对比学习(Contrastive Learning)相关进展梳理
最近深度学习两巨头 Bengio 和 LeCun 在 ICLR 2020 上点名 Self-Supervised Learning(SSL,自监督学习) 是 AI 的未来,而其的代表的 Framework 便是 Contrastive Learning(CL,对比学习)。 另一巨头 Hinton 和 Kaiming 两尊大神也在这问题上隔空过招,MoCo、SimCLR、MoCo V2 打得火热,这和 BERT 之后,各大公司出 XL-Net、RoBerta 刷榜的场景何其相似。本篇文章,将会从对比学习的背后的直觉原理出发,介绍其框架,并且对目前的一些相关的工作进行简要介绍,希望能够为感兴趣的同学提供一些帮助。
Motivation & Framework
很多研究者认为,深度学习的本质就是做两件事情:Representation Learning(表示学习)和 Inductive Bias Learning(归纳偏好学习)。目前的一个趋势就是,学好了样本的表示,在一些不涉及逻辑、推理等的问题上,例如判断句子的情感极性、识别图像中有哪些东西,AI 系统都可以完成非常不错;而涉及到更高层的语义、组合逻辑,则需要设计一些过程来辅助 AI 系统去分解复杂的任务,ICLR 19 的一篇 oral 就是做的类似的事情。因为归纳偏好的设计更多的是 任务相关的,复杂的过程需要非常精心的设计,所以很多工作都开始关注到表示学习上,NLP 最近大火的预训练模型,例如 BERT,就是利用大规模的语料预训练得到文本的好的表示。那么,CV 领域的 BERT 是什么呢?答案已经呼之欲出,就是对比学习。
Illustrative Example
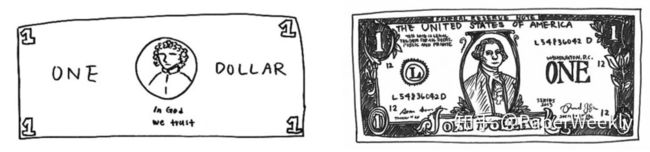
当你被要求画一张美元,左边是没有钞票在你面前,右边是面前摆着一张钞票画出来的结果,上面这个例子来自于 Contrastive Self-supervised Learning 这篇 Blog,表达的一个核心思想就是:尽管我们已经见过很多次钞票长什么样子,但我们很少能一模一样的画出钞票;虽然我们画不出栩栩如生的钞票,但我们依旧可以轻易地辨别出钞票。基于此,也就意味着表示学习算法并不一定要关注到样本的每一个细节,只要学到的特征能够使其和其他样本区别开来就行,这就是对比学习和对抗生成网络(GAN)的一个主要不同所在。
Contrastive Learning Framework
既然是表示学习,那么我们的核心就是要学习一个映射函数 ![]() ,把样本 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消 编码成其表示 ,对比学习的核心就是使得这个 满足下面这个式子:
,把样本 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消 编码成其表示 ,对比学习的核心就是使得这个 满足下面这个式子:
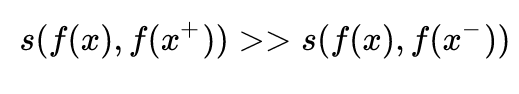
这里的![]() 就是和 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消 类似的样本, 就是和 不相似的样本, 这是一个度量样本之间相似程度的函数,一个比较典型的 score 函数就是就是向量内积,即优化下面这一期望:
就是和 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消 类似的样本, 就是和 不相似的样本, 这是一个度量样本之间相似程度的函数,一个比较典型的 score 函数就是就是向量内积,即优化下面这一期望:

如果对于一个![]() ,我们有 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消 个正例和 个负例,那么这个 loss 就可以看做是一个 N 分类问题,实际上就是一个交叉熵,而这个函数在对比学习的文章中被称之为 InfoNCE。事实上,最小化这一 loss 能够最大化 和 互信息的下界,让二者的表示更为接近。理解了这个式子其实就理解了整个对比学习的框架,后续研究的核心往往就聚焦于这个式子的两个方面:
,我们有 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消 个正例和 个负例,那么这个 loss 就可以看做是一个 N 分类问题,实际上就是一个交叉熵,而这个函数在对比学习的文章中被称之为 InfoNCE。事实上,最小化这一 loss 能够最大化 和 互信息的下界,让二者的表示更为接近。理解了这个式子其实就理解了整个对比学习的框架,后续研究的核心往往就聚焦于这个式子的两个方面:
- 如何定义目标函数?最简单的一种就是上面提到的内积函数,另外一中 triplet 的形式就是
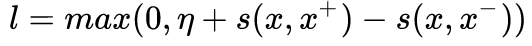 ,直观上理解,就是希望正例 pair 和负例 pair 隔开至少 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消 的距离,这一函数同样可以写成另外一种形式,让正例 pair 和负例 pair 采用不同的 函数,例如, ,。
,直观上理解,就是希望正例 pair 和负例 pair 隔开至少 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消 的距离,这一函数同样可以写成另外一种形式,让正例 pair 和负例 pair 采用不同的 函数,例如, ,。 - 如何构建正例和负例?针对不同类型数据,例如图像、文本和音频,如何合理的定义哪些样本应该被视作是
 ,哪些该被视作是 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消,;如何增加负例样本的数量,也就是上面式子里的 ?这个问题是目前很多 paper 关注的一个方向,因为虽然自监督的数据有很多,但是设计出合理的正例和负例 pair,并且尽可能提升 pair 能够 cover 的 semantic relation,才能让得到的表示在 downstream task 表现的更好。
,哪些该被视作是 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消,;如何增加负例样本的数量,也就是上面式子里的 ?这个问题是目前很多 paper 关注的一个方向,因为虽然自监督的数据有很多,但是设计出合理的正例和负例 pair,并且尽可能提升 pair 能够 cover 的 semantic relation,才能让得到的表示在 downstream task 表现的更好。
接下来,就会介绍一下 MoCo、SimCLR 以及 Contrasitve Predictive Coding(CPC) 这三篇文章,在构建对比样例中的一些核心观点。
Contrastive Pair
MoCo

论文标题:Momentum Contrast for Unsupervised Visual Representation Learning
论文来源:CVPR 2020
论文链接:https://arxiv.org/abs/1911.05722
代码链接:https://github.com/facebookresearch/moco
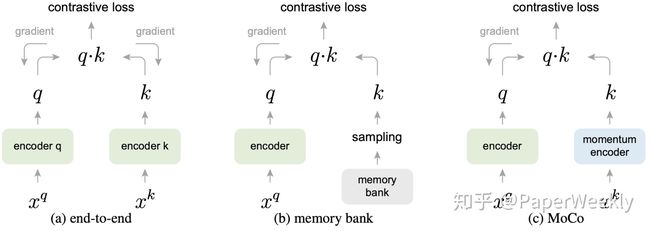
前面提到了,样本数量对于学习到的样本质量有很大的影响。MoCo 做的事情很简单,就是把负例样本的 encoder 和 mini-batch 大小解耦。也就是说,原先在算目标函数的时候,负例样本对也会为 loss 产生贡献,因为也就会有梯度回传给对应的 encoder,那么这样在实现的时候,样本数量必然会受到 batch size 的限制,从而影响学习到表示的质量。
为此,Memory Bank 提出我把所有样本的表示都存起来,然后每次随机采样,这样就可以认为我的负例样本理论上可以达到所有样本的数量,具体的做法就是每一轮来 encode 一次所有的变量,显然,这样很吃内存,并且得到的表示也和参数更新存在一定的滞后。
MoCo 则改善了上述的两个缺点,一方面,用一个 queue 来维护当前的 negative candidates pool,queue 有着进出的动态更新机制,一方面能够和 Mini-batch 解耦,queue size 可以设置的比较大,另外一方面也就不用对所有样本做类似预处理的进行编码;对于负例样本的参数,采用 Momentum update 的方式,来把正例 encoder 的参数![]() copy 给负例 encoder 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消:
copy 给负例 encoder 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消:

三种方式的示意图也在这一小节的开头给出了,可以清楚的看到三种方式的区别。这种对比画图的方式对于说明问题很有帮助,可以在论文中进行尝试。
SimCLR

论文标题:A Simple Framework for Contrastive Learning of Visual Representations
论文链接:https://arxiv.org/abs/2002.05709
代码链接:https://github.com/google-research/simclr
MoCo 刚说完样本数量对于对比学习很重要,这边 SimCLR 就从另外一个角度,说构建负例的方式(图像上,就是对于图像的 transformation)也很重要,探究了 transformation 、batch-size 大小等对于学习到的表示的影响,并且把这个框架用下面这张图来说明:
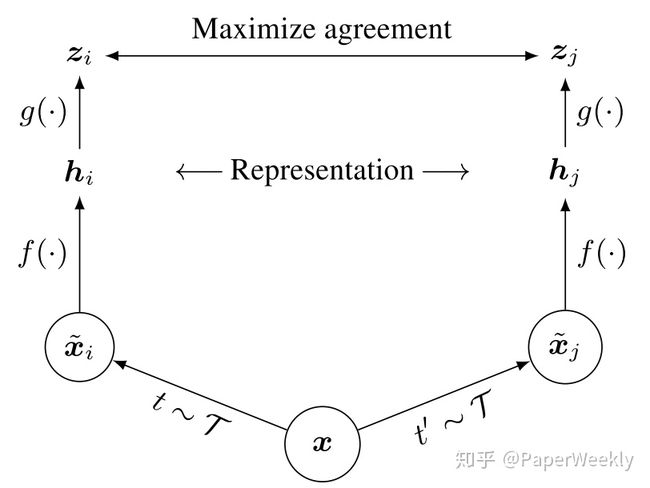
文章主要得出了下面几个结论:
- 对于样本进行变化,即构建正例和负例的 transformation 对于结果至关重要;
- 用 entropy loss 的 Contrastive Learning,可以通过 normalize representation embedding 以及 temperature adjustment 提点;
- 在计算 loss 之前,让表示再过一个 non-linear hard 能大幅提升效果,即上面框架图中的 ;
- 大 batch-size 对于 CL 的增益比 Supervised Learning 更大。
其中最后一个结论,和 MoCo 的初衷是符合的,并且作者虽说不用 Memory-bank,但是 SimCLR 尝试的 bsz 也达到了令人发指的 8192,用了 128 块 TPU,又是算力党的一大胜利。MoCo v2 也是利用了上面的第一点和第三点,在 MoCo 基础上得到了进一步的提升,然后作者还也明确的点名了 SimCLR,称不需要使用那么大的 batch size 也能超过它,可能这就是神仙打架吧。
CPC

论文标题:Representation Learning with Contrastive Predictive Coding
论文链接:https://arxiv.org/abs/1807.03748
代码链接:https://github.com/davidtellez/contrastive-predictive-coding
前面讨论的两篇文章主要集中在图像数据上,那么对于文本、音频这样的数据,常见的裁剪、旋转等变换操作就无法适用了,并且,因为其数据本身的时序性,设计合理的方法来把这一点考虑进去是至关重要的。Contrastive Predictive Coding(CPC) 这篇文章就提出,可以利用一定窗口内的 ![]() 和 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消 作为 Positive pair,并从输入序列之中随机采样一个输入 作为负例,下图说明了 CPC 的工作过程:
和 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消 作为 Positive pair,并从输入序列之中随机采样一个输入 作为负例,下图说明了 CPC 的工作过程:
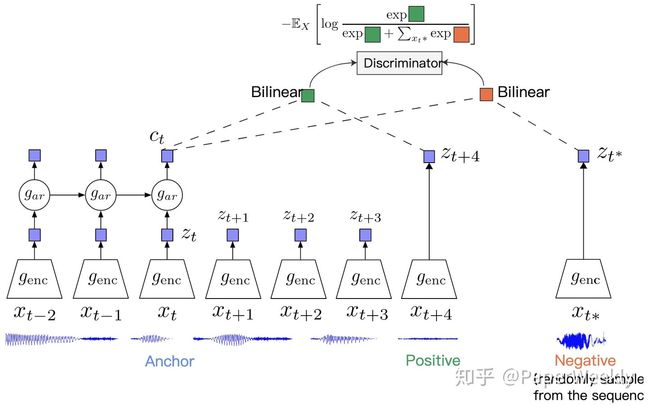
为了把历史的信息也加入进去,作者提出可以在 上额外增加一个自递归模型,例如 GRU,来在表示之中融入时序关系,得到相应的 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消 来进行对比学习。在下游任务中,既可以使用 也可以使用 ,又或者是二者的融合,可以根据任务需要来进行灵活的选择。
Theory & Application
接下来,会简要的讨论几篇关于对比学习的理论和应用类的文章:
ICML 2019

论文标题:A Theoretical Analysis of Contrastive Unsupervised Representation Learning
论文来源:ICML 2019
论文链接:https://arxiv.org/abs/1902.09229
这篇文章发表在 ICML 2019 上,对比学习这一框架虽然在直觉上非常 make sense,但是理论上为什么得到的表示就能够在 downstream 例如 classification 上表现良好?
这篇文章通过定义 latent class 以及样本和 latent class 的距离入手,推导出了二分类情况下的 loss bound,保证了其的泛化性能。文章提出了一个改进算法就是进行 block 处理,不再直接优化各个 pair 的 inner product,而是转而优化 positive block以及 negative block 的内积:

文章在后续的实验上也验证了这一方法会优于内积方法。
NIPS 2017

论文标题:Contrastive Learning for Image Captioning
论文来源:NIPS 2017
论文链接:https://arxiv.org/abs/1710.02534
代码链接:https://github.com/doubledaibo/clcaption_nips2017
这篇文章希望通过使用对比学习来解决 image captioning 中标题文本可区别性的问题,即尽可能让标题描述和唯一的一张图片对应,而不是笼统而又模糊的可能和多张图片对应。作者引入对比学习,把对应的图像和标题作为正例 pair ,并把其中的图像随机采样得到负例 pair 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消,并且在已有的 sota 模型上优化 ,提升生成的 caption 的效果。
ICLR 2020

论文标题:Contrastive Learning of Structured World Models
论文来源:ICLR 2020
论文链接:https://arxiv.org/abs/1911.12247
代码链接:https://github.com/tkipf/c-swm
前面提到,表示学习能够较好的解决一些简单的任务,但是理解物体之间的关系以及建模其间的交互关系不单单需要好的表示,同样需要一个好的归纳偏好。这篇文章就是通过利用 state set 来表示世界中各个物体的状态,并且利用图神经网络来建模其之间的交互,再进一步地利用对比学习来提升性能,下图给出了模型的示意图:
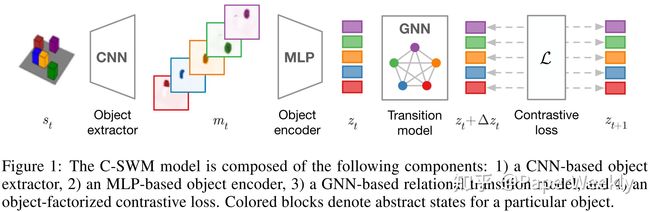
这里的对比学习是从 TransE 架构迁移而来,具体地,在 TransE 中,我们会希望一个三元组![]() 的能够让 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消 尽可能的小,即 的表示加上 relation 的表示和 的表示尽可能地接近,而迁移到世界模型中,就是要将 entity 换成物体的 state,relation 换成 action,即经过图卷积后的得到的新的表示,通过下面的式子进行优化:
的能够让 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消转存失败重新上传取消 尽可能的小,即 的表示加上 relation 的表示和 的表示尽可能地接近,而迁移到世界模型中,就是要将 entity 换成物体的 state,relation 换成 action,即经过图卷积后的得到的新的表示,通过下面的式子进行优化:

这里的 是从 experience buffer 中采样得到的负例样本,文章在后续多物体交互环境的模拟实验中验证了其方法的优越性。
Summary
本文介绍了关于对比学习背后的动机,以及一系列在图像、文本上的一些工作,在计算机视觉领域,其习得的表示能够很好地在下游任务泛化,甚至能够超过监督学习的方法。
回过头来看,预训练模型从 ImageNet 开始,后来这一思想迁移到 NLP,有了 BERT 等一系列通过自监督的预训练方法来学习表示,后来这一想法又反哺了计算机视觉领域,引出了诸如 MoCo、SimCLR 等工作,在一系列分割、分类任务上都取得了惊人的表现。那么,这一思想会不会又再次和 NLP 结合,碰撞出新的火花呢,让我们拭目以待。