【jetson nano】jetson nano环境配置+yolov5部署+tensorRT加速模型
目录
- jetson nano环境配置+yolov5部署+tensorRT加速模型
-
- 致谢
- 主机和jetson nano环境
- jetson系统开机烧录、系统设置、换源
- python环境配置
- conda环境
- yolov5环境
- matplotlib和opencv-python
- tensorRT加速
- Jetson Nano的conda 虚拟环境中使用TensorRT
-
- 建立软链接
- 查看版本
- 运行export.py和detect.py
- 其他错误
-
- KeyError: 'names'
- 总结
- 其他可能有用的参考文章
- 图片展示
jetson nano环境配置+yolov5部署+tensorRT加速模型
断断续续地前后花了一个多星期配置环境以及部署模型,期间也报了无数错误,参考了很多文档,求助了身边的朋友,因此尽可能详细的记录一下这个过程。
致谢
此处感谢Xnhyacinth在配置过程中对我的帮助哈哈哈꒰ঌ( ⌯’ '⌯)໒꒱
主机和jetson nano环境
我主机上的环境是python3.9,cuda11.6
jetson nano环境jetpack4.6,cuda10.2,python3.6(conda)
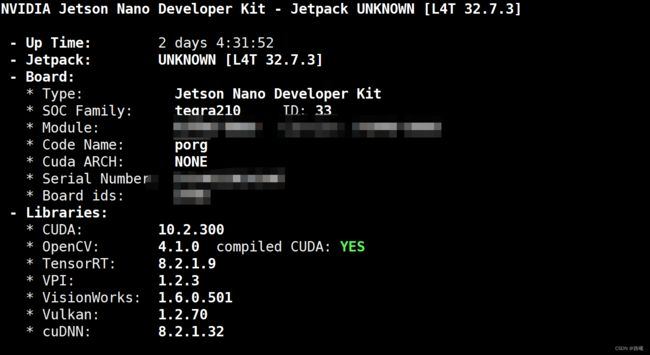
jetson系统开机烧录、系统设置、换源
先熟悉各个接口及其功能,具体可参考NVIDIA官方文档(见下文)先组装好买来的风扇,准备好无线网卡,我用的是即插即用的usb版本的无线网卡,JD上有卖,组装时发现jetson nano开发板上有一个跳线帽,那里默认是没有短接的,这样的话只能连接电脑电源,必须先把跳线帽短接才能连接直流电源。
NVIDIA jetson nano官网
刚开始的烧录,sd卡格式化以及相关工作都是对照这个来的,基本没什么问题。完成之后就可以得到一个Ubuntu18.04的系统,然后如果有无线网卡可以直接连接WiFi,我后面一般都是通过xshell连接开发板,直接在主机操作,除了需要查看图片或者视频的时候才接屏幕。
这个阶段我还部分参考了以下文档,在此做一个记录不赘述了。
Nvidia Jetson Nano介绍与使用指南
Jetson Nano 从入门到实战(案例:Opencv配置、人脸检测、二维码检测)这篇文章我主要参考了2.4.1到2.4.3的部分,配置了一些系统环境并换源,因为不换源下载东西速度可能比较慢,具体如何换源的网上资料很多,可以自行查阅。
python环境配置
刚开始我没有用虚拟环境,自带的环境里是python2.7,先下载3.6,又在环境里装了torch,花了好几天所有环境全部装完到最后跑yolov5的时候还是报错,然后请教了其他人,让我安装conda的虚拟环境,于是从头再来,重新装conda环境。前面的坑我就不说了,我们直接安装conda环境。建议卡在这里的也可以直接使用conda环境,确实方便很多。
conda环境
安装conda环境前我们要一直意识到一个问题,jetson nano是aarch64架构的,因此Jetson Nano开发板无法成功安装Anaconda。下载所有环境配置或者网上搜攻略都要加上jetson nano或者arm64位架构。conda环境同样如此,miniconda和anconda都不支持jetson nano,我们需要下载archiconda(Archiconda是用于64位ARM平台的Conda发行版),命令和使用方式和前两者都一样,所以也很方便。下载地址如下。
下载地址
安装完成之后按照在Windows系统上一样创建环境,(可以搜索如何用conda创建环境,我这里装的是python3.6)创建完成后激活环境(我给环境取名为yolov5)
#激活环境
conda activate yolov5
然后我们需要先安装很多包,很多很多。。我参考的是下面这个链接。建议这篇文章的第七步之前都可以按照作者写的走一遍,特别是下载一些包和cmake那段,一条一条命令复制过去安装,不然后面安装环境的时候会发现很多包下载不成功。
Jetson Nano部署YOLOv5与Tensorrtx加速——(自己走一遍全过程记录)
yolov5环境
然后接下来可以直接把你的yolo代码传到开发板上(我用的xftp),也可以先用官方的代码测试一下,先把环境跑一遍。我这里是先用官方代码跑了一遍再放的自己的代码。
先在jetson nano上安装一个git,然后直接
git clone https://github.com/ultralytics/yolov5.git
应该默认的是v7.0,反正是测试无关紧要。git下来之后,cd到yolov5主目录下,直接
pip install -r requirements.txt
应该有一部分下载不成功,先别着急,可以试着看看里面有哪些包需要安装,一个一个安装,尽量选低一些版本,实在不行手动下载安装包到本地然后安装,有找不到的包可以去pypi.org搜索下载,注意选择历史版本,然后选合适的python版本和系统版本,关键词“linux”“cp36”“arrch64”。

matplotlib和opencv-python
我当时遇到的情况是有两个包安装不上,耽搁了一天,一个是matplotlib,一个是opencv-python。第二个包我甚至参考了很多网上的编译安装opencv的教程,用c++编译安装的方式折腾了很久,实际上不需要,只要参考Jetson Nano部署YOLOv5与Tensorrtx加速——(自己走一遍全过程记录)并把作者的那些环境配置安装完之后就解决了。
全部环境安装完成之后直接命令行切到主目录然后输入python detect.py执行,如果下载速度很慢可以提前去yolov5官方仓库把yolov5s.pt下载到主目录,没有报错就会在run/detect/exp目录下生成两张图片,这就成功了。
tensorRT加速
tensorRT本质上就是把模型压缩,变得更快,因为jetson nano算力不够所以需要加速。官方仓库在这里我参考的仓库里面的README.md文档,按照他的指令转化成wts以及engine格式的模型文件。
另外还包括以下几篇文章的tensor加速部分。但是以下文章的该部分仅供参考,要确保自己的yolo以及各项版本和你下载的tensorRT一致(实际上很有可能不一致,也就是说即使生成了engine文件也用不了)。
Jetson nano上部署自己的Yolov5模型(TensorRT加速)onnx模型转engine文件
Jetson Nano部署YOLOv5与Tensorrtx加速——(自己走一遍全过程记录)
之所以说仅供参考是因为
1. 里面的部分内容与实际情况不一致
比如修改训练好的模型数量,默认是80我们不需要修改,但如果是自己训练的模型就需要修改,修改地址并非他们所说的tensorrtx/yolov5/yololayer.h,而是应该参考官方文档README里面的这样一句话:
cd [PATH-TO-TENSORRTX]/yolov5/
# Update kNumClass in src/config.h if your model is trained on custom dataset
上面的注释中提到了如果要修改分类数量应该在src/config.h文件中更新kNumClass变量

但是还是有可能报错,TensorRT生成engine文件异常([TRT] Network::addScale::434, condition: shift.count > 0 ?)(这是可能出现的问题之一,我还遇到了其他的错误,比如生成了engine文件却不能适配等),如果用下面的方法就不会出现这个问题。
2. 其实并不需要用上述方法,如果你是跑yolo模型
实际上yolov5主目录里有export.py,可以直接调用tensorRT包实现把模型从xx.pt到xx.engine的转换,非常方便,不需要其他操作。并且jetson nano有自带的tensorRT包,我们只需要和我们的conda环境里的包的安装目录建立软连接即可。具体方法见下节
Jetson Nano的conda 虚拟环境中使用TensorRT
建立软链接
TensorRT的系统安装路径为:/usr/lib/python3.6/dist-packages/tensorrt/(这个是大家都一样不变的)
执行以下命令,建立虚拟环境(自己的虚拟环境)对应的软链接(注意自己的archiconda的安装目录,这是本人目录仅供参考/home/alen123/archiconda3/envs/yolov5/lib/python3.6/site-packages)
sudo ln -s /usr/lib/python3.6/dist-packages/tensorrt* /home/alen123/archiconda3/envs/yolov5/lib/python3.6/site-packages
查看版本
>>> python
>>> import tensorrt
>>> tensorrt.__version__
运行export.py和detect.py
完成上步工作之后,tensorRT已经作为一个包可以直接调用了,然后直接在终端执行以下代码:
python export.py --weights yolov5.pt --include engine -- device 0
可能会报错,告诉你部分包未安装,这时候别着急安装,先cat requirements.txt,查找对应的包,以onnx为例,找到requirements.txt里面onnx对应的版本,直接在命令行下载文件要求的最低版本,默认应该是被注释掉了,在Export里面,我的是
# onnx>=1.9.0 # ONNX export
所以直接
pip install onnx==1.9.0
其他包同样如此。
重新执行
python export.py --weights yolov5.pt --include engine -- device 0
会生成一个engine文件。如果想要在开发板上跑时有更快的速度可以加--half,降低精度的,同时可以显著提高速度,我跑自己的模型时没用tensorRT加速速度是>100ms每帧。加速后,但加--half前速度大约是50ms每帧,加了--half之后是30ms每帧。
python export.py --weights yolov5.pt --include engine --half -- device 0
然后就会生成一个xx.engine文件,再执行detect.py,可以在文件里改,如果懒得改也可以直接命令行改模型:
python detect.py --weights yolov5.engine
这样就大功告成了,如果换成自己训练好的模型也是一样的,注意模型名字,数据路径什么的变化。
其他错误
其实一遍下来还有很多其他琐碎的错误,但有些在调试过程中解决了就没有全记录下来,接下来想到可能会慢慢补充。
KeyError: ‘names’
File "detect.py", line 368, in <module>
main(opt)
File "detect.py", line 262, in main
run(**vars(opt))
File "/home/alen123/archiconda3/envs/yolov5/lib/python3.6/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "detect.py", line 98, in run
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
File "/home/alen123/yolov5-7.0/models/common.py", line 500, in __init__
names = yaml_load(data)['names'] if data else {i: f'class{i}' for i in range(999)}
KeyError: 'names'
在跑自己的模型时遇到的,原因是数据的yaml文件里面没有模型类别名字,在自己训练的模型的yaml文件最后加上即可。我的模型只有开关两类,所以我要加上下面的内容。
names:
0: open
1: closed
总结
花了3个小时写的,内容有点仓促,可能会慢慢补充,大家可以和我交流,如有错误之处恳请指正。总得来说在业界jetson nano的配置和使用都比较完善,资料也比较齐全,所以费点时间都可以在网上找到,谨以此文做一个备份和记录供大家参考。
其他可能有用的参考文章
Nvidia Jetson nano 安装Archiconda、gpu版torch、踩坑记录
win10 yolov5转换Tensorrt的engine模型全流程安装运行解读(使用TRT的PythonApi)
图片展示

