shardingJDBC教程-分库分表
shardingJDBC的介绍直接引用官网描述:
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
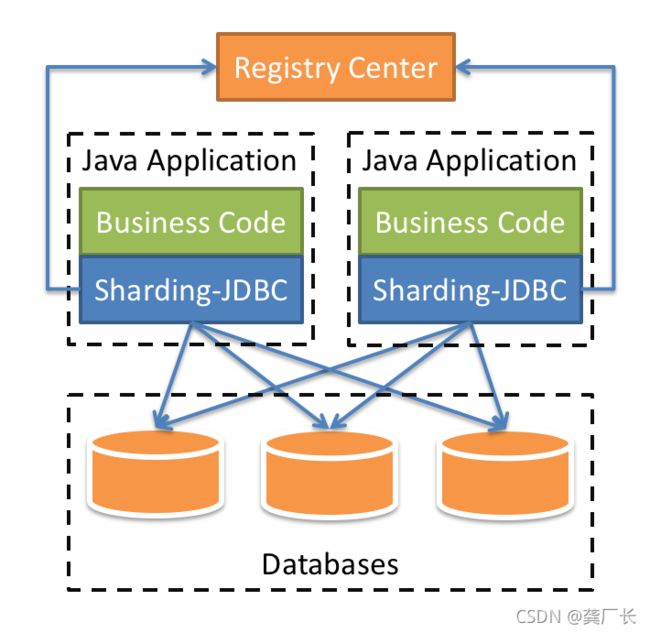
简单的说,shardingJDBC对应用相当于一个数据源,分库分表对应用是透明的,应用程序可以像使用单表一样访问分库分表。
下面将springboot与shardingJDBC结合起来,搭建一个分库分表应用。
本文目录
- 1、创建项目
- 2、水平分表
- 3、水平分库
- 4、广播表
- 参考文章
1、创建项目
下面是pom文件依赖的部分内容:
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.5.4version>
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.1.3version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.2.6version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.1.1version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
<exclusions>
<exclusion>
<groupId>org.junit.vintagegroupId>
<artifactId>junit-vintage-engineartifactId>
exclusion>
exclusions>
dependency>
dependencies>
2、水平分表
首先实现水平分表,之后介绍水平分库。
- 创建数据库sharding;
- 在数据库中创建两张表:person_01和person_02 ;
CREATE TABLE `person_01` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`sex` char(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
person_02与person_01字段完全一样。
- 分表规则:person_01存储id为偶数的记录,person_02存储id为奇数的记录;
- 根据上面的表结构生成实体类Person;
- 编写mapper文件:
public interface PersonMapper {
@Select("select * from person where id = #{id}")
public Person selectById(int id);
@Insert("insert into person(id,name,age,sex)value(#{id},#{name},#{age},#{sex})")
public void insert(Person p);
}
- 编写springboot配置文件:
#配置数据源的名称
spring.shardingsphere.datasource.names=ds
#配置数据源的数据库连接,注意中间的ds是数据源的名称
spring.shardingsphere.datasource.ds.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds.url=jdbc:mysql://127.0.0.1:3306/sharding?serverTimezone=UTC
spring.shardingsphere.datasource.ds.username=root
spring.shardingsphere.datasource.ds.password=root
#设置数据节点,数据节点由数据源名称和数据表组成,表示有哪些库和哪些表
spring.shardingsphere.sharding.tables.person.actual-data-nodes=ds.person_0$->{1..2}
#设置分表策略
#分表列名称
spring.shardingsphere.sharding.tables.person.table-strategy.inline.sharding-column=id
#使用行表达式分片策略
spring.shardingsphere.sharding.tables.person.table-strategy.inline.algorithm-expression=person_0${id%2+1}
分表规则使用行表达式,行表达式采用Groovy语法,下面文章对行表达式详细介绍:
https://shardingsphere.apache.org/document/legacy/4.x/document/cn/features/sharding/other-features/inline-expression/
还有一点需要特别注意:配置文件中,如果没有指定表的分库分表规则,而且也没有设置默认规则,shardingJDBC会随机选择一个数据源,并在该数据源下执行SQL语句。
- 编写测试类,测试效果:
@SpringBootTest
public class ShardingTest {
@Autowired
private PersonMapper personMapper;
@Test
public void insert(){
for (int i = 1; i <=5 ; i++) {
Person p = new Person();
p.setId(i);
p.setName("person"+i);
p.setSex("男");
p.setAge(10);
personMapper.insert(p);
}
}
@Test
public void query(){
for(int i=1;i<=6;i++) {
Person p = personMapper.selectById(i);
if(p!=null) {
System.out.println(p.getName());
}else{
System.out.println("查无此人");
}
}
}
}
-
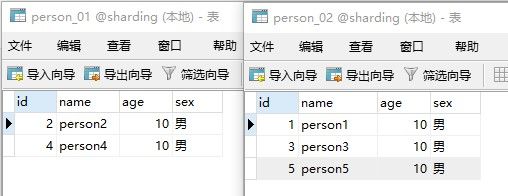
执行结果:
插入数据:
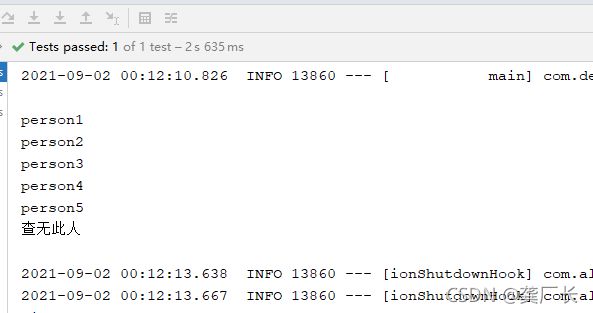
查询:
3、水平分库
下面借助于Groovy表达式,采用一个比较复杂的分库分表规则,这么做只是介绍如何使用Groovy表达式编写复杂规则,现实中估计不会使用这种蹩脚的方案,而且Groovy表达式越简单越好。
- 创建数据库sharding_01和sharding_02;
- 在sharding_01里面创建person_01表,在sharding_02里面创建person_02和person_03,表结构和上面一样;
- 分表规则:id%3=1的在person_01表,id%3=2的在person_02表,id%3=0的在person_03表;
- 实体类Person和mapper文件和上面一样;
- 编写springboot配置文件:
#配置数据源的名称
spring.shardingsphere.datasource.names=ds1,ds2
#配置数据源的数据库连接,注意中间的ds1和ds2是数据源的名称
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://127.0.0.1:3306/sharding_01?serverTimezone=UTC
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=root
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://127.0.0.1:3306/sharding_02?serverTimezone=UTC
spring.shardingsphere.datasource.ds2.username=root
spring.shardingsphere.datasource.ds2.password=root
#设置数据节点,数据节点由数据源名称和数据表组成,表示有哪些库和哪些表
spring.shardingsphere.sharding.tables.person.actual-data-nodes=ds$->{1..2}.person_0$->{1..3}
#设置分库策略
#分库列名称
spring.shardingsphere.sharding.tables.person.database-strategy.inline.sharding-column=id
#行表达式分片策略
spring.shardingsphere.sharding.tables.person.database-strategy.inline.algorithm-expression=ds$->{if(id%3==0||id%3==2) return 2;else return 1;}
#设置分表策略
#分表列名称
spring.shardingsphere.sharding.tables.person.table-strategy.inline.sharding-column=id
#使用行表达式分片策略
spring.shardingsphere.sharding.tables.person.table-strategy.inline.algorithm-expression=person_0$->{if(id%3==1) return 1;else if(id%3==2) return 2;else return 3; }
-
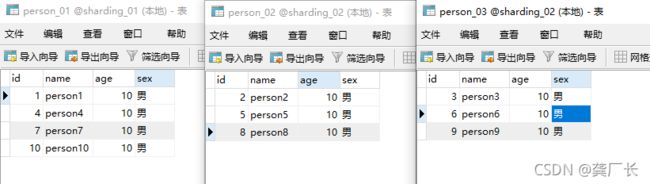
测试类和上面一样,只不过插入10条记录,直接看执行结果:
插入数据:
查询结果:
4、广播表
应用中有一种表比较特殊,这种表在每个数据库中都存在,而且数据都是一样的,这种表叫做广播表,它适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
shardingJDBC对广播表也进行了支持。
下面在数据库sharding_01和sharding_02增加一个表config,其表结构为:
CREATE TABLE `config` (
`id` int(11) NOT NULL,
`name` varchar(255) NOT NULL,
`value` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
在上面springboot配置文件的基础上增加如下配置:
#广播表
spring.shardingsphere.sharding.broadcast-tables=config
在应用中增加实体类Config,mapper文件如下:
public interface ConfigMapper {
@Select("select * from config where id = #{id}")
public Config selectById(int id);
@Insert("insert into config (id,name,value)value(#{id},#{name},#{value})")
public void insert(Config c);
}
编写测试类:
@SpringBootTest
public class BroadcastTest {
@Autowired
private ConfigMapper configMapper;
@Test
public void insert(){
for (int i = 1; i <=3 ; i++) {
Config c = new Config();
c.setId(i);
c.setName("test_key_"+i);
c.setValue("test_value_"+i);
configMapper.insert(c);
}
}
@Test
public void query(){
for(int i=1;i<=4;i++) {
Config c = configMapper.selectById(i);
if(c!=null) {
System.out.println(c.getName()+"="+c.getValue());
}else{
System.out.println("未找到对应配置");
}
}
}
}
执行结果如下:
插入数据:

可以看到,shardingJDB向每个库的表里面都插入了相同的数据。
参考文章
SPRING BOOT配置:https://shardingsphere.apache.org/document/legacy/4.x/document/cn/manual/sharding-jdbc/configuration/config-spring-boot/
行表达式:https://shardingsphere.apache.org/document/legacy/4.x/document/cn/features/sharding/other-features/inline-expression/