IO模型--多路复用
阻塞IO 和非阻塞IO 这两个概念是程序级别的。主要描述的是程序请求操作系统IO操作后,如果IO资源没有准备好,那么程序该如何处理的问题:前者等待;后者继续执行(但是使用线程一直轮询,直到有IO资源准备好了)。
同步IO 和 异步IO,这两个概念是操作系统级别的。主要描述的是操作系统在收到程序请求IO操作后,如果IO资源没有准备好,该如何响应程序的问题:前者不响应,直到IO资源准备好以后;后者返回一个标记(好让程序和自己知道以后的数据往哪里通知),当IO资源准备好以后,再用事件机制返回给程序。
同步阻塞模式总结
BIO模式因为进程的阻塞挂起,不会消耗过多的CPU资源,而且开发难度低,比较适合并发量小的网络应用开发。同时很容易发现因为请求IO会阻塞进程,所以不时候并发量大的应用。如果为每一个请求分配一个线程,系统开销就会过大。
同时在Java中,使用了多线程来处理阻塞模式,也无法解决程序在accept()和read()时候的阻塞问题。因为accept()和read()的IO模式支持是基于操作系统的,如果操作系统发现没有套接字从指定的端口传送过来,那么操作系统就会等待。这样accept()和read()方法就会一直等待。
同步非阻塞模式总结
用户需要不断地调用,尝试读取数据,直到读取成功后,才继续处理接收的数据。整个IO请求的过程中,虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
3、Multiplexing I/O【I/O多路复用】 同步阻塞io
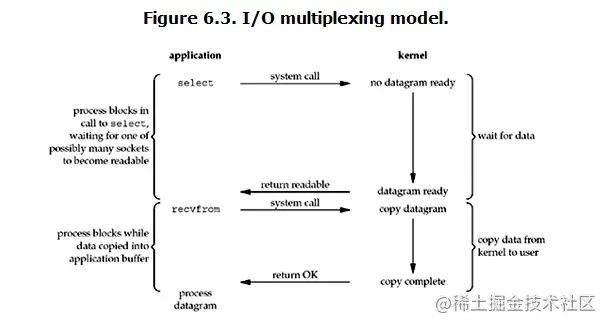
Multiplexing I/O,就是IO多路复用。在这里可能童鞋们就会发现这种IO方式跟前面的已经不同了,直接将IO多路复用可能大家不知道是什么,如果提到select/poll/epoll,在这里肯定大家都有所耳闻。IO多路复用也叫Event Driver IO【事件驱动IO】。至于什么是select/poll/epoll,等会再讲解
先来看下IO多路复用是怎么工作的。从图中可以看到,操作系统提供了一个叫select的系统调用,当一个用户进程调用了select,则该用户进程所负责的所有socket同样被select所负责。对于内核,则监听着所有select负责的socket。当调用了select之后,select会不断的轮询所有的socket,当某个socket有数据到达了,select就会返回,告知用户进程将数据拷贝从内核空间拷贝到用户空间
举例:跟上面的两种方式有很大的不同。假如有很多客户来买奶茶,每个客户用一个卡片将自己的姓名跟要买的奶茶型号写在上面,然后统一交给店员。每一次店员做好奶茶后,要在一堆卡片中,根据做好的奶茶型号找到对应的姓名,通知客户过来取奶茶。在这种方式上,每一次店员奶茶做好后,需要花大量的时间在一堆卡片中寻找客户。同样的,客户在等待奶茶做好之前,啥事都没干只有瞎等着【阻塞状态】
第三个问题:什么是select/poll/epoll
首先说明的是,select/poll/epoll是一种机制。这种机制是来实现IO多路复用的。那么这种机制是怎么实现的,就是内核提供了一种方式来实现一个进程可以监听多个不同的描述符,一旦有描述符数据准备就绪,就通知进程过来读取数据。而select/poll/epoll就是来实现这个方式的三种不同的方法
**select方式的实现。**在一个或多个进程管理着不同的描述符,每个描述符都有唯一的标识。当一个或多个进程向内核发起了select的系统调用后,内核就开始准备数据,当数据准备好后,要返回给对应进程中对应的描述符时,select需要遍历所有进程中所有的描述符,找到对应的发起请求的那个描述符后通知进程来读取数据。由于每次都要把select管理的进程轮询一遍,时间复杂度就是我们所说的 O(N) 复杂度。在select方式中,系统规定了单个进程中能够打开的描述符最大上限是1024个。至于为啥是1024个,这里就不再说明了
举例来理解:还是上面提到的买奶茶的例子。当有不同的客户【进程】来买奶茶,同时每个客户还要帮各自的朋友们买【描述符】,不过每个客户最多只能帮1024个朋友买【上限1024个描述符】,多的就不行了。这时候这些客户把自己的身份证号,自己朋友的生份证号,还有排队编号写在了一张卡片上交给了店员。等到奶茶做好后,店员就在这一堆卡片中,根据排队编号找到对应的客户身份证号,再通知客户过来取奶茶,再把奶茶送到对应的朋友手中。在这个过程中,每次店员都要把每一张卡片看遍【轮询遍历】,这就是所谓的O(N)复杂度,很明显,这很耗时间
**poll方式的实现。**poll的实现过程其实和select是一样的,只不过poll方式没有select有1024个最大描述符的限制
**epoll方式的实现。**在epoll方式中,跟select和poll方式不同的是,当一个或多个进程向内核发起了epoll调用后,内核这个时候就给该进程的描述符注册一个回调函数,在内核准备好数据后,让对应的描述符的进程自己过来读取数据,每一次只需要通知一个进程就行了,这个时间复杂度就是 O(1) 复杂度,很明显,这比 O(N) 复杂度效率高的太多了
举例来理解:还是同样的买奶茶的例子。当这些不同的客户过来买奶茶时,不再是扔一堆卡片跟店员了,而是店员给每一个客户一个呼叫机【注册了一个回调函数】,当呼叫机对应的奶茶做好后,就通知客户【进程】过来拿奶茶,这时候店员的工作量就已经是最小的了,每一次只需要通知到一个客户就行,这样效率就高太多了
以上就是关于select/poll/epoll方式的说明,在这里只提到了怎么通俗的理解这三种方式,其他的一些技术上的理解就不再说明了。
在IO多路复用中,本质上是和BIO是一样的。不同的是系统提供了一个机制,这种机制可以用来一次处理很多请求。但是对于进程的状态以及获取数据结果的过程,都是阻塞的状态和同步的过程。所以Multiplexing I/O也是同步阻塞IO
参考:阻塞、非阻塞、多路复用、同步、异步、BIO、NIO、AIO 一锅端 - 掘金