解读 JVM 类加载器-一篇文章简单易懂
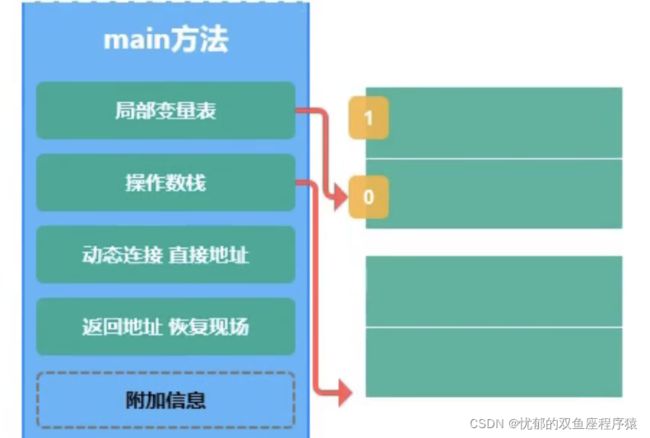
首先来看一张图
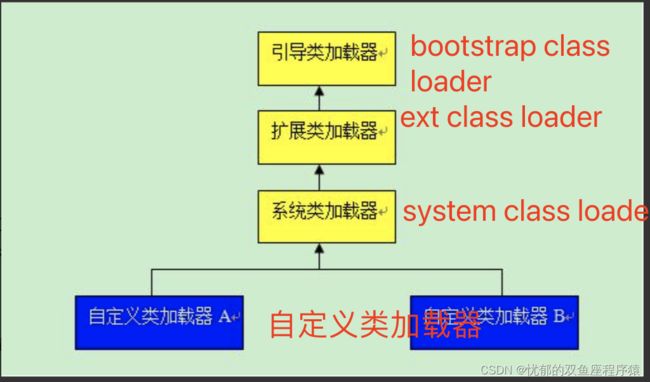
一、类加载器的简单认知和工作范畴
1.引导类加载器(bootstrap class loader):
它用来加载 Java 的核心库(jre/lib/rt.jar),是用原生C++代码来实现的,并不继承自java.lang.ClassLoader。加载扩展类和应用程序类加载器,并指定他们的父类加载器,在java中获取不到。
2.扩展类加载器(extensions class loader):
它用来加载 Java 的扩展库(jre/ext/*.jar)。Java 虚拟机的实现会提供一个扩展库目录。该类加载器在此目录里面查找并加载 Java 类。
3.系统类加载器(system class loader):
它根据 Java 应用的类路径(CLASSPATH)来加载 Java 类。一般来说,Java 应用的类都是由它来完成加载的。可以通过
ClassLoader.getSystemClassLoader()来获取它。
4.自定义类加载器(custom class loader):
除了系统提供的类加载器以外,开发人员可以通过继承 java.lang.ClassLoader类的方式实现自己的类加载器,满足特定开发需求
展示代码
/**
* @program:
* @description:
* @author: Mr.Wang
* @create: 2022-01-18 12:37
**/
public static void main(String[] args) {
System.out.println("我是自定义类加载器+"+myClassLoader.getSystemClassLoader());
System.out.println("我是类路径classpath加载器+"+myClassLoader.getSystemClassLoader().getParent());
System.out.println("我是jvm扩展的类加载器+"+myClassLoader.getSystemClassLoader().getParent().getParent());
System.out.println("我是bootstrap 基于C的类加载器+"+myClassLoader.getSystemClassLoader().getParent().getParent().getParent());
}

二 类加载器的工作机制

首先 先经历过 类编译器 后才会来到类加载器,类编译分为三种
1. 前端编译器:源代码到字节码(JAVAC)or(Eclipse JDT)
第一个阶段:词法、语法分析。在这个阶段,JVM 会对源代码的字符进行一次扫描,最终生成一个抽象的语法树。简单地说,在这个阶段 JVM 会搞懂我们的代码到底想要干嘛。就像我们分析一个句子一样,我们会对句子划分主谓宾,弄清楚这个句子要表达的意思一样。
第二个阶段:填充符号表。我们知道类之间是会互相引用的,但在编译阶段,我们无法确定其具体的地址,所以我们会使用一个符号来替代。在这个阶段做的就是类似的事情,即对抽象的类或接口进行符号填充。等到类加载阶段,JVM 会将符号替换成具体的内存地址。
第三个阶段:注解处理。我们知道 Java 是支持注解的,因此在这个阶段会对注解进行分析,根据注解的作用将其还原成具体的指令集。
第四个阶段:分析与字节码生成。到了这个阶段,JVM 便会根据上面几个阶段分析出来的结果,进行字节码的生成,最终输出为 class 文件。
2. JIT 编译器:从字节码到机器码
当源代码转化为字节码之后,其实要运行程序,有两种选择。一种是使用 Java 解释器解释执行字节码,另一种则是使用 JIT 编译器将字节码转化为本地机器代码。
这两种方式的区别在于,前者启动速度快但运行速度慢,而后者启动速度慢但运行速度快。至于为什么会这样,其原因很简单。因为解释器不需要像 JIT 编译器一样,将所有字节码都转化为机器码,自然就少去了优化的时间。而当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。所以在实际情况中,为了运行速度以及效率,我们通常采用两者相结合的方式进行 Java 代码的编译执行。
在 HotSpot 虚拟机内置了两个即时编译器,分别称为 Client Compiler 和Server Compiler。这两种不同的编译器衍生出两种不同的编译模式,我们分别称之为:C1 编译模式,C2 编译模式。
注意:现在许多人习惯上将 Client Compiler 称为 C1 编译器,将 Server Compiler 称为 C2 编译器,但在 Oracle 官方文档中将其描述为 compiler mode(编译模式)。所以说 C1 编译器、C2 编译器只是我们自己的习惯性称呼,并不是官方的说法。这点需要特别注意。
那么 C1 编译模式和 C2 编译模式有什么区别呢?
C1 编译模式会将字节码编译为本地代码,进行简单、可靠的优化,如有必要将加入性能监控的逻辑。而 C2 编译模式,也是将字节码编译为本地代码,但是会启用一些编译耗时较长的优化,甚至会根据性能监控信息进行一些不可靠的激进优化。
简单地说 C1 编译模式做的优化相对比较保守,其编译速度相比 C2 较快。而 C2 编译模式会做一些激进的优化,并且会根据性能监控做针对性优化,所以其编译质量相对较好,但是耗时更长。
如果你想单独使用 C1 模式或 C2 模式,使用 -client 或 -server 打开即可。
那么到底应该选择 C1 编译模式还是 C2 编译模式呢?
实际上对于 HotSpot 虚拟机来说,其一共有三种运行模式可选,分别是:
混合模式(Mixed Mode) 即 解释模式+编译模式
解释模式(Interpreted Mode)。即所有代码都解释执行,使用 -Xint 参数可以打开这个模式。
编译模式(Compiled Mode)。 此模式优先采用编译,但是无法编译时也会解释执行,使用 -Xcomp 打开这种模式。
3. AOT 编译器:源代码到机器码
好了 编译阶段我们先讲这么多
※接下来 继续是 我们的 类加载器 的 加载阶段
类加载器的工作机制
虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这就是虚拟机的类加载机制。
类加载器就是寻找类的字节码文件并构造出类在JVM内部表示的对象组件。在java中,类加载器把一个类装入JVM中,要经过以下步骤:
1.装载:查找和导入Class文件;
2.链接:执行校验、准备和解析步骤,其中解析步骤是可以选择的;
(1)校验:检查载入Class文件数据的正确性;
(2)准备:给累的静态变量分配存储空间;
(3)解析:将符号引用转成直接引用;
3.初始化:对类的静态变量、静态代码块执行初始化工作。
类加载工作由ClassLoader及其子类负责,ClassLoader是一个重要的java运行时系统组件,他负责在运行时查找和装入Class字节码文件。JVM在运行时会产生三个ClassLoader:根装载器、扩展类加载器和应用程序类加载器。其中根装载器不是ClassLoader的子类,它是由C++语言编写,因此我们在java中看不到它。根装载器负责装载JRE的核心类库,如JRE目标下的大rt.jar、charsets.jar等。扩展类加载器和应用程序类加载器都是ClassLoader的子类,其中扩展类加载器负责装载JRE扩展目录ext中的JAR类包;应用程序类加载器负责加载Classpath路径下的类包。
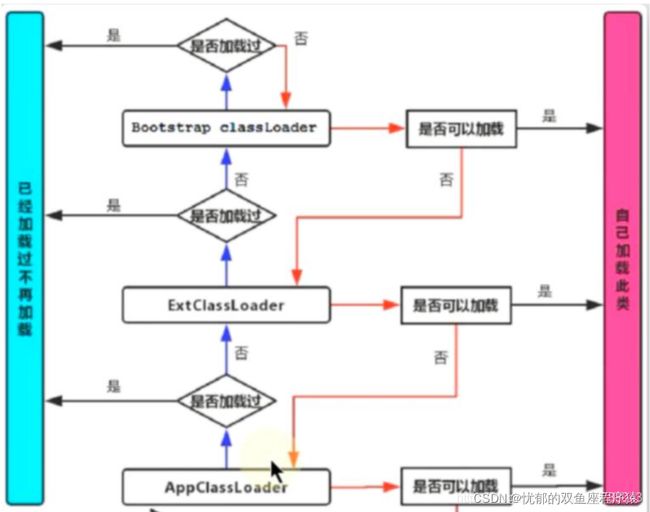
**三、双亲委派模型过程
某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父类加载器,依次递归,如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。**
双亲委派模型的系统实现
在java.lang.ClassLoader的loadClass()方法中,先检查是否已经被加载过,若没有加载则调用父类加载器的loadClass()方法,若父加载器为空则默认使用启动类加载器作为父加载器。如果父加载失败,则抛出ClassNotFoundException异常后,再调用自己的findClass()方法进行加载。
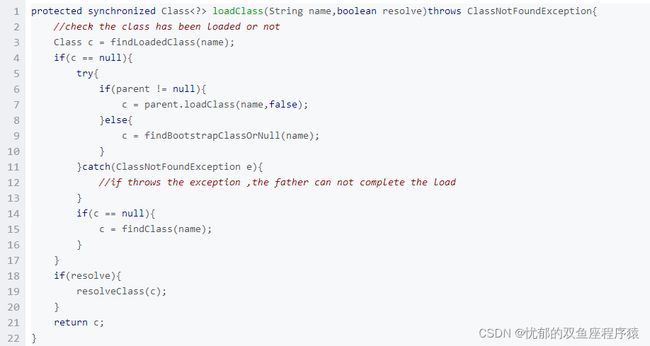
使用双亲委派模型的好处在于Java类随着它的类加载器一起具备了一种带有优先级的层次关系。例如类java.lang.Object,它存在在rt.jar中,无论哪一个类加载器要加载这个类,最终都是委派给处于模型最顶端的Bootstrap ClassLoader进行加载,因此Object类在程序的各种类加载器环境中都是同一个类。相反,如果没有双亲委派模型而是由各个类加载器自行加载的话,如果用户编写了一个java.lang.Object的同名类并放在ClassPath中,那系统中将会出现多个不同的Object类,程序将混乱。因此,如果开发者尝试编写一个与rt.jar类库中重名的Java类,可以正常编译,但是永远无法被加载运行。
这也是双亲委派模型的优点之一 :避免类的重复加载, 确保一个类的全局唯一性
双亲委派模型还有的优点是:保护程序安全, 防止核心 API 被随意篡改
同时 又延伸出了对应的缺点:
检查类是否加载的委派过程是单向的, 这个方式虽然从结构上说比较清晰,
使各个 ClassLoader 的职责非常明确, 但是同时会带来一个问题, 即顶层的
ClassLoader 无法访问底层的 ClassLoader 所加载的类
通常情况下, 启动类加载器中的类为系统核心类, 包括一些重要的系统接口,
而在应用类加载器中, 为应用类。 按照这种模式, 应用类访问系统类自然是没
有问题, 但是系统类访问应用类就会出现问题。 比如在系统类中提供了一个接
口, 该接口需要在应用类中得以实现, 该接口还绑定一个工厂方法, 用于创建该
接口的实例, 而接口和工厂方法都在启动类加载器中。 这时, 就会出现该工厂方
法无法创建由应用类加载器加载的应用实例
双亲委派模型的系统实现
在java.lang.ClassLoader的loadClass()方法中,先检查是否已经被加载过,若没有加载则调用父类加载器的loadClass()方法,若父加载器为空则默认使用启动类加载器作为父加载器。如果父加载失败,则抛出ClassNotFoundException异常后,再调用自己的findClass()方法进行加载。
代码展示
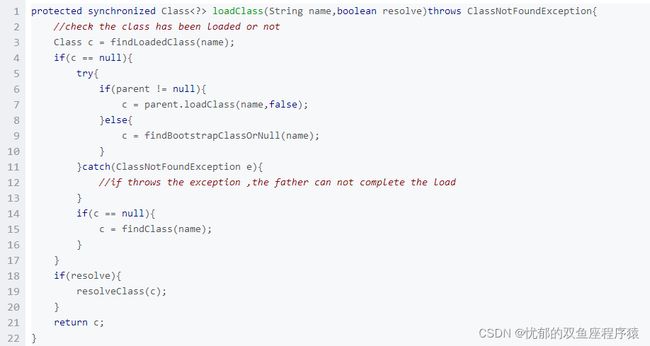
调用流程图:
类加载运行流程以及字节码观赏
JVM 是如何编译执行一段代码的
public static void main(String[] args) {
System.out.println("hello world");
}
jvm 是这样进行编译和执行的


先判断方法和返回类型: 然后生成 字节码指令
jvm 指令符:
getstatic 因为static 是静态的所以在本地获取 system对应的对象里面获取到 out 的静态属性 将这个属性压入操作树栈
ldc#3 去字符串 静态常量池 获取到字符串真正的内容 在压入 操作树栈
invokevirtual #4 传递两个参数 有个默认的 this 指针
因为我们调用的print方法不是个静态方法。所以要知道方法来源。 把helloword 传入 然后 就输出了
return 是默认返回的 根据不同的返回类型执行不同的的 return 例如 ireturn lreturn arereturn dreturn freturn 登等 例如 void 的return 虚拟机在执行return 之前 要去通过 pop 释放 main 方法引用的对应的栈帧