【JavaEE初阶】第八节.多线程(基础篇)阻塞队列(案例二)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
一、阻塞队列概论
1.1 阻塞队列的概念与作用
1.2 阻塞队列的应用场景 —— 生产者消费者模型
1.3 生产者消费者模型的好处
二、阻塞队列的实现
2.1 Java标准库里面的实现
2.2 自己动手去模拟实现一个阻塞队列
2.2.1 首先实现一个普通队列
2.2.2 接着需要解决线程安全问题
2.2.3 最后来实现阻塞效果
总结
前言
在单例模式之后,我们就来学习一下 第二个多线程案例 —— 阻塞队列;
提示:以下是本篇文章正文内容,下面案例可供参考
写在前面
在单例模式之后,我们就来学习一下 第二个多线程案例 —— 阻塞队列;
如果学过数据结构的话,就会知道 在数据结构里也有:队列、优先级队列;
队列:最简单的队列,先进先出,可基于数组实现,也可基于链表实现;
这是最朴素的队列,还衍生出了一些特殊规则的队列;
优先级队列:出队列不是完全按照 先进先出 了,而是优先级高的先出;
内部基于堆(完全二叉树)来实现的;
阻塞队列 在生活中又有很常见的例子:
比如说,做核酸的例子:
做核酸的时候,经常是有好多个队伍在排队,假设现在某个队伍已经没人了,那么 做核酸的工作人员 不会立即走的,还会等待,等待新的人过来,一直到约定好的时间;
再假设 现在的人比较多,张三同学过来做核酸了,他看了看人比较多,也不想在太阳底下晒着,就先在树荫里玩一会手机,等人少一点 然后再过去排队;
一、阻塞队列概论
1.1 阻塞队列的概念与作用
阻塞队列 实际上还是一种队列,遵循 "先进先出、后进后出" 的原则,它能够保证 "线程安全";
其主要特点是:
- 如果队列为空,尝试出队列 就会阻塞;
- 如果队列满,尝试入队列 也会阻塞;
阻塞:让线程停下来 等一等,本质上就是修改了线程的状态,让线程的 PCB 在内核中暂时不参与调度;
1.2 阻塞队列的应用场景 —— 生产者消费者模型
阻塞队列,其中的一个最重要的场景:生产者消费者模型;
咱们可以例举出一个场景来帮助理解什么叫做 生产者消费者模型:
过年的时候 包饺子,都是一家人围在一起,一起来包饺子;
包饺子里面有很多道工序,现在就简化一下步骤,假设只有以下步骤:擀饺子皮 —> 包饺子;
当人多的时候来包饺子的时候,会有这两种情况:
- 每个人都分别自己擀皮,自己包饺子;
- 有一个人专门负责擀皮,其他人来包饺子;
第一种情况:我们把每一个人想象成一个线程,每个线程都分别完成 "擀皮" 和 "包饺子" 这两样工作;
第二种情况:我们还是把每一个人想象成一个线程,一个线程负责 "擀皮",其它线程负责 "包饺子";
这两种情况 都是多线程编程典型的解决问题的方式
但是,其实还是有一点点缺陷的:
第一种情况 的效率比较低,多个线程都在抢同一个资源(擀面杖,正常家庭 也就只有一个擀面杖),只有 拿到 "擀面杖" 的线程 才可以 "擀皮",其他的线程 就可能在摸鱼、等着;
第二种情况 的效率就比较高效,擀皮的人一直都使用擀面杖,其他的人不使用;
而这第二种情况,我们就把它叫做 生产者消费者模型!!!


盖帘 就是一个阻塞队列,阻塞队列 的特点 在这上面也是可以体现的;
比如说,极端情况下,负责包饺子的消费者 包的太快了,使得负责擀皮的生产者跟不上了,盖帘 上面的饺子皮 都没有了,所以 负责包饺子的消费者 就只能阻塞等待,直到擀皮的人擀了一个新的饺子皮以后再取走;
另外一种极端情况,擀皮的人搞得太快了,包饺子的人包的太慢了,一顿操作猛如虎,擀皮的人把 盖帘 搞满了,所以此时 负责擀皮的人只能再等待一会;
像这样的场景,我们把它叫做 生产者消费者模型!!
1.3 生产者消费者模型的好处
使用 生产者消费者模型,在工作中是非常频繁的
优点有很多,其中最为明显的优点有两条:
(一)可以做到更好的 "解耦合"
耦合:两个模块的关联关系越紧密,就说明 耦合程度越高,一边出问题就会导致另一边出现问题,一边出问题就会对另一边有影响;
在写代码的时候,我们追求的都是 "低耦合",我们都希望,万一某一个模块出现了问题,另外一边还可以照常的工作,不会有太大的影响;

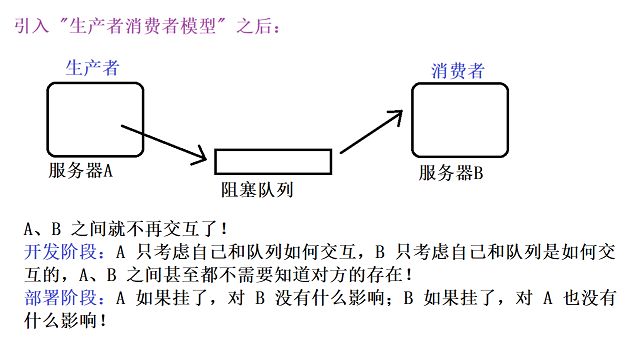
如果 服务器A 突然又发了一个数据 给服务器C,那么 在引入 "生产者消费者模型" 之前,就需要 重新调整 服务器A所需发送的数据的代码;但是,在引入 "生产者消费者模型" 之后,就不需要重新调整了,只需要 服务器C 去队列里取数据就可以了 ;
(二) 使用 生产者消费者模型,可以提高整个系统的抗风险能力
可以类似于 三峡大坝 的 "削峰填谷" 的功能:在旱季放水,在涝季存水 ;
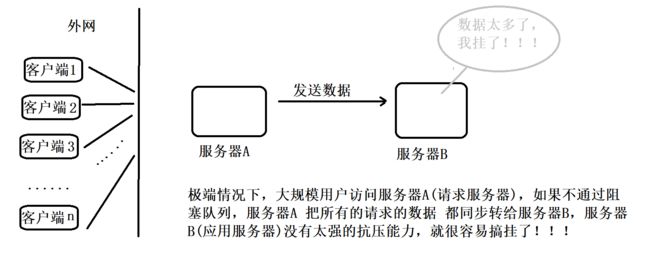
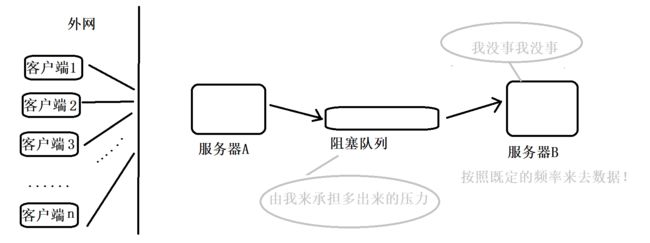

二、阻塞队列的实现
2.1 Java标准库里面的实现
首先,在 Java 标准库里面,提供了一个现成的实现
BlockingQueue 虽然也能够使用 offer、poll 等普通队列的方法,但是仍然建议大家使用 put 来入队列,使用 take 来出队列(这样可以做到 阻塞 的效果)
我们可以使用 sleep方法 来模拟生产者生产、消费者消费的频率:
情况一:生产者生产频率 = 消费者消费频率
代码实现:
package thread; import java.util.concurrent.BlockingDeque; import java.util.concurrent.LinkedBlockingDeque; public class Demo21 { public static void main(String[] args) { //内部基于链表实现 LinkedBlockingDeque BlockingDequequeue = new LinkedBlockingDeque<>(); //创建一个消费者线程 //消费者 每秒消费1个 Thread customer = new Thread(()-> { //获取队列里面的元素 while (true) { try { int value = queue.take();//自动拆箱 System.out.println("消费元素:" + value); Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } }); customer.start(); //创建一个生产者线程 //生产者每秒生产1个 Thread producer = new Thread(() -> { int n = 0; while (true) { System.out.println("生产元素:" + n); try { queue.put(n); n++; Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } }); producer.start(); } } 运行结果:

解析:
生产者与消费者频率一致;生产者刚生产好,就立即消费者被消费;
此时消费者步调与生产者一致;
情况二:生产者生产频率 > 消费者消费频率
代码实现:
使得生产者每 1 秒生产一个,消费者每 2 秒消费一个(代码都和上面一样,只不过把 sleep() 里面的时间修改了,所以就不做过多解释了)
运行结果:
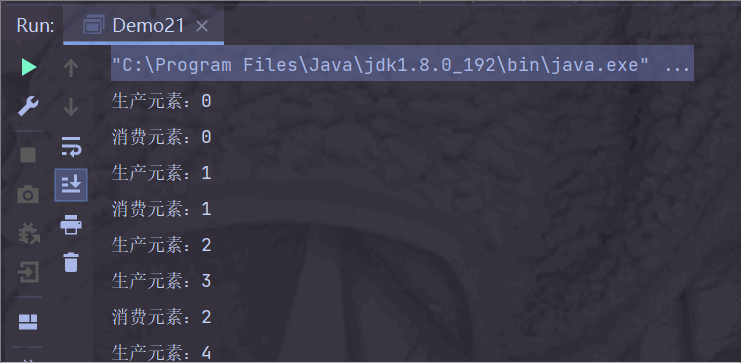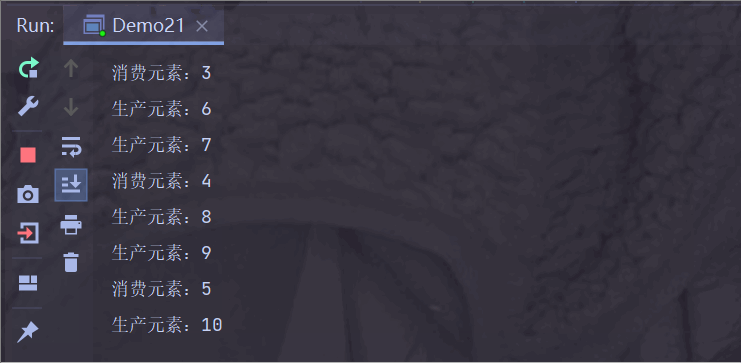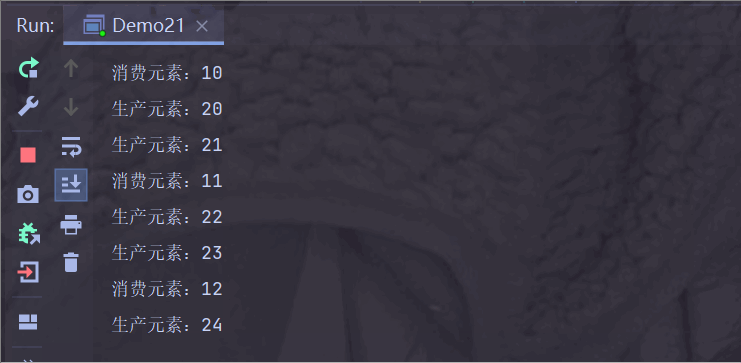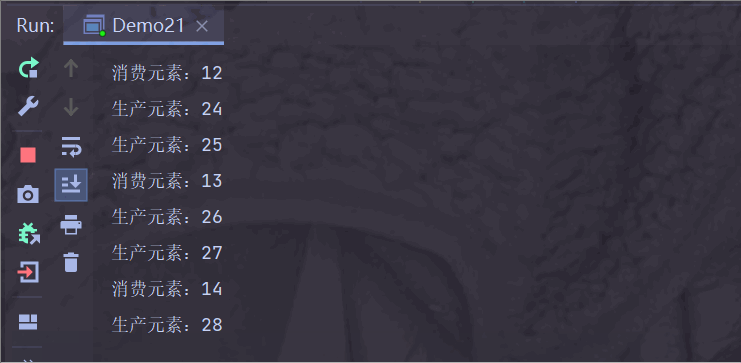
生产者生产快一点,消费者消费慢一点;
阻塞队列满了之后,生产者需要等待消费者消费后才能生产;
此时生产者步调与消费者一致;
情况三:生产者生产频率 < 消费者消费频率
使得生产者每 2 秒生产一个,消费者每 1 秒消费一个(代码都和上面一样,只不过把 sleep() 里面的时间修改了,所以就不做过多解释了)
运行结果:
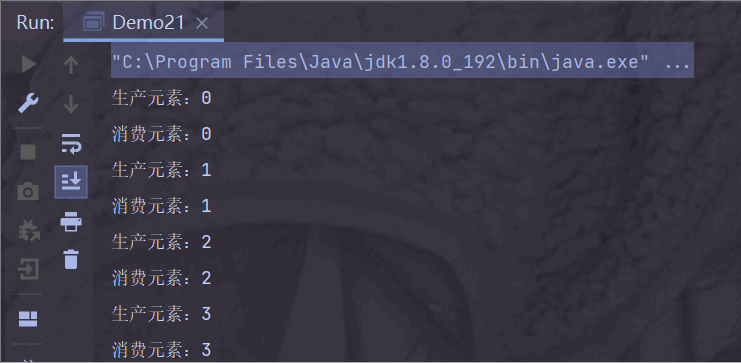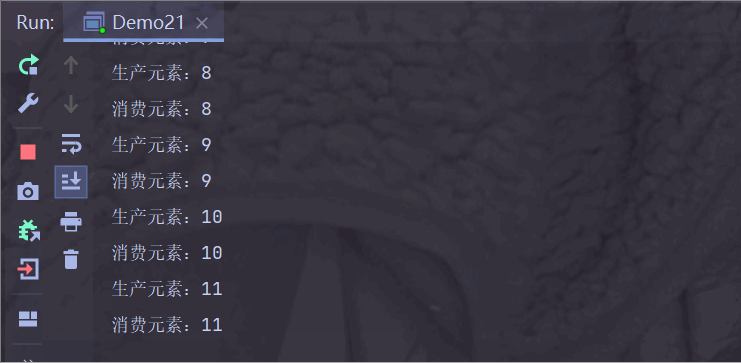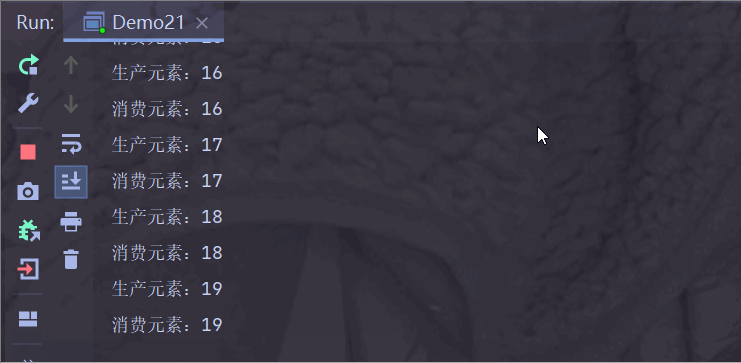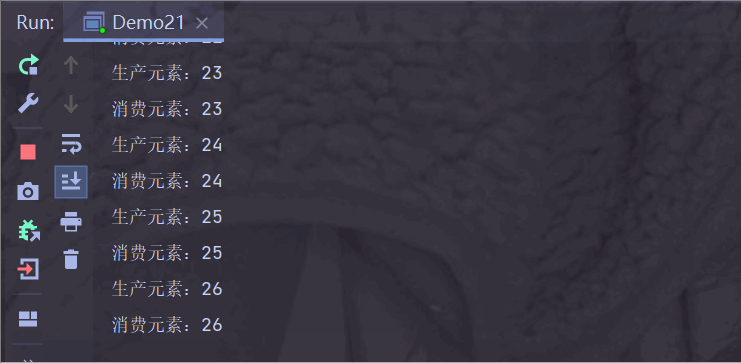
生产者生产慢一点,消费者消费快一点;
阻塞队列为空之后,消费者需要等待生产者生产,消费者才能消费;
此时消费者步调与生产者一致;
2.2 自己动手去模拟实现一个阻塞队列
2.2.1 首先实现一个普通队列
在这之前,我们需要模拟一个普通队列
//基于数组的方式来实现,提供 2 个核心方法:
// 1.put方法 入队列
// 2.take方法 出队列
class MyBlockingQueue {
//假定最大是 1000 个元素,当然也可以设定成 可配置的
private int[] items = new int[1000];
//对首的位置
private int head = 0;
//对尾的位置
private int tail = 0;
//队列的元素个数
private int size = 0;
//入队列
public void put(int value) {
synchronized (this) {
}
if(size == items.length) {
//队列已满,无法插入
return;
}
//队列没满,入队列
items[tail] = value;
tail++;
if (tail == items.length){
//判断 tail 是否到达末尾
//如果 tail 到达末尾,就需要从头开始
tail = 0;
}
//往上数五行代码,可以直接换成 tail = tail % items.length;
//不过带来了一些问题
//1.可读性不太好~ 写 if 做判断,一看就明白了;写 % 运算,也许其他人看不懂
//2.当使用 % 运算的时候,只有说 % 后面的操作数是 2^n 的时候,% 才能有一个比较高效的计算过程 (被编译器优化成与运算)
// 如果是随意给的运算,大概率是不行了
//个人建议 if() 版本
size++;
}
//出队列
public Integer take() { //int 不可以返回 null,Integer 可以返回 null
if (size == 0) {
//队列为空,无法出队列
return null;
}
//队列不为空,则 取出队首元素
int ret = items[head];
head++;
if (head == items.length) {
head = 0;
}
size--;
return ret;
}
}接着,我们可以在普通队列的基础上进行改进
- 线程安全 —— 加锁、volatile
- 阻塞 —— wait、notify
然后就自己模拟实现了一个阻塞队列啦;
2.2.2 接着需要解决线程安全问题
单例模式 之所以使用两个 if 的原因,是因为 单例模式 只是在初始化阶段有线程安全问题,一旦初始化好了,就线程安全了,所以需要使用外层条件 来决定当前是否要加锁;
而 当下的阻塞队列,是自始至终都有线程安全问题的,这个锁就得要始终加上;
需要注意的是,多线程这里,要不要加锁,具体锁加在哪里,是没有规律的,只能具体问题具体分析(千万不要无脑加锁);
当然,这个阻塞队列到处都是修改和读操作,就可以无脑加锁了;
当然,队列的元素个数 时不时的在读,而且在修改,加上 volatile 可能会更好;
代码实现:
//基于数组的方式来实现,提供 2 个核心方法: // 1.put方法 入队列 // 2.take方法 出队列 class MyBlockingQueue { //假定最大是 1000 个元素,当然也可以设定成 可配置的 private int[] items = new int[1000]; //对首的位置 private int head = 0; //对尾的位置 private int tail = 0; //队列的元素个数 volatile private int size = 0; //入队列 public void put(int value) { synchronized (this) { if(size == items.length) { //队列已满,无法插入 return; } //队列没满,入队列 items[tail] = value; tail++; if (tail == items.length){ //判断 tail 是否到达末尾 //如果 tail 到达末尾,就需要从头开始 tail = 0; } //往上数五行代码,可以直接换成 tail = tail % items.length; //不过带来了一些问题 //1.可读性不太好~ 写 if 做判断,一看就明白了;写 % 运算,也许其他人看不懂 //2.当使用 % 运算的时候,只有说 % 后面的操作数是 2^n 的时候,% 才能有一个比较高效的计算过程 (被编译器优化成与运算) // 如果是随意给的运算,大概率是不行了 //个人建议 if() 版本 size++; } } //出队列 public Integer take() { //int 不可以返回 null,Integer 可以返回 null int ret = 0; synchronized (this) { if (size == 0) { //队列为空,无法出队列 return null; } //队列不为空,则 取出队首元素 ret = items[head]; head++; if (head == items.length) { head = 0; } size--; } return ret; } }
2.2.3 最后来实现阻塞效果
阻塞有两种情况的:
- 队列为空,要阻塞,当队列不空的时候 就唤醒;
- 队列为满,要阻塞。当队列不满的时候 就唤醒;
所以,我们可以把 put 和 take 方法 改成如下形式:
注意:
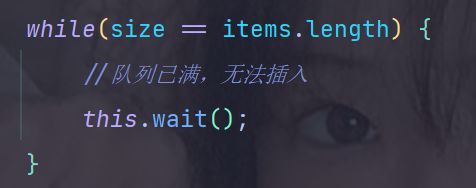
虽然按照上述的代码,发现唤醒的时候,一定是有元素插入成功了,所以条件不成立,等待确实是要结束了;
但是,更稳妥的办法,是 在唤醒之后,再判断一次(万一条件又成立了呢)!!!
所以,可以把 if 条件句 改成 while 循环语句:
我们 等待之前,判断一次;唤醒之后,再确认一次;

所以,最终的代码就出来了:
package thread; //自己来模拟实现一个阻塞队列 //基于数组的方式来实现,提供 2 个核心方法: // 1. put方法 入队列 // 2.take方法 出队列 class MyBlockingQueue { //假定最大是 1000 个元素,当然也可以设定成 可配置的 private int[] items = new int[1000]; //对首的位置 private int head = 0; //对尾的位置 private int tail = 0; //队列的元素个数 volatile private int size = 0; //入队列 public void put(int value) throws InterruptedException { synchronized (this) { while(size == items.length) { //队列已满,无法插入 this.wait(); } //队列没满,入队列 items[tail] = value; tail++; if (tail == items.length){ //判断 tail 是否到达末尾 //如果 tail 到达末尾,就需要从头开始 tail = 0; } //往上数五行代码,可以直接换成 tail = tail % items.length; //不过带来了一些问题 //1.可读性不太好~ 写 if 做判断,一看就明白了;写 % 运算,也许其他人看不懂 //2.当使用 % 运算的时候,只有说 % 后面的操作数是 2^n 的时候,% 才能有一个比较高效的计算过程 (被编译器优化成与运算) // 如果是随意给的运算,大概率是不行了 //个人建议 if() 版本 size++; //插入元素成功,说明队列不空,就要唤醒 this.notify(); } } //出队列 public Integer take() throws InterruptedException { //int 不可以返回 null,Integer 可以返回 null int ret = 0; synchronized (this) { while(size == 0) { //队列为空,就等待 this.wait(); } //队列不为空,则 取出队首元素 ret = items[head]; head++; if (head == items.length) { head = 0; } size--; //当取走一个元素成功,说明队列不满,就要唤醒 this.notify(); } return ret; } } public class Demo22 { public static void main(String[] args) throws InterruptedException { MyBlockingQueue queue = new MyBlockingQueue(); Thread customer = new Thread(() -> { while (true) { int value = 0; try { value = queue.take(); System.out.println("消费:" + value); Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } }); customer.start(); Thread producer = new Thread(() -> { int value = 0; while (true){ try { queue.put(value); System.out.println("生产:" + value); value++; Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } }); producer.start(); } }运行结果:

总结
好了,关于多线程的第二个案例 —— 阻塞队列,就暂时介绍到这里了;下一节内容我们将继续介绍有关多线程的下一个案例,让我们下一节再见!!!!!
