Linux TC 流量控制与排队规则 qdisc 树型结构详解(以HTB和RED为例)
1. 背景
Linux 操作系统中的流量控制器 TC (Traffic Control) 用于Linux内核的流量控制,它规定建立处理数据包的队列,并定义队列中的数据包被发送的方式,从而实现对流量的控制。
每个网络接口会有一个入队列(ingress)和一个出队列(egress),入队列功能较少。Linux流量控制主要是在输出接口进行处理和实现的。本文也都是基于出队列。
TC 模块实现流量控制功能使用的排队规则分为两类:无分类排队规则、分类排队规则。无分类排队规则相对简单,而分类排队规则则引出了分类和过滤器等概念,使其流量控制功能增强。
2. 流量控制组件
2.1 qdisc 排队规则
qdisc(队列规则,queueing discipline)是 Linux 流量控制系统的核心。实际就是一个队列上面附加的排队规则,下文有时也直接称为队列。
qdisc其实就是一个调度器,每个网络接口都会有一个调度器,qdisc会根据调度器的规则重新排列数据包进入队列的顺序。
-
无类排队规则
对进入网络设备(网卡)的数据流不加区分统一对待,能够接收数据包以及重新编排、延迟或丢弃数据包。可以对整个网络设备(网卡)的流量进行整形,但不能细分各种情况。
[p|b]fifo:简单先进先出pfifo_fast:根据数据包的tos将队列划分到3个band,每个band内部先进先出red:Random Early Detection,随机早期探测,带宽接近限制时随机丢包,适合高带宽应用sfq:Stochastic Fairness Queueing,随机公平队列,按照会话对流量排序并循环发送每个会话的数据包tbf:Token Bucket Filter,令牌桶过滤器,只允许以不超过事先设定的速率到来的数据包通过 , 但可能允许短暂突发流量朝过设定值
-
有类排队规则
对进入网络设备的数据包根据不同的需求以分类的方式区分对待。对数据包进行分类的工具是过滤器,队列规定就根据过滤器的决定把数据包送入相应的类进行排队。每个子类都可以再次使用它们的过滤器进行进一步的分类。绝大多数分类的队列规定还能够对流量进行整形。这对于需要同时进行调度和流量控制的场合非常有用。
cbq:Class Based Queueing,基于类别排队,借助EWMA(exponential weighted moving average, 指数加权移动均值 ) 算法确认链路的闲置时间足够长 , 以达到降低链路实际带宽的目的。如果发生越限 ,CBQ就会禁止发包一段时间。htb:Hierarchy Token Bucket,分层令牌桶,在tbf的基础上增加了分层prio:分类优先算法并不进行整形 , 它仅仅根据你配置的过滤器把流量进一步细分。缺省会自动创建三个FIFO类。
Linux默认的排队规则是pfifo_fast,这是一种比FIFO稍微复杂一点的排队规则。一个网络接口上如果没有设置qdisc,pfifo_fast就作为缺省的qdisc。
由于项目需要这里主要讨论在输出口使用 RED 和 HTB。
2.2 class 分类
类(class)仅存在于可分类的 qdisc 之下,过滤器(filter)也只能附加在有分类排队规则上。
类组成一个树,理论上能无限扩展。一个类可以仅包含一个叶子qdisc(默认为pfifo_fast),也可以包含多个子类,子类又可以包含一个叶子qdisc或者多个子类。 这就给 Linux 流量控制系统予以了极大的可扩展性和灵活性。
每个 class 和有类 qdisc 都需要一个唯一的标识符,称为句柄(handle)。标识符由一个主编号和一个子编号组成,编号必须是数字。句柄仅供用户使用,内核会使用自己的一套编号来管理流量控制组件对象。习惯上,需要为有子类的qdisc显式的分配一个句柄。
qdisc 的子编号必须为0,而分类的子编号必须是非0值。同一个qdisc对象下所有子类对象的主编号必须相同。
例如 root qdisc句柄为 1:0(或者1:),它的子类句柄可以为 1:1、1:2、1:3等等。
特别地,ingress qdisc (入队列)的编号总是 ffff:0。
这个结构会在后面详细说明。
2.3 filter 过滤器
**过滤器(filter)**即根据数据包的某属性进行匹配,进行分类后送到不同的队列上。过滤器能与 有分类qdisc 相关联,也可以和 class 相关联。
树的每个节点都可以有自己的过滤器,但是高层的过滤器也可以直接用于其子孙类。所有的出站数据包首先会通过 root qdisc,接着被与 root qdisc 关联的过滤器进行分类,进入子分类,并被子分类下的过滤器继续进行分类。如果数据包没有被成功归类,就会被排到这个类的叶子qdisc的队中。或者也可以只对根分类提供一个过滤器,然后为每个子分类提供路由映射。
过滤器使用**分类器(classifier)**进行数据包匹配,最常用的分类器是 u32 分类器,它可以根据数据包中的各个字段对数据包进行分类,例如源IP等。
**决策器(policer)**只能配合 filter 使用。当流量高于用户指定值时执行一种操作,反之执行另一种操作。在 Linux 流量控制系统中,想要丢弃数据包只能依靠决策器。决策器可以把进入队列的数据包流速限定在一个指定值之下。另外,它也可以配合分类器,丢弃特定类型的数据包。
3. 树型结构详解
流量控制(Traffic Control, TC)以qdisc - class - filter的树形结构来实现对流量的分层控制。
当Linux内核接收数据包时,先根据过滤器进行分类,符合条件的数据包就被归为相应的类,而每一个类都对应一个相应的排队规则。如果一个数据包对于所有的过滤条件都不满足,则该数据包会被归为缺省类,将会使用缺省的队列规定对其进行处理(默认pfifo_fast)。
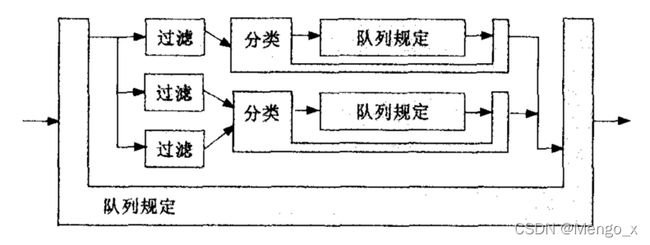
Linux在实现TC的时候,对“队列”进行了抽象,基本上它维护了两个回调函数指针,一个是enqueue入队操作,一个是dequeue出队操作。不管是enqueue还是dequeue,都并不一定真正将数据包排入队列,而仅仅是“执行一系列的操作”:
- 对于叶子节点,排入一个真实的队列或者从真正的队列拉出一个数据包;
- 递归调用其它抽象队列的enqueue/dequeue。
所以对于非叶子节点的qdisc,实际上是一个“不存在的队列”,数据包没有实际在此排队,只是递归调用子类的队列。只有在叶子节点上的队列才是真正能存放发出数据包的队列。
所以实际的树状结构如下:

一般为有子类的qdisc显式的分配一个句柄,方便添加过滤器和子类。
root qdisc 只是一个抽象队列,句柄为1:0。一个类有且仅有一个叶子 qdisc(可不显示分配句柄),默认为pfifo_fast。这个qdisc也可自行设置,此时就与父节点不再是同一个 qdisc 对象,随后将进行递归调用。若这个类有其他子类,那数据包就会通过类的过滤器进行分类进入子类,如果没有被成功归类,就会被排到这个类的叶子 qdisc 中。
同一个 qdisc 对象中,父节点的 filter 可以直接作用于子孙类,例如图中 root qdisc 的过滤器直接调用句柄为 1:6 的类。
数据包流入过程如下:
- 如上图所示,数据包从网卡进入后,首先经过
root qdisc 1:0,此处根上的是可分类队列,则会经过filter分到对应子类中。 - 若进入
class 1:2,则此类的规则生效后,直接进入这个类的叶子 qdisc 排队(默认pfifo_fast)。 - 若进入
class 1:1,则此类的规则生效后,进入一个新的qdisc 2:0,这个qdisc 也是可分类队列,所以数据包会经过filter进入子类,后续过程即递归调用。 - 若进入
class 1:3,则规则生效后会经过filter进入此类的子类,注意这里和root qdisc属于同一个对象。如果没有满足的分类规则,数据包会进入此类的默认叶子qdisc排队。 - 数据包进入
class 1:4,这里就会进入新的qdisc 4:0,此qdisc 是无分类队列,所以没有过滤器和子类。这个队列下也可直接接新的无分类队列qdisc z:0(此处是叶子队列,没有显式分配具柄),或者像class 1:5一样,qdisc 5:0后接新的可分类队列qdisc 6:0。
3. qdisc算法及使用
3.1 RED
随机早期探测(Random Early Detection,RED)是一种无分类qdisc。
当队列达到特定的平均长度,入队列的报文会有一定的(可配置)概率会被丢弃,这个概率会线性地增加到某一点,称为最大平均队列长度。
这种方式在队列增长时就开始随机丢包,使队列不至于太长,可以避免在流量突增之后导致的丢包重传(而这些重传会导致更多的重传)。
如果使用 ecn 参数,则以某概率丢包改为以某概率做 ECN 标记,即把IP数据包的ECT CE位置为 11。
用法
tc qdisc ... red limit BYTES [min BYTES] [max BYTES] avpkt BYTES [burst PACKETS] [probability PROBABILITY] [bandwidth KBPS] [ecn] [adaptive] [harddrop]
参数:
limit:真实队列的硬性限制,单位为字节,与 RED 算法无关。应当设置为大于最大队列长度与突发报文之和max + burst,超过此值后,接收到的报文都将被丢弃。RED正常工作的情况下,队列长度不会达到此值。min:单位为字节。开始进行标记的平均队列大小,默认为max/3。max:单位为字节。平均队列大小达到该值后,标记的概率达到最大(probability)。为了避免同步重传,应该至少是min的两倍,且大于最小的min值,默认为limit/4。Avpkt:单位是字节,与burst一起确定平均队列长度avg的时间常数。建议值1000(MTU为1500时)。burst:桶大小,决定了计算平均队列长度avg在多大程度上受到实际队列长度的影响。较大的值会减慢avg更新的速度,从而允许在标记开始之前出现更多的突发流量。实际经验遵循(min+min+max)/(3*avpkt)。probability:标记的概率的最大值(队列长达到max时),为0.0到1.0之间的浮点数,默认为0.02。bandwidth:该速率用于在一段空闲时间之后计算平均队列的大小,设置为接口的带宽,但不会进行整流。默认值为10Mbit。ecn:允许RED对支持ECN的主机以报文标记的形式通知拥塞(除非队列达到limit的字节数),推荐使用。harddrop**: 如果平均队列长度大于max字节数,则强制丢弃报文,而不是进行ECN标记。adaptive:Adaptive-RED算法,旨在通过动态调整probability的值(范围:[0.01,0.50]),将队列长度维持在 (max-min)/2。
通过计算最高可接受的基本排队延迟来设置min,并将其乘以带宽。例如,在 64kbit/s ISDN 链路上,想要 200 毫秒的基本排队延迟,因此我将min设置为 1600 字节
( 64 × 200 / 8 = 1600 64×200/8=1600 64×200/8=1600)。
设置 min 太小会降低吞吐量,太大会降低延迟。设置较小的最小值并不能替代降低慢速链路上的 MTU 以改善交互响应。
3.2 HTB
HTB(Hierarchy Token Bucket,分层令牌桶)是一种有分类排队规则,允许把一条物理链路模拟成几条更慢的链路,或者是把发出的不同类型的流量模拟成不同的连接。
它使用了令牌和桶的概念,并使用了基于类的系统和过滤器对流量进行复杂和细粒度的控制。通过一个复杂的借用模型,HTB可以实现各种复杂的流量控制技术。另一种最简单的方式是在整流时使用HTB。
用法
添加 htb qdisc:
... qdisc add ... htb [default N] [r2q N] [direct_qlen P]
-
default未分类的流量出口,默认为0,这样未分类的流量会使用硬件速度出队列,不会经过附加到 root qdisc 的所有类。 -
r2qDRR quantums are computed as rate in Bps/r2q {10} -
debugstring of 16 numbers each 0-3 {0} -
direct_qlenLimit of the direct queue {in packets}
添加类:
... class add ... htb rate R1 [burst B1] [mpu B] [overhead O]
[prio P] [slot S] [pslot PS]
[ceil R2] [cburst B2] [mtu MTU] [quantum Q]
rate最低期望速度,叶类的保证带宽(此叶类还能借)。ceil流量的最大速度,可以认为其等同于"突发的带宽",借用模型会详细说明。默认等于rate。burstrate的桶大小,HTB在等待更多令牌前可以加入队列burst字节的数据,即最大突发流量。cburstceil 的桶大小。HTB在等待更多ctokens前可以加入队列cburst字节的数据。quantum用于控制借用的关键参数。通常HTB会用r2q计算一个 ,用户无需指定。修改该值会对竞争下的借用和整流造成巨大的影响(因为它会在流量超过rate(且低于ceil)的子类间对流量进行分割,并传输这些子类的报文)。prio叶子的优先级,越小优先级越高。默认为0。mpuminimum packet size used in rate computationsoverheadper-packet size overhead used in rate computationslinklayadapting to a linklayer e.g. atmmtumax packet size we create rate map for {1600}
举例
HTB是典型的qdisc - class - filter树形结构来实现对流量的分层控制。以 eth0 网口为例,首先在根队列要建一个htb qdisc:
tc qdisc add dev eth0 root handle 1: htb
然后才能在之下建立子分类,这里为方便后续讲解手动设置quantum:
tc class add dev eth0 parent 1: classid 1:1 htb rate 100mibps
tc class add dev eth0 parent 1:1 classid 1:10 htb rate 30mibps ceil 80mibps prio 0 burst 10kbit cburst 20kbit quantum 30000
tc class add dev eth0 parent 1:1 classid 1:20 htb rate 20mibps ceil 50mibps prio 1 burst 10kbit cburst 20kbit quantum 20000
tc class add dev eth0 parent 1:10 classid 1:101 htb rate 10mibps ceil 80mibps prio 1 burst 10kbit cburst 20kbit quantum 10000
tc class add dev eth0 parent 1:10 classid 1:102 htb rate 5mibps ceil 40mibps prio 0 burst 10kbit cburst 20kbit quantum 5000
这些类的关系如下。随后可以使用filter和 u32 分类器把来自不同源 IP 的数据包送到不同的类。
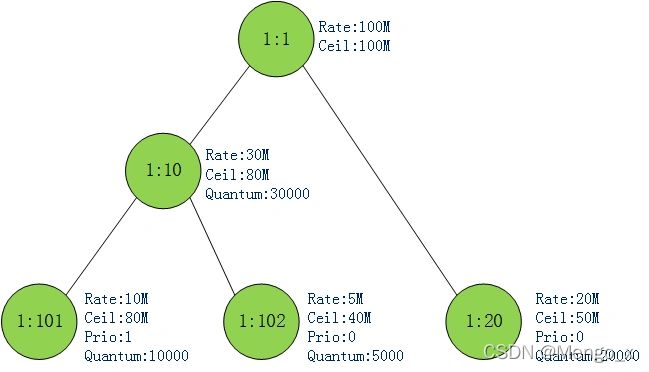
所有数据包最后只能从叶子类(leaf class)排队,其他内部类(inner class)起到和子类共享带宽的作用。
当网卡比较空闲时,leaf class可以以高于rate的速率出包,但不能高于ceil。带宽闲时共享,忙时按照比例分配(这个比例由rate、quantum共同决定)。prio优先级越高的类可以优先出流量。
原理
某个时刻每个类可以处于三种状态中的一种:
- CAN_SEND(令牌充足,发送的网络包小于
rate,例图中用绿色表示)) - MAY_BORROW(没有令牌,但可向父类借用。发送速率大于
rate小于ceil,例图中用黄色表示) - CANT_SEND(没有令牌且不可借用,发送速率大于
ceil,例图中用红色表示)
htb是如何决策哪个类出包的?
- htb算法从类树的底部开始往上找CAN_SEND状态的class。如果找到某一层有CAN_SEND状态的类则停止.
- 如果该层中有多个class处于CAN_SEND状态则选取优先级最高(prio最小)的class。如果最高优先级还是有多个class,那就在这些类中轮询处理。每个类每发送自己的quantum个字节后,轮到下一个类发送. 。
- 只有leaf class才可以发包,上述步骤若最终选到了inner class,就顺着树往下找处于MAY_BORROW状态的leaf class。将自己富余的令牌借给该leaf class让其出包。同样,多个子孙leaf class处于MAY_BORROW状态时和步骤2一样。
多个子类共享父类带宽也就体现在这里了。假设父类富余了10MB,子类1的quantum为30000,子类2的quantum为20000。那么父类帮子类1发送30000byte,再帮子类2发送20000byte。依次循环,最终效果就是子类1借到了6MB,子类2借到了4MB。因此上文说,当子类之间共享带宽时,rate/quantum共同决定它们分得的带宽。rate决定处于CAN_SEND状态时能发送多少字节,quantum决定处于MAY_BORROW状态时可借用令牌发送多少字节。
实例
这里直接看这篇文章吧
参考
Traffic Control HOWTO
Random Early Detection (RED)
Linux TC(Traffic Control)框架原理解析
Linux流量控制TC中的HTB队列创建与过滤
linux网络流控-htb算法简析
RED队列tc设置
流量控制
[1]郑辉. 基于 Linux 下的简单网络行为管理–Tc流量控制[J]. 软件:教育现代化(电子版), 2013(5):2.
[2]倪飞. 流量控制工具TC原理及应用[J]. 计算机科学, 2006, 33(B12):3.