Redis(三) -- redis简介、各数据类型应用
1. 与memcached的区别:
- Redis和Memcache都是将数据存放在内存中,都是内存数据库。不过memcache还可用于缓存其他东西,例如图片、视频等等;
- Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储;
- 虚拟内存–Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘;
- 过期策略–memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通过例如expire 设定,例如expire name 10;
- 分布式–设定memcache集群,利用magent做一主多从;redis可以做一主多从。都可以一主一从;
- 存储数据安全–memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化);
- 灾难恢复–memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复;
- Redis支持数据的备份,即master-slave模式的数据备份;
- memcached使用的是串行+多线程+锁,redis使用的是单线程+多路IO复用
2. Redis如何避免并发问题 – IO多路复用
redis是单线程(6改为多线程,但本质还是单线程)+多路IO复用技术
多路复用是指:使用一个线程来检查多个文件描述符的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)
多路复用简单点说就是给请求监视效果:
当有多个请求访问redis的时候,可以把这些请求都加一个监视效果,监视这个请求是否准备完毕,如果某个请求准备完毕,直接处理这个请求,处理完成当前请求后再处理其他请求。
没有阻塞的状态,一直在处理请求。
2.1 阻塞IO、非阻塞IO、IO多路复用区别:

- 其中select和poll的区别是poll没有数量限制;
- epoll相当于给请求加上一个标识符,通过标识符来判断它是否准备完毕
3. 适用场景:

4. redis五大类型简介及应用:
4.1 基本操作
- 选择库:
select index;
例:选择一号库:select 1; - 查看所有键:
keys *(生产不能用,太耗时) - 判断某个键是否存在:
exists key - 查看键的类型:
type key - 删除某个键:
del key - 为键值设置过期时间(单位秒):
expire key seconds
例:expire a 10 - 查看键剩余过期时间:
ttl key
-1表示永不过期,-2表示已经过期 - 查看当前数据库数量:
dbsize - 清空当前库:
Flushdb - 通杀全部库:
Flushall
4.2 String类型:
4.2.1 简介:
- string是Redis最基本的类型,可以理解成与memcached一模一样的类型,一个key对应一个value
- string类型是二进制安全的。意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象
- 一个redis中字符串value最多可以是512M
4.2.2 命令:
get key:获取key的valueset key value:设置k-v值append key value:在key的值后面追加value,返回追加后的value的长度strlen key:获取key的值长度setnx key value:如果在key不存在时设置值,如果存在不设置值
如果key存在返回0,如果key不存在返回1incr key:将key中储存的数字值+1,只能对数字值操作,否则报错,如果为空,新增值为1
decr key:将key中储存的数字值-1,只能对数字值操作,如果为空,新增值为-1incrby/decrby key 步长:将key中储存的值增减自定义步长mset key1 value1 key2 value2:一次性设置一个或多个键值对mget key1 key2 key3:一次获取一个或多个valuemsetnx key1 value1 key2 value2:同时设置一个或多个键值对,当且仅当给定的key都不存在。getrange key 起始位置 结束位置:获得范围内的值,包前包后,不修改原值setrange key 起始位置 value:用value从起始位置开始覆写key的字符串值setex key 过期时间 value:设置键值的同时设置过期时间,单位秒getset key value:以新换旧,设置新值同时获得旧值
4.2.3 应用:
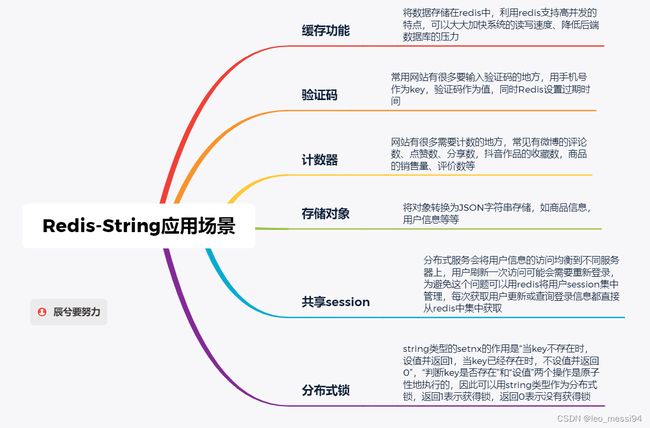
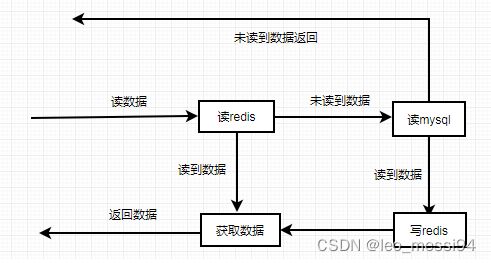
4.2.3.1 缓存功能:
部分数据第一次查询查询数据库,查询完后存入redis中,后续再获取可以从redis中获取
4.2.3.2 验证码:
网站登录中常有验证码,我们可以用此数据类型,手机号作为key,验证码作为value存储在redis中,设置过期时间,后续如果用户输入验证码,我们从redis中取值对比,如果过期则无效
set 13030303300 123456
4.2.3.3 数字计数:
比如帖子有点赞数,可以以帖子的id作为key,点赞总数作为value; 还比如访问量等,用户每次访问,访问总数可以加一,记录在redis中; 抖音的关注数,当大V注册抖音的时候,关注数会在非常短的时间内增加,这里我们可以用redis记录,一段时间后同步到mysql等数据库中;
user-id:10086:fans → 123456
user-id:10086:blogs → 999
user-id:10086:likes → 888
4.2.3.4 存储对象:
以json形式存储,常见key=id value=json格式数据,如商品id为key,商品信息为value
- 我的项目中的应用:
- 生成卷子时,卷子对象的json数据存到redis中,首次进入直接到redis中获取
- 定时任务给每个用户生成每日推荐,视频组成json列表存放
{"id":10086,"name":"哈哈哈哈","fans":123456,"blogs":999, "likes":888}
4.2.3.5 共享session:(分布式唯一id)
如我们第一次访问 https://editor.csdn.net这个域名,可能会对应这个IP 112.14.111.222的服务器,然后第二次访问,IP可能会变为112.13.121.219的服务器;负载均衡,一个域名对应多个服务器,将访问量分担到其他的服务器,这样很大程度的减轻了每个服务器上访问量
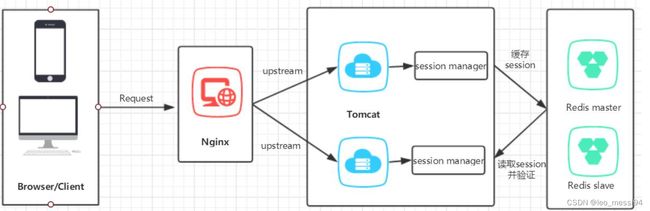
因为服务器都会有自己的会话session会导致用户每次刷新网页又要重新登录,为了解决这个问题,我们用redis将用户session集中管理,每次获取用户更新或查询登录信息都直接从redis中集中获取
这里的本质还是将某一个东西存入redis缓存中,和缓存功能类似,描述的是不同的应用场景
负载均衡:把众多的访问量分担到其他的服务器上,让每个服务器的压力减少
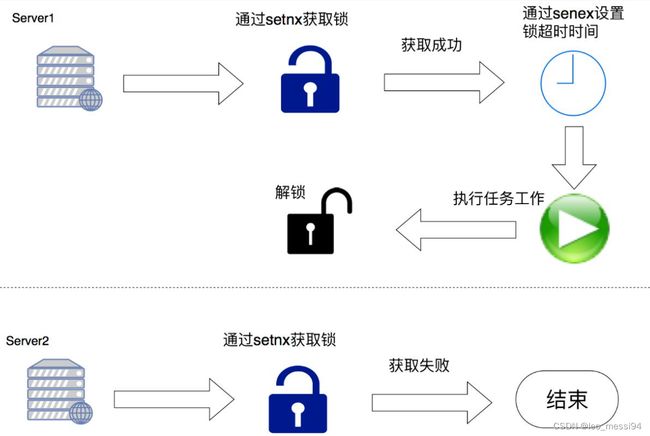
4.2.3.6 分布式锁
适用场景:在一个集群环境下,多个web应用时对同一个商品进行抢购和减库存操作时,可能出现超卖时会用到分布式锁
setnx key value //存入一个不存在的键值对,如果key不存在,同set;若存在,则不做任何操作
语法:SETNX key value
功能:当且仅当 key 不存在,将 key 的值设为 value ,并返回1;
若给定的 key 已经存在,则 SETNX 不做任何动作,并返回0。
4.3 list类型:
4.3.1 简介:
- 单键多值
- Redis列表是简单的字符串列表,按照插入顺序排序。可以添加一个元素到列表的头部(左边)或者尾部(右边)
- 底层是双向链表,对双端的操作性能很高,通过索引下标的操作中间的节点性能会较差
- 单个元素可以储存4GB数据

4.3.2 命令:
lpush/rpush key value1 value2 ...:从左边/右边插入一个或多个值(先进先出)lpop/rpop key:从左边/右边弹出一个数据,弹出后数据就不在list中了。rpoplpush key1 key2:从key1列表右边弹出一个值插入到key2的左边。lrange key start stop:按照索引下标获得元素(从左到右)
从头到尾:lrange key 0 -1llen key:获得列表长度lindex key index:获取index位置的元素(不弹出,从左往右)
lindex key -1:获取最后一个元素linsert key before/after value newvalue:在value的前/后面插入newvaluelrem key n value:从左边删除n个指定value(从左往右)
4.3.3 应用:
参考:https://blog.csdn.net/yaoyaochengxian/article/details/120401152
4.3.3.1 微信抢红包
关于微信抢红包,每个人应该都用过,我们今天就来聊聊这个抢红包的技术实现。
像微信抢红包的高峰期一般是在年底公司开年会和春节2个时间段,高峰的并发量是在几千万以上。
高峰的抢红包有3大特点:
- 包红包的人多:也就是创建红包的任务比较多,即红包系统是以单个红包的任务来区分,特点就是在高峰期红包任务多。
- 抢红包的人更多:当你发红包出去后,是几十甚至几百人来抢你的红包,即单红包的请求并发量大。
- 抢红包体验:当你发现红包时,要越快抢到越开心,所以要求抢红包的响应速度要快,一般1秒响应。
微信抢红包的技术实现原理:
- 包红包:
- 先把金额拆解为小金额的红包,例如 总金额100元,发20个,用户在点保存的时候,就自动拆解为20个随机小红包。
- 这里的存储就是个难题,多个金额(例如20个小金额的红包)如何存储?采用set、list、还是hash?set不能存储相同的值,也就无法用在金额相同的红包分发中;
- 代码:
public long setRedpacket(int total, int count) {
//拆解红包
Integer[] packet= this.splitRedPacket(total,count);
//为红包生成全局唯一id
long n=idGenerator .incrementId();
//采用list存储红包
String key=RED_PACKET_KEY+n;
this.redisTemplate.opsForList().leftPushAll(key,packet);
//设置3天过期
this.redisTemplate.expire(key,3, TimeUnit.DAYS);
log.info("拆解红包{}={}",key,packet);
return n;
}
- 抢红包:
- 高并发的抢红包时核心的关键技术,就是控制各个小红包的原子性。
- 例如 20个红包在500人的群里被抢,20个红包被抢走一个的同时要红包的库存减1,即剩下19个。
- 在整个过程中抢走一个 和 红包库存减1个 是一个原子操作。
- 那数据类型符合 “抢走一个 和 红包库存减1个 是一个原子操作” 采用set、list、还是hash?相对来说。list更加合适
- list的pop操作弹出一个元素的同时会自动从队列里面剔除该元素,它是一个原子性操作。
- 代码:
public int rob(long redid,long userid) {
//第一步:验证该用户是否抢过
Object packet=this.redisTemplate.opsForHash().get(RED_PACKET_CONSUME_KEY+redid,String.valueOf(userid));
if(packet==null){
//第二步:从list队列,弹出一个红包
Object obj=this.redisTemplate.opsForList().leftPop(RED_PACKET_KEY+redid);
if(obj!=null){
//第三步:抢到红包存起来
this.redisTemplate.opsForHash().put(RED_PACKET_CONSUME_KEY+redid,String.valueOf(userid),obj);
log.info("用户={}抢到{}",userid,obj);
//TODO 异步把数据落地到数据库上
return (Integer) obj;
}
//-1 代表抢完
return -1;
}
//-2 该用户代表已抢
return -2;
}
4.3.3.2 商品列表
聚划算商品页:https://ju.taobao.com/
这张页面的特点:
- 数据量少,才13页
- 高并发,请求量大。
像聚划算这种高并发的功能,绝对不可能用数据库的!
一般的做法是先把数据库中的数据抽取到redis里面。采用定时器,来定时缓存。
这张页面的特点,数据量不多,才13页。最大的特点就要支持分页。redis的 list数据结构天然支持这种高并发的分页查询功能。
具体的技术方案采用list 的lpush 和 lrange来实现。
代码:(此处直接用redis命令模拟存商品和获取商品代码)
## 先用定时器把数据刷新到list中
127.0.0.1:6379> lpush jhs p1 p2 p3 p4 p5 p6 p7 p8 p9 p10
(integer) 10
## 用lrange来实现分页
127.0.0.1:6379> lrange jhs 0 5
1) "p10"
2) "p9"
3) "p8"
4) "p7"
5) "p6"
6) "p5"
127.0.0.1:6379> lrange jhs 6 10
1) "p4"
2) "p3"
3) "p2"
4) "p1"
4.3.3.3 PV阅读量
- 并发量低的情况:通常情况我们使用
redisTemplate.opsForValue().increment(postId,num)就可以实现阅读量功能了。 - 并发量高的情况:假如每天有10万篇文章,每篇文章有10万次点击阅读;那么就需要10亿次自增操作,一天12小时高峰的话,平摊下来,Redis的QPS需要达到50多万,这就导致Redis服务器CPU必然达到了100%。
二级缓存的高并发微信文章的阅读量PV技术方案:
- 一级缓存定时器:
- JVM的缓存Map:
Map; - pvMap中的key存储的是时间块的值, Map
- 一级缓存定时器:将定时5分钟,将5分钟阅读量map放入Redis的List;
- List的value值为每隔时间块的阅读量map;
- 目的:是避免直接与Redis的阅读量计数器进行交互,分摊redis的并发量到本地的JVM,给JVM降压;
- JVM的缓存Map:
- 二级缓存定时器
- 定时将List的值拿出来,遍历每个map,先将数据插入数据库,再来修改文章阅读量计数器的值,使用incr;
- 目的:就是实现数据同步
这种方式利用了队列的特点;

具体实现:
- 模仿点击阅读量操作;
public class InitPVTask {
@Autowired
private RedisTemplate redisTemplate;
@PostConstruct
public void initPV(){
log.info("启动模拟大量PV请求 定时器..........");
new Thread(()->runArticlePV()).start();
}
/**
* 模拟大量PV请求
*/
public void runArticlePV() {
while (true){
this.batchAddArticle();
try {
//5秒执行一次
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
* 对1000篇文章,进行模拟请求PV
*/
public void batchAddArticle() {
for (int i = 0; i < 1000; i++) {
this.addPV(new Integer(i));
}
}
/**
*那如何切割时间块呢? 如何把当前的时间切入时间块中?
* 例如,我们要计算“小时块”,先把当前的时间转换为为毫秒的时间戳,然后除以一个小时,
* 即当前时间T/1000*60*60=小时key,然后用这个小时序号作为key。
* 例如:
* 2020-01-12 15:30:00=1578814200000毫秒 转换小时key=1578814200000/1000*60*60=438560
* 2020-01-12 15:59:00=1578815940000毫秒 转换小时key=1578815940000/1000*60*60=438560
* 2020-01-12 16:30:00=1578817800000毫秒 转换小时key=1578817800000/1000*60*60=438561
* 剩下的以此类推
*
* 每一次PV操作时,先计算当前时间是那个时间块,然后存储Map中。
*/
public void addPV(Integer id) {
//生成环境:时间块为5分钟
//long m5=System.currentTimeMillis()/(1000*60*5);
//为了方便测试 改为1分钟 时间块
long m1=System.currentTimeMillis()/(1000*60*1);
Map<Integer,Integer> mMap=Constants.PV_MAP.get(m1);
if (CollectionUtils.isEmpty(mMap)){
mMap=new ConcurrentHashMap();
mMap.put(id,new Integer(1));
//<1分钟的时间块,Map<文章Id,访问量>>
Constants.PV_MAP.put(m1, mMap);
}else {
//通过文章id 取出浏览量
Integer value=mMap.get(id);
if (value==null){
mMap.put(id,new Integer(1));
}else{
mMap.put(id,value+1);
}
}
}
}
- 一级缓存定时器
public class OneCacheTask {
@Autowired
private RedisTemplate redisTemplate;
@PostConstruct
public void cacheTask(){
log.info("启动定时器:一级缓存消费..........");
new Thread(()->runCache()).start();
}
/**
* 一级缓存定时器消费
* 定时器,定时(5分钟)从jvm的map把时间块的阅读pv取出来,
* 然后push到reids的list数据结构中,list的存储的书为Map<文章id,访问量PV>即每个时间块的pv数据
*/
public void runCache() {
while (true){
this.consumePV();
try {
//间隔1.5分钟 执行一遍
Thread.sleep(90000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("消费一级缓存,定时刷新..............");
}
}
public void consumePV(){
//为了方便测试 改为1分钟 时间块
long m1=System.currentTimeMillis()/(1000*60*1);
Iterator<Long> iterator= Constants.PV_MAP.keySet().iterator();
while (iterator.hasNext()){
//取出map的时间块
Long key=iterator.next();
//小于当前的分钟时间块key ,就消费
if (key<m1){
//先push
Map<Integer,Integer> map=Constants.PV_MAP.get(key);
//push到reids的list数据结构中,list的存储的书为Map<文章id,访问量PV>即每个时间块的pv数据
this.redisTemplate.opsForList().leftPush(Constants.CACHE_PV_LIST,map);
//后remove
Constants.PV_MAP.remove(key);
log.info("push进{}",map);
}
}
}
}
- 二级缓存定时器消费
public class TwoCacheTask {
@Autowired
private RedisTemplate redisTemplate;
@PostConstruct
public void cacheTask(){
log.info("启动定时器:二级缓存消费..........");
new Thread(()->runCache()).start();
}
/**
* 二级缓存定时器消费
* 定时器,定时(6分钟),从redis的list数据结构pop弹出Map<文章id,访问量PV>,弹出来做了2件事:
* 第一件事:先把Map<文章id,访问量PV>,保存到数据库
* 第二件事:再把Map<文章id,访问量PV>,同步到redis缓存的计数器incr。
*/
public void runCache() {
while (true){
while (this.pop()){
}
try {
//间隔2分钟 执行一遍
Thread.sleep(1000*60*2);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("消费二级缓存,定时刷新..............");
}
}
public boolean pop(){
//从redis的list数据结构pop弹出Map<文章id,访问量PV>
ListOperations<String, Map<Integer,Integer>> operations= this.redisTemplate.opsForList();
Map<Integer,Integer> map= operations.rightPop(Constants.CACHE_PV_LIST);
log.info("弹出pop={}",map);
if (CollectionUtils.isEmpty(map)){
return false;
}
// 第一步:先存入数据库
// TODO: 插入数据库
//第二步:同步redis缓存
for (Map.Entry<Integer,Integer> entry:map.entrySet()){
// log.info("key={},value={}",entry.getKey(),entry.getValue());
String key=Constants.CACHE_ARTICLE+entry.getKey();
//调用redis的increment命令
long n=this.redisTemplate.opsForValue().increment(key,entry.getValue());
// log.info("key={},pv={}",key, n);
}
return true;
}
}
- 查看浏览量
@GetMapping(value = "/view")
public String view(Integer id) {
String key= Constants.CACHE_ARTICLE+id;
//调用redis的get命令
String n=this.stringRedisTemplate.opsForValue().get(key);
log.info("key={},阅读量为{}",key, n);
return n;
}
4.3.3.4 推送帖子
前置条件:

发微博、帖子、文章push消息:
- 用户发微博,帖子时,先将数据插入DB,和Redis,再推送到个人主页List,和粉丝List;
- 当用户访问个人主页的时候,显示的是自己发过的微博,帖子或者文章等;使用List存储自己发过的微博,一页10页微博,并且可以进行分页查询;
- 当用户查看关注列表的时候,显示的是自己关注的人发的微博,文章等;
- 这就意味着:当用户发微博,首先推送到自己的个人主页List,再推送到粉丝的关注列表List;

当大明星发微博时,就会有大量粉丝来查询明星的个人主页;只能查Redis,不能查DB;不然直接夸了。
- 基于push技术,实现微博个人列表
/**
* push到个人主页
*/
public void pushHomeList(Integer userId,Integer postId){
String key= Constants.CACHE_MY_POST_BOX_LIST_KEY+userId;
this.redisTemplate.opsForList().leftPush(key,postId);
}
/**
* 获取个人主页列表
*/
public PageResult<Content> homeList(Integer userId,int page, int size){
PageResult<Content> pageResult=new PageResult();
List<Integer> list=null;
long start = (page - 1) * size;
long end = start + size - 1;
try {
String key= Constants.CACHE_MY_POST_BOX_LIST_KEY+userId;
//1.查询用户的总数
int total=this.redisTemplate.opsForList().size(key).intValue();
pageResult.setTotal(total);
//2.采用redis list数据结构的lrange命令实现分页查询。
list = this.redisTemplate.opsForList().range(key, start, end);
//3.去拿明细
List<Content> contents=this.getContents(list);
pageResult.setRows(contents);
}catch (Exception e){
log.error("异常",e);
}
return pageResult;
}
protected List<Content> getContents(List<Integer> list){
List<Content> contents=new ArrayList<>();
//发布内容的key
List<String> hashKeys=new ArrayList<>();
hashKeys.add("id");
hashKeys.add("content");
hashKeys.add("userId");
HashOperations<String, String ,Object> opsForHash=redisTemplate.opsForHash();
for (Integer id:list){
String hkey= Constants.CACHE_CONTENT_KEY+id;
List<Object> clist=opsForHash.multiGet(hkey,hashKeys);
//redis没有去db找
if (clist.get(0)==null && clist.get(1)==null){
Content obj=this.contentMapper.selectByPrimaryKey(id);
contents.add(obj);
}else{
Content content=new Content();
content.setId(clist.get(0)==null?0:Integer.valueOf(clist.get(0).toString()));
content.setContent(clist.get(1)==null?"":clist.get(1).toString());
content.setUserId(clist.get(2)==null?0:Integer.valueOf(clist.get(2).toString()));
contents.add(content);
}
}
return contents;
}
- 基于push技术,实现微博关注列表:发一条微博,批量推送给所有粉丝
/**
* 发一条微博,批量推送给所有粉丝
*/
private void pushFollower(int userId,int postId){
SetOperations<String, Integer> opsForSet = redisTemplate.opsForSet();
//读取粉丝集合
String followerkey=Constants.CACHE_KEY_FOLLOWER+userId;
//千万不能取set集合的所有数据,如果数据量大的话,会卡死
// Set sets= opsForSet.members(followerkey);
Cursor<Integer> cursor = opsForSet.scan(followerkey, ScanOptions.NONE);
try{
while (cursor.hasNext()){
//拿出粉丝的userid
Integer object = cursor.next();
String key= Constants.CACHE_MY_ATTENTION_BOX_LIST_KEY+object;
this.redisTemplate.opsForList().leftPush(key,postId);
}
}catch (Exception ex){
log.error("",ex);
}finally {
try {
cursor.close();
} catch (IOException e) {
log.error("",e);
}
}
}
- 查看关注列表
/**
* 获取关注列表
*/
public PageResult<Content> attentionList(Integer userId,int page, int size){
PageResult<Content> pageResult=new PageResult();
List<Integer> list=null;
long start = (page - 1) * size;
long end = start + size - 1;
try {
String key= Constants.CACHE_MY_ATTENTION_BOX_LIST_KEY+userId;
//1.设置总数
int total=this.redisTemplate.opsForList().size(key).intValue();
pageResult.setTotal(total);
//2.采用redis,list数据结构的lrange命令实现分页查询。
list = this.redisTemplate.opsForList().range(key, start, end);
//3.去拿明细数据
List<Content> contents=this.getContents(list);
pageResult.setRows(contents);
}catch (Exception e){
log.error("异常",e);
}
return pageResult;
}
优化:
优化方案采用:限定个人和关注list的长度为1000,即,
发微博的时候,往个人和关注list push完成后,把list的长度剪切为1000,
具体的技术方案采用list 的ltrim命令来实现。
LTRIM key start end
截取队列指定区间的元素,其余元素都删除
微博个人和关注列表的性能优化
//性能优化,截取前1000条
if(this.redisTemplate.opsForList().size(key)>1000){
this.redisTemplate.opsForList().trim(key,0,1000);
}
4.4 set
4.4.1 简介:
-
Set对外提供的功能与list类似,是一个列表的功能。特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这是list所不能提供的。
-
Set是String类型的无序集合。底层其实是一个value为null的hash表,所以添加删除查询的复杂度都是O(1)
-
类似java的set,可以用来求交集并集等
4.4.2 命令:
sadd key value1 value2.。。:将一个或多member元素加入到集合key中,如果有元素已经存在在key中,则会被忽略smembers key:取出 该集合的所有值simember key value:判断集合key中是否包含value,有返回1,没有返回0scard key:返回元素个数srem key value1 value2:删除集合中的一个或多个valuespop key:从集合中随机弹出一个值(弹出后不再在 列表中)srandmember key n:从集合中随机取出n个值,不会从集合中删除sinter key1 key2:返回2个集合的交集sunion key1 key2:返回2个集合的并集sdiff key1 key2:返回2个集合的差集(返回key1中有,key2中没有的)
4.4.3 应用:
4.4.3.1 淘宝黑名单
- 黑名单过滤器业务场景分析
淘宝的商品评价功能,不是任何人就能评价的,有一种职业就是差评师,差评师就是勒索敲诈商家。这种差评师在淘宝里面就被设置了黑名单,即使购买了商品,也评价不了。 - 解决的技术方案
黑名单过滤器除了针对上文说的淘宝评价,针对用户黑名单外,其实还有ip黑名单、设备黑名单等。在高并发的情况下,通过数据库过滤明显不符合要求,一般的做法都是通过Redis的set来实现的。- 步骤1:先把数据库的黑名单数据同步到redis的set集合中。
- 步骤2:评价的时候验证是否为黑名单,通过sismember命令来实现。
4.4.3.2 京东京豆抽奖
-
京东京豆抽奖的业务场景分析
可以无线抽,奖品是无限的,不同奖品的概率是不一样的;

-
京东京豆抽奖的技术方案(我项目中用的hash存放数据、随机数进行摇号,因为中签率不一样)
京豆抽奖一般是采用redis的set集合来操作的,那为什么是set集合适用于抽奖呢?- set集合的特点是元素不重复 存放1个 5个 10个京豆 谢谢参与
- set集合支持随机读取
- 具体的技术方案是采用set集合的srandmember命令来实现,随机返回set的一个元素
4.4.3.4 支付宝抽奖
思考一个问题:支付宝的抽奖 和 京东京豆的抽奖有什么区别????
- 京豆抽奖:奖品是可以重复,例如抽5京豆可以再抽到5京豆,即京豆是无限量抽。
- 支付宝抽奖: 奖品不能重复抽,例如1万人抽1台华为手机;再给大家举一个熟悉的例子:
例如公司年会,抽中奖品的人,下一轮就不能重复抽取,不然就会重复中奖。
- 技术方案和京东的京豆类似,但是不同的是
京东的京豆用了srandmember命令,即随机返回set的一个元素 - 支付宝的抽奖要用spop命令,即随机返回并删除set中一个元素
为什么呢? - 因为支付宝的奖品有限,不能重复抽,故抽奖完后,必须从集合中剔除中奖的人。
再举个每个人都参与过的例子,年会抽奖,你公司1000人,年会抽奖3等奖500名100元,2等奖50名1000元,1等奖10名10000元,
在抽奖的设计中就必须把已中奖的人剔除,不然就会出现重复中奖的概率。
这里如果考虑上中签率,可以初始化的时候,往列表中放入n个奖品(包括无奖),n可以自定义,主要考虑:
- 总抽奖人数
- 奖品中奖率
- 奖品数量
4.4.3.5 微博榜单与qq群的随机展示
- 随机展示业务场景分析
为什么要随机展示?因为展示的区域有限啊,在那么小的地方展示全部数据是不可能的,通常的做法就是随机展示一批数据,然后用户点击“换一换”按钮,再随机展示另一批 - 随机展示的redis技术方案
随机展示的原因就是区域有限,而区域有限的地方通常就是首页或频道页,这些位置通常都是访问量并发量非常高的,一般是不可能采用数据库来实现的,通常都是Redis来实现。
redis的实现技术方案:- 步骤1:先把数据准备好,把所有需要展示的内容存入redis的Set数据结构中。
- 步骤2:通过srandmember命令随机拿一批数据出来。
4.4.3.6 帖子点赞
-
微博点赞业务场景分析:
梳理点赞的业务场景,它有2个接口:- 点赞或取消点赞,用户点击功能
- 查看帖子信息:通过用户id 和帖子id,查看该帖子的点赞数、该用户是否点赞状态。
-
微博点赞的技术方案:
点赞的关键技术就是要判断该用户是否点赞,已重复点赞的不允许再点赞,即过滤重复,虽然业务不复杂,可以采用数据库直接实现。但是对于微博这种高并发的场景,不可能查数据库的,一般是缓存,即redis- 点赞或取消点赞,用户点击功能采用的是redis的set数据结构,
key=like:postid value={userid} - 采用scard命令,查看点赞总数,采用sismember命令,判断是否点赞
- 点赞或取消点赞,用户点击功能采用的是redis的set数据结构,
-
存在的问题:
- 这种方法只能记录帖子、评论的点赞数量和人数,不能记住流水
- 列表太多
# 采用sadd命令,添加点赞
127.0.0.1:6379> sadd like:1000 101
(integer) 1
127.0.0.1:6379> sadd like:1000 102
(integer) 1
127.0.0.1:6379> sadd like:1000 103
(integer) 1
127.0.0.1:6379> smembers like:1000
1) "101"
2) "102"
3) "103"
# 采用srem命令,取消点赞
127.0.0.1:6379> srem like:1000 101
(integer) 1
127.0.0.1:6379> smembers like:1000
1) "102"
2) "103"
# 获取点赞总数
127.0.0.1:6379> smembers like:1000
1) "102"
2) "103"
127.0.0.1:6379> scard like:1000
(integer) 2
# 判断是否点赞
127.0.0.1:6379> smembers like:1000
1) "102"
2) "103"
127.0.0.1:6379> sismember like:1000 102
(integer) 1
127.0.0.1:6379> sismember like:1000 101
(integer) 0
4.4.3.7 关注与粉丝
- 微博关注与粉丝的业务场景分析
我关注了雷军:我就是雷军的粉丝follower;
雷军被阿甘关注:雷军就是阿甘的关注followee; - 微博关注与粉丝的redis技术方案
技术方案:每个用户都有2个集合:关注集合和粉丝集合
例如 我关注了雷军,做了2个动作- 把我的userid加入雷军的粉丝follower集合set
- 把雷军的userid加入我的关注followee集合set
- 集合key设计
我的关注集合 key=follower:我的userid
雷军的粉丝集合 key=follower:雷军userid
4.4.3.8 微关系计算
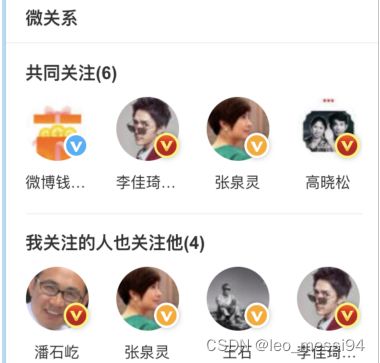
- 计算好友关系业务场景分析
微博微关系:
共同关注:是计算出我和雷军共同关注的人有哪些?
我关注的人也关注他:是计算出我关注的人群中,有哪些人同时和我一样关注了雷军 - 计算好友关系的redis技术方案
思考题:如果是采用数据库来实现用户的关系,一般SQL怎么写? 例如 阿甘关注10个人,雷军关注100个人,让你计算2人的共同关注那些人?- SQL的写法,一般是采用in 或 not in 来实现。但是对于互联网高并发的系统来说,in not in 明显不适合。
- 一般的做法是采用redis的set集合来实现。
Redis Set数据结构,非常适合存储好友、关注、粉丝、感兴趣的人的集合。然后采用set的命令就能得出我们想要的数据。- sinter命令:获得A和B两个用户的共同好友
- sismember命令:判断C是否为B的好友
- scard命令:获取好友数量
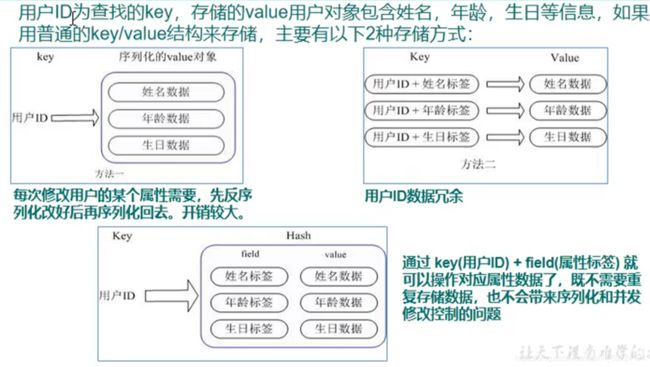
4.5 hash:
4.5.1 简介
- hash是一个键值对集合
- 是一个string类型的field和value的映射表,hash特别适合用于存储对象
- 类似java中的map
- 用户ID为key,存储的内容包括:姓名:小红,年龄:15.。。。
- Redis的hash结构更适合存储写频率高的Java对象。
- Redis只能对key进行设置过期时间,不能对key的field设置过期时间,这是值得注意的点;
4.5.2 命令:
hset key field value:给集合key中的field键赋值value
相当于key指向Maphget key field:从集合key中获取field键的值hmset key1 field1 value1 field2 value2...:批量设置hset值hexists key field:查看key集合中field键是否存在hkeys key:累出该hash集合的所有fieldhvals key:列出该hash集合的所有valuehincrby key field increment:为集合key的field键的值加上增量incrementhsetnx key field value:将集合key的field键的值设置为value,当且仅当field不存在,添加成功返回1,失败返回0
4.5.3 应用:
https://blog.csdn.net/yaoyaochengxian/article/details/120234850
4.5.3.1 本质上是存储java对象
redis存储java对象常用String,那为什么还要用hash来存储?

Redis存储java对象,一般是String 或 Hash 两种,那到底什么时候用String ? 什么时候用hash ?
- String的存储通常用在频繁读操作,它的存储格式是json,即把java对象转换为json,然后存入redis
- Hash的存储场景应用在频繁写操作,即:当对象的某个属性频繁修改时,不适用string+json的数据结构,因为不灵活,每次修改都需要把整个对象转换为json存储。
如果采用hash,就可以针对某个属性单独修改,不用序列号去修改整个对象。例如,商品的库存、价格、关注数、评价数经常变动时,就使用存储hash结果。
4.5.3.2 短连接
你们应该收到淘宝的短信:
【天猫】有优惠啦!黄皮金煌芒果(水仙芒)带箱10斤49.8元!
核薄无丝很甜喔!购买: c.tb.cn/c.ZzhFZ0 急鲜丰 退订回TD
这个 c.tb.cn/c.ZzhFZ0 就是短链接;
打开IE,输入 c.tb.cn/c.ZzhFZ0 就转变为如下一大坨
https://h5.m.taobao.com/ecrm/jump-to-app.html?scm=20140608.2928562577.LT_ITEM.1699166744&target_url=
http%3A%2F%2Fh5.m.taobao.com%2Fawp%2Fcore%2Fdetail.htm%3Fid%3D567221004504%26scm=20140607.2928562577.
LT_ITEM.1699166744&spm=a313p.5.1cfl9ch.947174560063&short_name=c.ZzhFZ0&app=chrome
短链接就是把普通网址,转换成比较短的网址。
短链接有什么好处?
- 节省网址长度,便于社交化传播。
- 方便后台跟踪点击量、统计。
《短链接转换器》的原理:
- 长链接转换为短链接
实现原理:长链接转换为短链接加密串key,然后存储于redis的hash结构中。 - 重定向到原始的url
实现原理:通过加密串key到redis找出原始url,然后重定向出去
4.5.3.3 购物车

登录淘宝后,逛淘宝时,点击商品加入购物车时,购物车中就会有一件对应的商品;
- 往购物车加入2件商品。采用hash数据结果,
key=cart:user:用户id
127.0.0.1:6379> hset cart:user:1000 101 1
(integer) 1
127.0.0.1:6379> hset cart:user:1000 102 1
(integer) 1
127.0.0.1:6379> hgetall cart:user:1000
1) "101"
2) "1"
3) "102"
4) "1"
- 修改购物车的数据,为某件商品添加数量
127.0.0.1:6379> hincrby cart:user:1000 101 1
(integer) 2
127.0.0.1:6379> hincrby cart:user:1000 102 10
(integer) 11
127.0.0.1:6379> hgetall cart:user:1000
1) "101"
2) "2"
3) "102"
4) "11"
- 统计购物车有多少件商品
127.0.0.1:6379> hlen cart:user:1000
(integer) 2
- 删除购物车某件商品
127.0.0.1:6379> hdel cart:user:1000 102
(integer) 1
127.0.0.1:6379> hgetall cart:user:1000
1) "101"
2) "2"
京东购物车:
京东在未登录的情况下,用户点击商品加入购物车后,购物车中自动就有了商品的信息,当用户退出重新进入网站后,再次点开购物车,商品还是存在的;
也就是京东网站使用Cookie机制为未登录的用户提供一个购物车ID;
当用户登录后,会将未登录时的购物车与登录后的购物车进行合并;
4.5.3.4 帖子点赞
-
使用set存放帖子点赞存在的问题:
- 这种方法只能记录帖子、评论的点赞数量和人数,不能记住流水
- 列表太多
-
redis设计:
- 所谓点赞记录缓存即“是否做了点赞这件事”,最终将持久化到数据库的点赞关系表上,用于表示某个用户是否已经点赞了某个作品。这里储存的是一种行为,或者称之为关系。
- 而点赞数量缓存即缓存某一个作品现在有多少点赞数。它缓存的是一个数字,并不能表示哪个用户点赞了哪个表。这储存的是一种数据。
- redis的hash可以指定一个Key,因此我们使用likeRecord和likeCount两个key来区分上述两种缓存。
- 用户点赞一条数据,设置状态为0,并且更新被点赞内容的likeCount+1
- 用户取消点赞一条数据,设置状态为1,并且更新被点赞内容的likeCount-1
-
键值对设计
- 点赞信息:
- key:likeRecord
- field: (String) 浏览信息id和点赞用户id拼接而成, 分隔符为::
- value: (HashMap) 存储点赞状态(0: 点赞 1:取消点赞)和更新时间的时间戳
- 即键值对为:
"浏览信息id::点赞用户id" value: {status: Integer, updateTime: long}
- 点赞数量
- field: (String) 浏览信息id
- value: (Integer) 点赞数量
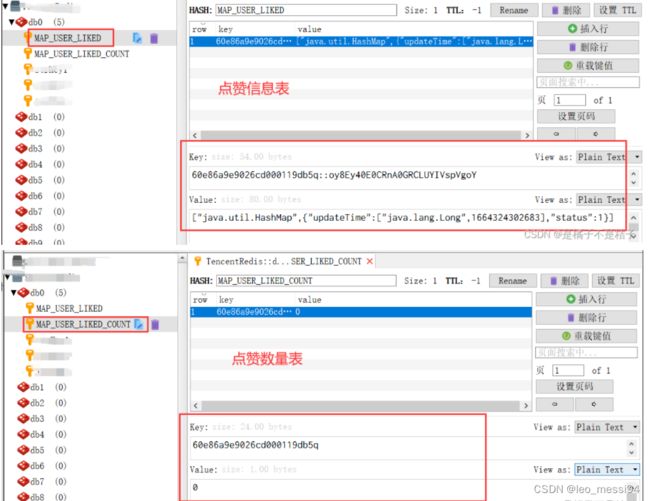
- 点赞信息:
-
操作步骤:
-
点赞:
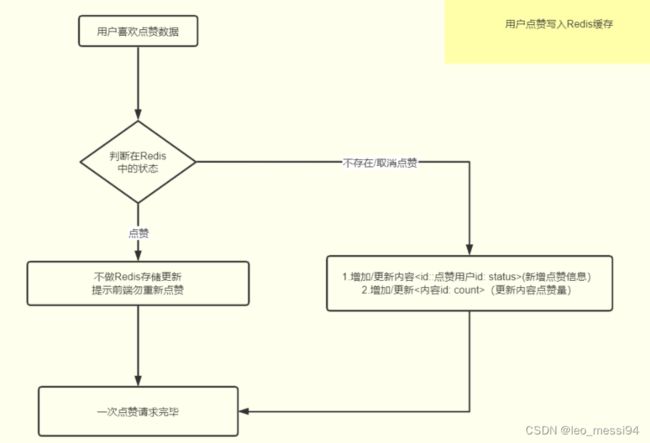
-
取消点赞:
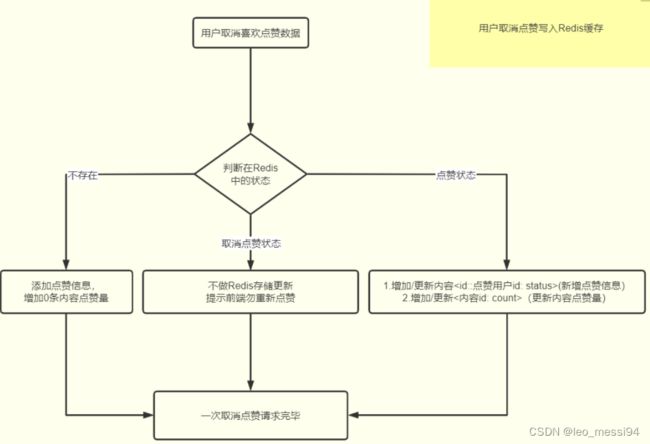
-
-
持久化:使用定时任务,定时加redis中的数据写入到数据库汇总

4.6 zset(sorted set)
4.6.1 简介:
Redis有序集合和普通集合set很相似,是一个没有重复元素的字符串集合。
不同之处时有序集合的每个成员都关联了一个评分(score),这个评分被用来按照最低分到最高分的方式排序集合种的成员。集合的成员是唯一的,但是分数可以重复。
因为元素是有序的,所有可以很快的根据评分或者次序来获取一个范围的元素。
访问有序集合的中间元素也是非常快的,因为你能够使用有序集合作为一个没有重复成员的智能列表。
最经典的应用就是排行榜。
4.6.2 命令:
zadd key score1 value1 score2 value2...:将一个或多个member元素及其score添加到有序集合key中zrange key start end (withscores):返回有续集key中,下标在start,stop之间的元素
带withscores,可以让分数一起和值返回到结果集zrangebyscore/zrevrangebyscore key min max (withscores) (limit offset count):返回有续集key中,所有score值介于【min,max】的成员。有序集按score值递增/递减排序zincrby key increment value:为元素的score加上增量zrem key value:删除集合中指定元素zcount key min max:统计【min,max】之间元素个数zrank key value:返回该值在集合中的排名,从0开始
4.6.3 应用:
4.6.3.1 排行榜
技术模拟思路:
采用26个英文字母来实现排行,随机为每个字母生成一个随机数作为score
实现:
- 先初始化1个月的历史数据
@Service
@Slf4j
public class InitService {
@Autowired
private RedisTemplate redisTemplate;
/**
* 先初始化1个月的历史数据
*/
public void init30day(){
//计算当前的小时key
long hour=System.currentTimeMillis()/(1000*60*60);
//初始化近30天,每天24个key
for(int i=1;i<24*30;i++){
//倒推过去30天
String key=Constants.HOUR_KEY+(hour-i);
this.initMember(key);
System.out.println(key);
}
}
/**
*初始化某个小时的key
*/
public void initMember(String key) {
Random rand = new Random();
//采用26个英文字母来实现排行,随机为每个字母生成一个随机数作为score
for(int i = 1;i<=26;i++){
this.redisTemplate.opsForZSet().add(key,String.valueOf((char)(96+i)),rand.nextInt(10));
}
}
}
- 定时5秒钟,模拟微博的热度刷新(例如模拟点赞 收藏 评论的热度值更新)
@Service
@Slf4j
public class TaskService {
@Autowired
private RedisTemplate redisTemplate;
/**
*2. 定时5秒钟,模拟微博的热度刷新(例如模拟点赞 收藏 评论的热度值更新)
* 3. 定时1小时合并统计 天、周、月的排行榜。
*/
@PostConstruct
public void init(){
log.info("启动初始化 ..........");
// 2. 定时5秒钟,模拟微博的热度刷新(例如模拟点赞 收藏 评论的热度值更新)
new Thread(()->this.refreshDataHour()).start();
// 3. 定时1小时合并统计 天、周、月的排行榜。
new Thread(()->this.refreshData()).start();
}
/**
*采用26个英文字母来实现排行,随机为每个字母生成一个随机数作为score
*/
public void refreshHour(){
//计算当前的小时key
long hour=System.currentTimeMillis()/(1000*60*60);
//为26个英文字母来实现排行,随机为每个字母生成一个随机数作为score
Random rand = new Random();
for(int i = 1;i<=26;i++){
//redis的ZINCRBY 新增这个积分值
this.redisTemplate.opsForZSet().incrementScore(Constants.HOUR_KEY+hour,String.valueOf((char)(96+i)),rand.nextInt(10));
}
}
/**
*刷新当天的统计数据
*/
public void refreshDay(){
long hour=System.currentTimeMillis()/(1000*60*60);
List<String> otherKeys=new ArrayList<>();
//算出近24小时内的key
for(int i=1;i<23;i++){
String key=Constants.HOUR_KEY+(hour-i);
otherKeys.add(key);
}
//把当前的时间key,并且把后推23个小时,共计近24小时,求出并集存入Constants.DAY_KEY中
//redis ZUNIONSTORE 求并集
this.redisTemplate.opsForZSet().unionAndStore(Constants.HOUR_KEY+hour,otherKeys,Constants.DAY_KEY);
//设置当天的key 40天过期,不然历史数据浪费内存
for(int i=0;i<24;i++){
String key=Constants.HOUR_KEY+(hour-i);
this.redisTemplate.expire(key,40, TimeUnit.DAYS);
}
log.info("天刷新完成..........");
}
/**
*刷新7天的统计数据
*/
public void refreshWeek(){
long hour=System.currentTimeMillis()/(1000*60*60);
List<String> otherKeys=new ArrayList<>();
//算出近7天内的key
for(int i=1;i<24*7-1;i++){
String key=Constants.HOUR_KEY+(hour-i);
otherKeys.add(key);
}
//把当前的时间key,并且把后推24*7-1个小时,共计近24*7小时,求出并集存入Constants.WEEK_KEY中
this.redisTemplate.opsForZSet().unionAndStore(Constants.HOUR_KEY+hour,otherKeys,Constants.WEEK_KEY);
log.info("周刷新完成..........");
}
/**
*刷新30天的统计数据
*/
public void refreshMonth(){
long hour=System.currentTimeMillis()/(1000*60*60);
List<String> otherKeys=new ArrayList<>();
//算出近30天内的key
for(int i=1;i<24*30-1;i++){
String key=Constants.HOUR_KEY+(hour-i);
otherKeys.add(key);
}
//把当前的时间key,并且把后推24*30个小时,共计近24*30小时,求出并集存入Constants.MONTH_KEY中
this.redisTemplate.opsForZSet().unionAndStore(Constants.HOUR_KEY+hour,otherKeys,Constants.MONTH_KEY);
log.info("月刷新完成..........");
}
/**
*定时1小时合并统计 天、周、月的排行榜。
*/
public void refreshData(){
while (true){
//刷新当天的统计数据
this.refreshDay();
// 刷新7天的统计数据
this.refreshWeek();
// 刷新30天的统计数据
this.refreshMonth();
//TODO 在分布式系统中,建议用xxljob来实现定时
try {
Thread.sleep(1000*60*60);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
*定时5秒钟,模拟微博的热度刷新(例如模拟点赞 收藏 评论的热度值更新)
*/
public void refreshDataHour(){
while (true){
this.refreshHour();
//TODO 在分布式系统中,建议用xxljob来实现定时
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
- 定时1小时合并统计 天、周、月的排行榜。
@RestController
@Slf4j
public class Controller {
@Autowired
private RedisTemplate redisTemplate;
@GetMapping(value = "/getHour")
public Set getHour() {
long hour=System.currentTimeMillis()/(1000*60*60);
//ZREVRANGE 返回有序集key中,指定区间内的成员,降序。
Set<ZSetOperations.TypedTuple<Integer>> rang= this.redisTemplate.opsForZSet().reverseRangeWithScores(Constants.HOUR_KEY+hour,0,30);
return rang;
}
@GetMapping(value = "/getDay")
public Set getDay() {
Set<ZSetOperations.TypedTuple<Integer>> rang= this.redisTemplate.opsForZSet().reverseRangeWithScores(Constants.DAY_KEY,0,30);
return rang;
}
@GetMapping(value = "/getWeek")
public Set getWeek() {
Set<ZSetOperations.TypedTuple<Integer>> rang= this.redisTemplate.opsForZSet().reverseRangeWithScores(Constants.WEEK_KEY,0,30);
return rang;
}
@GetMapping(value = "/getMonth")
public Set getMonth() {
Set<ZSetOperations.TypedTuple<Integer>> rang= this.redisTemplate.opsForZSet().reverseRangeWithScores(Constants.MONTH_KEY,0,30);
return rang;
}
}
一般情况下,我们浏览各大网站时,点击某篇文章,博客,帖子,其阅读量就会+1,或者点击 点赞按钮,又或是评论数量;
这些都会根据热度算法,计算其热度;
4.6.3.2 微博推送
- 场景:每个用户都有一个关注微博列表List,和个人微博列表List;
明星发表一条微博、如果使用 Redis List数据结构, 就需要先获取明星的粉丝集合,再将微博的ID发送到粉丝的List,如果粉丝的用户量不大,就几十万,还是勉强可以支撑的。适合中小型并发。但是像大明星,粉丝数量几千万,将明星微博的ID推送Push到粉丝的关注List,这个过程太耗时间,会直接把服务器给卡死了。
而且明星实时在线粉丝数量可能只有百分之一,也就是几十万。push操作短时间内看来相当于做了无用功; - 替代方案:使用zset pull 推送,每个用户都有一个关注微博列表Zset , 和个人列表Zset;
当用户登录后,主动去查询关注用户的微博;并将他们的微博放到自己的关注微博列表Zset里面;
PULL 与PUSH的差别
- push : 每次用户发微博都要异步推送给每个粉丝的关注列表;
- pull :每个粉丝查看关注微博列表,都需要主动去关注人的个人微博列表下拉取,再存储到自己的关注微博列表里;
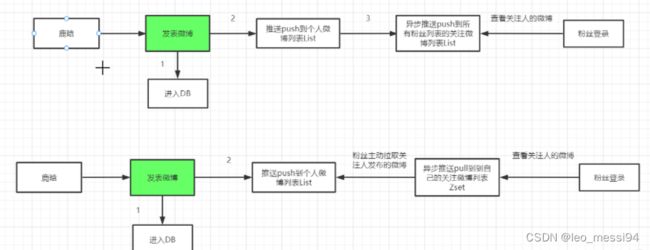
选择pull 方式, 需要自己去关注人的个人微博列表下拉取最新微博,这种方式可以通过客户端定时轮询服务端,查询最新的微博;
pull 技术方案

- 用户发微博、先写入DB、再写入Redis, 使用Hash数据结构存储微博 、
key = post::id - 异步推送到个人微博列表Zset;

为什么个人列表和关注列表采用zset集合?
- 拉取微博是根据刷新时间t进行过滤的,使用List集合的话,只能用将微博的发表时间和id一起转化为JSON字符串(或者将将ID写入list),再写入List, 获取数据时,需要根据时间进行过滤,就意味着,我们并不知道微博的发表时间,只能根据List的微博ID拉取全部微博JSON字符串,再获取发表时间,再进行过滤,太麻烦了,效率也很低;
- 使用Zset集合,将发表时间作为score, id作为value,查询时,根据score进行排序,进行过滤,进行分页查询,比List方便一点;
基于pull技术,实现微博个人列表
- 将数据存放到数据库
- 将数据存放到个人微博列表
@Slf4j
@Service
public class PullContentService extends ContentService{
/**
* 用户发微博
*/
public void post(Content obj){
Content temp=this.addContent(obj);
this.addMyPostBox(temp);
}
/**
* 发布微博的时候,加入到我的个人列表
*/
public void addMyPostBox(Content obj){
String key= Constants.CACHE_MY_POST_BOX_ZSET_KEY+obj.getUserId();
//按秒为单位
long score=obj.getCreateTime().getTime()/1000;
this.redisTemplate.opsForZSet().add(key,obj.getId(),score);
}
/**
* 获取个人列表
*/
public PageResult<Content> homeList(Integer userId, int page, int size){
PageResult<Content> pageResult=new PageResult();
List<Integer> list=new ArrayList<>();
long start = (page - 1) * size;
long end = start + size - 1;
try {
String key= Constants.CACHE_MY_POST_BOX_ZSET_KEY+userId;
//1.设置总数
long total=this.redisTemplate.opsForZSet().zCard(key);
pageResult.setTotal(total);
//2.分页查询
//redis ZREVRANGE
Set<ZSetOperations.TypedTuple<Integer>> rang= this.redisTemplate.opsForZSet().reverseRangeWithScores(key,start,end);
for (ZSetOperations.TypedTuple<Integer> obj:rang){
list.add(obj.getValue());
log.info("个人post集合value={},score={}",obj.getValue(),obj.getScore());
}
//3.去拿明细数据
List<Content> contents=this.getContents(list);
pageResult.setRows(contents);
}catch (Exception e){
log.error("异常",e);
}
return pageResult;
}
}
基于pull技术,实现微博关注列表
- 拿到个人关注的用户列表
- 获取到个人关注的用户的近两天发布的微博列表,并将这些数据存放到个人关注微博列表,时间作为score(只取前1000条数据)
/**
* 刷新拉取用户关注列表
* 用户第一次刷新或定时刷新 触发
*/
private void refreshAttentionBox(int userId){
//获取刷新的时间
String refreshkey=Constants.CACHE_REFRESH_TIME_KEY+userId;
Long ago=(Long) this.redisTemplate.opsForValue().get(refreshkey);
//如果时间为空,取2天前的时间
if (ago==null){
//当前时间
long now=System.currentTimeMillis()/1000;
//当前时间减去2天
ago=now-60*60*24*2;
}
//提取该用户的关注列表
String followerkey=Constants.CACHE_KEY_FOLLOWEE+userId;
Set<Integer> sets= redisTemplate.opsForSet().members(followerkey);
log.debug("用户={}的关注列表={}",followerkey,sets);
//当前时间
long now=System.currentTimeMillis()/1000;
String attentionkey= Constants.CACHE_MY_ATTENTION_BOX_ZSET_KEY+userId;
for (Integer id:sets){
//去关注人的个人主页,拿最新微博
String key= Constants.CACHE_MY_POST_BOX_ZSET_KEY+id;
Set<ZSetOperations.TypedTuple<Integer>> rang= this.redisTemplate.opsForZSet().rangeByScoreWithScores(key,ago,now);
if(!CollectionUtils.isEmpty(rang)){
//加入我的关注post集合 就是通过上次刷新时间计算出最新的微博,写入关注zset集合;再更新刷新时间
this.redisTemplate.opsForZSet().add(attentionkey,rang);
}
}
//关注post集合 只留1000个
//计算post集合,总数
long count=this.redisTemplate.opsForZSet().zCard(attentionkey);
//如果大于1000,就剔除多余的post
if(count>1000){
long end=count-1000;
//redis ZREMRANGEBYRANK
this.redisTemplate.opsForZSet().removeRange(attentionkey,0,end);
}
long days=this.redisTemplate.getExpire(attentionkey,TimeUnit.DAYS);
if(days<10){
//设置30天过期
this.redisTemplate.expire(attentionkey,30,TimeUnit.DAYS);
}
this.redisTemplate.opsForValue().set(refreshkey,now);
}