二分查找(折半查找)详解
二分查找详解
- 1. 二分查找的引入
- 2. 二分的一些基本知识
-
- 1) 定义
- 2) 特点
- 3. 二分查找的边界问题
-
- 1) 常用模板
- 2)综合练习
- 4.二分的应用
-
- 1) Flyer
- 2) Distributing Ballot Boxes
- 5.二分的拓展
1. 二分查找的引入
说到二分查找相信大家都很熟悉,最经典的例子就是猜数字问题:
从1到100中,随机抽取一个数字。现在让你猜测这个数字究竟是多少,如果你猜的数字大于目标值,则会提示你该值大了;反之则会提示你该值小了。
对于这道题有多种解法,首先最简单的方法就是都从头开始往后猜,这样的方法简单暴力,但是非常慢,最坏的情况下可能要猜测100个数字才把这个数字猜出来。但如果说使用二分查找就不一样了,二分的猜法就快多了。
假设现在产生了一个随机值:31
step1:我们会猜 (1 + 100) / 2 = 50,然后就会提示该值大了
step2:我们会猜(1 + 50) / 2 = 25,然后就会提示该值小了
step3:我们会猜(25 + 50) / 2 = 37,然后就会提示该值大了
step4:我们会猜(25 + 37) / 2 = 31,便得到了我们要的答案
2. 二分的一些基本知识
1) 定义
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
2) 特点
二分查找在使用时必须满足必须采用顺序存储结构且必须按关键字大小有序排列,其时间复杂度为:O(log2n)
3. 二分查找的边界问题
二分查找的基本思路其实不难,但是二分查找的边界问题是真的恶心。许多地方都有关于二分查找的模板。写法各不相同,其实没有意外的话,多种写法都是对的,但是如果把几种模板混在一起用就很有可能因为边界问题出现翻车现象。以下是我结合自己常用的模板,总结出来的一些想法。
1) 常用模板
bool check(int x) // 检查x是否满足某种性质
//模板一
int bsearch(int l, int r) {
while (l < r) {
int mid = l + r >> 1;// >> 1等价于除以2
if (check(mid)) r = mid;
else l = mid + 1;
}
return l;
}
//模板二
int bsearch(int l, int r) {
while (l < r) {
int mid = l + r + 1 >> 1;// >> 1等价于除以2
if (check(mid)) l = mid;
else r = mid - 1;
}
return l;
}
这两套模板会根据不同的情况使用。而到底应该使用哪一份模板取绝于check函数中当前的mid值到底包不包含在我们的答案之中。下面我们就据两个例子来说明一下。
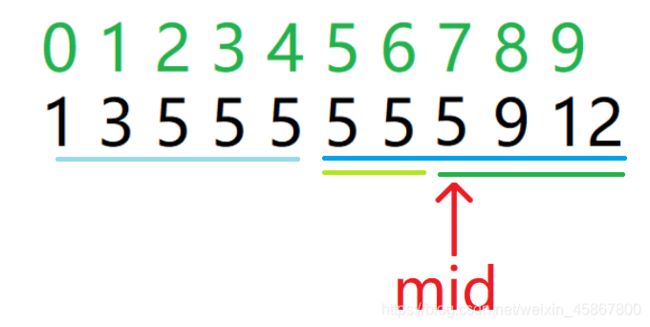
假设我们现在有这么个序列:
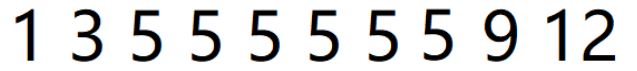
问:
- 查找从左往右找第一个小于等于5的下标
- 查找从右往左找第一个小于等于5的下标
首先我们来分析第一题。我们拿第一次查找为例子:
在我们第一次使用二分时,我们的mid会指向如图所示的5,此时我们应该往左搜还是往右搜呢?显然我们还没找到最左边的一个5,所以此时我们应该继续往左搜。那此时条件确定了,当arr[mid] >= target(arr为这个序列,target为目标值)时,我们往左搜,反之则往右搜。那么此时mid是否要包含在区域内呢?答案是要的。原因我们可以再往下看一轮
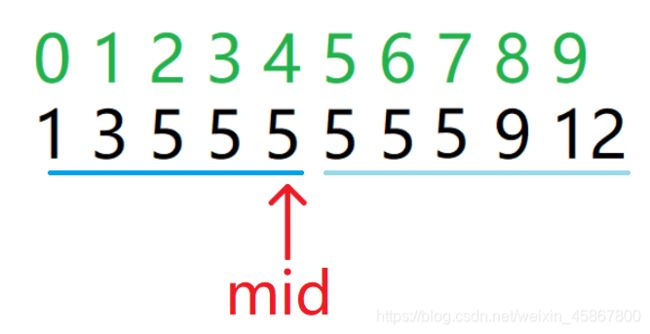
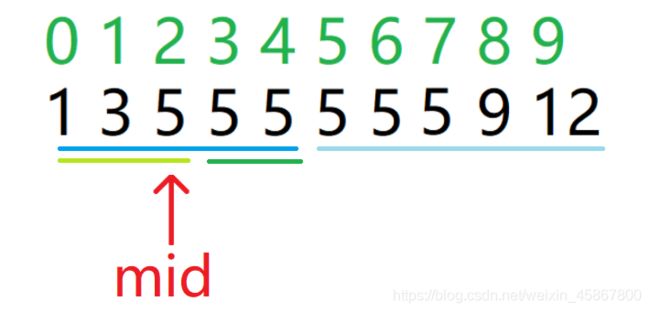
在第二轮中,我们可以看到我们已经指到了我们要的答案。如果此时我们不把mid包含在下一轮的二分中,则我们就会丢失掉这一份答案。所以我们要把mid包含进来。
结合一下刚才讲的东西我们可以看到我们的更新方式是这样的
if(nums[mid] >= taraget) r = mid;
else l = mid - 1;
结合一下模板我们会发现这种更新方式与模板一相似,所以我们写下以下代码:
int l = 0, r = n - 1;
while(l < r) {
int mid = (l + r) >> 1;
if(nums[mid] >= target) r = mid;
else l = mid + 1;
}
接下来我们来讲第二题,先看第一次查找(此处的二分取mid的方式与前面有点不一样,mid = (l + r + 1) >> 1,后面会说明为什么这么分)
首先此时我们查找到mid处的5,但显然我们要查的5是最靠右边的5,所以我们此时应该往右边找,我们可以得到,当arr[mid] <= target时,我们应该往右边找。接下来我们思考我们是否要把mid包含进答案呢?答案是要的。我们看看下一次循环:
在第二轮的二分时我们可以看到此时的mid已经指向了我们要的最右边的5了,如果此时不包含5,我们就无法保存下当前的这个值因此我们可以得出式子:
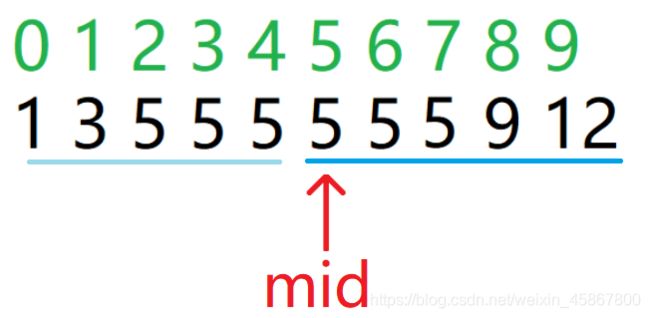
if(nums[mid] <= target) l = mid;
else r = mid - 1;
结合一下模板我们会发现这种更新方式与模板二相似,所以我们写下以下代码:
l = 0, r = n - 1;
while(l < r) {
int mid = (l + r + 1) >> 1;
if(nums[mid] <= target) l = mid;
else r = mid - 1;
}
在这段代码中有个需要注意的地方就是mid = (l + r + 1) >> 1。这是因为如果 l 和 r 相差1的时候,(l + r) >> 1会等于 l ,然后 l 又会更新为 l 。出现这种情况就会使程序陷入死循环,因此使用模板二时要把注意二分取mid时 l + r 后还要再加1。
2)综合练习
接着我们综合的来练一道题:
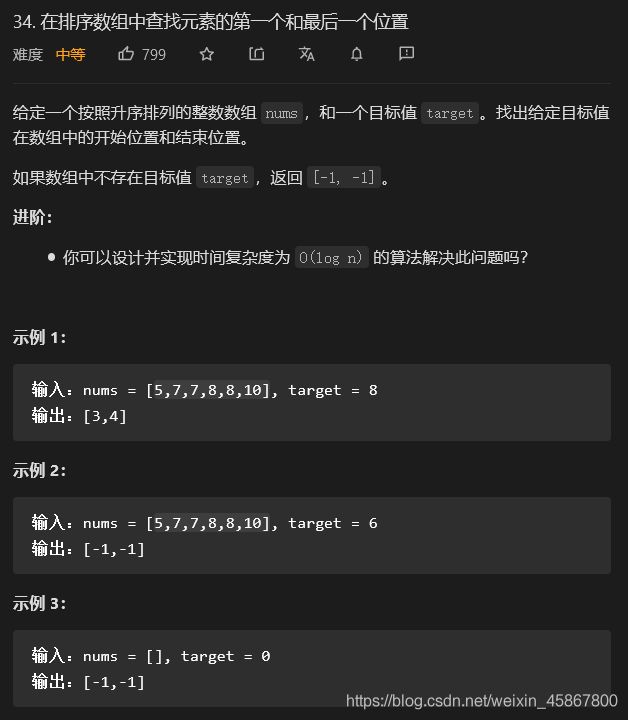
这是力扣34题,我们可以用这道题来检测一下上面的知识你是否弄懂了。这道题其实与上面的思路差不多。就是找到第一个目标值的下标和最后一个目标值(即最右边的目标值)的下标,如果找不到,则返回[-1 , -1]。
//参考代码
class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target) {
vector<int> ans;
int n = nums.size();
if(n == 0) {
vector<int> tmp(2, -1);
return tmp;
}
//使用模板一找到最左边的目标值的下标
int l = 0, r = n - 1;
while(l < r) {
int mid = (l + r) >> 1;
if(nums[mid] >= target) r = mid;
else l = mid + 1;
}
if(nums[l] != target) ans.push_back(-1);
else ans.push_back(l);
//使用模板二找到最左边的目标值的下标
l = 0, r = n - 1;
while(l < r) {
int mid = (l + r + 1) >> 1;
if(nums[mid] <= target) l = mid;
else r = mid - 1;
}
if(nums[l] != target) ans.push_back(-1);
else ans.push_back(l);
return ans;
}
};
4.二分的应用
我一开始以为二分都是在一堆数中找一个数而已。后来我接触了一些题才知道原来二分还有很多其他的应用,接下来我么就来看几道关于二分的应用题:
1) Flyer
传送门
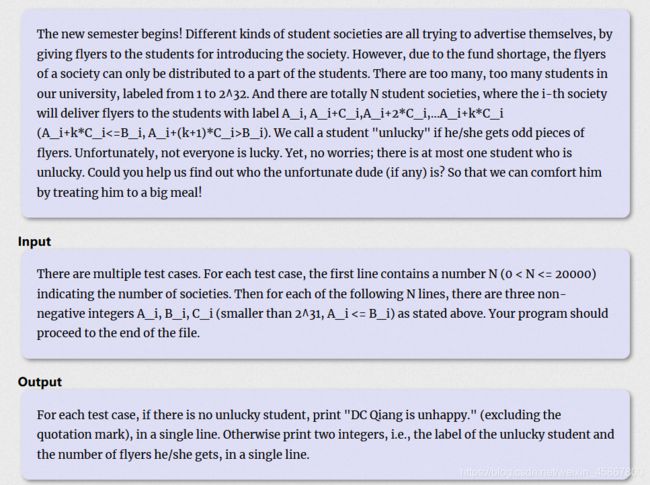

大致思路就是在每次二分区间看奇数区间在左边还是在右边,若奇数区间在左边,那么查找左边,反之查找右边。而这里我们用了类似前缀和的思路来做,我们判断奇数区间的办法就是看当前区间的和是奇数还是偶数。因为偶数的和一定为偶数,而如果一个区间和中出现一个奇数,那么该区间和就会为奇数。根据这种方式我们就可以最终二分出那个奇数的点。
接着讲讲区间和如何求,因为我们有n各部门发传单,所以我们只要看当前区间被派了多少传单即可,但注意情况分析。第一种,查询区间在派发起点之前,那么区间什么也没加到,不用处理。第二种是大于起点的情况下,小于派发终点,这个时候我们只要计算区间内的传单数即可。第三种就是派发区间终点包含在计算区间内,那么把符合条件的传单数全部加入区间即可。
最后注意要开long long
#include2) Distributing Ballot Boxes
传送门

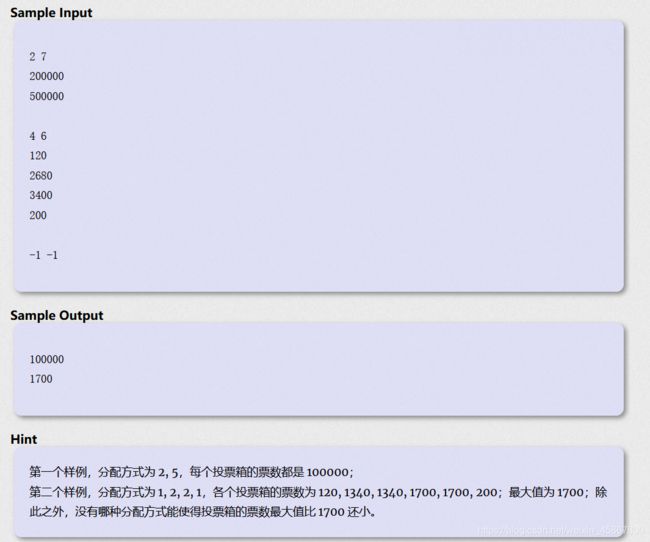
首先找到我们要二分什么,我们要二分的东西就是符合条件的最大的半径。
接下来我们要找到我们二分判断的条件,二分的条件就是在当前选择的半径下(即mid),是否可分出f + 1份pie,如果符合就往上找,不符合就往下找。
最后注意一下一些细节问题,精度问题一定要处理好,容易wa的地方在代码中已标出。
#include5.二分的拓展
我们刚刚讨论的都是整数二分,那么如果是浮点数该怎么办呢?
浮点二分的大致模板如下:
double fb(double x) {
while(r - l > D) {
double mid = (l + r) / 2;
if(check(mid)) r = mid;
else l = mid;
}
return l;
}
//浮点二分不能直接与整数一样
其中D表示精度,即 l 和 r 要多接近时才跳出循环。其他都与整数二分相似
接下来我们看一道题:
Pie
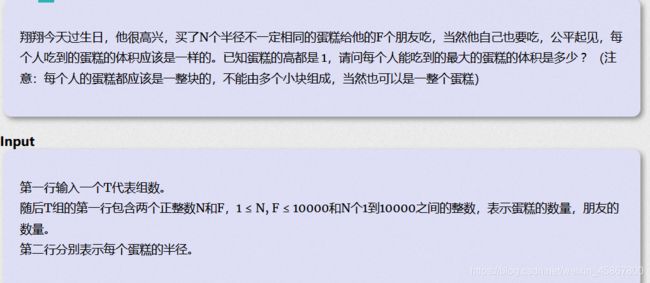
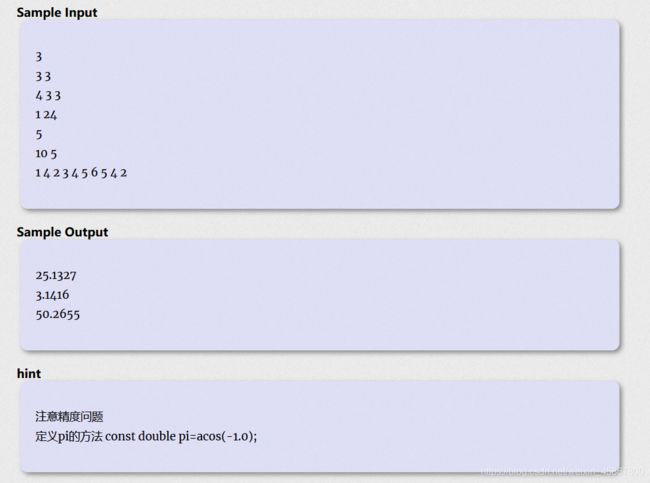
首先找到我们要二分什么,我们要二分的东西就是符合条件的最大的半径。
接下来我们要找到我们二分判断的条件,二分的条件就是在当前选择的半径下(即mid),是否可分出f + 1份pie,如果符合就往上找,不符合就往下找。
最后注意一下一些细节问题,精度问题一定要处理好,容易wa的地方在代码中已标出。
#include注:作者学自ACwing网站,本博客基于y总的总结归纳