从prometheus生态系统组件到集成Java开发
Prometheus介绍
Prometheus是最初在SoundCloud上构建的开源系统监视和警报工具包。于2016年加入了 Cloud Native Computing Foundation,这是继Kubernetes之后的第二个托管项目。Prometheus 其实就是一个数据监控解决方案,它能帮你简单快速地搭建起一套可视化的监控系统。
官网:https://prometheus.io
文档:https://prometheus.io/docs/introduction/overview/
prometheus各组件:https://prometheus.io/download/
prometheus的架构
下图说明了Prometheus的体系结构及其某些生态系统组件:
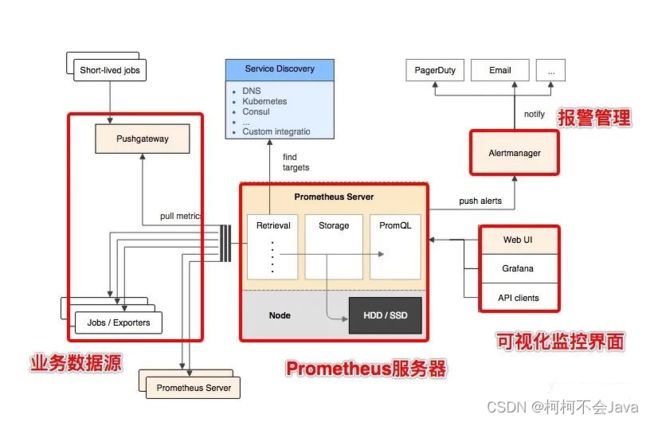
从上图可以看到,整个 Prometheus 可以分为四大部分,分别是:
- Prometheus 服务器
Prometheus Server 是 Prometheus 组件中的核心部分,负责实现对监控数据的获取,存储以及查询。
- NodeExporter 业务数据源
业务数据源通过 Pull/Push 两种方式推送数据到 Prometheus Server。
- AlertManager 报警管理器
Prometheus 通过配置报警规则,如果符合报警规则,那么就将报警推送到 AlertManager,由其进行报警处理。
- 可视化监控界面
Prometheus 收集到数据之后,由 WebUI 界面进行可视化图标展示。目前我们可以通过自定义的 API 客户端进行调用数据展示,也可以直接使用 Grafana 解决方案来展示。
简单地说,Prometheus 的实现架构也并不复杂。其实就是收集数据、处理数据、可视化展示,再进行数据分析进行报警处理。 但其珍贵之处在于提供了一整套可行的解决方案,并且形成了一整个生态,能够极大地降低我们的研发成本。
Prometheus安装
下载地址
https://prometheus.io/download/

安装
mkdir /usr/local/prometheus
tar -zxvf prometheus-2.35.0.linux-amd64.tar.gz
启动
nohup /usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml &
访问
Prometheus配置
prometheus的配置文件prometheus.yml,它主要分以下几个配置块:
全局配置 global
告警配置 alerting
规则文件配置 rule_files
拉取配置 scrape_configs
远程读写配置 remote_read、remote_write
全局配置 global
global指定在所有其他配置上下文中有效的参数。还可用作其他配置部分的默认设置。
global:
# 默认拉取频率
[ scrape_interval: > | default = 1m ]
# 拉取超时时间
[ scrape_timeout: > | default = 10s ]
# 默认情况下Prometheus会每分钟对告警规则进行计算,如果用户想定义自己的告警计算周期,则可以通过evaluation_interval来覆盖默认的计算周期
[ evaluation_interval: > | default = 1m ]
# 通信时添加到任何时间序列或告警的标签
# external systems (federation, remote storage, Alertmanager).
external_labels:
[ > ... ]
# 记录PromQL查询的日志文件
[ query_log_file: > ]
告警配置 alerting
alerting指定与Alertmanager相关的设置。
alerting:
alert_relabel_configs:
[ - > ... ]
alertmanagers:
[ - > ... ]
规则文件配置 rule_files
rule_files指定prometheus加载的任何规则的位置,从所有匹配的文件中读取规则和告警。目前没有规则。
rule_files:
[ - > ... ]
拉取配置 scrape_configs
scrape_configs指定prometheus监控哪些资源。默认会拉取prometheus本身的时间序列数据,通过http://localhost:9090/metrics进行拉取。
一个scrape_config指定一组目标和参数,描述如何拉取它们。在一般情况下,一个拉取配置指定一个作业。在高级配置中,这可能会改变。
scrape_configs:
# 作业名
- job_name: "prometheus"
# 拉取的http路径,默认是http://主机地址:9090/metrics
# metrics_path defaults to '/metrics'
# 配置用于请求的协议,默认是http
# scheme defaults to 'http'.
# 静态配置拉取主机目标列表
static_configs:
- targets: ["192.168.0.231:9090"]
# 另一个拉取的作业配置,可以配置多个Node Exporter节点
- job_name: 'node1'
static_configs:
- targets: ['192.168.0.232:9100']
拉取指标配置 metric_relabel_configs
通过metric_relabel_configs可配置想要拉取的指标,例如下面是配置node232这个作业,只拉取name以node或者http开头的指标
scrape_configs:
- job_name: 'node232'
static_configs:
- targets: ['192.168.0.232:9100']
metric_relabel_configs:
- source_labels: [__name__]
regex: (node|http).*
action: drop
可以看到node开头的node_memory_Active_bytes指标已经拉取不了了

Node Exporter部署
下载node_exporter
安装
mkdir /usr/local/node_exporter
tar -zxvf node_exporter-1.3.1.linux-amd64.tar.gz
启动
nohup /usr/local/node_exporter/node_exporter --collector.cpu.info &
访问

配置
启动好node_exporter后,还需要配置prometheus才能访问node exporter指标。
vim /usr/local/prometheus/prometheus.yml
scrape_configs:
# 作业名
- job_name: "prometheus"
# 静态配置拉取主机目标列表
static_configs:
- targets: ["192.168.0.231:9090"]
# 另一个拉取的作业配置,可以配置多个Node Exporter节点
- job_name: 'node1'
static_configs:
- targets: ['192.168.0.232:9100']
重启prometheus
ps -ef|grep prometheus
kill -9 进程号
nohup /usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml &
再次访问
访问prometheus页面,Status → Targets
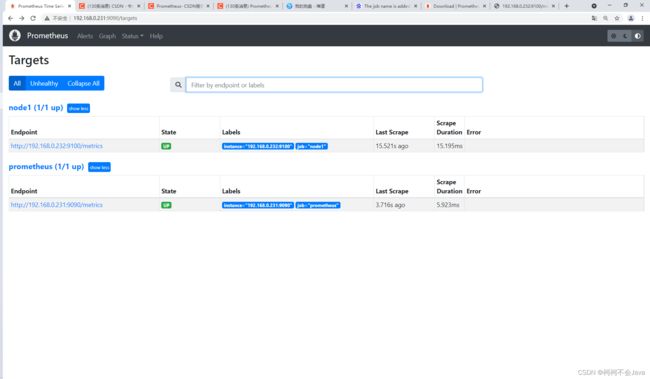
监控数据查看
Prometheus UI 是 Prometheus 内置的一个可视化管理界面,我们通过 http://1902.168.0.231:9090 就可以访问到该页面。
通过 Prometheus UI 可以查询 Prometheus 收集到的数据,而 Prometheus 定义了 PromQL 语言来作为查询监控数据的语言,其余 SQL 类似。
访问 http://localhost:9090,进入到 Prometheus Server。如果输入「up」并且点击执行按钮以后,可以看到如下结果:
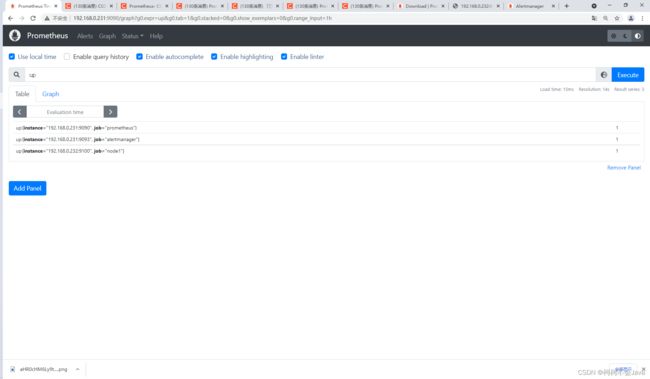
可以看到 Element 处有几条记录,其中 instance 值为 localhost:8080 的记录,value 是 1,这代表对应应用是存活状态。
up{instance="192.168.0.231:9090", job="prometheus"} 1
例如查看我们所运行 NodeExporter 节点所在机器的内存使用情况,可以输入 node_memory_Active_bytes/(1024*1024*1024) 查看。
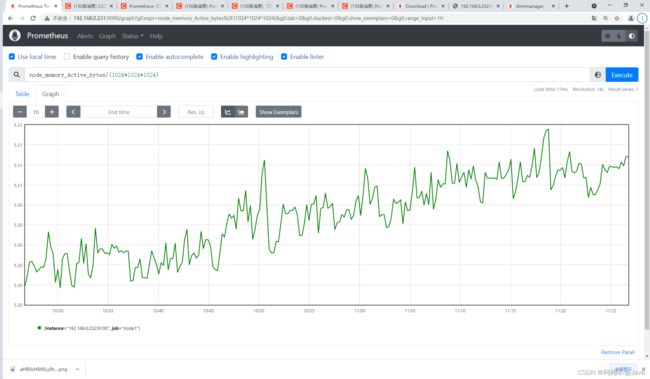
Prometheus + Grafana实现可视化、告警
Prometheus UI 提供了快速验证 PromQL 以及临时可视化支持的能力,但其可视化能力却比较弱。一般情况下,我们都用 Grafana 来实现对 Prometheus 的可视化实现。
什么是 Grafana
Grafana 是一个用来展示各种各样数据的开源软件,在其官网上用这么一段话来说明其作用。Used by thousands of companies to monitor everything from infrastructure, applications, and power plants to beehives. 数以万计的公司用 Grafana 来监控基础设施、应用。
安装 Grafana
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-8.5.2-1.x86_64.rpm
yum install grafana-enterprise-8.5.2-1.x86_64.rpm
访问
登录
初始账号和密码:
admin
admin
配置数据源
配置面板
在 Grafana 中有「Dashboard」和「Panel」的概念,Dashboard 可以理解成「看板」,而 Panel 可以理解成「图表,一个看看板中包含了无数个图表。创建一个图表来显示内存使用情况


AlertManager安装
安装
地址和上面Prometheus一样,安装步骤也和上面Prometheus一样。
启动
nohup /usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml &
访问
配置 alerting
启动好alertmanager后,还需要配置prometheus才能通过alertmanager告警。
vim /usr/local/prometheus/prometheus.yml
alerting:
alertmanagers:
- static_configs:
- targets: ["192.168.0.231:9093"]
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["192.168.0.231:9090"]
- job_name: 'node1'
static_configs:
- targets: ['192.168.0.232:9100']
- job_name: 'alertmanager'
static_configs:
- targets: ['192.168.0.231:9093']
重启Prometheus再次访问

可以看到,之前部署的alertmanager状态是UP,说明运行正常。
alertmanager部署完成。但alertmanager还需要进一步配置通知路由和通知接收者。
AlertManager配置实现邮件投递
alertmanager通过命令行标志和配置文件进行配置。命令行标志配置不可变的系统参数时,配置文件定义禁止规则,通知路由和通知接收器。
alertmanager的配置文件alertmanager.yml,它主要分以下几个配置块:
全局配置 global
通知模板 templates
路由配置 route
接收器配置 receivers
抑制配置 inhibit_rules
全局配置 global
global指定在所有其他配置上下文中有效的参数。还用作其他配置部分的默认设置。
global:
# 经过此时间后,如果尚未更新告警,则将告警声明为已恢复。(即prometheus没有向alertmanager发送告警了)
resolve_timeout: 5m
# 下面是邮件推送的相关配置
# 邮件发送方
smtp_from: '[email protected]'
# SMTP服务器用于发送电子邮件,包括端口号
smtp_smarthost: 'smtp.qiye.aliyun.com:465'
# 发送方邮件名
smtp_auth_username: '[email protected]'
# 发送方邮件密码
smtp_auth_password: '123456'
# 是否使用tls加密
smtp_require_tls: false
通知模板 templates
templates指定了从其中读取自定义通知模板定义的文件,最后一个文件可以使用一个通配符匹配器,如templates/*.tmpl。
templates:
['/usr/local/alertmanager/alertmanager-0.21.0.linux-amd64/templates/alert.tmpl']
alert.tmpl文件配置
{{ define "email.from" }}发送方邮箱地址{{ end }}
{{ define "email.to" }}接收方邮箱地址{{ end }}
{{ define "email.to.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}
<h2>@告警通知h2>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} 级 <br>
告警类型: {{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Local.Format "2006-01-02 15:04:05" }} <br>
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}
<h2>@告警恢复h2>
告警程序: prometheus_alert <br>
故障主机: {{ .Labels.instance }}<br>
故障主题: {{ .Annotations.summary }}<br>
告警详情: {{ .Annotations.description }}<br>
告警时间: {{ .StartsAt.Local.Format "2006-01-02 15:04:05" }}<br>
恢复时间: {{ .EndsAt.Local.Format "2006-01-02 15:04:05" }}<br>
{{ end }}{{ end -}}
{{- end }}
路由配置 route
route所有报警都会进入到这个根路由下,可以根据根路由下的子路由设置报警分发策略
route:
# 先解释一下分组,分组就是将多条告警信息聚合成一条发送,这样就不会收到连续的报警了。
# 将传入的告警按标签分组(标签在prometheus中的rules中定义),例如:
# 接收到的告警信息里面有许多具有cluster=A 和 alertname=LatencyHigh的标签,这些个告警将被分为一个组。
#
# 如果不想使用分组,可以这样写group_by: [...]
group_by: ['alertname', 'cluster', 'service']
# 第一组告警发送通知需要等待的时间,这种方式可以确保有足够的时间为同一分组获取多个告警,然后一起触发这个告警信息。
group_wait: 30s
# 发送第一个告警后,等待"group_interval"发送一组新告警。
group_interval: 5m
# 分组内发送相同告警的时间间隔。这里的配置是每3小时发送告警到分组中。举个例子:收到告警后,一个分组被创建,等待5分钟发送组内告警,如果后续组内的告警信息相同,这些告警会在3小时后发送,但是3小时内这些告警不会被发送。
repeat_interval: 5m
# 告警发送是需要指定接收器的,接收器在receivers中配置,接收器可以是email、webhook、pagerduty、wechat等等。一个接收器可以有多种发送方式。
receiver: 'email'
# 下面是子路由的配置
routes:
# 使用正则的方式匹配告警标签
- match_re:
# 这里可以匹配出标签含有service=foo1或service=foo2或service=baz的告警
service: ^(foo1|foo2|baz)$
# 指定接收器为team-X-mails
receiver: team-X-mails
接收器配置 receivers
receivers是一个或多个通知集成的命名配置。
# 下面配置的是接收器
receivers:
# 接收器的名称、通过邮件的方式发送
- name: 'email'
email_configs:
# 发送给哪些人
- to: '{{ template "email.to"}}' # 接收警报的email(这里是引用模板文件中定义的变量)
html: '{{ template "email.to.html" .}}' # 发送邮件的内容(调用模板文件中的)
# 是否通知已解决的警报
send_resolved: true
抑制配置 inhibit
下面是关于inhibit(抑制)的配置,先说一下抑制是什么:抑制规则允许在另一个警报正在触发的情况下使一组告警静音。其实可以理解为告警依赖。比如一台数据库服务器掉电了,会导致db监控告警、网络告警等等,可以配置抑制规则如果服务器本身down了,那么其他的报警就不会被发送出来。
inhibit_rules:
# 下面配置的含义:当有多条告警在告警组里时,并且他们的标签alertname,cluster,service都相等,如果severity: 'critical'的告警产生了,那么就会抑制severity: 'warning'的告警。
- source_match: # 源告警(我理解是根据这个报警来抑制target_match中匹配的告警)
severity: 'critical' # 标签匹配满足severity=critical的告警作为源告警
target_match: # 目标告警(被抑制的告警)
severity: 'warning' # 告警必须满足标签匹配severity=warning才会被抑制。
# 必须在源告警和目标告警中具有相等值的标签才能使抑制生效。(即源告警和目标告警中这三个标签的值相等'alertname', 'cluster', 'service')
equal: ['alertname', 'dev', 'instance']
prometheus配置文件配置
global:
scrape_interval: 15s
# 默认情况下Prometheus会每分钟对告警规则进行计算,如果用户想定义自己的告警计算周期,则可以通过evaluation_interval来覆盖默认的计算周期
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets: ["192.168.0.231:9093"]
rule_files:
- "rules/*.yml"
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["192.168.0.231:9090"]
- job_name: 'node1'
static_configs:
- targets: ['192.168.0.232:9100']
prometheus规则文件node-up.yml配置(文件位置放在rule_files配置的rules目录下)
groups:
- name: node-up
rules:
# 告警规则的名称
- alert: node-up
# 基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件
expr: up{} == 0
# 评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending
for: 10s
# 自定义标签,允许用户指定要附加到告警上的一组附加标签
labels:
severity: 1
team: node
# 用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager
annotations:
summary: "{{ $labels.instance }} 已停止运行超过 15s"
description: "主机已经停止运行15s"
示例
# 监控组件停止运行即产生告警
groups:
- name: node-up-rule
rules:
- alert: node-up-rule140
expr: up{instance="192.168.0.140:9100"} == 0
for: 10s
labels:
severity: 1
team: node
annotations:
summary: "{{ $labels.instance }} 已停止运行超过 15s"
description: "主机已经停止运行15s"
- alert: node-up-rule232
expr: up{instance="192.168.0.232:9100"} == 0
for: 10s
labels:
severity: 1
team: node
annotations:
summary: "{{ $labels.instance }} 已停止运行超过 15s"
description: "主机已经停止运行15s"
# 内存使用量大于6GB即产生告警
- name: node-memory-high
rules:
- alert: node-memory-high140
expr: node_memory_Active_bytes{instance="192.168.0.140:9100", job="node140"}/1024/1024/1024 > 6
for: 3s
labels:
severity: 1
team: node
annotations:
summary: "{{ $labels.instance }} 内存使用量超过6G"
description: "主机内存使用量超标了"
测试
ps -ef|grep node_exporter
kill -9 进程号
prometheus页面显示

邮件接收
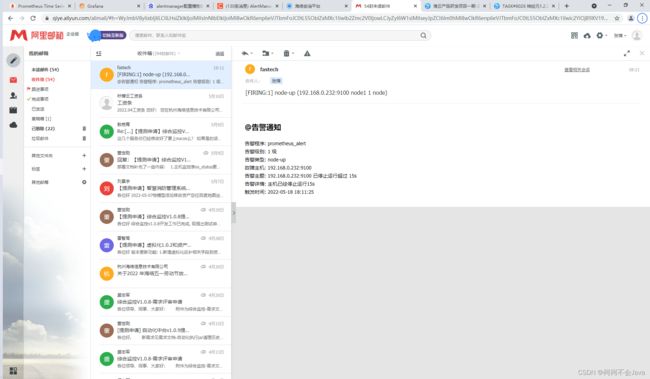
ps:还可以集成其他第三方服务,比如Slack、企业微信、钉钉,具体文档可参考:https://www.prometheus.wang/alert/alert-manager-use-receiver.html
对比现在的投递服务
可以想现在投递服务一样配置抑制时间,在alertmanager.yml中配置
global:
# 经过此时间后,如果尚未更新告警,则将告警声明为已恢复。(即prometheus没有向alertmanager发送告警了),默认为5分钟
[ resolve_timeout: > | default = 5m ]
不推荐配置时间太短,不然alertmanager服务会报错,太频繁的发送邮件

ps:没有和现在投递服务抑制次数作用相同的配置。
Prometheus监控SpringBoot项目
依赖的maven包
其实我们市面上的springboot项目基本都是基于此actutor做监控的。或者是直接用或者是代理一层做的,所以说prometheus的监控也是通过此包进行的,所以说上边我们不仅要导入actuator这个包还要导入prometheus的包,因为prometheus是对actuator进行一层代理。至于这里的第三个包micrometer-jvm-extrs其实要不要都不要紧,第三个包主要用来监控jvm的。
本项目使用的是spring boot2.6.7,依赖导入如下
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-actuatorartifactId>
dependency>
<dependency>
<groupId>io.micrometergroupId>
<artifactId>micrometer-registry-prometheusartifactId>
dependency>
<dependency>
<groupId>io.github.mweirauchgroupId>
<artifactId>micrometer-jvm-extrasartifactId>
<version>0.2.0version>
dependency>
如果是比较低的spring boot版本,如1.5.22.RELEASE(官方是使用这个版本),依赖导入如下
<dependency>
<groupId>io.prometheusgroupId>
<artifactId>simpleclientartifactId>
<version>0.15.1-SNAPSHOTversion>
dependency>
<dependency>
<groupId>io.prometheusgroupId>
<artifactId>simpleclient_commonartifactId>
<version>0.15.1-SNAPSHOTversion>
dependency>
<dependency>
<groupId>io.prometheusgroupId>
<artifactId>simpleclient_spring_webartifactId>
<version>0.15.1-SNAPSHOTversion>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-actuatorartifactId>
<version>1.5.22.RELEASEversion>
dependency>
配置文件
#management.endpoints.web.exposure.include=*
#management.endpoint.health.show-details=always
#management.health.defaults.enabled=false
#info.app.name=actuator-test-demo
#info.app.encoding=UTF-8
#info.app.java.source=1.8
#info.app.java.target=1.8
#management.endpoint.shutdown.enabled=true
server.port=8081
spring.application.name=springboot
management.endpoint.metrics.enabled=true
## 暴露所有的actuator endpoints
management.endpoints.web.exposure.include=*
management.endpoint.prometheus.enabled=true
management.metrics.export.prometheus.enabled=true
## Grafana上的应用名字
management.metrics.tags.application=springboot
部署访问
prometheus添加配置并重启
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["192.168.0.231:9090"]
- job_name: 'node232'
static_configs:
- targets: ['192.168.0.232:9100']
- job_name: 'springboot'
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['192.168.0.231:8081']
访问
Java集成Prometheus获取Prometheus监控的数据
方式1、通过Prometheus启动后,官方提供的http接口(推荐使用)
http://192.168.0.231:9090/metrics,可以通过这个接口返回promethus监控的全部数据。

获取Prometheus监控的单个指标(以获取监控节点的内存使用情况为例)
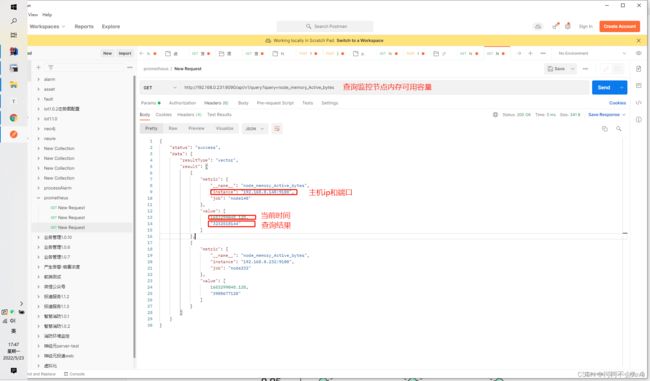
可以看到,通过prometheus提供的http接口,可以清楚的读取Prometheus监控的数据。
集成Java的demo测试样例编写
@Resource
RestTemplate restTemplate;
@Test
public void testTecentApi() {
JSONObject jsonObject = restTemplate.getForObject("http://192.168.0.231:9090/api/v1/query?query=node_memory_Active_bytes", JSONObject.class);
System.out.println(jsonObject);
}
测试运行结果
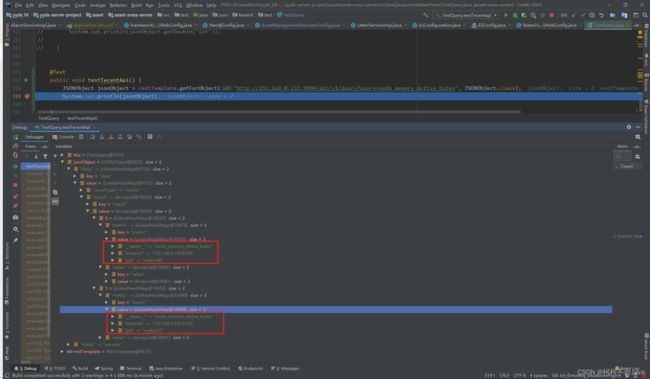
方式2、通过Prometheus的数据存储,直接读取Prometheus的数据库
Prometheus的数据存储
Prometheus的存储结构-TSDB是参考了Facebook的Gorilla之后,自行实现的。
下面是一个非常典型的监控曲线。

可以观察到,监控数据都是由一个一个数据点组成,所以可以用下面的结构来保存最基本的存储单元
type sample struct {
t int64
v float64
}
同时我们还需要注意到的信息是,我们需要知道这些点属于什么机器的哪种监控。这种信息在Promtheus中就用Label(标签来表示)。一个监控项一般会有多个Label(例如图中),所以一般用labels []Label。
由于在我们的习惯中,并不关心单独的点,而是要关心这段时间内的曲线情况。所以自然而然的,我们存储结构肯定逻辑上是这个样子:

这样,我们就可以很容易的通过一个Labels(标签们)找到对应的数据了。
监控数据在内存中的表示形式
将最近的数据保存在内存中,这样查询最近的数据会变得非常快,然后通过一个compactor定时将数据打包到磁盘。数据在内存中最少保留2个小时。压缩率在2小时时候达到最高,如果保留的时间更短,就无法最大化的压缩。
内存序列(memSeries),具体的数据结构
type memSeries stuct {
......
ref uint64 // 其id
lst labels.Labels // 对应的标签集合
chunks []*memChunk // 数据集合
headChunk *memChunk // 正在被写入的chunk
......
}
其中memChunk是真正保存数据的内存块,将在后面讲到。我们先来观察下memSeries在内存中的组织。
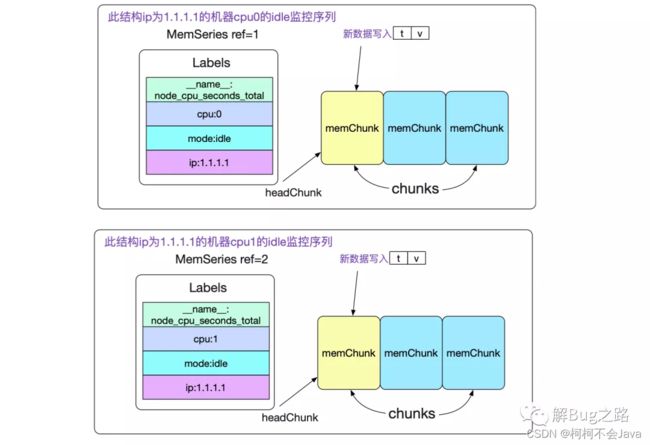
由此我们可以看到,针对一个最终端的监控项(包含抓取的所有标签,以及新添加的标签,例如ip),我们都在内存有一个memSeries结构。
Prometheus内存中的数据写入磁盘
先看下Prometheus服务器的数据目录的目录结构如下所示:
./data
├── 01BKGV7JBM69T2G1BGBGM6KB12(block)
│ └── meta.json
├── 01BKGTZQ1SYQJTR4PB43C8PD98(block) // 默认分组成 2 小时的块存储,初始经过压缩持久化存储为1个目录
│ ├── chunks // chunks 目录中的样本默认组合成一个或多个段文件
│ │ └── 000001 // 每个段文件最大为 512MB
│ │ └── 000002
│ ├── tombstones // 删除记录存储在单独的 tombstone 文件中(而不是立即从块段中删除数据)
│ ├── index // 索引文件
│ └── meta.json // 元数据文件,标明存储目录的起止时间和包含的存储块
├── 01BKGTZQ1HHWHV8FBJXW1Y3W0K(block)
│ └── meta.json
├── 01BKGV7JC0RY8A6MACW02A2PJD(block) // 最终在后台会被压缩成更长的块,包含最多保留时间的10%或31天(以较小者为准)的数据
│ ├── chunks
│ │ └── 000001
│ │ └── 000002
│ ├── tombstones
│ ├── index
│ └── meta.json // 记录chunks(段文件目录)里的内容来自多少个存储块(包含多少个2小时块)
├── chunks_head
│ └── 000001
└── wal // 最新的2小时存储在内存和预写文件wal中,重启可通过wal恢复到内存
├── 000000002 // 每128M为一段,wal目录至少包含3个段文件,甚至更多
└── checkpoint.00000001
└── 00000000
一个Block就是一个独立的小型数据库,其保存了一段时间内所有查询所用到的信息。包括标签/索引/符号表数据等等。Block的实质就是将一段时间里的内存数据组织成文件形式保存下来。最近的Block一般是存储了2小时的数据,而较为久远的Block则会通过compactor进行合并,一个Block可能存储了若干小时的信息。可以通过检查meta.json来得到当前Block的一些元信息。
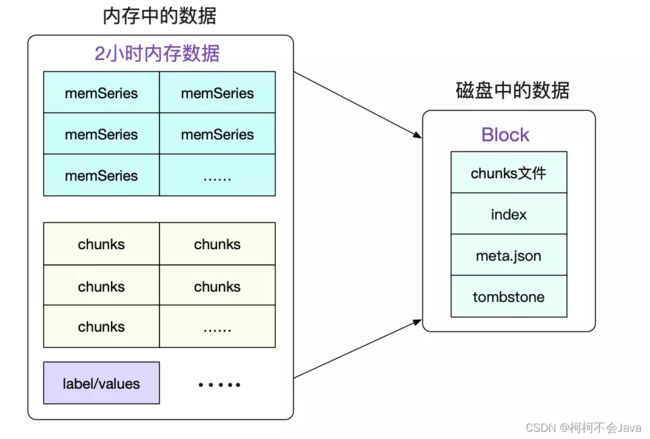
最近的Block一般是存储了2小时的数据,而较为久远的Block则会通过compactor进行合并,一个Block可能存储了若干小时的信息。
Chunks结构
CUT文件切分
所有的Chunk文件在磁盘上都不会大于512M,对应的源码为:
func (w *Writer) WriteChunks(chks ...Meta) error {
......
for i, chk := range chks {
cutNewBatch := (i != 0) && (batchSize+SegmentHeaderSize > w.segmentSize)
......
if cutNewBatch {
......
}
......
}
}
当写入磁盘单个文件超过512M的时候,就会自动切分一个新的文件。
一个Chunks文件包含了非常多的内存Chunk结构,如下图所示:
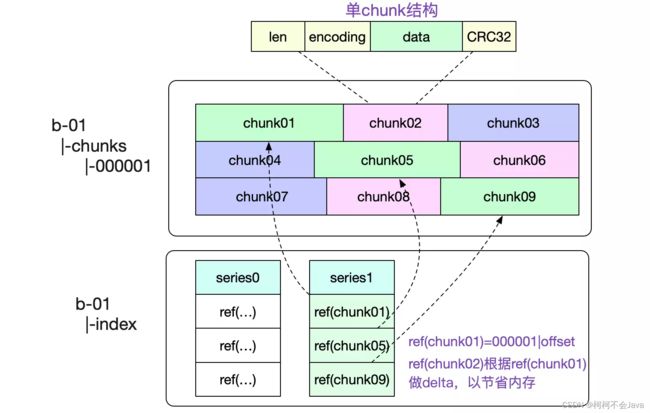
图中也标出了,我们是怎么寻找对应Chunk的。通过将文件名(000001,前32位)以及(offset,后32位)编码到一个int类型的refId中,使得我们可以轻松的通过这个id获取到对应的chunk数据。
chunks文件通过mmap去访问
由于chunks文件大小基本固定(最大512M),所以我们很容易的可以通过mmap(一种内存映射文件的方法)去访问对应的数据。直接将对应文件的读操作交给操作系统,既省心又省力。对应代码为:
func NewDirReader(dir string, pool chunkenc.Pool) (*Reader, error) {
......
for _, fn := range files {
f, err := fileutil.OpenMmapFile(fn)
......
}
......
bs = append(bs, realByteSlice(f.Bytes()))
}
通过sgmBytes := s.bs[offset]就直接能获取对应的数据

Prometheus时序数据库-数据的查询
Prometheus提供了强大的Promql来满足我们千变万化的查询需求。以一个简单的Promql为例,讲述下Prometheus查询的过程。
拥有系列三个label
http_requests{job="api-server",instance="0"}
且时间为start/end的所有序列数据
这里以查询的数据存在磁盘数据库Block里为例,我们先从选择Block开始,遍历所有Block的meta.json,找到具体的Block

prometheus通过Labels找数据是通过倒排索引。我们的倒排索引是保存在index文件里面的。 那么怎么在这个单一文件里找到倒排索引的位置呢?这就引入了TOC(Table Of Content)
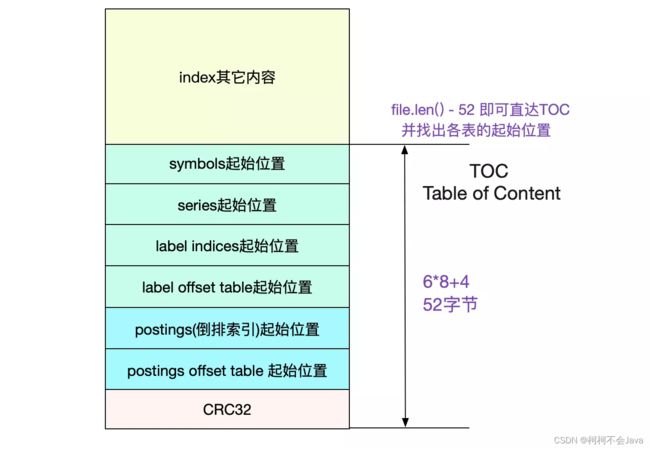
由于index文件一旦形成之后就不再会改变,所以Prometheus也依旧使用mmap来进行操作。采用mmap读取TOC非常容易:
func NewTOCFromByteSlice(bs ByteSlice) (*TOC, error) {
......
// indexTOCLen = 6*8+4 = 52
b := bs.Range(bs.Len()-indexTOCLen, bs.Len())
......
return &TOC{
Symbols: d.Be64(),
Series: d.Be64(),
LabelIndices: d.Be64(),
LabelIndicesTable: d.Be64(),
Postings: d.Be64(),
PostingsTable: d.Be64(),
}, nil
}
Posting offset table 以及 Posting倒排索引
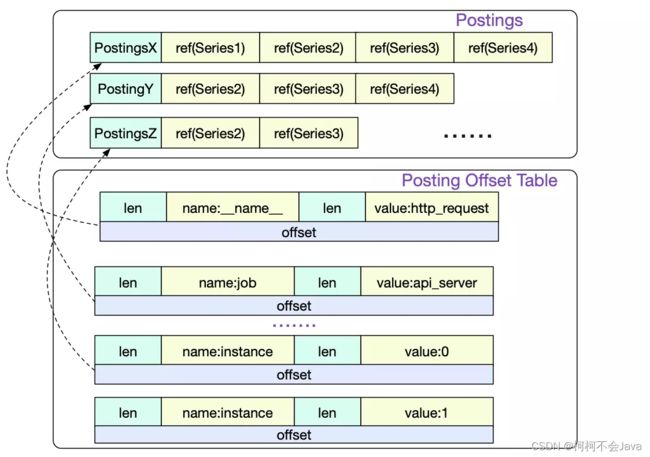
首先我们访问的是Posting offset table。由于倒排索引按照不同的LabelPair(key/value)会有非常多的条目。所以Posing offset table就是决定到底访问哪一条Posting索引。offset就是指的这一Posting条目在文件中的偏移。
Series
我们通过三条Postings倒排索引索引取交集得出
{series1,Series2,Series3,Series4}
∩
{series1,Series2,Series3}
∩
{Series2,Series3}
=
{Series2,Series3}
也就是要读取Series2和Serie3中的数据,而Posting中的Ref(Series2)和Ref(Series3)即为这两Series在index文件中的偏移。
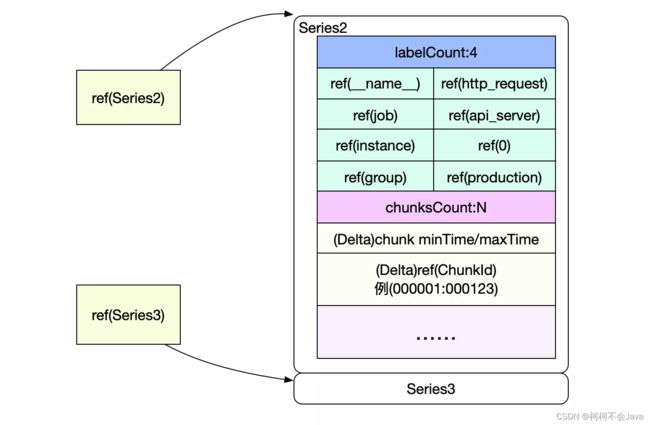
Series以Delta的形式记录了chunkId以及该chunk包含的时间范围。这样就可以很容易过滤出我们需要的chunk,然后再按照chunk文件的访问,即可找到最终的原始数据。
方式3、Prometheus的远程存储,将Prometheus监控数据导入kafka中间件
Prometheus-kafka-adapter
Prometheus-kafka-adapter 是一项服务,它通过 接收Prometheus指标remote_write,编组为 JSON 并将它们发送到Kafka。
操作步骤
telefonica/prometheus-kafka-adapter:1.8.0 Docker Hub上有一个可用的 docker 映像。
镜像地址
https://hub.docker.com/r/telefonica/prometheus-kafka-adapter/
拉取镜像
docker pull telefonica/prometheus-kafka-adapter:1.8.0
运行镜像
docker run -d --name prometheus-kafka-adapter-01 --restart=always -m 2g -e KAFKA_BROKER_LIST=192.168.0.221:9092,192.168.0.222:9092,192.168.0.223:9092 -e KAFKA_TOPIC=prometheus-metric -e PORT=10403 -e SERIALIZATION_FORMAT=json -e GIN_MODE=release -e LOG_LEVEL=debug -p 10403:10403 telefonica/prometheus-kafka-adapter:1.8.0
参数解释
Prometheus-kafka-adapter 监听来自 Prometheus 的指标并将它们发送到 Kafka。可以使用以下环境变量配置此行为:
KAFKA_BROKER_LIST: 定义 kafka 端点和端口,默认为kafka:9092.KAFKA_TOPIC: 定义要使用的 kafka 主题,默认为metrics.KAFKA_COMPRESSION: 定义要使用的压缩类型,默认为none.KAFKA_BATCH_NUM_MESSAGES: 定义要批量写入的消息数量,默认为10000.SERIALIZATION_FORMAT: 定义序列化格式,可以是json,avro-json, 默认为json.PORT: 定义要监听的 http 端口,默认为8080,由gin直接使用。BASIC_AUTH_USERNAME: 用于接收端点的基本身份验证用户名,默认为无基本身份验证。BASIC_AUTH_PASSWORD: 用于接收端点的基本身份验证密码,默认为无基本身份验证。LOG_LEVEL: 定义日志级别logrus,可以是debug,info,warn,error,fatal或panic, 默认为info.GIN_MODE: 管理gin调试日志,可以是debug或release.
要通过 SSL 连接到 Kafka,请定义以下附加环境变量:
KAFKA_SSL_CLIENT_CERT_FILE: Kafka SSL 客户端证书文件,默认为""KAFKA_SSL_CLIENT_KEY_FILE: Kafka SSL 客户端证书密钥文件,默认为""KAFKA_SSL_CLIENT_KEY_PASS: Kafka SSL 客户端证书密钥密码(可选),默认为""KAFKA_SSL_CA_CERT_FILE: Kafka SSL broker CA 证书文件,默认为""
要通过 SASL/SCRAM 身份验证连接到 Kafka,请定义以下附加环境变量:
KAFKA_SECURITY_PROTOCOL: Kafka 客户端使用协议与代理通信,如果要使用 SASL,则必须设置,无论是普通还是 SSLKAFKA_SASL_MECHANISM: 用于身份验证的 SASL 机制,默认为""KAFKA_SASL_USERNAME: 用于 PLAIN 和 SASL-SCRAM-… 机制的 SASL 用户名,默认为""KAFKA_SASL_PASSWORD: 用于 PLAIN 和 SASL-SCRAM-… 机制的 SASL 密码,默认为""
停止运行的镜像
docker stop prometheus-kafka-adapter-01
删除镜像
docker rm prometheus-kafka-adapter-01
普罗米修斯
Prometheus 需要remote_write配置一个 url,指向运行 prometheus-kafka-adapter 服务的主机和端口的“/receive”端点。例如:
remote_write:
- url: "http://prometheus-kafka-adapter:8080/receive"
相关问题
如何配置发送到kafka的频率?
发送到kafka的频率和prometheus抓取数据的频率是一致的,具体配置如下:
全局配置,默认是一分钟
global:
scrape_interval: 15s
单个监控的节点配置,不配置默认使用全局配置
scrape_configs:
- job_name: 'node232'
scrape_interval: 15s
static_configs:
- targets: ['192.168.0.232:9100']
如何配置prometheus监控的哪些我们想要的数据发送到kafka?
例一:配置标签名以go开头的标签不发送到kafka
remote_write:
- url: "http://192.168.0.231:10403/receive"
write_relabel_configs:
- source_labels: [__name__]
regex: go.*
action: drop
例二:配置标签名以process开头的标签才发送到kafka
remote_write:
- url: "http://192.168.0.231:10403/receive"
write_relabel_configs:
- source_labels: [__name__]
regex: process.*
action: keep
结果

也可以通过上方Prometheus配置的拉取指标配置 metric_relabel_configs来实现,不拉取不想要的指标,即不会将这些指标发送到kafak
kafka单个topic数据查看
./kafka-console-consumer.sh --bootstrap-server 192.168.0.221:9092,192.168.0.222:9092,192.168.0.223:9092 --topic prometheus-metric --from-beginning
总结
1、使用Prometheus的http接口获取其监控的数据,推荐使用,每一个监控指标都有一个接口获取其监控的数据。
2、Prometheus底层是用go语言编写,如果想要模仿go语言的实现逻辑书写一套Java读取Prometheus数据库的操作,成本太高,不建议使用。
3、使用Prometheus集成kafka的操作能大大降低其性能损耗,是目前最优的方式。