[root@bigdata04 flink-1.11.1]# bin/yarn-session.sh
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/yarn/exceptions/YarnException
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)
at java.lang.Class.privateGetMethodRecursive(Class.java:3048)
at java.lang.Class.getMethod0(Class.java:3018)
at java.lang.Class.getMethod(Class.java:1784)
at sun.launcher.LauncherHelper.validateMainClass(LauncherHelper.java:544)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:526)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.yarn.exceptions.YarnException
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 7 more
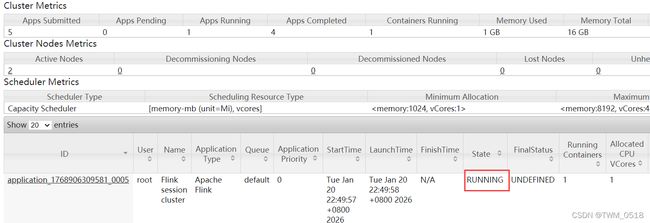
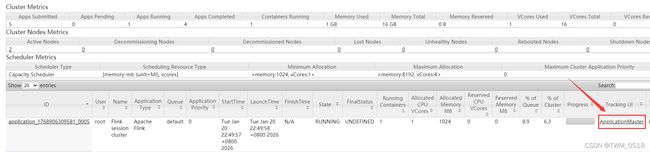
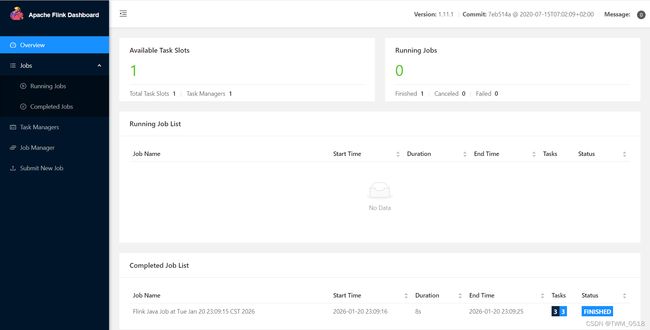
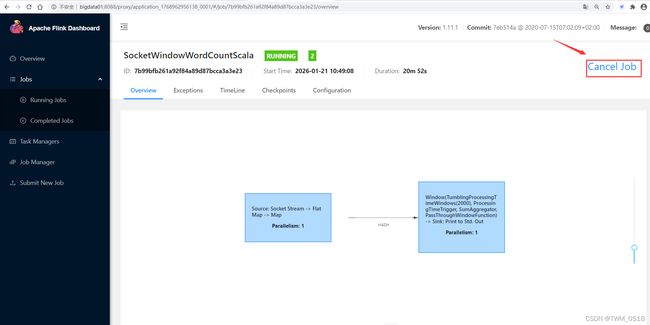
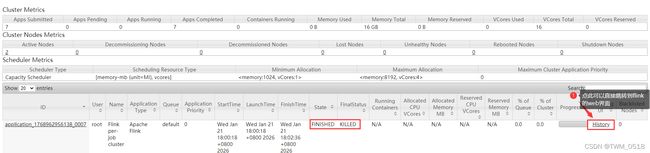
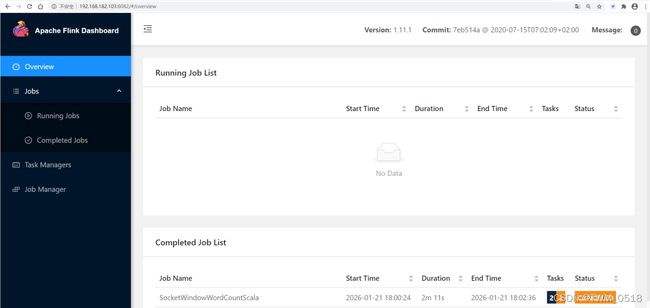
2026-01-20 22:50:06,767 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2026-01-20 22:50:06,768 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface bigdata02:34470 of application 'application_1768906309581_0005'.
JobManager Web Interface: http://bigdata02:34470
2026-01-20 22:50:06,982 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - The Flink YARN session cluster has been started in detached mode. In order to stop Flink gracefully, use the following command:
$ echo "stop" | ./bin/yarn-session.sh -id application_1768906309581_0005
If this should not be possible, then you can also kill Flink via YARN's web interface or via:
$ yarn application -kill application_1768906309581_0005
Note that killing Flink might not clean up all job artifacts and temporary files.
[root@bigdata04 flink-1.11.1]# yarn application -kill application_1768906309581_0005
2026-01-20 23:25:22,548 INFO client.RMProxy: Connecting to ResourceManager at bigdata01/192.168.182.100:8032
Killing application application_1768906309581_0005
2026-01-20 23:25:23,239 INFO impl.YarnClientImpl: Killed application_1768906309581_0005
针对yarn-session命令,它后面还支持一些其它参数,可以在后面传一个-help参数
[root@bigdata04 flink-1.11.1]# bin/yarn-session.sh -help
Usage:
Optional
-at,--applicationType Set a custom application type for the application on YARN
-D use value for given property
-d,--detached If present, runs the job in detached mode
-h,--help Help for the Yarn session CLI.
-id,--applicationId Attach to running YARN session
-j,--jar Path to Flink jar file
-jm,--jobManagerMemory Memory for JobManager Container with optional unit (default: MB)
-m,--jobmanager Address of the JobManager to which to connect. Use this flag to connect to a different JobManager than the one specified in the configuration.
-nl,--nodeLabel Specify YARN node label for the YARN application
-nm,--name Set a custom name for the application on YARN
-q,--query Display available YARN resources (memory, cores)
-qu,--queue Specify YARN queue.
-s,--slots Number of slots per TaskManager
-t,--ship Ship files in the specified directory (t for transfer)
-tm,--taskManagerMemory Memory per TaskManager Container with optional unit (default: MB)
-yd,--yarndetached If present, runs the job in detached mode (deprecated; use non-YARN specific option instead)
-z,--zookeeperNamespace Namespace to create the Zookeeper sub-paths for high availability mode
在这我对一些常见的命令进行了整理,添加了中文注释
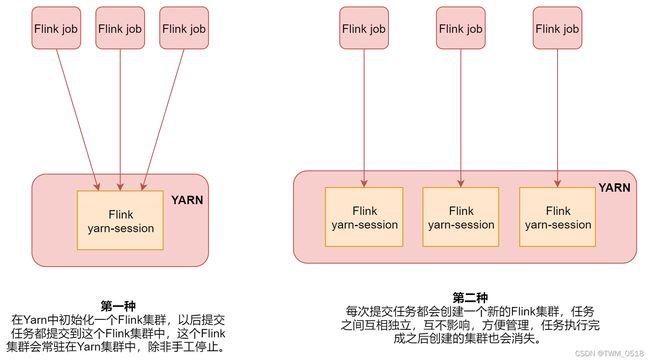
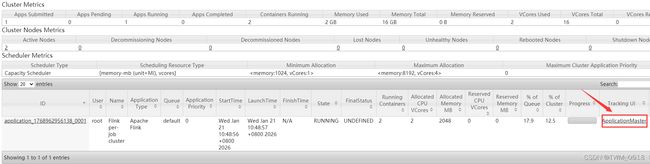
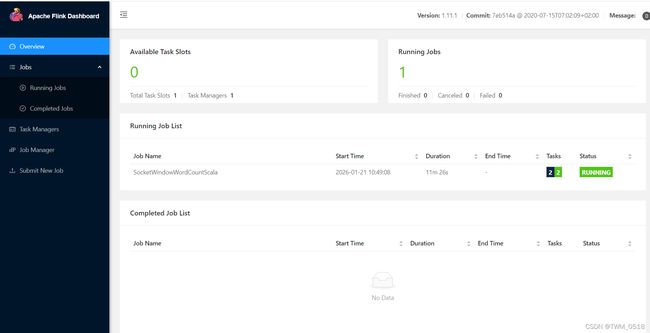
3、Flink ON YARN第二种方式
flink run -m yarn-cluster (创建Flink集群+提交任务) 使用flink run直接创建一个临时的Flink集群,并且提交任务 此时这里面的参数前面加上了一个y参数
ArcgisEngine实现对地图的放大、缩小和平移:
个人觉得是平移,不过网上的都是漫游,通俗的说就是把一个地图对象从一边拉到另一边而已。就看人说话吧.
具体实现:
一、引入命名空间
using ESRI.ArcGIS.Geometry;
using ESRI.ArcGIS.Controls;
二、代码实现.
Given a linked list and a value x, partition it such that all nodes less than x come before nodes greater than or equal to x.
You should preserve the original relative order of th