三 Ceph集群搭建
Ceph集群
集群组件
Ceph集群包括Ceph OSD,Ceph Monitor两种守护进程。
Ceph OSD(Object Storage Device): 功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD守护进程的心跳来向Ceph Monitors提供一些监控信息。
Ceph Monitor: 是一个监视器,监视Ceph集群状态和维护集群中的各种关系。
Ceph存储集群至少需要一个Ceph Monitor和两个 OSD 守护进程。
集群环境准备
集群图

准备工作
准备四台服务器,需要可以上外网,其中三台作为ceph集群 一台作为cehp客户端,除了client外每台加一个磁盘(/dev/sdb),无需分区
环境查看

配置主机名及hosts(四台主机主机名不一样hosts一样)
| 1 2 3 4 5 6 7 |
|
关闭防火墙及selinux
设置ntpdate时间同步并设置在crontab内
| 1 |
|
配置ceph的yum源
| 1 |
|
四台主机均设置,如果需要设置其他版本的yum源可以打开页面选择
阿里云开源镜像站资源目录
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
更新yum源
| 1 |
|
注意:需要更新否则后面会报错
配置ssh免密登录
以node1位部署节点在node1配置使node1可以免密登录四台主机
| 1 2 3 4 5 |
|
在node1上ssh其他主机无需输入密码代表配置ssh成功
在node1上安装部署工具(其他节点不用安装)
| 1 |
|
建立一个集群配置目录
注意:后面大部分操作在此目录进行
| 1 2 |
|
创建集群
| 1 |
|
过程如下
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|

会在当前配置文件目录生成以下配置文件
| 1 2 |
|
说明
| 1 2 3 4 |
|
集群节点安装ceph
node1 node2 node3 client都需要安装
| 1 |
|
查看版本
| 1 2 |
|
注意: 如果公网OK,并且网速好的话,可以用`ceph-deploy install node1 node2 node3`命令来安装,但网速不好的话会比较坑
所以这里我们选择直接用准备好的本地ceph源,然后`yum install ceph ceph-radosgw -y`安装即可。
客户端client安装ceph-common
| 1 |
|
好像上一步已经在client安装了cehp-common
创建mon监控
解决public网络用于监控
修改配置文件在[global]配置端添加下面一句
| 1 |
|
监控节点初始化,并同步配置到所有节点(node1,node2,node3,不包括client)
| 1 |
|
如果执行报错
| 1 2 3 |
|
则在修改配置public network = 192.168.1.0/24之前执行一次ceph-deploy mon create-initial修改配置之后再次执行即可
查看监控状态
| 1 2 |
|
将配置信息同步到所有节点
| 1 |
|
在node2 node3多了几个配置文件
| 1 2 3 4 5 6 |
|
查看状态
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
为了防止mon单点故障,你可以加多个mon节点(建议奇数个,因为有quorum仲裁投票)
| 1 2 |
|
再次查看
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
#### 监控到时间不同步的解决方法
ceph集群对时间同步要求非常高, 即使你已经将ntpd服务开启,但仍然可能有`clock skew deteted`相关警告**
请做如下尝试:
1, 在ceph集群所有节点上(`node1`,`node2`,`node3`)不使用ntpd服务,直接使用crontab同步
# systemctl stop ntpd
# systemctl disable ntpd
# crontab -e
*/10 * * * * ntpdate ntp1.aliyun.com 每5或10分钟同步1次公网的任意时间服务器
2, 调大时间警告的阈值
[root@node1 ceph]# vim ceph.conf
[global] 在global参数组里添加以下两行
mon clock drift allowed = 2 # monitor间的时钟滴答数(默认0.5秒)
mon clock drift warn backoff = 30 # 调大时钟允许的偏移量(默认为5)
修改了ceph.conf配置需要同步到所有节点
| 1 |
|
前面第1次同步不需要加--overwrite-conf参数
这次修改ceph.conf再同步就需要加--overwrite-conf参数覆盖
所有ceph集群节点上重启ceph-mon.target服务
| 1 |
|
创建mgr(管理)
eph luminous版本中新增加了一个组件:Ceph Manager Daemon,简称ceph-mgr。
该组件的主要作用是分担和扩展monitor的部分功能,减轻monitor的负担,让更好地管理ceph存储系统。
| 1 |
|

查看
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
添加多个mgr可以实现HA
| 1 2 |
|
查看
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
创建OSD(存储盘)
查看帮助
| 1 2 3 |
|
zap表示干掉磁盘上的数据,相当于格式化
| 1 2 3 |
|

将磁盘创建为osd
| 1 2 3 |
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
|
查看
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
集群节点的扩容方法
假设再加一个新的集群节点node4
1, 主机名配置和绑定
2, 在node4上`yum install ceph ceph-radosgw -y`安装软件
3, 在部署节点node1上同步配置文件给node4. `ceph-deploy admin node4`
4, 按需求选择在node4上添加mon或mgr或osd等
ceph dashboard
查看集群状态确认mgr的active节点
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
查看开启及关闭的模块
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
|
开启dashboard模块
| 1 |
|
如果开启报错
| 1 2 |
|
需要在每个开启mgr的节点安装ceph-mgr-dashboard
| 1 |
|
注意:不能仅仅在active节点安装,需要在standby节点都安装
创建自签名证书
| 1 2 |
|
生成密钥对,并配置给ceph mgr
| 1 2 |
|
| 1 |
|
| 1 2 |
|
在ceph集群的active mgr节点上(我这里为node1)配置mgr services
| 1 2 |
|
重启dashboard模块,并查看访问地址
注意:需要重启不重启查看的端口是默认的8443端口无法访问
重启就是先关disable再开启enable
| 1 2 |
|
查看mgr service
| 1 2 3 4 |
|
设置访问web页面用户名和密码
| 1 |
|
通过本机或其它主机访问 https://ip:8080
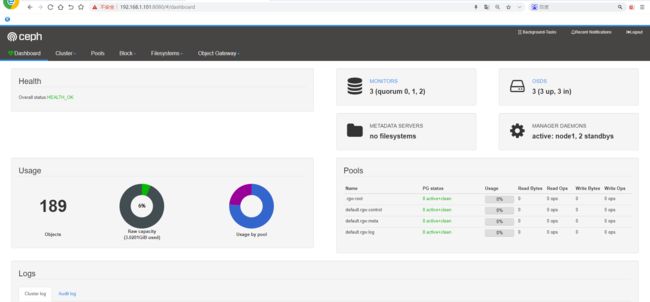
Ceph文件存储
要运行Ceph文件系统,你必须先装只是带一个mds的Ceph存储集群
Ceph.MDS:为Ceph文件存储类型存放元数据metadata(也就是说Ceph块存储和Ceph对象存储不使用MDS)
创建文件存储并使用
第1步 在node1部署节点上修改配置/etc/ceph/ceph.conf 增加配置
| 1 |
|

同步配置文件
注意:修改了配置文件才需要同步,没有修改不需要同步配置文件
| 1 |
|
创建3个mds
| 1 |
|
第2步: 一个Ceph文件系统需要至少两个RADOS存储池,一个用于数据,一个用于元数据。所以我们创建它们
| 1 2 3 4 |
|
参数解释
| 1 2 |
|
PG介绍
PG, Placement Groups。CRUSH先将数据分解成一组对象,然后根据对象名称、复制级别和系统中的PG数等信息执行散列操作,再将结果生成PG ID。可以将PG看做一个逻辑容器,这个容器包含多个对象,同时这个逻辑对象映射之多个OSD上。
如果没有PG,在成千上万个OSD上管理和跟踪数百万计的对象的复制和传播是相当困难的。没有PG这一层,管理海量的对象所消耗的计算资源也是不可想象的。建议每个OSD上配置50~100个PG。
如果定义PG数
一般的

少于5个OSD则PG数为128
5-10个OSD则PG数为512
10-50个OSD则PG数为1024
如果有更多的OSD需要自己理解计算
查看
| 1 2 3 |
|
查看创建的pool详细信息
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
第3步: 创建Ceph文件系统,并确认客户端访问的节点
| 1 2 |
|
查看
| 1 2 3 4 5 6 7 |
|
| 1 2 |
|

| 1 2 |
|

metadata保存在node3上
客户端准备验证key文件
说明: ceph默认启用了cephx认证, 所以客户端的挂载必须要验证(ceph.conf默认配置文件开启)
在集群节点(node1,node2,node3)上任意一台查看密钥字符串
| 1 |
|
输出
| 1 |
|
把这个文件放在客户端client /root/admin.key
注意:直接把key复制编辑admin.key文档可能会在挂载时报错
客户端client安装
| 1 |
|
需要安装否则客户端不支持
客户端挂载
可以使用其他node主机名进行挂载,例如node3
| 1 |
|
查看
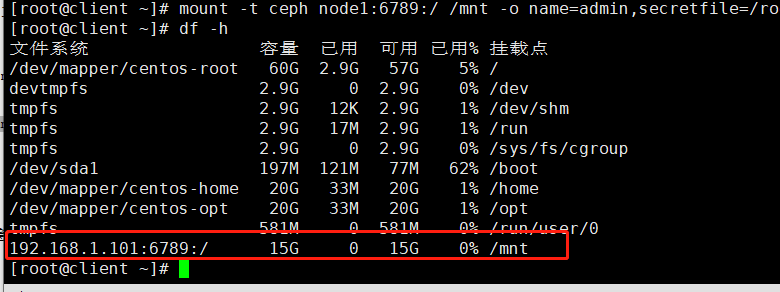
注意:如果使用文件挂载报错可以使用参数secret=秘钥进行挂载
可以使用两个客户端, 同时挂载此文件存储,可实现同读同写
往挂载的硬盘写数据可以在dashboard查看读写监控状态
| 1 |
|
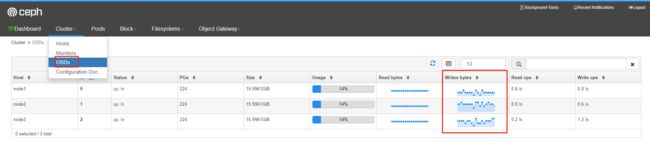
删除文件存储
在所有挂载了文件存储的客户端卸载文件挂载
| 1 |
|
停掉所有节点的mds node1 node2 node3
| 1 |
|
回到集群任意一个节点上(node1,node2,node3其中之一)删除
如果要客户端删除,需要在node1上`ceph-deploy admin client`同步配置才可以
| 1 2 3 4 5 |
|
注意:为了安全需要输入两次创建的pool名并且加参数--yes-i-really-really-mean-it才能删除
注意:需要在配置文件添加以下配置,才能删除
| 1 |
|
如果已经添加配置还提示
| 1 |
|
则重启服务ceph-mon.target即可
启动md是服务 node1 node2 node3节点启动
| 1 |
|
Ceph快存储
第一步:在node1上同步配置文件到client
| 1 2 |
|
第二步:建立存储池,并初始化
在客户端client操作
| 1 2 |
|
初始化
| 1 |
|
第三步:创建一个存储卷(这里卷名为volume1 大小为5000M)
| 1 |
|
查看
| 1 2 |
|
| 1 2 3 4 5 6 7 8 9 10 11 |
|
第四步:将创建的卷映射成块设备
因为rbd镜像的一些特性,OS kernel并不支持,所以映射报错
| 1 2 3 4 5 |
|
解决办法:disable掉相关特性
| 1 |
|
再次映射
| 1 2 |
|
创建了磁盘/dev/rbd0 类似于做了一个软连接
查看映射
| 1 2 3 |
|
如果需要取消映射可以使用命令
| 1 |
|
第六步:格式化挂载
| 1 2 |
|
查看
| 1 2 |
|
块扩容与裁减
扩容成8000M
| 1 2 |
|
查看并没有变化
| 1 2 |
|
动态刷新扩容
| 1 2 3 4 5 6 7 8 9 10 11 |
|
注意:该命令和LVM扩容命令一致
再次查看,扩容成功
| 1 2 |
|
块存储裁减
不能在线裁减,裁减后需要重新格式化再挂载,如果有数据需要提前备份好数据
裁减为5000M
| 1 2 |
|
卸载,格式化
| 1 2 3 4 |
|
查看
| 1 2 |
|
删除块存储
| 1 2 3 4 5 6 7 |
|
Ceph对象存储
第一步:在node1上创建rgw
| 1 |
|
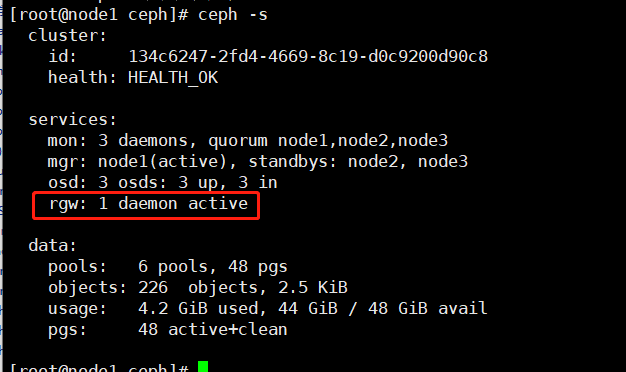
查看,运行端口是7480
| 1 |
|
第二步:在客户端测试连接对象网关
在client操作
安装测试工具
创建一个测试用户,需要在部署节点使用ceph-deploy admin client同步配置文件给client
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
|
上面一大段主要有用的为access_key与secret_key,用于连接对象存储网关
| 1 2 3 |
|
s3连接对象网关
第一步:客户端安装s3cmd工具,并编写配置文件
| 1 |
|
创建配置文件,内容如下
| 1 2 3 4 5 6 7 8 |
|
列出bucket
| 1 |
|
创建一个桶
| 1 |
|
上传文件到桶
| 1 |
|
下载文件到当前目录
| 1 |
|