分布式TDSQL的实践
分布式TDSQL跟单节点的TDSQL有什么不同,这种分布式架构下又是如何实现一系列的保障,如何做到对业务透明、对业务无感知。
1.分表

分表,当在单机模式下,用户看到的一张逻辑表,其实也是一张物理表,存储在一个物理节点(物理机)上。在分布式形态下,用户看到的逻辑表的实际物理存储可能是被打散分布到不同的物理节点上。所以TDSQL分表的目标,希望做到对业务完全透明,比如业务只看到一个完整的逻辑表,他并不知道这些表其实已经被TDSQL均匀拆分到各个物理节点上。比如:之前可能数据都在一台机器上,现在这些数据平均分布在了5台机器上,但用户却丝毫没有觉察,这是TDSQL要实现的一个目标——在用户看来是完全的一张逻辑表,实际上它是在后台打散了的。
这个表在后台如何去打散,如何去分布呢?我们希望对用户做到透明,做到屏蔽,让他不关心数据分布的细节。怎么将这个数据分布和打散呢?这就引出了一个概念:shardkey——是TDSQL的分片关键字,也就是说TDSQL会根据shardkey字段将这个数据去分散。

我们认为,shardkey是一个很自然的字段,自然地通过一个字段去将数据打散。举个例子,腾讯内部我们喜欢用QQ号作为一个shardkey,通过QQ号自动把数据打散,或者微信号;而一些银行类的客户,更喜欢用一些客户号、身份证号以及银行卡号,作为shardkey。也就是说通过一个字段自然而然把这个数据分散开来。我们认为引入shardkey后并不会增加额外的工作,因为首先用户是最了解自己得数据的,知道自己的数据按照什么字段均匀分布最佳,同时给用户自主选择分片关键字的权利,有助于从全局角度实现分布式数据库的全局性能最佳。
所以这里可能有些人会想,是不是主键是最好的或者尽可能地分散?没错,确实是这样的,作为TDSQL的分片关键字越分散越好,要求是主键或者是唯一索引的一部分。确定了这个分片关键字后,TDSQL就可以根据这个分片关键字将数据均匀分散开来。比如这张图,我们按照一个字段做了分片之后,将1万条数据均匀分布在了四个节点上。
既然我们了解了shardkey是一个分片关键字,那怎么去使用呢?这里我们就聊聊如何去使用。

举个例子,我们创建了TB1这个表,这里有若干个字段,比如说ID,从这个名字上来看就应该知道它是一个不唯一的,或者可以说是一个比较分散的值。我们看到这里,以“ID”作为分配关键字,这样六条数据就均匀分散到了两个分片上。当然,数据均匀分散之后,我们要求SQL在发往这边的都需要带上shardkey,也就是说发到这里之后可以根据对应的shardkey发往对应的分片。如果不带这个shardkey的话,它不知道发给哪个分片,就发给了所有分片。所以强调通过这样的改善,我们要求尽可能SQL要带上shardkey。带上shardkey的话,就实现了SQL的路由分发到对应的分片。
讲完数据分片,我们再看一下数据的拆分。
2.水平拆分
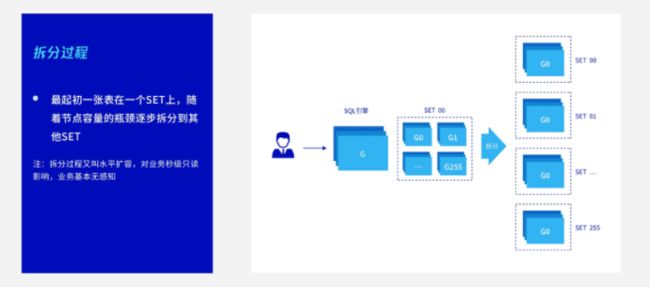
对于分布式来说,可能最初我们所有的数据都在一个节点上。当一个节点出现了性能瓶颈,需要将数据拆分,这时对我们TDSQL来说非常简单,在界面上的一个按纽:即一键扩容,它就可以将这个数据自动拆分。拆分的过程也比较容易理解,其实就是一个数据的拷贝和搬迁过程,因为数据本身是可以按照一半一半这样的划分的。比如最先是这么一份数据,我们需要拆成两份,需要把它的下半部分数据拷到另外一个节点上。这个原理也比较简单,就是一个数据的拷贝,这里强调的是在拷贝的过程中,其实业务是不受任何影响的。最终业务只会最终有一个秒级冻结。
为什么叫秒级冻结?因为,最后一步,数据分布到两个节点上涉及到一个路由信息变更,比如原来的路由信息要发到这个分片,现在改了之后需要按照划分,上半部分要发给一个分片,下半部分发给另一个分片。我们在改路由的这个过程中,希望这个数据是没有写入相对静止的。
当然改路由也是毫秒级别完成,所以数据拆分时,真正最后对业务的影响只有不到1s,并且只有在最后改路由的冻结阶段才会触发。
讲完数据拆分,我们开始切入分布式里面最难解决的这个问题,分布式事务。
3.健壮、可靠的分布式事务
单节点的事务是很好解决的,但是在分布式场景下想解决分布式事务还是存在一定的困难性,它需要考虑各种各样复杂的场景。
其实分布式事务实现不难,但首要是保证它的健壮性和可靠性,能应对各种各样的复杂场景。比如说涉及到分布式事务的时候,有主备切换、节点宕机……在各种容灾的测试环境下,如何保证数据总帐是平的,不会多一分钱也不会少一分钱,这是分布式事务需要考虑的。
TDSQL分布式事务基于拆的标准两阶段提交实现,这也是业内比较通用的方法。我们看到SQL 引擎作为分布式事务的发起者,联合各个资源节点共同完成分布式事务的处理。
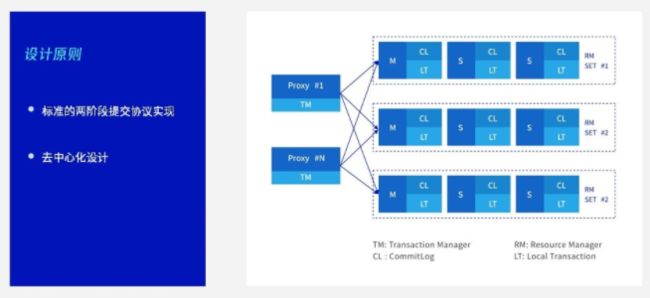
分布式事务也是根据shardkey来判断,具体来说,对于SQL引擎读发起一个事务,比如第一条SQL是改用户ID为A的用户信息表。第二条SQL是插入一个用户ID为A的流水表,这两张表都以用户ID作为shardkey。我们发现这两条SQL都是发往一个分片,虽然是一个开启的事务,但是发现它并没有走分布式事务,它实际还是限制在单个分片里面走了一个单节点的事务。当然如果涉及到转帐:比如从A帐户转到B帐户,正好A帐户在第一个分片,B帐户是第二个分片,这样就涉及到一个分布式事务,需要SQL引擎完成整个分布式事务处理。
分布式事务是一个去中心化的设计,无论是SQL引擎还是后端的数据节点,其实都是具备高可用的同时支持线性扩展的设计。分布式事务比较复杂,单独讲的话可能能讲一门课,这里面涉及的内容非常多,比如两级段提交过程中有哪些异常场景,失败怎么处理,超时怎么处理,怎么样保证事务最终的一致性等等。这里不再深入,希望有机会能单独给大家分享这块内容。
所以,这里只对分布式事务做一个总结,我们不再去探讨它的细节:
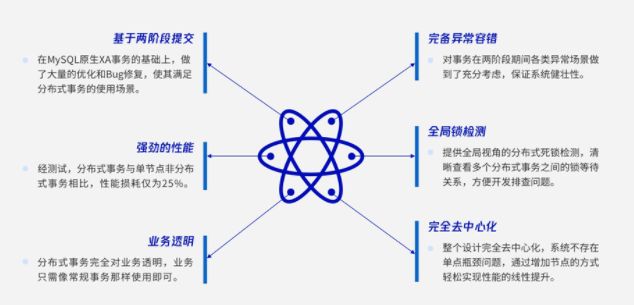
首先是基于两阶段提交,我们在MySQL原生XA事务的基础上做了大量的优化和BUG修复。比如说原生的XA在主备切换时会发生数据不一致和丢失,TDSQL在这个基础上做了大量的修复,让XA事务能够保证数据一致性。
第二个是强劲的性能。起初我们引进原生分布式事务的时候,分布式事务的性能还达不到单节点的一半。当然经过一系列的优化调优,最后我们的性能损耗是25%,也就是说它能达到单节点75%的性能。
第三个是对业务透明,因为对业务来说其实根本无需关心到底是分布式还是非分布式,仅需要按照正常业务开启一个事务使用即可。
第四个是完备的异常容错。分布式事务是否健壮也需要考虑容错性的能力。
第五个是全局的锁检测。对于分布式环境下锁检测也是不可或缺的。TDSQL提供全局视角的分布式死锁检测,可清晰查看多个分布式事务之间的锁等待关系。
第六点是完全去中心化。无论是SQL引擎还是数据节点,都是支持高可用并且能够线性扩展。
以上是TDSQL分布式事务的总结。如果说用户要求保持跟MySQL的高度兼容性,那可能Noshard版TDSQL更适合。但是如果对于用户来说,单节点已经达到资源的瓶颈,没有办法在单节点下做数据重分布或者扩容,那必须选择Shard模式。但是在Shard模式下,我们对SQL有一定的约束和限制,后面会有专门的一门课去讲分布式TDSQL对SQL是如何约束的。
我们看到无论是Noshard还是Shard,都具备高可用、数据强一致、自动容灾的能力。

同时TDSQL也支持Noshard到Shard的迁移,可能早期我们规划的Noshard还可以承载业务压力,但是随着业务的突增已经撑不住了,这个时候需要全部迁到Shard,那么TDSQL也有完善的工具帮助用户快速进行数据迁移。
本文由博客一文多发平台 OpenWrite 发布!