【文本分析学习】Anaconda+pytorch虚拟环境下的pycharm文本分析(含分词、词性标注、词形归一化、停用词、文本情感分析、词频、文本相似度,附数据代码) NLTK
【文本分析】Anaconda+pytorch虚拟环境下的pycharm文本分析 NLTK
- 一、准备工作
-
- (一)Anaconda、pytorch、pycharm安装
- 二、Pycharm解释器配置
- 三、Pycharm中的文本分析下载基本的包
-
- (一)下载nltk、jieba
- (二)下载语料库
- (三)下载wordcloud
- 四、Pycharm中使用NLTK进行文本分析
-
- (一)文本预处理
-
- 1.分词
- 2.词性标注
- 3.词形归一化
- 4.删除停用词
- (二)文本情感分析
-
- 1.基于情感词典
- 2.基于机器学习
- (三)文本相似度
- (四)
- 参考:
一、准备工作
(一)Anaconda、pytorch、pycharm安装
详情见前文:【深度学习】Anaconda:Windows 中 非英伟达显卡(CPU版本)下的 Pytorch安装与环境配置及pycharm安装使用
注意:目前pycharm软件通过设置可以显示中文,详细的可以自行搜索,将pycharm汉化,需要注意pycharm版本不能太低,我之前使用了2020版,版本太低,没办法兼容汉化软件。
另外,虚拟环境下的pycharm下载包,一直报错,在本文中也有解决!!!
(/ _ \,倒腾了我一个周末!)
二、Pycharm解释器配置
选择已有环境、pytorch虚拟环境
三、Pycharm中的文本分析下载基本的包
(一)下载nltk、jieba
- 直接在设置里面下载 ,搜索相关名字,进行安装;
- 或者通过命令 pip install jieba
(二)下载语料库
- 输入命令nltk.download() ,在跳出的窗口选择File-download,然后点击File-change download directory全部下载,注意初次下载会有点慢;
import nltk
nltk.download()
- 测试语料库是否下载成功
form.nltk.corpus import brown
brown.words()
#或者使用内置的案例进行测试
import nltk
from nltk.book import *
(三)下载wordcloud
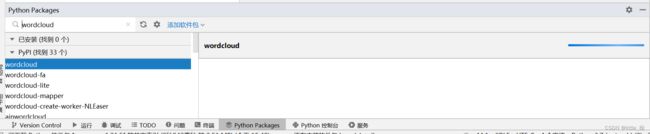
注意:可能是使用了虚拟环境,直接用这个下载包,一直报错,
某天突然突发奇想,又倒腾了一下,发现能下载了,点 文件-设置-解释器
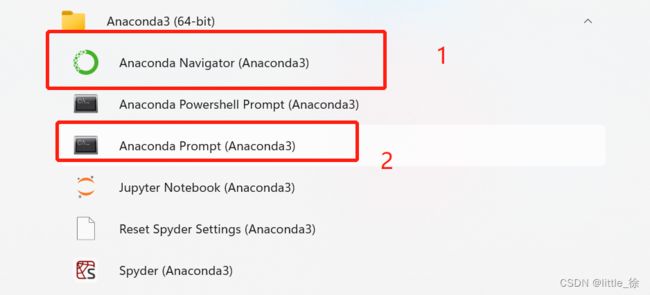
还有一种方法!
由于使用了Anaconda+pytorch虚拟环境 所以可以通过该虚拟环境下载第三方库
首先:打开1.Anaconda Navigator 找到相应的环境进行第三方库的搜索,没有的话再打开Anaconda Prompt
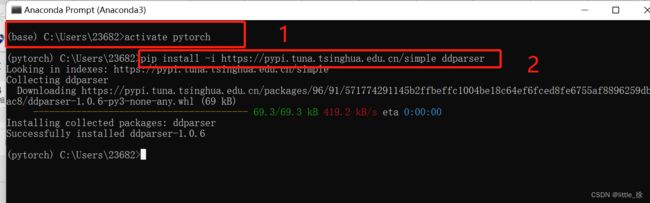
然后:转到相应的环境中 输入activate pytorch
最后:输入下载命令 ,使用清华镜像快速安装,pip install -i https://pypi.tuna.tsinghua.edu.cn/simple ddparser
因为我安装的是ddparser第三方库 所以输入这个,相应的需要哪个第三方库,就下载哪个。
完成~

四、Pycharm中使用NLTK进行文本分析
(一)文本预处理
1.分词
(1)英文分词:调用nltk中的word_tokenize()函数
import nltk
Sentence = 'I like blue'
words =nltk.word_tokenize(Sentence)
print(words)
以上内容,可以参考链接
(2) 中文分词:用到jieba包
jieba库是第三方中文分词函数库,需要额外安装。
import jieba
Sentence = "我要去吃饭"
term_list =jieba.cut(Sentence,cut_all=False)
print('[精确模式]:'+'/'.join(term_list))

2.词性标注
(1)英文分词:调用nltk中的word_tokenize()函数
https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/packages/taggers/averaged_perceptron_tagger.zip
备注:将文件解压之后,命名放入该文件夹下 C:\Users\23682.conda\envs\pytorch\share\nltk_data
import nltk
words = nltk.word_tokenize("There are many difficulties in learning English.")
print(nltk.pos_tag(words))
PS:中文如何进行词性标注
3.词形归一化
(1)词干提取:使用波特词干提取器,用于删除词性的词缀
from nltk.stem.porter import PorterStemmer
porter_stem = PorterStemmer()
words = porter_stem.stem('watched')
print(words)
类似还有兰卡斯特词干提取器、Snowballstemmer等
(2)词形还原:基于词根还原单词,使用wordNetLemmatizer类
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
wordl = lemmatizer.lemmatize('went')
wordll = lemmatizer.lemmatize('goods')
wordlll = lemmatizer.lemmatize("went", pos="v")
print(wordl)
print(wordll)
# 如果需要得到更精确的词元,需要告诉 WordNetLemmatizer 你感兴趣的词性是什么。n v a
print(wordlll)

4.删除停用词
(1)需要下载相对应的语料库:停用词表(中文:哈工大停用词表、百度停用词列表、中文停用词库)
其他参考:www.ranksml/stopwoeds
from nltk.corpus import stopwords
text = 'There are many difficulties in learning English'
words =nltk.word_tokenize(text)
stop_words =stopwords.words('english')
remain_list =[]
for word in words:
if word not in stop_words:
remain_list.append(word)
print(remain_list)

注意,标点符号并不会删除,所以需要查找 在分析之后,再删除符号的代码
另外,最后输出的remain_list 是列表 remain_list =[],所以直接读取会产生问题,因此需要找到相应的解决办法。(数据读取有待加强)
错误示范:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
textl = lemmatizer.lemmatize(remain_list)
print(textl)

(二)文本情感分析
指又称为倾向性分析和意见挖掘,指对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。
目前分两种,基于情感词典、基于机器学习。
1.基于情感词典
代码案例补充
PS:缺陷,当遇到一些新词或特殊词,无法识别,扩展性有待加强。
2.基于机器学习
(1)朴素贝叶斯:基于概率论的分类算法。
提前下载好nltk.classify模块中的NaiveBayesClassifier类,
该类中有一个类方法train(),主要用于根据训练集来训练模型。
import nltk
# 按 Shift+F10 执行或将其替换为您的代码。
# 按 双击 Shift 在所有地方搜索类、文件、工具窗口、操作和设置。
from nltk.stem.porter import PorterStemmer
from nltk.stem import WordNetLemmatizer
from nltk.classify import NaiveBayesClassifier
from nltk.corpus import stopwords
#准备用于训练的文本
text_one = "This is a wonderful book."
text_two = "I like reading this book very much."
text_thr = "This book reads well."
text_fou = "This book is not good."
text_fiv = "This is a very bad book."
def pret_text(text):
#文本预处理:分词、词性归一化,删除停用词
words = nltk.word_tokenize(text)
wordnet = WordNetLemmatizer()
words = [wordnet.lemmatize(word) for word in words]
# 删除停用词的操作
remain_list=[word for word in words if word not in stopwords.words('english')]
print(remain_list)
#遍历词 得到对应的词是否在文本中 列中元素编为字典,并标记为Ture
return {word: True for word in remain_list}
print(pret_text(text_one))
print(pret_text(text_two))
# 构建训练文本
train_data = [[pret_text(text_one),1],[pret_text(text_two),1],[pret_text(text_thr),1],[pret_text(text_fou),-1],[pret_text(text_fiv),-1]]
print(train_data )
# 训练得到模型
model = NaiveBayesClassifier.train(train_data)
# 模型的测试
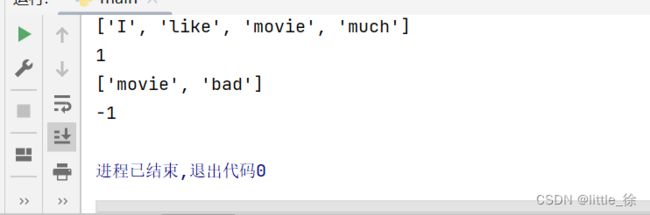
test_text1="I like this movie very much"
test_text2="this movie is very bad"
print(model.classify(pret_text(test_text1)))
print(model.classify(pret_text(test_text2)))
(三)文本相似度
通过词频,计算文本相似度
import nltk
from nltk.stem.porter import PorterStemmer
from nltk.stem import WordNetLemmatizer
from nltk.classify import NaiveBayesClassifier
from nltk.corpus import stopwords
from nltk import FreqDist
text1 = "John likes to watch movies"
text2 = "John also likes to watch footballl games"
all_text = text1 + ' ' + text2
print (all_text)
#分词
word = nltk.word_tokenize(all_text)
#创建FreqDist对象,记录每个词出现的频率
freq_dist = FreqDist(word)
print(freq_dist["likes"])
#取出5个常用的单词
most_comman_words = freq_dist.most_common(5)
print(most_comman_words)
#找到单词所在的位置
def find_position(comman_words):
"""
查找常用单词
:param comman_words:
:return:
"""
result = {}
pos = 0
for word in comman_words:
result[word[0]]= pos
pos += 1
return result
# 调用方法,记录常用单词对应的位置
pos_dict = find_position(most_comman_words)
print(pos_dict)
def text_to_vector(words):
"""
将文本转换成词频向量
:param words:
:return:
"""
ferq_vec = [0] * 5
# 在常用的单词列表上计算词频
for word in words:
if word in list(pos_dict.keys()):
ferq_vec[pos_dict[word]] += 1
return ferq_vec
#获取text1 、text2的词频向量
vec1 = text_to_vector(nltk.word_tokenize(text1))
print(vec1)
vec2 = text_to_vector(nltk.word_tokenize(text2))
print(vec2)
#计算文本的相似度
from nltk.cluster.util import cosine_distance
sim = cosine_distance(vec1,vec2)
print(sim)
(四)
import pandas as pd
file_data = pd.read_csv("./商品评价信息.csv", encoding='gbk')
print(file_data)
print(file_data.head())
#对数据进行去重
file_data = file_data.drop_duplicates(keep= False)
print(file_data)
补充知识:
data.drop_duplicates(subset=[‘A’,‘B’],keep=‘first’,inplace=True)
subset: 列名,可选,默认为None ;
keep: {‘first’, ‘last’, False}, 默认值 ‘first’
- first: 保留第一次出现的重复行,删除后面的重复行。
- last: 删除重复项,除了最后一次出现。
- False: 删除所有重复项。
#词云
wc = WordCloud(font_path=,background_color="white", width=1000, height=800).generate(" ".join(new_data))
plt.imshow (wc)
plt.axis("off")
plt.show()
import pandas as pd
import jieba
from nltk import FreqDist
from wordcloud import WordCloud
from matplotlib import pyplot as plt
#导入数据
file_data = pd.read_csv("./商品评价信息.csv", encoding='gbk')
print(file_data)
#print(file_data.head())
#对数据进行去重
file_data = file_data.drop_duplicates(keep= False) #False: 删除所有重复项。)
#print(file_data)
#针对每个评价进行jieba分词
#使用精准的划分方式
Sentence =str(file_data["评价信息"].values)
cut_words =jieba.lcut(Sentence,cut_all=False)
#print(cut_words)
#加载停用词列表
#读取停用词
with open('./stopword.txt') as f:
stop_words = f.read()
new_data = []
for word in cut_words:
if word not in stop_words:
new_data.append(word)
print(new_data)
#词频统计
freq_list = FreqDist(new_data)
most_comman_words =freq_list.most_common()
print(most_comman_words)
#
wc = WordCloud(font_path='./simhei.ttf', background_color="white", width=1000, height=800).generate(" ".join(new_data))
plt.imshow (wc)
plt.axis("off")
plt.show()
结果显示:
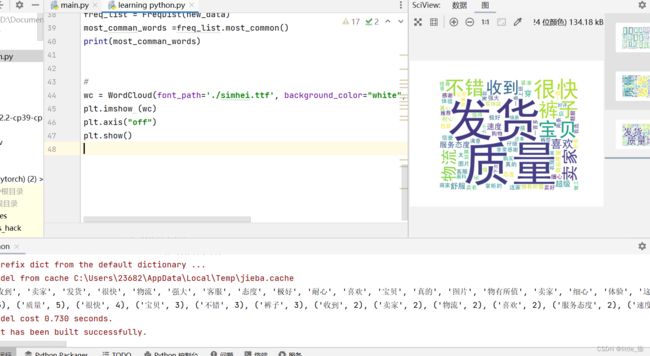
大功告成~~~~
附上本文数据:文本分析附件220926.zip
参考:
本文基于B站UP主视频,进行学习操作,并根据自己的软件环境进行改进。代码、数据及相关文件均由本人自己整理。感兴趣的小伙伴可以去原视频进行观看,尊重原创视频。
B站视频,Python-文本数据分析