自话粒子群算法(超简单实例)
简介
上次在自话遗传算法中提到后期会写两篇关于粒子群算法和蚁群算法的博文,所以这次给大家带来的是我对粒子群的一些理解,并附带一个相当简单的实例去描述这个算法,我会尽力通俗易懂的把整个算法描述一遍,其实粒子群算法的思想也挺简单的,希望我不要反而写复杂了,下面同样引用百度百科的摘要结束简介部分。
粒子群优化算法(PSO)是一种进化计算技术(evolutionary computation),1995 年由Eberhart 博士和kennedy 博士提出,源于对鸟群捕食的行为研究 。该算法最初是受到飞鸟集群活动的规律性启发,进而利用群体智能建立的一个简化模型。粒子群算法在对动物集群活动行为观察基础上,利用群体中的个体对信息的共享使整个群体的运动在问题求解空间中产生从无序到有序的演化过程,从而获得最优解。
基本思想
正如简介所描述的那样,粒子群算法是模拟群体智能所建立起来的一种优化算法,像后面我向大家介绍的蚁群算法也属于这类算法,粒子群算法可以用鸟类在一个空间内随机觅食为例,所有的鸟都不知道食物具体在哪里,但是他们知道大概距离多远,最简单有效的方法就是搜寻目前离食物最近的鸟的周围区域。
所以,粒子群算法就是把鸟看成一个个粒子,并且他们拥有位置和速度这两个属性,然后根据自身已经找到的离食物最近的解和参考整个共享于整个集群中找到的最近的解去改变自己的飞行方向,最后我们会发现,整个集群大致向同一个地方聚集。而这个地方是离食物最近的区域,条件好的话就会找到食物。这就是粒子群算法,很好理解。
算法描述
所以,我们需要一个pbest来记录个体搜索到的最优解,用gbest来记录整个群体在一次迭代中搜索到的最优解。速度和粒子位置的更新公式如下:
v[i] = w * v[i] + c1 * rand() * (pbest[i] - present[i]) + c2 * rand() * (gbest - present[i])
present[i] = present[i] + v[i]
其中v[i]代表第i个粒子的速度,w代表惯性权值,c1和c2表示学习参数,rand()表示在0-1之间的随机数,pbest[i]代表第i个粒子搜索到的最优值,gbest代表整个集群搜索到的最优值,present[i]代表第i个粒子的当前位置。
我这里打了一个求解y=-x*(x-1) 在[-2,2]上最大值的粒子群算法,选用这个简单的例子主要是能让大家清楚的看到效果和粒子的运动方向,也方便理解我想说的一些观点。代码如下:


1 /*** 2 * 计算y=-x(x-1)的最大值 3 * 取值范围x--[-2,2] 4 * @author BreezeDust 5 * 6 */ 7 public class PSOTest { 8 int n=2; //粒子个数,这里为了方便演示,我们只取两个,观察其运动方向 9 double[] y; 10 double[] x; 11 double[] v; 12 double c1=2; 13 double c2=2; 14 double pbest[]; 15 double gbest; 16 double vmax=0.1; 17 public void fitnessFunction(){//适应函数 18 for(int i=0;i<n;i++){ 19 y[i]=-1*x[i]*(x[i]-2); 20 } 21 } 22 public void init(){ //初始化 23 x=new double[n]; 24 v=new double[n]; 25 y=new double[n]; 26 pbest=new double[n]; 27 /*** 28 * 本来是应该随机产生的,为了方便演示,我这里手动随机落两个点,分别落在最大值两边 29 */ 30 x[0]=-0.5; 31 x[1]=2.6; 32 v[0]=0.01; 33 v[1]=0.02; 34 fitnessFunction(); 35 //初始化当前个体极值,并找到群体极值 36 for(int i=0;i<n;i++){ 37 pbest[i]=y[i]; 38 if(y[i]>gbest) gbest=y[i]; 39 } 40 System.out.println("start gbest:"+gbest); 41 } 42 public double getMAX(double a,double b){ 43 return a>b?a:b; 44 } 45 //粒子群算法 46 public void PSO(int max){ 47 for(int i=0;i<max;i++){ 48 double w=0.4; 49 for(int j=0;j<n;j++){ 50 //更新位置和速度 51 v[j]=w*v[j]+c1*Math.random()*(pbest[j]-x[j])+c2*Math.random()*(gbest-x[j]); 52 if(v[j]>vmax) v[j]=vmax; 53 x[j]+=v[j]; 54 //越界判断 55 if(x[j]>2) x[j]=2; 56 if(x[j]<-2) x[j]=-2; 57 58 } 59 fitnessFunction(); 60 //更新个体极值和群体极值 61 for(int j=0;j<n;j++){ 62 pbest[j]=getMAX(y[j],pbest[j]); 63 if(pbest[j]>gbest) gbest=pbest[j]; 64 System.out.println(x[j]+" "+v[j]); 65 } 66 System.out.println("======"+(i+1)+"======gbest:"+gbest); 67 } 68 69 70 } 71 public static void main(String[] args){ 72 PSOTest ts=new PSOTest(); 73 ts.init(); 74 ts.PSO(100); 75 } 76 77 78 79 }
输出结果如下:
1 start gbest:0.0
2 -0.4 0.1
3 0.0 -10.751668729351186
4 ======1======gbest:0.0
5 -0.6822365786740794 -0.2822365786740793
6 0.0 -5.375834364675593
7 ======2======gbest:0.0
8 -0.5822365786740794 0.1
9 0.0 -2.6879171823377965
10 ======3======gbest:0.0
11 -0.48223657867407943 0.1
12 -1.3439585911688983 -1.3439585911688983
13 ======4======gbest:0.0
14 -0.38223657867407945 0.1
15 -1.2439585911688982 0.1
16 ======5======gbest:0.0
17 -0.47659030560462123 -0.09435372693054181
18 -1.143958591168898 0.1
19 ======6======gbest:0.0
20 -0.37659030560462126 0.1
21 -1.043958591168898 0.1
22 ======7======gbest:0.0
23 -0.2765903056046213 0.1
24 -0.943958591168898 0.1
25 ======8======gbest:0.0
26 -0.27903394174424034 -0.0024436361396190653
27 -0.843958591168898 0.1
28 ======9======gbest:0.0
29 -0.38899022876058803 -0.10995628701634769
30 -0.7439585911688981 0.1
31 ======10======gbest:0.0
32 -0.35250959144436234 0.03648063731622572
33 -0.6439585911688981 0.1
34 ======11======gbest:0.0
35 ........ 36 ........ 37 ........ 38 ........ 39 0.9999990975760489 -1.556071309835406E-6
40 ======98======gbest:1.0
41 1.0000000029937202 4.411275849326098E-9
42 1.0000001827158205 1.085139771533034E-6
43 ======99======gbest:1.0
44 0.9999999993730952 -3.6206249540206964E-9
45 1.0000001197322141 -6.298360633295484E-8
46 ======100======gbest:1.0
我们可以从打印的数据看出来,刚开始x[0]和x[1]分散在最大值两边,然后x[0]和x[1]逐渐聚集到1的周围,这里,我们已经收敛到x=1这个地方了,这正是我们要求的最大值,其最大值为1,下面是图解过程。
1.初始状态
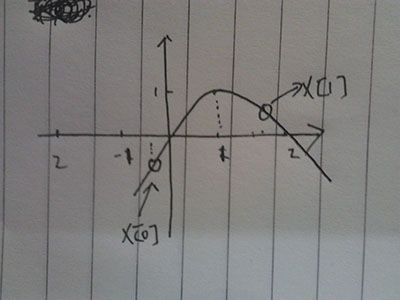
2.第二次x[1]向左边移动了
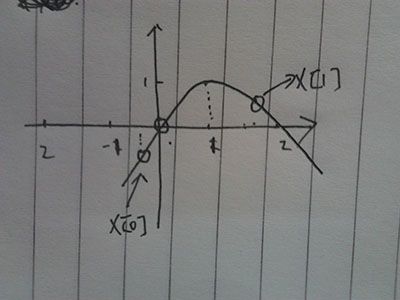
3.最后,两点聚集在1上,上面多个圈是他们聚集的过程,可以看出来,聚集过程是个越来越密集的过程。
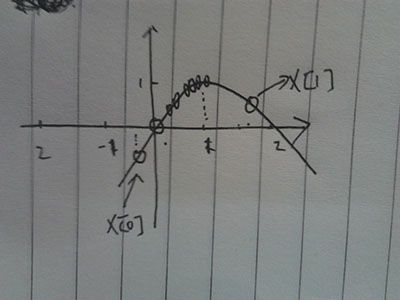
最后
粒子群算法,相对于我上次提到的遗传算法而言编码要简单很多,同样属于进化算法,但是粒子群算法并没有像遗传算法那样有选择交叉变异这样的过程,而更多的是体现在追踪单个粒子和共享集体最优信息来实现向最优空间搜索的形式,但是正由于它不同于遗传算法那样去忽略个体的一些内在联系,所以往往会陷入局部最优,所以,在粒子群算法中加入像遗传算法中的变异或者模拟退火等,可以跳过这个局部最优解。
而惯性权值对于函数收敛速度和是否收敛有很大的决定作用,两个学习参数c1,c2的制定也同等重要,但是即使这样,它也没有遗传算法中会有多个参数去维护,所以整个算法就那一个公式就行了,相当的清晰。在遗传算法中的信息的共享是染色体互相之间通过交叉共享,所以在搜索移动过程显得平均缓慢,而粒子群算法是根据gbest来决定整个集群的单向移动,所以相对遗传算法,它更快的收敛。
这不由得让我想到了熵这个概念,在诸如我们社会甚至宇宙这样复杂的系统,我们都处于一个无序的状态,属于熵增状态,像粒子群,遗传算法,对群体的研究,体现的智能不就是在这个无序的系统提供有序的能量,然后它就逐渐有序了。对于智能,我想我有更深的体会了。这段话属于发神经,不作参考。
注:本博文版权属BreezeDust所有
欢迎转载,转载请注明:http://www.cnblogs.com/BreezeDust/p/3354769.html