spark---数据的加载和保存
Spark—数据的加载和保存
文章目录
- Spark---数据的加载和保存
- 通用的加载和保存方式
- 加载数据
- 保存数据
-
-
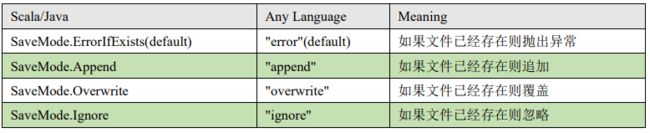
- 如果文件已经存在则抛出异常
- 如果文件已经存在则追加
- 如果文件已经存在则覆盖
- 如果文件已经存在则忽略
- Parquet
-
- 加载
- 保存
- JSON
- CSV
- MySql
-
- 添加依赖
- 方式 1:通用的 load 方法读取
- 方式 2:通用的 load 方法读取 参数另一种形式
- 方式 3:使用 jdbc 方法读取
-
通用的加载和保存方式
SparkSQL 提供了通用的保存数据和数据加载的方式。这里的通用指的是使用相同的API,根据不同的参数读取和保存不同格式的数据,SparkSQL 默认读取和保存的文件格式为 parquet
加载数据
spark.read.load 是加载数据的通用方法

读取不同格式的数据,可以对不同的数据格式进行设定
spark.read.format(“…”)[.option(“…”)].load(“…”)
- format(“…”):指定加载的数据类型,包括"csv"、“jdbc”、“json”、“orc”、“parquet”、“textFile”
- load(“…”):在"csv"、“jdbc”、“json”、“orc”、“parquet”、"textFile"格式下需要传入加载数据的路径
- option(“…”):在"jdbc"格式下需要传入 JDBC 相应参数,url、user、password 和 dbtable
保存数据
df.write.save 是保存数据的通用方法
如果保存不同格式的数据,可以对不同的数据格式进行设定

df.write.format(“…”)[.option(“…”)].save(“…”)
- format(“…”):指定保存的数据类型,包括"csv"、“jdbc”、“json”、“orc”、“parquet"和"textFile”
- save (“…”):在"csv"、“orc”、"parquet"和"textFile"格式下需要传入保存数据的路径
- option(“…”):在"jdbc"格式下需要传入 JDBC 相应参数,url、user、password 和 dbtable
保存操作可以使用 SaveMode, 用来指明如何处理数据,使用 mode()方法来设置。
有一点很重要: 这些 SaveMode 都是没有加锁的, 也不是原子操作。
SaveMode 是一个枚举类,其中的常量包括

如果文件已经存在则抛出异常
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSql")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
val frame: DataFrame = spark.read.format("json").load("datas/user.json")
frame.show()
//如果文件已经存在则抛出异常
frame.write.mode(SaveMode.ErrorIfExists).save("output")
spark.close()
}

如果文件已经存在则追加
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSql")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
val frame: DataFrame = spark.read.format("json").load("datas/user.json")
frame.show()
//如果文件已经存在则追加
frame.write.mode(SaveMode.Append).save("output")
spark.close()
}
如果文件已经存在则覆盖
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSql")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
val frame: DataFrame = spark.read.format("json").load("datas/user.json")
frame.show()
//如果文件已经存在则覆盖
frame.write.mode(SaveMode.Overwrite).save("output")
spark.close()
}

如果文件已经存在则忽略
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSql")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
val frame: DataFrame = spark.read.format("json").load("datas/user.json")
frame.show()
//如果文件已经存在则忽略
frame.write.mode(SaveMode.Overwrite).save("output")
spark.close()
}

Parquet
Spark SQL 的默认数据源为 Parquet 格式。Parquet 是一种能够有效存储嵌套数据的列式存储格式
数据源为 Parquet 文件时,Spark SQL 可以方便的执行所有的操作,不需要使用 format
修改配置项 spark.sql.sources.default,可修改默认数据源格式
加载
val df = spark.read.load(“file:///opt/soft/spark312/examples/src/main/resources/users.parquet”)

保存
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSql")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
val frame: DataFrame = spark.read.format("json").load("datas/user.json")
frame.show()
//保存为 parquet 格式
frame.write.save("output")
spark.close()
}

JSON
Spark SQL 能够自动推测 JSON 数据集的结构,并将它加载为一个 Dataset[Row]. 可以通过 SparkSession.read.json()去加载 JSON 文件。
注意:Spark 读取的 JSON 文件不是传统的 JSON 文件,每一行都应该是一个 JSON 串
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("readJson").getOrCreate()
val sc: SparkContext = spark.sparkContext
val userDF: DataFrame = spark.read.format("json").option("head", "false").load("in/user.json")
userDF.show()
}
CSV
Spark SQL 可以配置 CSV 文件的列表信息,读取 CSV 文件,CSV 文件的第一行设置为数据列
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("read").getOrCreate()
val df: DataFrame = spark.read.format("csv").option("header", "false").load("in/users.csv")
df.show()
}
MySql
添加依赖
这里mysql的版本是8.0.29
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>
方式 1:通用的 load 方法读取
def main(args: Array[String]): Unit = {
//创建SparkSQL的运行环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSql")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
val df: DataFrame = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://192.168.95.130:3306/mysql50")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "root")
.option("dbtable","student")
.load()
df.show
//关闭
spark.close()
}

方式 2:通用的 load 方法读取 参数另一种形式
def main(args: Array[String]): Unit = {
//创建SparkSQL的运行环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSql")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
val frame: DataFrame = spark.read.format("jdbc")
.options(Map(
"url" -> "jdbc:mysql://192.168.95.130:3306/mysql50?user=root&password=root",
"dbtable" -> "student",
"driver" -> "com.mysql.cj.jdbc.Driver"
)).load()
frame.show()
//关闭
spark.close()
}

方式 3:使用 jdbc 方法读取
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName("sparkhive")
.master("local[*]")
.getOrCreate()
val url = "jdbc:mysql://192.168.95.130:3306/mysql50"
val user = "root"
val password = "root"
val driver = "com.mysql.cj.jdbc.Driver"
val properties: Properties = new Properties()
properties.setProperty("user",user)
properties.setProperty("password",password)
properties.setProperty("driver",driver)
val studentTable = "student"
val frame: DataFrame = spark.read.jdbc(url, studentTable, properties)
frame.show()
}
