大数据技术之Spark(四)——RDD依赖关系
前言
我们之前在maven中使用过的依赖,即在创建项目的时候需要用到哪些其他的项目,或者第三方的模块/类库,我们需要依赖于它,这就是依赖关系。
在spark中,如果A用到了B,我们就称A依赖于B,B用到了C,那么B依赖于C。此时,A和C的关系称为间接依赖(maven框架),在spark中我们称这种关系为血缘。
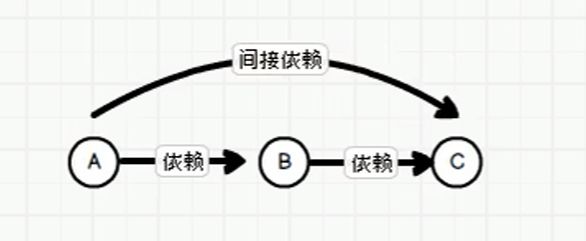
同样的,如果RDD1依赖于RDD2,RDD2依赖于RDD3,
如:val rdd1 = rdd.map(_*2)
那么我们称呼相邻的两个RDD的关系为依赖关系。
多个连续的RDD的依赖关系,称之为血缘关系。
每个RDD会保存血缘关系。

一、血缘关系与依赖关系
由于RDD只支持粗粒度转换,即在大量记录上执行的单个操作。RDD是不会保存数据的(不保存数据是指数据不会落盘,直接内存传递),但是为了提高容错性,RDD会将创建 RDD 的一系列 Lineage (血统)(即RDD间的关系)记录下来,以便恢复丢失的分区。一旦出现错误,它可以根据血缘关系将数据源重新读取来重新运算,并恢复丢失的数据分区。
每个RDD都能保存依赖关系。
查看血缘关系: toDebugString
object RDD_Dep {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("BroadCast").setMaster("local[*]")
val sc = new SparkContext(conf)
val fileRDD = sc.textFile("in/test.log")
println(fileRDD.toDebugString)
println("----------------------")
val wordRDD = fileRDD.flatMap(_.split(" "))
println(wordRDD.toDebugString)
println("----------------------")
val mapRDD = wordRDD.map((_,1))
println(mapRDD.toDebugString)
println("----------------------")
val resultRDD = mapRDD.reduceByKey(_+_)
println(resultRDD.toDebugString)
resultRDD.collect()
println("----------------------")
val map2RDD = resultRDD.map((_,"a"))
println(map2RDD.toDebugString)
map2RDD.collect()
}
}

步骤:
1. 走完textFile之后,已经把血缘关系列出来了。
2. 当走到flatMap的时候,会在原来的textFile的基础上加上了flatMap
3. reduceByKey操作的时候,连接断开了,中间存在shuffle操作(表示为+-符号)
二、RDD窄依赖与宽依赖
2.1 区别
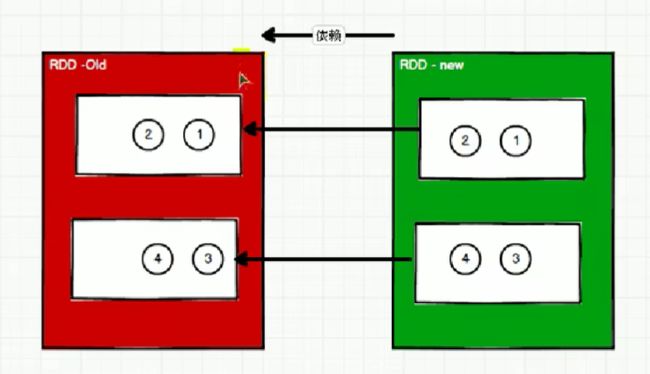
新的RDD的一个分区的数据依赖于旧的RDD一个分区的数据。这个依赖称之为OneToOne依赖,也叫窄依赖。
窄依赖我们形象的比喻为独生子女。class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd)
新的RDD的一个分区的数据依赖于旧的RDD多个分区的数据。这个依赖称之为Shuffle依赖,也叫宽依赖。
宽依赖我们形象的比喻为多生。
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag]( @transient private val _rdd: RDD[_ <: Product2[K, V]], val partitioner: Partitioner, val serializer: Serializer = SparkEnv.get.serializer, val keyOrdering: Option[Ordering[K]] = None, val aggregator: Option[Aggregator[K, V, C]] = None, val mapSideCombine: Boolean = false) extends Dependency[Product2[K, V]]

2.2 作用
划分 Stage。Stage 之间做 shuffle,Stage 之内做 pipeline(流水线)。方便stage内优化。
相比宽依赖,窄依赖对优化很有利:
(1)数据的容错性:
假如某个节点出故障了:
窄依赖:只要重算和子RDD分区对应的父RDD分区即可;
宽依赖:极端情况下,所有的父RDD分区都要进行重新计算。
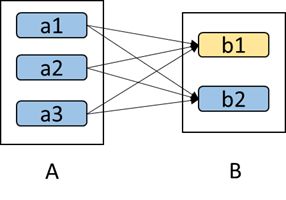
如下图所示,b1分区丢失,则需要重新计算a1,a2和a3,这就产生了冗余计算(a1,a2,a3中对应b2的数据)。
(2)传输
宽依赖往往对应着shuffle操作,需要在运行过程中将同一个父RDD的分区传入到不同的子RDD分区中,中间可能涉及多个节点之间的数据传输;
窄依赖的每个父RDD的分区只会传入到一个子RDD分区中,通常可以在一个节点内完成转换。
三、RDD阶段划分与任务划分
3.1 概念
RDD转换算子从分区数据是否会重新组合的角度看可分为两类:
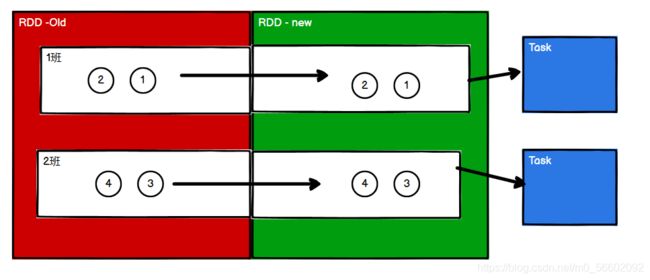
一类是如map、mapPartitions等,一个分区的数据经过处理后仍然还在同一个分区。各个分区的数据不存在互相依赖的关系,即OneToOne依赖,因此各个分区在处理完自己的任务后就可以直接通过转换算子进入新的RDD,不需要谁等谁。
而另一类转换算子如groupBy、reduceByKey等,分区数据需要重新组合(即存在shuffle操作)。各个分区的数据存在互相依赖的关系,即Shuffle依赖(宽依赖),需要进行这类转换算子操作时,一个分区处理完任务后不能立即进行转换,需要等待所有分区都准备好后,再一起转换进入下一个阶段,这里就有了阶段划分的概念。
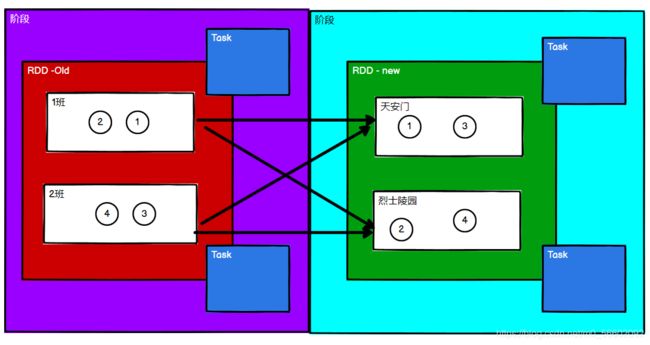
3.2 RDD任务划分
RDD 任务切分中间分为:Application、Job、Stage 和 Task。
Application:初始化一个 SparkContext 即生成一个 Application;
Job:一个 Action 算子就会生成一个 Job;
Stage:Stage 等于宽依赖(ShuffleDependency)的个数加 1;阶段的数量 = shuffle依赖的数量 + 1
ResultStage只有一个,最后需要执行的阶段。
Task:一个 Stage 阶段中,最后一个 RDD 的分区个数就是 Task 的个数。
任务的数量 = 当前阶段中最后一个RDD的分区数量


注意:Application -> Job -> Stage -> Task 每一层都是1对n的关系