C++左值与右值の深思——万能引用与完美转发
目录
-
- 传统艺能
- 左值与右值
- 左/右值引用
- 意义与应用
- 左值引用的缺陷
- 移动语义
- 移动构造与拷贝构造的区别
-
- 编译器优化
- 移动赋值
-
- 移动赋值和赋值重载的区别
- 容器优化
- 右值引用引用左值
-
- 容器优化
- 万能引用
- 完美转发
-
- 使用场景
传统艺能
小编是双非本科大一菜鸟不赘述,欢迎米娜桑来指点江山哦(QQ:1319365055)
非科班转码社区诚邀您入驻
小伙伴们,打码路上一路向北,彼岸之前皆是疾苦
一个人的单打独斗不如一群人的砥砺前行
这是我和梦想合伙人组建的社区,诚邀各位有志之士的加入!!
社区用户好文均加精(“标兵”文章字数2000+加精,“达人”文章字数1500+加精)
直达: 社区链接点我

左值与右值
在 C++11 里,尤其突出了两个概念那就是左右值, = 左边就是左值, = 右边就是右值,但是其实左右值的药还藏的蛮深的,里面学问大着呢,记得之前 21 年字节的青训营就出过关于左右值的作业,叫手撕一个完美转发,一时半会儿磕不明白左右值搞混了就直接头疼。
左值是一个表示数据的表达式,如变量名或解引用的指针。 \color{red} {左值是一个表示数据的表达式,如变量名或解引用的指针。} 左值是一个表示数据的表达式,如变量名或解引用的指针。
左值可以被取地址,也可以被修改(const修饰的左值除外)。左值可以出现在赋值符号的左边,也可以出现在赋值符号的右边:
int main()
{
//下面 a、b、c、*a 都是左值
int* a = new int(0);
int b = 1;
const int c = 2;
return 0;
}
右值也是一个表示数据的表达式,如字母常量、表达式的返回值、函数的返回值(不能是左值引用返回)等等 \color{red} {右值也是一个表示数据的表达式,如字母常量、表达式的返回值、函数的返回值(不能是左值引用返回)等等} 右值也是一个表示数据的表达式,如字母常量、表达式的返回值、函数的返回值(不能是左值引用返回)等等
右值不能被取地址,也不能被修改。右值可以出现在赋值符号的右边,但是不能出现在赋值符号的左边:
int main()
{
double x = 1.1, y = 2.2;
//常见右值
10;
x + y;
fmin(x, y);
//错误示例(右值不能在赋值符号左边)
//10 = 1;
//x + y = 1;
//fmin(x, y) = 1;
return 0;
}
右值本质就是一个临时变量或常量值,比如代码中的10就是常量值,表达式 x+y 和函数 fmin 的返回值就是临时变量,这些都叫做右值。
这些临时变量和常量值并没有被实际存储起来,这也就是为什么右值不能被取地址的原因,因为只有被存储起来后才有地址。
但需要注意的是,这里说函数的返回值是右值,指的是传值返回的函数,因为传值返回的函数在返回对象时返回的是对象的拷贝,这个拷贝出来的对象就是一个临时变量
对于左值引用返回的函数来说,这些函数返回的就是左值,比如 string 类实现的 [] 运算符重载函数:
namespace str
{
//模拟实现string类
class string
{
public:
//[]运算符重载(可读可写)
char& operator[](size_t i)
{
assert(i < _size); //检测下标的合法性
return _str[i]; //返回对应字符
}
//...
private:
char* _str; //存储字符串
size_t _size; //记录字符串当前的有效长度
//...
};
}
int main()
{
str::string s("hello");
s[3] = 'x'; //引用返回,支持外部修改
return 0;
}
这里的 [] 运算符重载函数返回的是引用,因为它需要支持外部对该位置的修改,所以必须采用左值引用返回。之所以说这里返回的是一个左值,是因为这个返回的字符是被存储起来了的,存在 string 的 _str 对象中,因此这个字符可以被取到地址
左/右值引用
C++98 中就有引用的语法,而 C++11 中新增了右值引用,为了进行区分,于是将 C++11 之前的引用就叫做左值引用,但是无论左值引用还是右值引用,本质都是给对象取别名
左值引用通过 & 来声明。:
int main()
{
//下面 a、b、c、*a 都是左值
int* a = new int(0);
int b = 1;
const int c = 2;
//对上面左值的左值引用
int*& ra = a;
int& rb = b;
const int& rc = c;
int& va = *a;
return 0;
}
右值引用通过 && 来声明:
int main()
{
double x = 1.1, y = 2.2;
//常见的右值
10;
x + y;
fmin(x, y);
//对右值的右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double rr3 = fmin(x, y);
return 0;
}
需要注意的是,右值是不能取地址的,但是给右值取别名后,会导致右值被存储到特定位置,这时这个右值可以被取到地址,并且可以被修改,如果不想让被引用的右值被修改,可以用const修饰右值引用
int main()
{
double x = 1.1, y = 2.2;
int&& rr1 = 10;
const double&& rr2 = x + y;
rr1 = 20;
rr2 = 5.5; //报错
return 0;
}
那么问题来了,左值引用可以引用右值吗?右值引用又可以引用左值吗?
左值引用不能引用右值,因为右值是不能被修改的,而左值引用是可以修改,这是典型的权限放大问题,但是 const 的左值引用可以引用右值,因为 const 能够保证被引用的数据不会被修改,维持了权限。
template<class T>
//const 左值引用引用右值
void func(const T& val)
{
cout << val << endl;
}
int main()
{
string s("hello");
func(s); //s为左值
func("world"); //"world"为右值
return 0;
}
右值引用只能引用右值,不能引用左值,但是右值引用可以引用move以后的左值,move 是 C++11 提供的一个函数,被 move 后的左值能够赋值给右值引用。
int main()
{
int a = 10;
//int&& r1 = a; //右值引用不能引用左值,报错
int&& r2 = move(a); //右值引用可以引用move后的左值
return 0;
}
意义与应用
为了更好的说明问题,这里需要借助一个深拷贝的类,模拟实现一个简化的 string 类。
类当中实现了一些基本的成员函数,并在string的拷贝构造函数和赋值运算符重载函数当中打印一条提示语句,这样我们就能够知道是否调用了这两个函数:
namespace cl
{
class string
{
public:
typedef char* iterator;
iterator begin()
{
return _str; //返回第一个字符的地址
}
iterator end()
{
return _str + _size; //返回字符串中最后一个字符的后一个的地址
}
//构造函数
string(const char* str = "")
{
_size = strlen(str); //初始时,字符串大小设置为字符串长度
_capacity = _size;
_str = new char[_capacity + 1]; //为存储字符串开辟空间(多开一个用于存放'\0')
strcpy(_str, str);
}
//交换两个对象的数据
void swap(string& s)
{
//调用库里的swap
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
//拷贝构造函数(现代写法)
string(const string& s)
:_str(nullptr)
, _size(0)
, _capacity(0)
{
cout << "string(const string& s) -- 深拷贝" << endl;
string tmp(s._str); //构造函数构造一个C字符串对象
swap(tmp); //交换这两个对象
}
//赋值运算符重载(现代写法)
string& operator=(const string& s)
{
cout << "string& operator=(const string& s) -- 深拷贝" << endl;
string tmp(s); //用s拷贝构造出对象tmp
swap(tmp); //交换这两个对象
return *this; //返回左值(支持连续赋值)
}
//析构函数
~string()
{
delete[] _str; //释放_str指向的空间
_str = nullptr; //及时置空,防止非法访问
_size = 0; //大小置0
_capacity = 0; //容量置0
}
//[]运算符重载
char& operator[](size_t i)
{
assert(i < _size); //检测下标的合法性
return _str[i]; //返回对应字符
}
//改变容量,大小不变
void reserve(size_t n)
{
if (n > _capacity) //当n大于对象当前容量时才需执行操作
{
char* tmp = new char[n + 1]; //多开一个空间用于存放'\0'
strncpy(tmp, _str, _size + 1); //将对象原本的C字符串拷贝过来(包括'\0')
delete[] _str;
_str = tmp;
_capacity = n;
}
}
//尾插字符
void push_back(char ch)
{
if (_size == _capacity) //判断是否需要增容
{
reserve(_capacity == 0 ? 4 : _capacity * 2); //容量扩大为原来的两倍
}
_str[_size] = ch; //将字符尾插到字符串
_str[_size + 1] = '\0'; //字符串结尾放上'\0'
_size++; //字符串的大小加一
}
//+= 运算符重载
string& operator+=(char ch)
{
push_back(ch); //尾插字符串
return *this; //返回左值(支持连续+=)
}
//返回C类型的字符串
const char* c_str()const
{
return _str;
}
private:
char* _str;
size_t _size;
size_t _capacity;
};
}
左值引用的使用场景有:
- 引用做参数,防止传参时进行拷贝操作。
- 左值引用做返回值,防止返回时对返回对象进行拷贝操作
void func1(cl::string s)
{}
void func2(const cl::string& s)
{}
int main()
{
cl::string s("hello");
func1(s); //值传参
func2(s); //左值引用传参
s += 'X'; //左值引用返回
return 0;
}
因为我们模拟实现 string 类的拷贝构造函数当中打印了提示语句,因此值传参时调用了string的拷贝构造函数。
因为 string 的 += 重载函数是左值引用返回的,因此在返回 += 后不会调用拷贝构造函数,但如果将 += 改为传值返回,那么重新运行代码后你会发现多了一次拷贝构造函数调用!
我们知道 string 的拷贝是深拷贝,深拷贝的代价是比较高的,我们应该尽量避免不必要的深拷贝操作,因此这里左值引用起到的作用还是很明显的
左值引用的缺陷
虽然 const 左值引用既能接收左值,又能接收右值,但左值引用终究有缺陷。 要知道左值引用做参数,能够完全避免传参时不必要的拷贝操作; \color{red} {要知道左值引用做参数,能够完全避免传参时不必要的拷贝操作;} 要知道左值引用做参数,能够完全避免传参时不必要的拷贝操作; 左值引用做返回值,并不能完全避免函数返回对象时不必要的拷贝操作 \color{red} {左值引用做返回值,并不能完全避免函数返回对象时不必要的拷贝操作} 左值引用做返回值,并不能完全避免函数返回对象时不必要的拷贝操作
如果函数返回的对象是一个局部变量,该变量出了函数作用域就被销毁了,这种情况就是我们之前所熟知的临时变量做返回值,因此不能用左值引用作为返回值,只能以传值的方式返回,这就是左值引用的短板。
比如我们模拟实现一个重载为 int 的 to_string 函数,因为函数返回的是一个局部变量,所以 to_string 函数就不能使用左值引用返回:
namespace cl
{
cl::string to_string(int value)
{
bool flag = true;
if (value < 0)
{
flag = false;
value = 0 - value;
}
cl::string str;
while (value > 0)
{
int x = value % 10;
value /= 10;
str += (x + '0');
}
if (flag == false)
{
str += '-';
}
std::reverse(str.begin(), str.end());
return str;
}
}
此时调用to_string函数返回时,就一定会调用string的拷贝构造函数,比如:
int main()
{
cl::string s = cl::to_string(1234);
return 0;
}
移动语义
为了解决左值引用的短板,就有了右值引用的诞生,但是并不是简单的将右值引用作为函数的返回值,此时针对右值引用就有了一种应用叫做—— 移动构造 \color{red} {移动构造} 移动构造
移动构造也是一种构造函数,参数是右值引用类型,移动构造本质就是将传入右值的资源窃取过来,占为己有,这样就避免了进行深拷贝,所以它叫做移动构造,说白了就是 ntr ,黄毛嗯把苦主的马子给牛过来,最后和苦主的资源喜结连理,happy ending。
string 类中增加一个移动构造函数,他要做的就是调用 swap 函数将传入右值的资源窃取过来,为了得知移动构造函数是否被调用,我们依然采用打印提示语句的方法检验:
namespace cl
{
class string
{
public:
//移动构造
string(string&& s)
:_str(nullptr)
, _size(0)
, _capacity(0)
{
cout << "string(string&& s) -- 移动构造" << endl;
swap(s);
}
private:
char* _str;
size_t _size;
size_t _capacity;
h };
}
移动构造与拷贝构造的区别
- 在没有增加移动构造之前,由于拷贝构造采用的是 const 左值引用接收参数,因此无论拷贝构造对象时传入的是左值还是右值,都会调用拷贝构造函数。
- 增加移动构造之后,由于移动构造采用的是右值引用接收参数,因此如果拷贝构造对象时传入的是右值,那么就会调用移动构造函数(最匹配原则)。
- string 的拷贝构造函数做的是深拷贝,而移动构造函数中只需要调用 swap 函数进行资源的转移,因此调用移动构造的代价比调用拷贝构造的代价小。
比如:
int main()
{
cl::string s = cl::to_string(1234);
return 0;
}
当然,这里 to_string 传的参数是一个 string 类型的左值,左值在函数完成后就会销毁,这种即将被销毁的对象我们称之为 将亡值 \color{red} {将亡值} 将亡值,匿名对象就是一个典型的“将亡值”,与其让将亡值出来走一下过场不如资源利用最大化,所以编译器会将将亡值自动识别成右值,这样就可以匹配到右值引用的移动构造函数。
编译器优化
我们都知道实际当一个函数在返回局部对象时,会先用局部对象拷贝构造一个临时对象,然后再用临时对象来拷贝构造接收返回值的对象:

C++11 出来之前,对于深拷贝的类来说会进行两次深拷贝,所以编译器为了提高效率对这种情况进行了优化,连续调用构造函数会被优化成一次,减少了一次不必要的深拷贝(但是不是所有编译器都做了这个优化):

C++11 里,优化依然存在:
- 如果编译器不优化,这里应该调用两次移动构造,第一次调用移动构造用返回的局部 string 对象构造出一个临时对象,第二次调用移动构造用这个临时对象构造接收返回值的对象。
- 而经过编译器优化后,最终这两次移动构造优化成了一次,直接将返回的局部 string 对象的资源移动给接收返回值的对象。
- 此外,C++11 就算编译器没有进行优化问题也不大,因为就算调用两次移动构造也只是进行两次资源的转移而已
但如果我们不是用函数的返回值来构造一个对象,而是用一个已经定义好的对象来接收函数的返回值,这时编译器就无法进行优化了,他会先用这个局部对象拷贝构造出一个临时对象,然后再调用赋值运算符重载函数将这个临时对象赋值给接收函数返回值的对象:

C++11 出来之前,因为深拷贝的类的赋值重载函数也需要以深拷贝方式实现,所以对于深拷贝的类来说这里仍然会存在两次深拷贝。
但引入 C++11 的移动构造后,这里仍然需要再调用一次赋值运算符重载函数进行深拷贝,因此深拷贝的类不仅需要实现移动构造,还需要实现移动赋值。
需要说明的是,对于返回局部对象的函数,就算只是调用函数而不接收他的返回值,也会存在一次拷贝构造或移动构造,因为返回值不管你接不接收都必须要有,而当函数结束后局部对象都会被销毁,所以就算不接收返回值也会调用一次拷贝构造或移动构造生成临时对象
移动赋值
移动赋值是一个赋值运算符重载函数,该函数的参数是右值引用类型的,思想和移动构造是一样的,窃取传入右值的资源即可,避免了深拷贝。
namespace cl
{
class string
{
public:
//移动赋值
string& operator=(string&& s)
{
cout << "string& operator=(string&& s) -- 移动赋值" << endl;
swap(s);
return *this;
}
private:
char* _str;
size_t _size;
size_t _capacity;
};
}
移动赋值和赋值重载的区别
移动赋值和原有 operator= 函数的区别和移动构造那里是一样的逻辑:
- 在没有增加移动赋值之前,由于原有 operator= 函数采用的是 const 左值引用接收参数,因此无论赋值时传入的是左值还是右值,都会调用原有的 operator= 函数。
- 增加移动赋值之后,由于移动赋值采用右值引用接收参数,如果赋值时传入的是右值,那么就会调用移动赋值函数(最匹配原则)。
- string 原有的 operator= 函数做的是深拷贝,而移动赋值函数中只需要调用 swap 函数进行资源转移,因此移动赋值的代价比原有 operator= 的代价小
给 string 增加移动构造和移动赋值后,就算用一个已经定义好的 string 对象去接收 to_string 函数返回值,也不会存在深拷贝了:
int main()
{
cl::string s;
//...
s = cl::to_string(1234);
return 0;
}
注意:代码运行后的输出结果会多打印一次拷贝构造函数的调用,这是原有operator=函数内部调用的!
容器优化
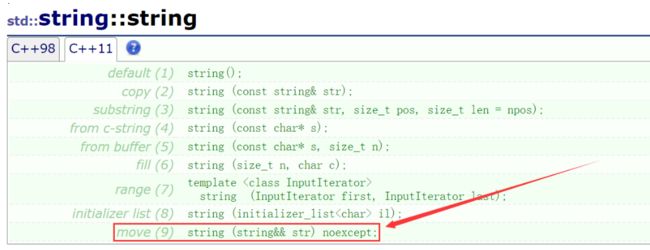
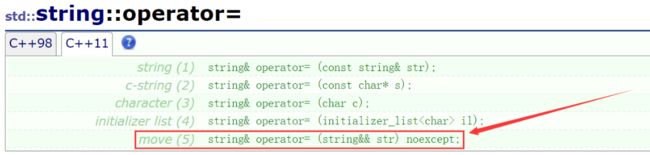
C++11 的优化好在做的非常彻底,在各种常用的 STL 容器里面也加入了移动构造和移动赋值的机制,以 STL 的 string 为例:
移动构造 \color{red} {移动构造} 移动构造:
移动赋值 \color{red} {移动赋值} 移动赋值:
右值引用引用左值
之前说过 move 是可以让对象具有右值属性,可以通过move函数将左值转化为右值,该函数唯一的功能就是将一个左值强制转化为右值引用,然后实现移动语义,并不能像他的名字一样转移什么东西。
//move 函数定义
template<class _Ty>
inline typename remove_reference<_Ty>::type&& move(_Ty&& _Arg) _NOEXCEPT
{
// _Arg 参数类型不是右值引用,而是万能引用。他们形式一样,但右值引用需要确定的类型。
return ((typename remove_reference<_Ty>::type&&)_Arg);
}
一个左值被 move 以后,它的资源可能被转移给别人了,因此要慎用一个被 move 后的左值。
容器优化
C++11 里面 STL 容器插入接口函数也增加了右值引用版本:

那么他的意义何在呢?其实很简单,如果 list 容器存储的是 string 对象,那么调用 push_back 插入元素时,可能会有如下几种方式:
int main()
{
list<cl::string> lt;
cl::string s("1111");
lt.push_back(s); //调用string的拷贝构造
lt.push_back("2222"); //调用string的移动构造
lt.push_back(cl::string("3333")); //调用string的移动构造
lt.push_back(std::move(s)); //调用string的移动构造
return 0;
}
push_back函数会先构造一个结点,然后将该结点插入到底层的双链表当中
- C++11 之前 list 的 push_back 只有一个左值引用版本,因此 push_back 构造结点时,这个左值只能匹配到 string 的拷贝构造函数进行深拷贝。
- C++11 出来之后,string 类提供了移动构造函数,并且 list 的 push_back 也提供了右值引用版本,此时如果传入 push_back 的 string 对象是一个右值,那么构造结点时,这个右值就可以匹配到 string 的移动构造进行资源转移,就避免了深拷贝提高了效率。
- 上述代码中插入第一个元素时就会匹配到 push_back 左值引用版本,在 push_back 内部调用 string 的拷贝构造进行深拷贝,而插入后三个元素时由于是右值,因此会匹配到 push_back 的右值引用版本,此时就会调用 string 的移动构造进行资源转移
万能引用
万能引用,既能接收左值又能接收右值,表示形式和右值引用一样但不需要指明类型:
template<class T>
void PerfectForward(T&& t)
{
//...
}
万能引用会根据传入实参的类型进行推导,如果传入的是一个左值,那么这里的形参 T 就是左值引用,如果传入的是一个右值,那就是右值引用。这里我们可以重载四个函数来观察万能引用的调用情况:
void Func(int& x)
{
cout << "左值引用" << endl;
}
void Func(const int& x)
{
cout << "const 左值引用" << endl;
}
void Func(int&& x)
{
cout << "右值引用" << endl;
}
void Func(const int&& x)
{
cout << "const 右值引用" << endl;
}
template<class T>
void PerfectForward(T&& t)
{
Func(t);
}
int main()
{
int a = 10;
PerfectForward(a); //左值
PerfectForward(move(a)); //右值
const int b = 20;
PerfectForward(b); //const 左值
PerfectForward(move(b)); //const 右值
return 0;
}
但是结果是出人意料的,左右值最后都会匹配到左值引用(const 左值引用),=根本原因就是右值引用后会导致右值被存储到特定位置,这时右值可以取到地址了,并且可以被修改,所以调用 Func 函数时会将 T 识别成一个左值。
也就是说,右值经过一次参数传递后其属性会退化成左值,如果想要在这个过程中保持右值的属性,就需要用到完美转发
完美转发
完美转发可以保持值的属性,要想在参数传递过程中保持其原有的属性,需要在传参时调用 forward 函数:
template<class T>
void PerfectForward(T&& t)
{
Func(std::forward<T>(t));
}
经过完美转发后,调用右值就会匹配到右值引用版本的 Func 函数,传入的是 const 右值就会匹配到 const 右值引用版本的 Func 函数,这就是完美转发的价值 。
使用场景
这里模拟实现一个简化版的 list 类,类当中分别提供了左值引用版本和右值引用版本的 push_back 和 insert 函数:
namespace cl
{
template<class T>
struct ListNode
{
T _data;
ListNode* _next = nullptr;
ListNode* _prev = nullptr;
};
template<class T>
class list
{
typedef ListNode<T> node;
public:
list()
{
_head = new node;
_head->_next = _head;
_head->_prev = _head;
}
//左值引用push_back
void push_back(const T& x)
{
insert(_head, x);
}
//右值引用push_back
void push_back(T&& x)
{
insert(_head, std::forward<T>(x)); //完美转发
}
//左值引用insert
void insert(node* pos, const T& x)
{
node* prev = pos->_prev;
node* newnode = new node;
newnode->_data = x;
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = pos;
pos->_prev = newnode;
}
//右值引用insert
void insert(node* pos, T&& x)
{
node* prev = pos->_prev;
node* newnode = new node;
newnode->_data = std::forward<T>(x); //完美转发
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = pos;
pos->_prev = newnode;
}
private:
node* _head; //链表头结点指针
};
}
注意代码中push_back和insert函数的参数T&&是右值引用,而不是万能引用,因为在 list 对象创建时这个类就已经实例化,参数 T&& 中的 T 是一个确定类型,而不是在调用 push_back 和 insert 函数时才进行类型推导。我们用这个 list 对象来存储 string 类:
int main()
{
cl::list<cl::string> lt;
cl::string s("1111");
lt.push_back(s); //调用左值引用push_back
lt.push_back("2222"); //调用右值引用push_back
return 0;
}
左值引用的 push_back 会调用 string 原有的 operator= 进行深拷贝,而右值引用的push_back 只会调用 string 的移动赋值进行资源移动
这个场景中就用到了完美转发,否则右值引用的push_back 接收到右值后,右值属性就退化了,此时在右值引用的 push_back 调用insert函数,会匹配到左值引用的 insert 函数,最终调用的还是原有的 operator= 函数进行深拷贝
也就是说,只要想保持右值的属性,每次右值传参时都需要进行完美转发,实际STL库中也是通过完美转发来保持右值属性的

我们自己实现的 list 调用的却不是 string 的拷贝构造和移动构造,而是 string 原有的 operator= 和移动赋值,原因就是我使用了 new 操作符,new 的使用会伴随着自动初始化,因此在后续就会直接调用对应的 operator= 或移动赋值进行深拷贝或资源的转移。如果想实现与 STL 库一样的原理,那就改用 malloc 就行了。
aqa 芭蕾 eqe 亏内,代表着开心代表着快乐,ok 了家人们