浅谈GFS之---读写文件流程
文章目录
-
-
-
- Master 主要的两个表单
- 读 文 件 流 程
- 写文件流程
-
- primary chunk 不存在
- 脑裂 split-brain
-
-
Master 主要的两个表单
客户端要从chunkserver 上读写文件首先要发请求给Master获取文件相关的数据。将数据缓存到客户端本地(后面将介绍为什么要这么做)。根据相关数据与chunkserver 进行交互,实现文件的读写。每个chunk 的大小为64MB。Master主要有两个表单来存储相关的元数据(注意有的元数据需要持久化到硬盘,有的只存放在内存,后面将介绍为什么这样做)。
两个表单如下:
- 文件名到chunk ID 或者 chunk Handle 数组(文件较大会对应多个chunk ID,多个chunkID 组成chunk Handle 数组)的对应。
- chunkID 到 chunk 数据的对应关系(如下)。
2.1 每个chunk (论文中说,一个chunkID 一般有三个副本及三个chunk )存储在哪个服务器上。(list of chunkserver) (不持久化到master 磁盘)
2.2 每个chunk 当前版本(version)。设置版本主是为了检测过期失效的副本。版本号只会在master指定一个新的Primary才会改变(持久化到master磁盘)
2.3 哪个chunk 服务器有主chunk(primary). gfs引入了租约来最小化master 节点的管理负担。(持久化到master 磁盘)
2.4 租约的过期时间(lease expiration). gfs 默认过期时间是60s(可以修改)
租约(lease)介绍:lease 是数据库中的一个术语。Master 节点为chunk的一个副本建立一个租约,这个副本就做主chunk(primary),主chunk对chunk的 所有更改操作进行序列化,所有副本都遵循这个序列进行修改操作。
读 文 件 流 程
client 将文件名,及从文件哪个位置读取的偏移量(offset)发送给master,master主要做下面三个操作。
1. 从file 表单中查文件名
2. 文件偏移量/64MB=chunk ID (多个组成chunk Handle)
3. 从表单中将chunk Handle 和对应chunk服务器列表发送给客户端。
客户端可以从这些Chunk服务器中挑选一个来读取数据。GFS论文说,客户端会选择一个网络上最近的服务器(Google的数据中心中,IP地址是连续的,所以可以从IP地址的差异判断网络位置的远近),并将读请求发送到那个服务器。因为客户端每次可能只读取1MB或者64KB数据,所以,客户端可能会连续多次读取同一个Chunk的不同位置。所以,客户端会缓存Chunk和服务器的对应关系,这样,当再次读取相同Chunk数据时,就不用一次次的去向Master请求相同的信息。
接下来,客户端会与选出的Chunk服务器通信,将Chunk Handle和偏移量发送给那个Chunk服务器。Chunk服务器会在本地的硬盘上,将每个Chunk存储成独立的Linux文件,并通过普通的Linux文件系统管理。并且可以推测,Chunk文件会按照Handle(也就是ID)命名。所以,Chunk服务器需要做的就是根据文件名找到对应的Chunk文件,之后从文件中读取对应的数据段,并将数据返回给客户端。
读数据跨chunk的边界:
客户端本身依赖了一个GFS的库,这个库会注意到读请求跨越了Chunk的边界 ,并会将读请求拆分,之后再将它们合并起来。所以这个库会与Master节点交互,Master节点会告诉这个库说Chunk7在这个服务器,Chunk8在那个服务器。之后这个库会说,我需要Chunk7的最后两个字节,Chunk8的头两个字节。GFS库获取到这些数据之后,会将它们放在一个buffer中,再返回给调用库的应用程序。Master节点会告诉库有关Chunk的信息,而GFS库可以根据这个信息找到应用程序想要的数据。应用程序只需要确定文件名和数据在整个文件中的偏移量,GFS库和Master节点共同协商将这些信息转换成Chunk。
写文件流程
client-------->Master 发送请求,表示想要向这个文件名对应的文件追加数据,告诉我最后一个chunk 的位置。写文件通过chunk的的主副本(primary chunk)写入。
流程如下
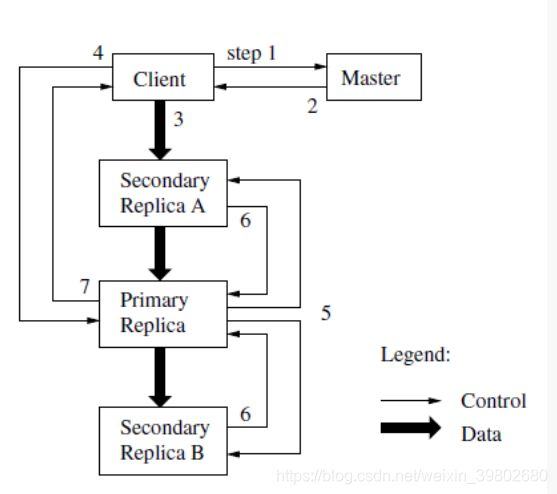
◆客户机向Master节点询问哪一个Chunk服务器持有当前的租约,以及其它副本的位置。如果没有一个Chunk持有租约,Master节点就选择其中一个副本建立一个租约(这个步骤在图上没有显示)。
◆ Master节点将主Chunk的标识符以及其它副本(又称为secondary副本、二级副本)的位置返回给客户机。客户机缓存这些数据以便后续的操作。只有在主Chunk不可用,或者主Chunk回复信息表明它已不再持有租约的时候,客户机才需要重新跟Master节点联系。
◆ 客户机把数据推送到所有的副本上。客户机可以以任意的顺序推送数据。Chunk服务器接收到数据并保存在它的内部LRU缓存中,一直到数据被使用或者过期交换出去。由于数据流的网络传输负载非常高,通过分离数据流和控制流,我们可以基于网络拓扑情况对数据流进行规划,提高系统性能,而不用去理会哪个Chunk服务器保存了主Chunk。
◆当所有的副本都确认接收到了数据,客户机发送写请求到主Chunk服务器。这个请求标识了早前推送到所有副本的数据。主Chunk为接收到的所有操作分配连续的序列号,这些操作可能来自不同的客户机,序列号保证了操作顺序执行。它以序列号的顺序把操作应用到它自己的本地状态中(alex注:也就是在本地执行这些操作,这句话按字面翻译有点费解,也许应该翻译为“它顺序执行这些操作,并更新自己的状态”)。
◆主Chunk把写请求传递到所有的二级副本。每个二级副本依照主Chunk分配的序列号以相同的顺序执行这些操作。
◆所有的二级副本回复主Chunk,它们已经完成了操作。
◆主Chunk服务器(主Chunk所在的Chunk服务器)回复客户机。任何副本产生的任何错误都会返回给客户机。在出现错误的情况下,写入操作可能在主Chunk和一些二级副本执行成功。(如果操作在主Chunk上失败了,操作就不会被分配序列号,也不会被传递。)客户端的请求被确认为失败,被修改的region处于不一致的状态。我们的客户机代码通过重复执行失败的操作来处理这样的错误。在从头开始重复执行之前,客户机会先从步骤(3)到步骤(7)做几次尝试。
如果应用程序一次写入的数据量很大,或者数据跨越了多个Chunk,GFS客户机代码会把它们分成多个写操作。这些操作都遵循前面描述的控制流程,但是可能会被其它客户机上同时进行的操作打断或者覆盖。因此,共享的文件region的尾部可能包含来自不同客户机的数据片段,尽管如此,由于这些分解后的写入操作在所有的副本上都以相同的顺序执行完成,Chunk的所有副本都是一致的。这使文件region处于2.7节描述的一致的、但是未定义的状态。
primary chunk 不存在
当Chunk服务器失效时,Chunk的副本有可能因错失了一些修改操作而过期失效。Master节点保存了每个Chunk的版本号,用来区分当前的副本和过期副本。
无论何时,只要Master节点和Chunk签订一个新的租约,它就增加Chunk的版本号,然后通知最新的副本。Master节点和这些副本都把新的版本号记录在它们持久化存储的状态信息中。这个动作发生在任何客户机得到通知以前,因此也是对这个Chunk开始写之前。如果某个副本所在的Chunk服务器正好处于失效状态,那么副本的版本号就不会被增加。Master节点让这个Chunk服务器重新启动,并且向Master节点报告它拥有的Chunk的集合以及相应的版本号的时候,就会检测出它包含过期的Chunk。如果Master节点看到一个比它记录的版本号更高的版本号,Master节点会认为它和Chunk服务器签订租约的操作失败了,因此会选择更高的版本号作为当前的版本号。
Master节点在例行的垃圾回收过程中移除所有的过期失效副本。在此之前,Master节点在回复客户机的Chunk信息请求的时候,简单的认为那些过期的块根本就不存在。另外一重保障措施是,Master节点在通知客户机哪个Chunk服务器持有租约、或者指示Chunk服务器从哪个Chunk服务器进行克隆时,消息中都附带了Chunk的版本号。客户机或者Chunk服务器在执行操作时都会验证版本号以确保总是访问当前版本的数据。
脑裂 split-brain
脑裂,它通常是由网络分区引起的。比如说,Master无法与Primary通信,但是Primary又可以与客户端通信,这就是一种网络分区问题。网络故障是这类分布式存储系统中最难处理的问题之一。
在某个时间点,Master指定了一个Primary,之后Master会一直通过定期的ping来检查它是否还存活。因为如果它挂了,Master需要选择一个新的Primary。Master发送了一些ping给Primary,并且Primary没有回应,你可能会认为Master会在那个时间立刻指定一个新的Primary。但事实是,这是一个错误的想法。为什么是一个错误的想法呢?因为可能是网络的原因导致ping没有成功,所以有可能Primary还活着,但是网络的原因导致ping失败了。但同时,Primary还可以与客户端交互,如果Master为Chunk指定了一个新的Primary,那么就会同时有两个Primary处理写请求,这两个Primary不知道彼此的存在,会分别处理不同的写请求,最终会导致有两个不同的数据拷贝。这被称为脑裂(split-brain)。
所以在master ping不通primary 时需要等lease 过期后才能分配新的primary。