AI开发平台系列2:集成式机器学习平台对比分析
【编者按:在上一期中,我们介绍了算法开发平台的发展背景和驱动力,算法开发平台的主要分类——集成式机器学习平台和AI基础软件平台,以及算法开发平台的核心价值。在本期的分享中,我们将上期所提到的云厂商集成式机器学习平台进行功能和技术的具体分析和对比】
近年来,云计算厂商纷纷向云计算+AI转型,无论是百度云提出的“云智一体”,阿里云打出的“大数据“+“AI工程化”,还是华为云的AI全栈全场景战略,都是这一趋势的有力体现。云厂商在数据和算力云原生的基础上,延伸打造涵盖算法开发全流程的集成式机器学习平台,助力企业释放数据价值,加速智能化转型。与云的深度协同,是云厂商机器学习平台的立足之基,也塑造了其产品与服务体系架构。
1. 云厂商集成式机器学习平台产品与服务架构
云厂商通过云服务获得了丰富的客户基础,并在客户服务中积累了大量机器学习应用实践。基于这些优势,云厂商通常提供包括底层云计算基础设施、机器学习平台和应用层行业解决方案于一体的产品和服务。
云计算基础设施层,主要通过容器对异构硬件资源进行统一管理和调度,帮助客户在人工智能业务中实现资源的灵活分配,让最适合的专用硬件去服务最适合的业务场景。同时,配置大数据计算引擎,为大规模分布式计算提供基础设施支撑。
在行业应用层,通常基于自身业务或服务客户的实践积累,面向特定行业、特定场景提供针对性的算法解决方案,如阿里巴巴内部的搜索系统、推荐系统及金融服务系统等算法,通过PAI平台输出赋能零售、金融等企业客户。
对于最核心的机器学习平台层,集成式机器学习平台产品建构于主流机器学习框架之上,兼容 TensorFlow、Pytorch、Caffe 等开源框架,为使用者提供更高的灵活性,同时降低环境配置成本。从功能上,集成并提供数据管理与准备、模型开发、计算与训练、推理部署与运维各阶段的产品与服务。
此外,从生态构建的角度,云厂商纷纷依托自身集成式机器学习平台搭建AI市场,吸引广大开发者和算法需求方,推动算法、模型的共享和交易。但AI市场尚处于发展早期,对集成式算法开发平台的商业和生态反哺作用较为优先,其主要挑战在于:所开发模型的行业价值、应用潜力还有待挖掘;能提出明确需求的市场购买者仍有待培育,交易和供应链机制仍待完善(包括算法和模型供需的匹配、模型生产优化的调试服务等)。

图1 云厂商集成式机器学习平台产品与服务架构
2. 部分平台核心功能与技术对比
对于集成式机器学习平台的核心功能,即数据管理与准备、模型开发、计算与训练、推理部署与运维,我们将以AWS SageMaker、百度BML、阿里云PAI和华为ModelArts为例进行深入分析。
2.1 数据管理与准备
机器学习平台数据管理与准备模块的核心价值,是让数据科学家、算法工程师便捷地接入数据并快速了解数据。四大集成式机器学习平台在数据管理和开发准备方面主要提供数据接入、数据管理、数据处理、数据标注、数据探索及高级探索等功能,其中,数据处理与标注两大细分功能是重中之重。在缺乏有效工具的情况下,这两大事项通常耗费算法开发人员最多的开发准备时间和精力。
数据处理是从大量非标、杂乱的数据中提取或生成有价值的数据集,用于后续数据标注和模型训练。从各企业官网公开信息来看,AWS SageMaker和华为云ModelArts的数据处理类型相对更为丰富,包括数据校验、数据选择、数据清洗和数据增强;阿里云仅对可视化建模预置数据处理工具,采用交互式建模的算法工程师和数据科学家需先使用Dataworks产品进行数据处理。
数据标注,模型训练过程中需要大量已标注的数据,本文涉及的四大集成式机器学习平台均提供人工标注、智能标注和团队标注功能。但目前智能标注和团队标注功能仍无法全场景、大规模使用,以华为云ModelArts为例(如图3),智能标注仅支持图像分类和物体检测,团队标注对语音内容、声音分类和视频尚不支持。
SageMaker是这四大集成式机器学习平台中目前唯一提供特征库的平台。SageMaker Feature Store是完全托管的机器学习特征存储库,帮助数据科学家和算法工程师团队高效安全地存储、共享和检索可供训练及预测工作使用的工程数据。

图2 云厂商集成式机器学习平台数据管理与准备功能/技术对比
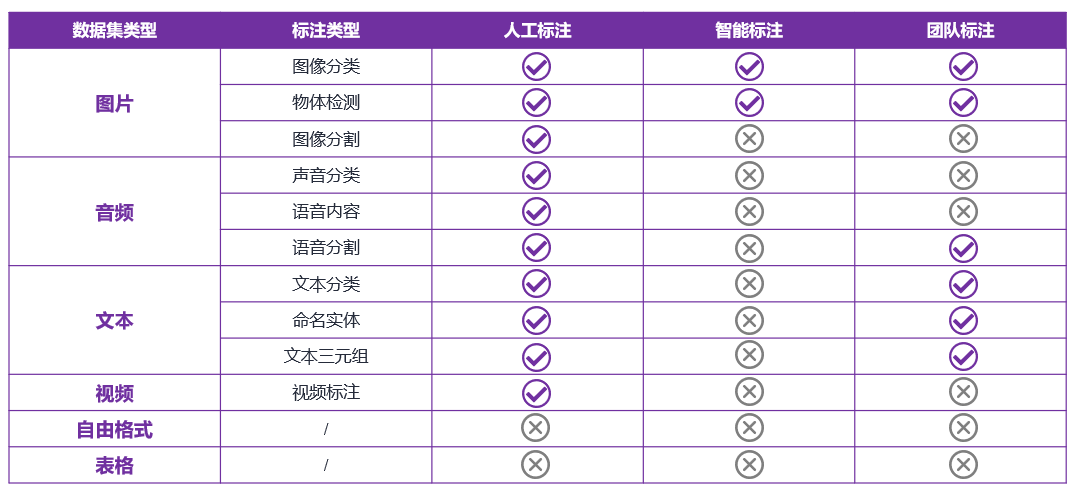
图3 华为云ModelArts数据标注功能
2.2 模型开发
模型开发方面,本文涉及的四大集成式机器学习平台功能基本旗鼓相当(见图4)。其所服务的使用对象,均既包括专业的数据科学家和算法工程师,也包括业务人员和AI初学者,并针对两类用户的差异化需求,分别提供交互式建模和可视化建模环境。
对于交互式建模,四大平台采用集成JupyterLab/Jupyter notebook的方式,进行一定程度的插件优化,其更多的精力则投入到可视化建模工具的打造。可视化建模面向的用户缺乏模型构建能力,甚至对模型开发的基本步骤与概念也知之甚少。这类使用者通过可视化建模工具仅需进行简单的点击和拖拽,无需编写代码或具有任何机器学习经验即可构建模型并进行业务预测。由于可视化建模与业务应用紧密耦合,因此,可视化建模工具的核心差异化竞争力在于行业专精以及内置算子的丰富度和质量。目前,各平台可视化建模的落地应用还仅限于部分聚焦场景,如阿里PAI内置的数百个成熟机器学习算法主要聚焦于商品推荐、金融风控、广告预测等高频场景,AWS SageMaker的可视化建模目前主要针对客户流失预测、价格优化和库存优化场景。
除开发环境外,工作流的调度和管理也是提升模型开发效率的重要一环。从目前官网公布信息来看,SageMaker具有相对完善的工作流管理工具,阿里PAI的工作流主要基于开源的MLflow构建。
2.3 计算与训练
在计算与训练环节,最核心的需求是支持分布式训练和弹性计算资源管理,以提升大模型训练的效率,节约算力成本。本文对比分析的四大平台均能较好支持这两大功能需求。
对于分布式训练,AWS SageMaker和阿里云PAI采取的方式是,基于自身的深度学习容器提供支持数据并行和模型并行的分布式训练库,以提升训练速度和吞吐量。此外,华为云ModelArts提供华为自研的分布式训练加速框架——Moxing,它构建于开源的深度学习算法框架 TensorFlow、MXNet、PyTorch等之上,提升这些框架的训练性能。从华为云披露的测试结果来看,在ImageNet数据集上用128块V100 GPU训练 ResNet-50模型, 与 fast.ai 相比,利用Moxing加速后,训练时长由18分钟缩短到 10 分钟,为用户节省 44%的成本1。
计算资源管理方面,四大平台基于自身云服务,均可支持自动扩缩容。特别地,SageMaker提供托管的Spot训练,利用Amazon EC2 Spot 实例(AWS中的可用空闲计算容量)而非按需示例来训练模型。Spot训练与按需获取算力资源的训练相比,可大幅降低算力成本。但由于Spot训练可被中断,导致训练需要更长的时间,因此Spot实例配合checkpoint的方式更适合非紧急的复杂大模型训练。
此外,超算数优化等模型调试功能和模型评估工具,也逐渐被集成进机器学习平台。但目前相关工具还处于完善过程中。

图4 云厂商集成式机器学习平台模型开发、计算与训练功能对比
2.4 推理部署与运维
模型开发与训练的最终目标,是将其部署到生产环境中,为业务赋能。SDK发布、API发布和多版本管理是各集成式机器学习平台均具备的基本功能。
除前文所提到的数据处理和标注外,工程化机器学习模型的另一核心难点是推理性能的优化。随着生产环境日趋多元和分散化(需支持多元的算法框架、异构的硬件和系统)以及模型日益复杂化,对推理性能优化的需求更加突出。各平台均开始提供推理优化工具,封装编译优化、计算图优化等技术,降低模型优化门槛,提升用户体验和生产效率。此外,模型转换也是提升生产效率的重要手段,通过转化模型格式,使其更适配于目标生产环境。但目前仅部分玩家明确提及支持模型转化,如华为云ModelArts目前支持原始框架类型为Caffe和Tensorflow的模型转换,目标部署芯片支持Ascend芯片、ARM或GPU三种类型。模型转化功能未来仍有较大的完善空间。
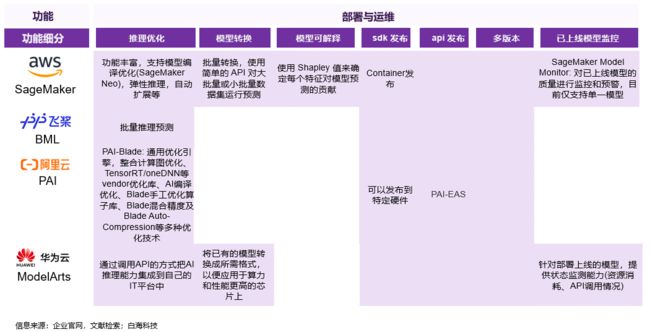
图5 云厂商集成式机器学习平台部署与运维功能/技术对比
3. 总结
云厂商集成式机器学习平台目前已基本涵盖AI开发和生产全流程所需的工具。随着AI应用的大规模落地,人工智能系统的运维管理(MLOps)将是该类平台未来发展的方向,通过标准化的模型开发、部署与运维流程、持续集成和持续部署,进一步加速企业模型开发与部署的同时,有效保障模型质量。
【参考资料】
1. 华为云产品与解决方案,《华为云ModelArts做到性能极致!128块GPU,ImageNet训练时间10分钟》
