python搭建ip池(多线程)
之前有讲过怎么搭建ip池,但由于单线程的效率太低,于是我们升级改造一下,将单线程变成多线程来搭建ip池,之前的方法可以参考一下:python搭建ip池 (如果会简单的request和提取文字就可以直接不看)
本文将会重点放在多线程的部分。
过程分为两部分:
一、从网站上获取所有的ip信息
1、获取待爬取的url列表
2、对多线程类进行重写
3、多线程访问前面获取的url列表,获取ip信息
4、将爬取的ip信息提取并处理,返回一个列表,方便后续的保存
5、将ip信息保存到本地csv
二、将爬取的ip进行验证
1、读取前面保存的文件
2、创建多线程来验证ip是否可用
3、保存可用的ip
随便找到一个免费的ip代理网站:http://www.66ip.cn/
定义函数列表:
老样子,先附上全部代码(这个代码修改一下保存地址就可以直接使用的),后面再对每个模块进行详解。
# -*- coding: gbk -*- # 防止出现乱码等格式错误
# ip代理网站:http://www.66ip.cn/areaindex_19/1.html
import requests
from fake_useragent import UserAgent
import pandas as pd
from lxml import etree # xpath
import threading # 多线程
# --------------爬取该网站全国ip----------------
# ----先获取一共多少页,然后修改url得到url列表------
def get_url():
url_list = []
url = 'http://www.66ip.cn/index.html'
data_html = requests.get(url)
data_html.encoding = 'gbk'
data_html = data_html.text
html = etree.HTML(data_html)
page = html.xpath('//*[@id="PageList"]/a[12]/text()') # 获取全球代理的页码
for i in range(int(page[0])):
country_url = 'http://www.66ip.cn/{}.html'.format(i+1)
url_list.append(country_url)
for i in range(1,35):
city_url = 'http://www.66ip.cn/areaindex_{}/1.html'.format(i)
url_list.append(city_url)
return url_list
# ---------------爬取该网站城市ip----------------
def get_all_ip(url_list):
headers = {
'User-Agent': UserAgent().random,
}
test_ip = [] # 用于存放爬取下来的ip
for url in url_list:
try: # 防止有时访问异常抛出错误
data_html = requests.get(url=url, headers=headers)
data_html.encoding = 'gbk'
data_html = data_html.text
html = etree.HTML(data_html)
etree.tostring(html)
response = html.xpath('//div[@align="center"]/table/tr/td/text()') # 获取html含有ip信息的那一行数据
test_ip += dispose_list_ip(response) # 调用下面的处理函数,将不必要的数据筛掉
except:
continue
print("本次获取ip信息的数量:",len(test_ip))
return test_ip
# --------------将爬取的list_ip关键信息进行提取、方便后续保存----------------
def dispose_list_ip(list_ip):
num = int((int(len(list_ip)) / 5) - 1) # 5个一行,计算有几行,其中第一行是标题直接去掉
test_list = []
for i in range(num):
a = i * 5
ip_index = 5 + a # 省去前面的标题,第5个就是ip,往后每加5就是相对应ip
location_index = 6 + a
place_index = 7 + a
items = []
items.append(list_ip[ip_index])
items.append(list_ip[location_index])
items.append((list_ip[place_index]))
test_list.append(items)
return test_list
# -----------将列表的处理结果保存在csv-------------
def save_list_ip(list,file_path):
columns_name=["ip","port","place"]
test=pd.DataFrame(columns=columns_name,data=list) # 去掉索引值,否则会重复
test.to_csv(file_path,mode='a',encoding='utf-8')
print("保存成功")
# ------------读取文件,以df形式返回--------------
def read_ip(file_path):
file = open(file_path,encoding='utf-8')
df = pd.read_csv(file,usecols=[1,2,3]) # 只读取2,3,4,列(把第一列的索引去掉)
df = pd.DataFrame(df)
return df
# ----------------验证ip是否合格-----------------
def verify_ip(ip_list):
verify_ip = []
for ip in ip_list:
ip_port = str(ip[0]) + ":" + str(ip[1]) # 初步处理ip及端口号
headers = {
"User-Agent": UserAgent().random
}
proxies = {
'http': 'http://' + ip_port,
'https': 'https://'+ip_port
}
'''http://icanhazip.com访问成功就会返回当前的IP地址'''
try:
p = requests.get('http://icanhazip.com', headers=headers, proxies=proxies, timeout=3)
item = [] # 将可用ip写入csv中方便读取
item.append(ip[0])
item.append(ip[1])
item.append(ip[2])
verify_ip.append(item)
print(ip_port + "验证成功!")
except Exception as e:
print(ip_port,"验证失败")
continue
return verify_ip
# ----------------多线程重写----------------------
class MyThread(threading.Thread):
def __init__(self,func,args):
"""
:param func: run方法中的函数名
:param args: func函数所需的参数
"""
threading.Thread.__init__(self)
self.func = func
self.args = args
def run(self):
print('当前子线程:{}启动'.format(threading.current_thread().name))
self.result = self.func(self.args)
return self.func
def get_result(self): # 获取返回值
try:
return self.result # 如果子线程不使用join方法,此处可能会报没有self.result的错误
except:
return None
# -----将待处理任务进行平均分割为线程数,方便线程执行----
def split_list(list,thread_num):
list_total = []
num = thread_num # 线程数量
x = len(list) // num # 将参数进行分批(5批)方便传参
count = 1 # 计算这是第几个列表
for i in range(0, len(list), x):
if count < num:
list_total.append(list[i:i + x])
count += 1
else:
list_total.append(list[i:])
break
return list_total
# -----------多线程访问网址获取ip信息---------------
def create_thread_get_ip_list(list,thread_num):
list_total = split_list(list,thread_num) # 调用上面的方法,将任务平均分配给线程
thread_list =[] # 线程池
for url in list_total: # 添加线程
t = MyThread(func=get_all_ip,args=url)
thread_list.append(t)
# thread1 = MyThread(func=get_all_ip,args=list_total[0])
# thread2 = MyThread(func=get_all_ip,args=list_total[1])
for t in thread_list: # 批量启动线程
t.start()
for t in thread_list: # 主线程等待子线程
t.join()
ip=[] # 存放爬取的ip
for t in thread_list: # 将数据存入ip中
ip += t.get_result()
print("总共线程获取ip数量为:",len(ip))
return ip
# ------------创建线程验证ip----------------------
def create_thread_verify_ip(list,thread_num):
list_total = split_list(list, thread_num)
thread_list = [] # 存放线程池
ip = [] # 存放验证成功的ip
for list in list_total:
t = MyThread(func=verify_ip,args=list)
thread_list.append(t)
for t in thread_list:
t.start()
for t in thread_list:
t.join()
for t in thread_list:
ip += t.get_result()
return ip
if __name__ == '__main__':
# ----------# 获取待爬取的全部url---------
url_list = get_url()
print(url_list)
# ----------# 创建多线程爬取--------------
thread_num1 = 100 # 第一个线程数量
test_ip = create_thread_get_ip_list(url_list,thread_num)
# ----------# 保存数据-------------------
test_path = 'test.csv'
save_list_ip(test_ip,test_path)
# -----这里建议先运行上面,结束后再运行下面---------
# ----------# 读取、初步处理数据--------------
df = read_ip(test_path)
print("去重前数据有:",len(df))
df = df.drop_duplicates() # 去除重复数据
print("去重后数据有:",len(df))
ip_list = df.values.tolist() # df转列表(方便等会多线程的时候分配任务)
print(ip_list)
# ----------# 创建多线程验证ip--------------
thread_num2 = 100 # 第二个线程的数量
ip = create_thread_verify_ip(list=ip_list,thread_num=thread_num2)
print("验证失败ip数量:",len(ip_list)-len(ip))
print("可用ip数量:",len(ip))
# 保存
save_path = "verify_ip.csv"
save_list_ip(ip,save_path)
'''
# ----第二次验证(这里可以按自己需求写一个for循环来多验证几次,从而来提高ip池的质量)----
verify_path = 'verify_ip.csv'
df = read_ip(verify_path)
print("去重前数据有:",len(df))
df = df.drop_duplicates() # 去除重复数据
print("去重后数据有:",len(df))
ip_list = df.values.tolist() # df转列表(方便等会多线程的时候分配任务)
print(ip_list)
# ----------# 创建多线程验证ip--------------
thread_num3 = 20 # 第三个线程的数量
ip = create_thread_verify_ip(list=ip_list,thread_num=thread_num3)
print("验证失败ip数量:",len(ip_list)-len(ip))
print("可用ip数量:",len(ip))
# 保存
save_path = "优质ip.csv"
save_list_ip(ip,save_path)
'''
一、从网站上爬取所有的ip信息
1、获取待爬取的url列表
先获取页码,然后对url进行一个简单的拼接,返回url的列表,(这部分是比较简单的可以直接略过)
# ---------先获取url列表----------
def get_url():
url_list = []
url = 'http://www.66ip.cn/index.html'
data_html = requests.get(url)
data_html.encoding = 'gbk'
data_html = data_html.text
html = etree.HTML(data_html)
page = html.xpath('//*[@id="PageList"]/a[12]/text()') # 获取全球代理的页码
for i in range(int(page[0])):
country_url = 'http://www.66ip.cn/{}.html'.format(i+1)
url_list.append(country_url)
for i in range(1,35): # 因为那个网站只有35个城市
city_url = 'http://www.66ip.cn/areaindex_{}/1.html'.format(i)
url_list.append(city_url)
return url_list2、-----------------------------------多线程重写----------------------------------
在调用多线程去访问ip之前先对多线程类进行重写,方便后续调用多线程,并获取返回值。
# ----------------多线程重写----------------------
class MyThread(threading.Thread):
def __init__(self,func,args):
"""
:param func: run方法中的函数名
:param args: func函数所需的参数
"""
threading.Thread.__init__(self)
self.func = func
self.args = args
def run(self):
print('当前子线程:{}启动'.format(threading.current_thread().name))
self.result = self.func(self.args)
return self.func
def get_result(self): # 获取返回值
try:
return self.result # 如果子线程不使用join方法,此处可能会报没有self.result的错误
except:
return None3、---------------多线程爬取网站,获取ip信息(重点!!!)------------------------
创建多线程需要具备两个前提条件:函数、参数
因此我们先定义一个函数。携带url列表后进行访问、爬取页面的ip数据(可以在for循环里面让他停零点几秒,不然容易被识别成ddos攻击然后有几个url访问不进去):
def get_all_ip(url_list):
headers = {
'User-Agent': UserAgent().random,
}
test_ip = [] # 用于存放爬取下来的ip
for url in url_list:
try: # 防止有时访问异常抛出错误
data_html = requests.get(url=url, headers=headers)
data_html.encoding = 'gbk'
data_html = data_html.text
html = etree.HTML(data_html)
etree.tostring(html)
response = html.xpath('//div[@align="center"]/table/tr/td/text()') # 获取html含有ip信息的那一行数据
test_ip += dispose_list_ip(response) # 调用下面的处理函数,将不必要的数据筛掉
except:
continue
print("本次获取ip信息的数量:",len(test_ip))
return test_ipdispose_list_ip函数(用来处理一下返回的信息,将一些不必要的信息给筛掉):
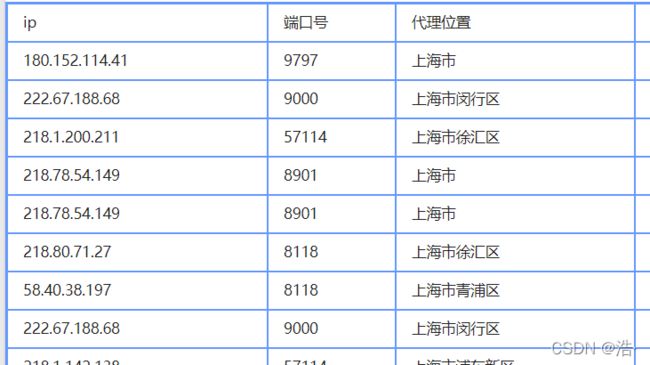
让最后的结果变成这种格式:![]()
# --------------将爬取的list_ip关键信息进行提取、方便后续保存----------------
def dispose_list_ip(list_ip):
num = int((int(len(list_ip)) / 5) - 1) # 5个一行,计算有几行,其中第一行是标题直接去掉
test_list = []
for i in range(num):
a = i * 5
ip_index = 5 + a # 省去前面的标题,第5个就是ip,往后每加5就是相对应ip
location_index = 6 + a
place_index = 7 + a
items = []
items.append(list_ip[ip_index])
items.append(list_ip[location_index])
items.append((list_ip[place_index]))
test_list.append(items)
return test_list在爬取网站之前我们要先明白,多线程需要函数、参数,我们这里参数只有一个url列表,如果每个线程都用这个url列表的话那就会重复了,因此我们要先将url列表进行一个切割。
将url列表平均切割成与线程数量相等的多个列表:
# -----将待处理任务进行平均分割为线程数,方便线程执行----
def split_list(list,thread_num):
list_total = []
num = thread_num # 线程数量
x = len(list) // num # 将参数进行分批(批数 = 线程数)方便传参
count = 1 # 计算这是第几个列表
for i in range(0, len(list), x):
if count < num:
list_total.append(list[i:i + x])
count += 1
else:
list_total.append(list[i:])
break
return list_total具体的运行效果可以先参考一下这篇文章:平均切割列表,并分配给多个线程
在切割完毕后,函数有了,参数有了,那么我们就可以开始进行线程的配置了
# -----------多线程访问网址获取ip信息---------------
# thread_num为线程数量(调用的时候自己设置)
# list 为总的url列表
def create_thread_get_ip_list(list,thread_num):
list_total = split_list(list,thread_num) # 调用上面的方法,将任务平均分配给线程(切割列表)
thread_list =[] # 线程池
for url in list_total: # 添加线程
t = MyThread(func=get_all_ip,args=url)
thread_list.append(t) # 等同于下面两句话
# thread1 = MyThread(func=get_all_ip,args=list_total[0])
# thread2 = MyThread(func=get_all_ip,args=list_total[1])
for t in thread_list: # 批量启动线程
t.start()
for t in thread_list: # 主线程等待子线程
t.join()
ip=[] # 存放爬取的ip
for t in thread_list: # 将数据存入ip中
ip += t.get_result()
print("总共线程获取ip数量为:",len(ip))
# print(ip)
return ip效果:(我这里启动了100个线程,由于url比较多可能会等二十秒左右)

5、将ip信息保存到本地csv
# -----------将列表的处理结果保存在csv-------------
# list:列表数据
#file_path:保存地址、名称 ag:file_path = 'test.csv'
def save_list_ip(list,file_path):
columns_name=["ip","port","place"]
test=pd.DataFrame(columns=columns_name,data=list) # 去掉索引值,否则会重复
test.to_csv(file_path,mode='a',encoding='utf-8')
print("保存成功")到这里第一步已经完成了,我们可以看看保存在本地的数据:

二、将爬取的ip进行验证
1、读取前面保存的文件
# ------------读取文件,以df形式返回--------------
def read_ip(file_path):
file = open(file_path,encoding='utf-8')
df = pd.read_csv(file,usecols=[1,2,3]) # 只读取2,3,4,列(把第一列的索引去掉)
df = pd.DataFrame(df)
return df2、-------------------------多线程验证ip是否可用(重点!!!!)---------------------------------
前面讲到,多线程的创建必须具备:函数、参数,二者必不可少
我们先来创建验证ip的函数(传入ip列表,判断是否可用):
有个可以用来验证ip是否可用的网站:http://icanhazip.com访问成功就会返回当前的IP地址
# -----------读取爬取的ip并验证是否合格-----------
def verify_ip(ip_list):
verify_ip = []
for ip in ip_list:
ip_port = str(ip[0]) + ":" + str(ip[1]) # 初步处理ip及端口号
headers = {
"User-Agent": UserAgent().random
}
proxies = {
'http': 'http://' + ip_port,
'https': 'https://'+ip_port
}
'''http://icanhazip.com访问成功就会返回当前的IP地址'''
try:
p = requests.get('http://icanhazip.com', headers=headers, proxies=proxies, timeout=3)
item = [] # 将可用ip写入csv中方便读取
item.append(ip[0])
item.append(ip[1])
item.append(ip[2])
verify_ip.append(item)
print(ip_port + "验证成功!")
except Exception as e:
print(ip_port,"验证失败")
continue
return verify_ip函数有了,我们继续解决参数的问题,前面讲到:列表需要进行切割用来平均分配给各个线程,否者就会出现线程重复访问的情况,这里还是调用前面定义好的split_list()函数
def split_list(list,thread_num):函数、列表都有了,我们就可以开始配置线程:
# ------------创建线程验证ip----------------------
def create_thread_verify_ip(list,thread_num):
list_total = split_list(list, thread_num)
thread_list = [] # 存放线程池
ip = [] # 存放验证成功的ip
for list in list_total:
t = MyThread(func=verify_ip,args=list)
thread_list.append(t)
for t in thread_list:
t.start()
for t in thread_list:
t.join()
for t in thread_list:
ip += t.get_result()
return ip3、保存可用的ip
上面返回得到一个可用的ip列表后,我们就可以继续调用之前的保存列表的save_list_ip(list,file_path)函数啦
三、main函数部分:
if __name__ == '__main__':
# ----------# 获取待爬取的全部url---------
url_list = get_url()
print(url_list)
# ----------# 创建多线程爬取--------------
thread_num1 = 100 # 第一个线程数量
test_ip = create_thread_get_ip_list(url_list,thread_num1)
# ----------保存数据-------------------
test_path = 'test.csv'
save_list_ip(test_ip,test_path)
# -----这里建议先运行上面,结束后再运行下面,否则容易弄乱---------
# ----------# 读取、初步处理数据--------------
df = read_ip(test_path)
print("去重前数据有:",len(df))
df = df.drop_duplicates() # 去除重复数据
print("去重后数据有:",len(df))
ip_list = df.values.tolist() # df转列表(方便等会多线程的时候分配任务)
print(ip_list)
# ----------# 创建多线程验证ip--------------
thread_num2 = 100 # 第二个线程的数量
ip = create_thread_verify_ip(list=ip_list,thread_num=thread_num2)
print("验证失败ip数量:",len(ip_list)-len(ip))
print("可用ip数量:",len(ip))
# 保存
save_path = "verify_ip.csv"
save_list_ip(ip,save_path)
'''
# ----第二次验证(这里可以按自己需求写一个for循环来多验证几次,提高ip池的质量)----
verify_path = 'verify_ip.csv'
df = read_ip(verify_path)
print("去重前数据有:",len(df))
df = df.drop_duplicates() # 去除重复数据
print("去重后数据有:",len(df))
ip_list = df.values.tolist() # df转列表(方便等会多线程的时候分配任务)
print(ip_list)
# ----------# 创建多线程验证ip--------------
thread_num3 = 20 # 第三个线程的数量
ip = create_thread_verify_ip(list=ip_list,thread_num=thread_num3)
print("验证失败ip数量:",len(ip_list)-len(ip))
print("可用ip数量:",len(ip))
# 保存
save_path = "优质ip.csv"
save_list_ip(ip,save_path)
'''