【信用评分预测模型(四)】Python随机森林模型
文章目录
- 前言
- 一、随机森林介绍
- 一、定义函数
- 二、模型建立
-
- 1.模型参数设置
- 2.模型训练集和测试集拆分
- 3.模型训练
- 4.特征值
- 总结
前言
在https://blog.csdn.net/m0_65157892/article/details/129523883这篇文章中已经对数据进行了标准化和异常值处理。得到了一个新的数据集,且数据集是不受极端值影响的数据集。
在另外一篇文章中讲解了普遍情况下的随机森林预测模型,在这篇文章将运用在信用评分预测上。
一、随机森林介绍
首先了解一下集成学习,集成学习(ensemble)思想是为了解决单个模型或者某一组参数的模型所固有的缺陷,从而整合起多个模型,取长补短,避免局限性。
集成时一般用到bootstrap方法(自助法,随机抽样),bagging方法(自助抽样集成,多个模型,使用投票或其他方法来整合模型,分类问题一般类似投票,回归问题一般均值)
随机森林就是集成学习思想下的产物,将许多棵决策树整合成森林,合并用来预测最终结果。实际上是一种特殊的bagging方法,将决策树用作bagging中的模型。
用bootstrap方法生成m个训练集,然后,对于每个训练集,构造一颗决策树。不同的是选择特征时是随机抽取部分特征取最优解来分裂。预测阶段,采用的是bagging的策略,分类问题就是投票(回归问题则为均值)。
随机森林算法可被用于很多不同的领域,如银行,股票市场,医药和电子商务。在银行领域,它通常被用来检测那些比普通人更高频率使用银行服务的客户,并及时偿还他们的债务。同时,它也会被用来检测那些想诈骗银行的客户。在金融领域,它可用于预测未来股票的趋势。在医疗保健领域,它可用于识别药品成分的正确组合,分析患者的病史以识别疾病。除此之外,在电子商务领域中,随机森林可以被用来确定客户是否真的喜欢某个产品。
一、定义函数
def list_add(a, b):
# 这个函数实现列表a与列表b相加,同时相加后的值存到列表a中
assert len(a) == len(b)
for i in range(len(a)):
a[i] += b[i]
def list_div(a, num):
# 这个函数将列表a的各值除以num,同时将处理后的值存到列表a中
for i in range(len(a)):
a[i] /= num
return a
这个定义的函数是为了在后面模型训练打下基础的。
二、模型建立
1.模型参数设置
acc_mean = 0
acc_mean_10test = 0
feature_mean = [0] * len(df.columns[:-1])
n = 1000
max_acc = 0;
index_of_max = 0 # 何时的acc最大,以及对应的index
min_acc = 1;
index_of_min = 0 # 何时的acc最小,以及对应的index
max_arg_acc = 0;
index_of_max_acc2 = 0 # 何时的acc最大,以及对应的index
# 树的个数
trees = 10
- 我们在这里是将循环次数设置为n = 1000
- 即在随机划分训练集和测试集时,穷举随机数种子为1-1000时的情况
- trees = 10随机森林数量设置为10
2.模型训练集和测试集拆分
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.6, random_state=i + 1)
x_test2, x_check, y_test2, y_check = train_test_split(x_test, y_test, train_size=0.25, random_state=i + 1)
3.模型训练
在这里我们需要先定义一个函数train_test(),通过这个函数我们可以训练随机森林模型,不断地迭代直到出现最合适的解出现。
def train_test():
global acc_mean, acc_mean_10test, max_acc, max_arg_acc, min_acc, index_of_max, index_of_max_acc2, index_of_min
for i in range(50):
# print('*'*150)
print('第 %d 次 test' % (i + 1))
# x_test,x_train,y_test,y_train=train_test_split(x,y,random_state=i+1)
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.6, random_state=i + 1)
x_test2, x_check, y_test2, y_check = train_test_split(x_test, y_test, train_size=0.25, random_state=i + 1)
forest = RandomForestClassifier(n_estimators=trees, random_state=100)
#y_train改成y_train.astype('int')
forest.fit(x_train, y_train.astype('int'))
# 经测试,random_state=594时验证集上精度最高
# n_estimators表示树的个数,测试中10颗树足够
# print('*'*100)
# print('start')
test_score = forest.score(x_check, y_check.astype('int')) # 300条数据得到的score
# print("random forest with %d trees:"%trees)
print("accuracy on the training subset:{:.3f}".format(forest.score(x_train, y_train.astype('int'))))
print("accuracy on the test subset:{:.3f}".format(test_score))
# print("avg accuracy on the test subset:{:.3f}".format(acc_mean/(i+1)))
# print('Feature importances:{}'.format(forest.feature_importances_))
if (max_acc <= test_score):
max_acc = test_score
index_of_max = i + 1
if (min_acc >= test_score):
min_acc = test_score
index_of_min = i + 1
acc_mean += test_score # check subset mean
print("i times avg accuracy on the check subset:{:.3f}".format(acc_mean / (i + 1)))
acc_mean2 = 0 # 临时的
acc_mean2 += test_score
print('10 check score')
for j in range(10):
# x_test2,x_train2,y_test2,y_train2=train_test_split(x,y,random_state=j+1)
# x_train2,x_test2,y_train2,y_test2=train_test_split(x,y,random_state=j+1)
# x_train2,x_test2,y_train2,y_test2=train_test_split(x,y,train_size=0.4,test_size=0.4,random_state=j+1)
# x_train2,x_test2,y_train2,y_test2=train_test_split(x,y,test_size=0.4,random_state=j+1)
x_test2, x_check, y_test2, y_check = train_test_split(x_test, y_test, train_size=0.25,
random_state=j + 1) # 划分10次check集
acc_mean2 += forest.score(x_check, y_check.astype('int'))
print(forest.score(x_test2, y_test2.astype('int')), end=' ')
print()
print("avg accuracy on the 11 check subset:{:.3f}".format(acc_mean2 / 11)) # 在此模型下多次划分check集合得到一个平均精度
acc_mean2 = acc_mean2 / 11
# 得到最大时的index
if (max_arg_acc <= acc_mean2):
max_arg_acc = acc_mean2
index_of_max_acc2 = i + 1
list_add(feature_mean, forest.feature_importances_)
acc_mean_10test += acc_mean2
print("all-avg accuracy on the 10 check subsets:{:.3f}".format(acc_mean_10test / (i + 1)))
# 得到一千次训练的平均精度
# 然后暂时可以先用最高精度构造出分类器后测试其在不同测试集上的精度
# print()
print('Final :')
print("avg accuracy on the check subset:{:.3f}".format(acc_mean / n))
# print('avg Feature importances:{}'.format(list_div(feature_mean,n)))
print('max_acc on the check subset: %f' % max_acc)
print('index : %d' % index_of_max)
print('min_acc on the check subset: %f' % min_acc)
print('index : %d' % index_of_min)
print('max_arg_acc on 11 check subsets: %f' % max_arg_acc)
print('index : %d' % index_of_max_acc2)
train_test()
4.特征值
train_test()
# x_train,x_test,y_train,y_test=train_test_split(x,y,train_size=0.4,test_size=0.4,random_state=index_of_max_acc2)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.4, random_state=index_of_max_acc2)
x_test2, x_check, y_test2, y_check = train_test_split(x_test, y_test, train_size=0.25, random_state=index_of_max_acc2)
# x_test,x_train,y_test,y_train=train_test_split(x,y,random_state=index_of_max_acc2)
forest = RandomForestClassifier(n_estimators=trees, random_state=100)
forest.fit(x_train, y_train.astype('int'))
result_acc = 0
result_acc += forest.score(x_check, y_check.astype('int'))
for j in range(10):
x_test2, x_check, y_test2, y_check = train_test_split(x_test, y_test, train_size=0.25, random_state=j + 1)
print(forest.score(x_check, y_check.astype('int')), end=' ')
# print(forest.predict(x_check))
result_acc += forest.score(x_check, y_check.astype('int'))
print()
print("avg accuracy on the 11 check subsets:{:.3f}".format(result_acc / 11))
# 做出特征重要性的图
n_features = x.shape[1]
plt.barh(range(n_features), forest.feature_importances_, align='center')
plt.yticks(np.arange(n_features), names)
plt.title("random forest with %d trees:" % trees)
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.show()
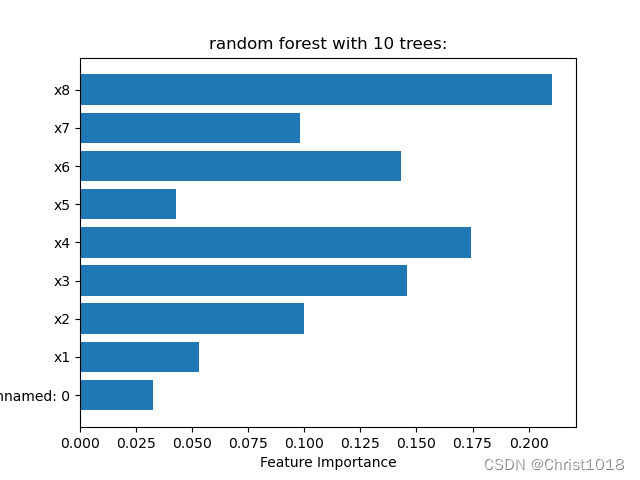
通过模型的迭代求出最佳取值,将所求出的最佳值用来特征值选取,从而求得哪个变量的影响因素最大。
总结
通过随机森林模型,我们可以求出特征变量的特征值,银行在进行信用评分时,可以根据这些变量来对决策进行修改。如上图所示即特征值得分,通过这个特征值我们可以看到,第八个变量的特征值得分最高,最低的得分是第五个变量,因此在进行信用赋分时,我们可以按照不同的特征值,赋予不同的权重,使预测更加准确。