【论文笔记 · RL】Toward A Thousand Lights Decentralized Deep Reinforcement Learning for Large-Scale TSC...
Toward A Thousand Lights Decentralized Deep Reinforcement Learning for Large-Scale Traffic Signal Control
文章目录
- Toward A Thousand Lights Decentralized Deep Reinforcement Learning for Large-Scale Traffic Signal Control
-
- 摘要
- 介绍
-
- 传统交通信号控制方法
- 已有强化学习交通信号控制方法及本文方法
-
- **当前已有强化学习的交通信号控制方法**
- 本文方法
- 文章贡献
- 前提
-
- 定义
-
- **交通移动(Traffic Movement)**
- **信号相位(Signal Phase)**
- **信号相位压力(Pressure of Signal Phase)**
- 问题
-
- **多交叉路口交通信号控制(Multi-intersection traffic signal control)**
- 方法
-
- 基于压力的协同机制(Pressure-based Coordination)
- DQN Agent
-
- FRAP Base Model
- Deep Q-learning
- 参数共享
- 实验
-
- 设置
-
- 数据集
- 对比方法
- 评价指标
- 性能比较
- 扩展性分析
- 消融实验
-
- 压力设计的作用与影响
- 共享参数的作用与影响
摘要
强化学习已在交通信号控制上取得了长足进步,但是针对大规模城市网络中的控制和协调正遇挑战。
文章贡献:
- 利用“压力”概念设计了agent,来实现区域层级的信号协同;
- 通过精心设计的奖励,个体控制agent可以实现协调,从而降低维数;
- 在多场景下进行了广泛实验,包括在纽约曼哈顿2510个红绿灯的现实场景。
介绍
传统交通信号控制方法
传统交通信号控制可分为:
- Pretimed control (Koonce and Rodegerdts 2008)
- Actuated control (Cools, Gershenson, and D’Hooghe 2013)
- Adaptive control (Lowrie 1990; Hunt et al. 1981)
- Optimization based control (Varaiya 2013)
以上方法都强依赖于一个给定的交通模型或者基于专家知识预定义的规则,难以适应动态交通。
已有强化学习交通信号控制方法及本文方法
文章提出了一种强化学习交通信号控制方法,来控制城市级别的信号协调。该方法使用交通状况作为输入,学习如何为每个路口决定下一阶段。有三个要素需要解决:
- **可扩展性:**所提出的方法需要能够进行大规模有效协同,并且实现全局最优;
- **协同:**交通信号需要实现协同,不能实现协同会出现一个点的交通状况恶化导致另一个点的状况恶化的情况;
- **数据可行性:**方法所使用的数据必须是现实可获得的。
当前已有强化学习的交通信号控制方法
- El-Tantawy and Abdulhai 2012; Van der Pol and Oliehoek 2016; Nishi et al. 2018:无法满足上述三要素;
- Prashanth and Bhatna-gar 2011; Kuyer et al. 2008; Van der Pol and Oliehoek 2016:不满足可扩展性,因为动作空间过大;
- 分布式RL方法能够处理大规模网络,但是难以将全局奖励函数分配到各交叉口进行协调。
- Nishi et al. 2018; El-Tantawy and Abdulhai 2012; V an der Pol and Oliehoek 2016:采用常见运输度量作为奖励函数,如平均等待时间(Nishi et al. 2018)、延迟(El-Tantawy and Abdulhai 2012; V an der Pol and Oliehoek 2016)等,但不能保证每个agent能最大化自己的期望来优化总体目标;
- Wei et al. 2018; Van der Pol and Oliehoek 2016:一些RL方法假设详细交通状况能够被轻易获得,但在真实世界是不现实的。
本文方法
本文提出了一个分布式强化学习模型,来解决城市规模的交通信号控制问题。
该模型采用去中心化的RL范式来实现可扩展性,同时在此基础上进一步使交叉路口间的参数共享。这里会出现两个矛盾:
- 由于不同交叉路口的不同结构和局部交通状况的不同,进行所有交叉路口的参数共享会导致较差的性能。
- 上千个agent尽管控制不同结构的不同交通流,但其本质上遵循相似的控制逻辑,所学的知识应该被共享,从而提高学习速度。
为了解决这对矛盾,文章采用了FRAP(Zheng et al. 2019a)作为基础模型。FRAP是专为相位竞争设计的,不用考虑交叉口结构和当地交通状况。
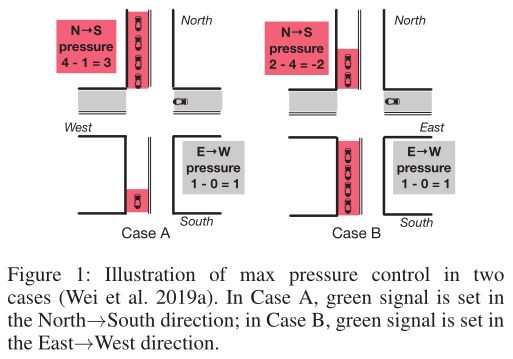
此外,为了实现协同,模型还将“压力”概念吸收进了agent,这一概念产生于Max Pressure Control Theory,目的是最大化交通领域的全局吞吐量。交叉路口的压力可以被视为上行和下行队伍的长度差,从而代表车辆分配的不平均。为了最小化压力,文章提出的agent能够平衡系统内车辆的分布,并且最大化吞吐量。
文章中还基于PressLight(Wei et al. 2019a)设计了State和Reward。而PressLight是一个简单的DQN网络。
总之,文章使用了FRAP作为基础模型,使得参数能够在不同交叉路口间共享;此外,文章采用了队列长度来使得数据可获取。
文章贡献
- 首次将智能交通信号控制算法应用于大规模交通网络(上千个信号灯);
- 提出了一种能应用于大规模交通网络的、参数共享的强化学习分布式网络。
前提
定义
交通移动(Traffic Movement)
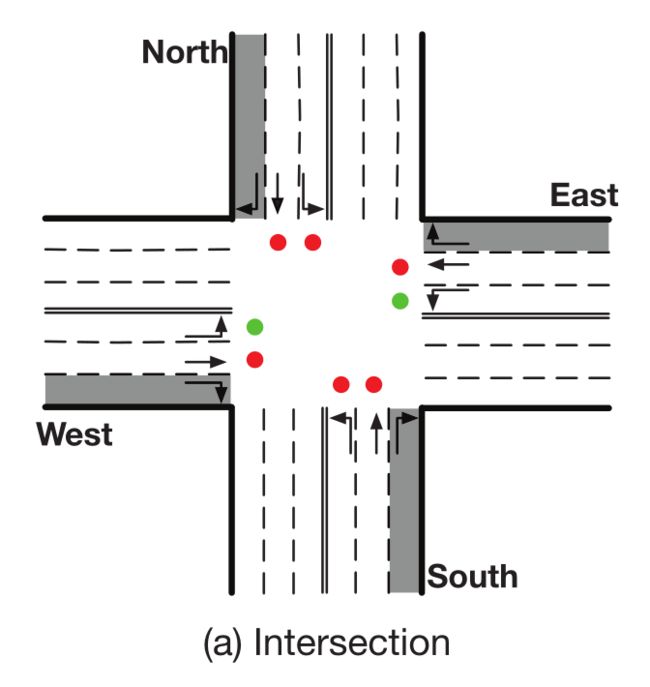
Traffic movement是车辆穿过交叉路口,从进入车道到离开车道的过程。文章中将这一过程定义为 ( l , m ) (l,m) (l,m),指从道路 l l l到道路 m m m,如上图中有12对Traffic movement。
信号相位(Signal Phase)

Signal phase s s s是一组被允许的traffic movement。如上图中,该交叉路口有8个相,目前相位2被激活,对应图a中为绿灯。 S i S_i Si代表交叉路口 i i i的所有相位。
信号相位压力(Pressure of Signal Phase)
对于每个信号相位 s s s,有允许的Traffic movement ( l , m ) (l,m) (l,m),则有 x ( l , m ) x(l,m) x(l,m)表示车道 l l l及车道 m m m的车辆数量差异,信号相位 p ( s ) p(s) p(s)是允许的相位压力的总和 ∑ ( l , m ) x ( l , m ) , ∀ ( l , m ) ∈ s \sum_{(l,m)}x(l,m),\forall(l,m)\in s ∑(l,m)x(l,m),∀(l,m)∈s。
交叉路口压力(Pressure of An Intersection)

交叉路口压力是在进入车道的车辆数量之和与离开车道的车辆数量之和的差
问题
多交叉路口交通信号控制(Multi-intersection traffic signal control)
每个交叉路口都被一个agent控制。在时间步 t t t时,agent i i i所观察到的环境为 o i t o^t_i oit。在给定交通状况和当前交通信号相位时,agent的目标就是得到一个最优Action a a a,使得Reward r r r最大化。
方法
基于压力的协同机制(Pressure-based Coordination)
为了最小化压力,agent能够平衡车辆在系统中的分布,最大化吞吐量。
根据Varaiya 2013的工作,最大压力控制被证明是稳定、最优的,能够仅利用交叉路口的局部信息稳定、最大化吞吐量。而最大压力控制的关键则是将优化目标设置为每个信号相位的压力最小。

**算法1 最大压力控制:**在交叉路口 i i i,对每个相位 s ∈ S i s\in S_i s∈Si,计算出压力 p ( s ) p(s) p(s)。最大压力控制会选择具有最大压力的相位。
在实际实现中,最大压力控制会使用贪心进行实现。故在接下来的部分,文章设计了一种利用基于压力的Reward的长期优化agent PressLight。
DQN Agent
通过将agent的Reward和最大压力控制目标相同,每个局部agent要最大化它的累计Reward,从而进一步使得网络吞吐量在一定约束下最大化。
-
**观测(Observation):**每个agent都将系统状态的一部分作为自己的观测。在一个标准的12个traffic movement的交叉路口,agent的观测包括当前相位 p p p和12个traffic movement的压力。需要注意的是,在交叉路口少于12个traffic movement时,对向量使用zero-padding。
-
**动作(Action):**在时间 t t t,各个agent选择一个相位 p p p作为它的状态 a t a_t at,在本文中,agent会从8个候选相位中进行选择。根据Wei et al. 2019a和Zheng et al. 2019a,其会比从一个子集中选择可能的动作更加有效。
-
**奖励(Reward):**本文将奖励 r i r_i ri定义为agent i i i在交叉路口的压力。文章使用 P i P_i Pi表示交叉路口 i i i的压力,则奖励 r i r_i ri为:
r i = − P i r_i=-P_i ri=−Pi
FRAP Base Model
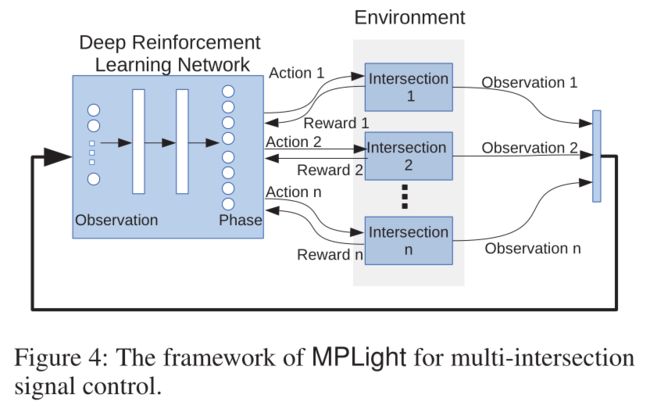
在对相位竞争关系进行建模时,FRAP有两个优点:
- 优良的performance;
- 更快的训练过程。
值得注意的是,基于压力的设计并不仅限于FRAP,其也能被整合进入其他强化学习模型中。
Deep Q-learning
文章使用了DQN来解决多交叉路口信号控制问题。DQN将traffic movement的状态特征作为输入,预测每个候选相位的分数:
Q ( s t , a t ) = R ( s t , a t ) + γ max Q ( s t + 1 , a a + 1 ) Q(s_t,a_t)=R(s_t,a_t)+\gamma \max Q(s_{t+1},a_{a+1}) Q(st,at)=R(st,at)+γmaxQ(st+1,aa+1)
参数共享
所有agent的参数都被共享,单个PressLight模型接受来自不同交叉路口的观测用于预测对应动作,并且从环境奖励中进行学习。同时,重放记忆也是共享的。
实验
设置
文章在Cityflow上进行了实验,将交通数据输入模拟器后,车辆将根据环境设置项目的地行驶。模拟器向模型提供状态,执行模型所返回的交通信号动作。
按照传统,每个绿色信号后,有3秒的黄色信号和2秒的全红色信号,以使得交叉路口通畅。
数据集
在交通流数据集中,每个车辆被描述为 ( o , t , d ) (o,t,d) (o,t,d),其中 o o o是其起始位置, t t t是时间, d d d是目的位置。
在实验中使用了合成和真实世界的数据集,这些数据集是双向、动态、具有转向的交通流。
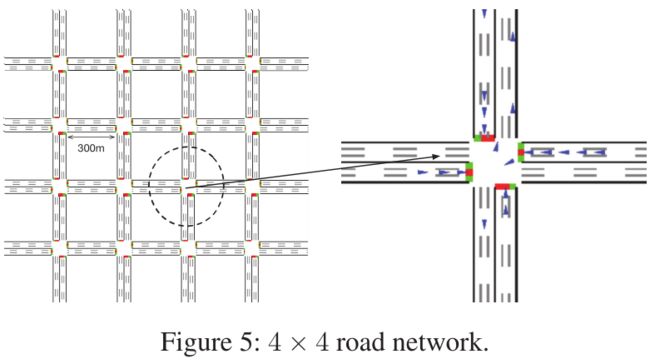
- **合成数据集:**其具有一个 4 × 4 4\times 4 4×4的路网系统,每个交叉路口都是四向路口,具有四条300米长的路段。实验使用了4种配置来在不同交通需求下测试模型,两种车辆的平均到达率,以及两种需求Flat(方差0.3),Peak(方差0.6)。根据对真实数据集的统计,将交叉路口的转弯率设置为左转10%、直行60%、右转30%。

- **真实数据集:**文章使用了纽约曼哈顿的路网系统(数据来自OpenStreetMap)输入模拟器。文章使用的数据是从开源的出租车交通流数据生成。总的交通流量按照生成的交通流数据成倍增长,因为一个出租车行程就能够被视作真实行程的分布。具体来说,1小时内,有约25156辆车。这里需要注意的是,交通不是均匀的,因为交通流数据是真实出租车数据乘以一个因子,路网也是局部的,故车辆可能从网络的任何边缘产生和消失。
对比方法
为了公平,所有强化学习方法都没有预训练过程,动作间隔被设置为10秒。
- FixedTime
- MaxPressure
- GRL
- GCN
- PressLight
- NeighborRL
- FRAP
文章提出的方法为MPLight。
评价指标
- **行驶时间(Travel Time):**在系统中的所有车辆的平均行驶时间;
- **吞吐量(Throughput):**模拟过程中,车辆完成的行程数。给定时间段内吞吐量越大,该时间段内完成行程的车辆越多,控制策略越好。
性能比较

扩展性分析

消融实验
压力设计的作用与影响

共享参数的作用与影响

上图为模型收敛的测试片段数。