFHQ和LSUN数据集,我们显示了StyleGAN2和GGDR的结果。对于AFHQ和景观,我们展示了ADA和GGDR的结果。
】
5. Related Work
利用语义标签映射的条件图像合成。对于生成图像的可控性,通常利用语义布局级别信息来生成条件图像[21、41、61]。SPADE[45]利用空间自适应非规范化来保留语义信息,OASIS[56]表明,它能够使用预测像素级语义标签的鉴别器来训练条件GAN,而无需将语义地图作为附加条件。此外,如[10,51]所示,可以使用深度网络的特征来对生成器进行语义引导,而不是使用明确的语义基本事实。与这些工作不同,我们的方法旨在无条件生成图像。
GAN的正规化。有几项工作致力于稳定GAN训练,特别是通过正则化鉴别器[33,42,43]。最近,利用增强技术实现鉴别器获得了很多兴趣,这在一般视觉任务中被证明是成功的[66,68]。在一致性正则化(CR)[69,71]中,除了使用规则GAN损耗外,鉴别器还受到增强图像和非增强图像之间8个输出差异的惩罚。APA[24]通过自适应地将假图像用作伪真实数据来正则化鉴别器。DiffAugment[70]和ADA[26]对发电机和鉴别器损耗使用无泄漏增强。最近,一些论文使用预训练模型帮助鉴别器进行快速稳定的训练。ProjGAN[48]使用EfficientNet[58]作为鉴别器的特征提取器,视觉辅助GAN[38]提供了从预训练网络模型库中的自动选择,以获得用于真假鉴别的最佳特征。
生成器功能的利用。最近的研究表明,生成器在特征中包含丰富且不纠缠的语义结构。Collins等人[9]表明,通过对生成器的特征激活应用k均值聚类,可以在生成的图像中提取语义对象和对象部分。Xu等人[63]训练了生成器中的特征图和语义图之间的线性映射,Endo等人[11]通过平均与反转图像的地面真实语义标签对应的特征向量,使用了特征图和代表向量之间的最近邻匹配。StyleMapGAN[30]在潜在代码和通道分组中使用了空间维度,以进一步理清空间语义特征。
6. Conclusion and limitation
在本文中,我们提出了稠密语义标签映射用于无条件图像生成的有效性。受这一观察结果的启发,我们提出了一种新的正则化方法,以利用生成器的特征图,而不是人工注释基本真理语义注释,以允许鉴别器学习更丰富的语义表示。由于附加参数可以忽略不计,并且没有地面真值语义分割图,所提出的GGDR始终优于强基线。由于我们的方法取决于生成器的性能,如果生成器由于数据数量极其有限或初始训练崩溃而无法学习有意义的表示,GGDR将无法提高性能。然而,多亏了现代GAN和训练技术,我们相信我们的方法可以很容易地应用于各种情况。
Acknowledgement.
本文中的实验是在NA-VER智能机器学习(NSML)平台上进行的[32,55]。我们感谢朱、吴在宏、NA VER-AI实验室研究人员和评审人员的宝贵意见和讨论。
References
[1] Flickr. https://www.flickr.com/. 5
[2] Kaggle landscapes dataset. https://www.kaggle.
com/arnaud58/landscape-pictures, 2019. 5, 11
[3] David Bau, Jun-Yan Zhu, Hendrik Strobelt, Bolei Zhou,
Joshua B Tenenbaum, William T Freeman, and Antonio Tor-
ralba. Gan dissection: Visualizing and understanding genera-
tive adversarial networks. ICLR, 2019. 1
[4] Sam Bond-Taylor, Peter Hessey, Hiroshi Sasaki, Toby P
Breckon, and Chris G Willcocks. Unleashing transformers:
Parallel token prediction with discrete absorbing diffusion for
fast high-resolution image generation from vector-quantized
codes. arXiv preprint arXiv:2111.12701, 2021. 6
[5] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large
scale gan training for high fidelity natural image synthesis.
ICLR, 2019. 1
[6] Ting Chen, Xiaohua Zhai, Marvin Ritter, Mario Lucic, and
Neil Houlsby. Self-supervised gans via auxiliary rotation loss.
In CVPR, 2019. 5
[7] Y unjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha,
Sunghun Kim, and Jaegul Choo. Stargan: Unified genera-
tive adversarial networks for multi-domain image-to-image
translation. In CVPR, 2018. 1
[8] Y unjey Choi, Y oungjung Uh, Jaejun Y oo, and Jung-Woo Ha.
Stargan v2: Diverse image synthesis for multiple domains. In
CVPR, 2020. 5, 11
[9] Edo Collins, Raja Bala, Bob Price, and Sabine Susstrunk.
Editing in style: Uncovering the local semantics of gans. In
CVPR, 2020. 3, 9
[10] Luke Ditria, Benjamin J. Meyer, and Tom Drummond. Open-
gan: Open set generative adversarial networks. In ACCV,
2020. 8
[11] Y uki Endo and Y oshihiro Kanamori. Few-shot semantic im-
age synthesis using stylegan prior. CoRR, abs/2103.14877,
2021. 3, 9
[12] Xinyu Gong, Shiyu Chang, Yifan Jiang, and Zhangyang Wang.
Autogan: Neural architecture search for generative adversarial
networks. In ICCV, 2019. 5
[13] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing
Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and
Y oshua Bengio. Generative adversarial networks. In NeurIPS,
2014. 4
[14] Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent
Dumoulin, and Aaron C Courville. Improved training of
wasserstein gans. In NeurIPS, 2017. 5
[15] Erik H¨ark¨onen, Aaron Hertzmann, Jaakko Lehtinen, and Syl-
vain Paris. Ganspace: Discovering interpretable gan controls.
NeurIPS, 2020. 1
[16] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bern-
hard Nessler, and Sepp Hochreiter. Gans trained by a two
time-scale update rule converge to a local nash equilibrium.
In NeurIPS, 2017. 5
[17] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu-
sion probabilistic models. In NeurIPS, 2020. 5
[18] Sheng-Wei Huang, Che-Tsung Lin, Shu-Ping Chen, Yen-Yi
Wu, Po-Hao Hsu, and Shang-Hong Lai. Auggan: Cross do-
main adaptation with gan-based data augmentation. In ECCV,
2018. 1
9
[19] Ahmed Imtiaz Humayun, Randall Balestriero, and Richard
Baraniuk. Polarity sampling: Quality and diversity control of
pre-trained generative networks via singular values. In CVPR,
2022. 6
[20] Phillip Isola, Jun-Y an Zhu, Tinghui Zhou, and Alexei A Efros.
Image-to-image translation with conditional adversarial net-
works. In CVPR, 2017. 1
[21] Phillip Isola, Jun-Y an Zhu, Tinghui Zhou, and Alexei A Efros.
Image-to-image translation with conditional adversarial net-
works. In CVPR, 2017. 8
[22] Ali Jahanian, Lucy Chai, and Phillip Isola. On the “steer-
ability” of generative adversarial networks. In ICLR, 2020.
1
[23] Jongheon Jeong and Jinwoo Shin. Training gans with stronger
augmentations via contrastive discriminator. In ICLR, 2021.
6
[24] Liming Jiang, Bo Dai, Wayne Wu, and Chen Change Loy.
Deceive d: Adaptive pseudo augmentation for gan training
with limited data. In NeurIPS, 2021. 9
[25] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen.
Progressive growing of gans for improved quality, stability,
and variation. ICLR, 2018. 1, 5
[26] Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine,
Jaakko Lehtinen, and Timo Aila. Training generative adver-
sarial networks with limited data. In NeurIPS, 2020. 1, 2, 5,
6, 9
[27] Tero Karras, Miika Aittala, Samuli Laine, Erik H¨ark¨onen,
Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Alias-free
generative adversarial networks. NeurIPS, 2021. 1
[28] Tero Karras, Samuli Laine, and Timo Aila. A style-based
generator architecture for generative adversarial networks. In
CVPR, 2019. 1, 2, 5, 11
[29] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten,
Jaakko Lehtinen, and Timo Aila. Analyzing and improving
the image quality of stylegan. In CVPR, 2020. 1, 2, 5, 6
[30] Hyunsu Kim, Y unjey Choi, Junho Kim, Sungjoo Y oo, and
Y oungjung Uh. Exploiting spatial dimensions of latent in gan
for real-time image editing. In CVPR, 2021. 1, 9
[31] Hyunsu Kim, Ho Y oung Jhoo, Eunhyeok Park, and Sungjoo
Y oo. Tag2pix: Line art colorization using text tag with secat
and changing loss. In ICCV, 2019. 1
[32] Hanjoo Kim, Minkyu Kim, Dongjoo Seo, Jinwoong Kim,
Heungseok Park, Soeun Park, Hyunwoo Jo, KyungHyun
Kim, Y oungil Yang, Y oungkwan Kim, et al. Nsml: Meet the
mlaas platform with a real-world case study. arXiv preprint
arXiv:1810.09957, 2018. 9
[33] Junho Kim, Y unjey Choi, and Y oungjung Uh. Feature statis-
tics mixing regularization for generative adversarial networks.
In CVPR, 2022. 5, 8
[34] Junho Kim, Minjae Kim, Hyeonwoo Kang, and Kwang Hee
Lee. U-gat-it: Unsupervised generative attentional networks
with adaptive layer-instance normalization for image-to-
image translation. In ICLR, 2020. 1
[35] Taeksoo Kim, Moonsu Cha, Hyunsoo Kim, Jung Kwon Lee,
and Jiwon Kim. Learning to discover cross-domain relations
with generative adversarial networks. In ICML, 2017. 1
[36] Y unji Kim and Jung-Woo Ha. Contrastive fine-grained class
clustering via generative adversarial networks. ICLR, 2022. 1
[37] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple
layers of features from tiny images. Technical report, Depart-
ment of Computer Science, University of Toronto, 2009. 5,
11
[38] Nupur Kumari, Richard Zhang, Eli Shechtman, and Jun-Yan
Zhu. Ensembling off-the-shelf models for gan training. In
CVPR, 2022. 6, 7, 9
[39] Tuomas Kynk¨a¨anniemi, Tero Karras, Samuli Laine, Jaakko
Lehtinen, and Timo Aila. Improved precision and recall
metric for assessing generative models. NeurIPS, 2019. 5
[40] Bingchen Liu, Yizhe Zhu, Kunpeng Song, and Ahmed El-
gammal. Towards faster and stabilized gan training for high-
fidelity few-shot image synthesis. In ICLR, 2020. 6
[41] Xihui Liu, Guojun Yin, Jing Shao, Xiaogang Wang, and Hong-
sheng Li. Learning to predict layout-to-image conditional
convolutions for semantic image synthesis. In NeurIPS, 2019.
1, 2, 8
[42] Lars Mescheder, Sebastian Nowozin, and Andreas Geiger.
Which training methods for gans do actually converge? In
ICML, 2018. 1, 5, 8
[43] Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and
Y uichi Y oshida. Spectral normalization for generative ad-
versarial networks. ICLR, 2018. 1, 8
[44] Augustus Odena, Christopher Olah, and Jonathon Shlens.
Conditional image synthesis with auxiliary classifier gans. In
ICML, 2017. 1
[45] Taesung Park, Ming-Y u Liu, Ting-Chun Wang, and Jun-Yan
Zhu. Semantic image synthesis with spatially-adaptive nor-
malization. In CVPR, 2019. 1, 2, 8
[46] Kevin Roth, Aurelien Lucchi, Sebastian Nowozin, and
Thomas Hofmann. Stabilizing training of generative adver-
sarial networks through regularization. NeurIPS, 2017. 1
[47] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki
Cheung, Alec Radford, and Xi Chen. Improved techniques
for training gans. In NeurIPS, 2016. 5
[48] Axel Sauer, Kashyap Chitta, Jens M¨uller, and Andreas Geiger.
Projected gans converge faster. NeurIPS, 2021. 6, 7, 9
[49] Edgar Schonfeld, Bernt Schiele, and Anna Khoreva. A u-net
based discriminator for generative adversarial networks. In
CVPR, 2020. 1
[50] Y ujun Shen, Jinjin Gu, Xiaoou Tang, and Bolei Zhou. Inter-
preting the latent space of gans for semantic face editing. In
CVPR, 2020. 1
[51] Assaf Shocher, Y ossi Gandelsman, Inbar Mosseri, Michal
Yarom, Michal Irani, William T. Freeman, and Tali Dekel.
Semantic pyramid for image generation. In CVPR, 2020. 8
[52] Aliaksandr Siarohin, Enver Sangineto, St´ephane Lathuiliere,
and Nicu Sebe. Deformable gans for pose-based human image
generation. In CVPR, 2018. 1
[53] Ivan Skorokhodov, Sergey Tulyakov, and Mohamed Elho-
seiny. Stylegan-v: A continuous video generator with the
price, image quality and perks of stylegan2. In CVPR, 2022.
1
[54] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab-
hishek Kumar, Stefano Ermon, and Ben Poole. Score-based