linux cgroup学习总结
linux-cgroup使用
大纲
- 概念
- 安装与使用
概念
基础知识
cgroups 是Linux内核提供的一种可以限制,隔离单个进程或者多个进程组 (process groups)所使用物理资源的机制,可以对 cpu,内存,i/o等资源实现精细化的控制,cgroups 全称是Control Groups
Docker 就使用了 cgroups 提供的资源限制能力来完成cpu,内存等部分的资源控制。
Cgroups是从Linux内核版本2.6.24开始添加进去的,Cgroups最初是由Google的工程师在2006年开发的,起初的名字叫“process containers”,在2007年改名为“Control Groups”。(所以 Cgroups 是系统内置的只需使用即可)
Cgroups并不是全新创造的,而是将进程管理从 cpuset 中剥离出来。CGroups 是管理虚拟化资源手段。 CGroup 提供了一个虚拟文件系统,是进行分组管理和各子系统设置的接口。所以**要使用 CGroup,必须挂载 CGroup 文件系统。**通过挂载选项指定使用哪个子系统
使用 uname -r 查看当前系统内核版本
基础概念
Cgroups 中主要有以下几个关键概念名词
- 控制组(control group)
- 子系统(subsystem)
- 层级(hierarchy)
- 任务(task)
控制组(control group)
cgroup的资源控制是以控制组的方式实现,控制组指明了资源的配额限制。进程可以加入到某个控制组,也可以迁移到另一个控制组
子系统(subsystem)
一个子系统其实就是一种资源的控制器,比如memory子系统可以控制进程内存的使用。子系统需要加入到某个层级,然后该层级的所有控制组,均受到这个子系统的控制。
子系统功能说明
- 1)blkio --为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等)。
- 2)cpu – 使用调度程序提供对CPU的cgroup任务访问。
- 3)cpuacct --自动生成cgroup中任务所使用的CPU资源报告。
- 4)cpuset --为cgroup中的任务分配独立CPU(在多核系统)和内存节点。
- 5)devices --可允许或者拒绝中的任务对设备的访问。
- 6)freezer --挂起或者恢复cgroup中的任务。
- 7)memory --设定 cgroup 中任务使用的内存限制,并自动生成任务使用的内存资源报告。
- 8)net_cls–使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。
- 9)net_prio–允许管理员动态的通过各种应用程序设置网络传输的优先级,类似于socket 选项的SO_PRIORITY,但它有它自身的优势。
- 10)HugeTLB–HugeTLB页的资源控制功能
注意:不同的linux内核版本支持的cgroup子系统数量不同,同时默认也不会全部挂载这些子系统 使用lssubsys -a 可以查看支持的子系统。在/sys/fs/cgroup文件夹下可以看到已经挂载的子系统
子系统类型
lssubsys --all 查看当前linux支持的cgroup 子系统
子系统配置项
blkio 控制选项
按比例分配块设备 IO 资源
blkio.weight:填写 100-1000 的一个整数值,作为相对权重比率,作为通用的设备分配比。
blkio.weight_device: 针对特定设备的权重比,写入格式为device_types:node_numbers weight,空格前的参数段指定设备,weight参数与blkio.weight相同并覆盖原有的通用分配比。{![查看一个设备的device_types:node_numbers可以使用:ls -l /dev/DEV,看到的用逗号分隔的两个数字就是。有的文章也称之为major_number:minor_number。]}
控制 IO 读写速度上限
blkio.throttle.read_bps_device:按每秒读取块设备的数据量设定上限,格式device_types:node_numbers bytes_per_second。
blkio.throttle.write_bps_device:按每秒写入块设备的数据量设定上限,格式device_types:node_numbers bytes_per_second。
blkio.throttle.read_iops_device:按每秒读操作次数设定上限,格式device_types:node_numbers operations_per_second。
blkio.throttle.write_iops_device:按每秒写操作次数设定上限,格式device_types:node_numbers operations_per_second
针对特定操作 (read, write, sync, 或 async) 设定读写速度上限
blkio.throttle.io_serviced:针对特定操作按每秒操作次数设定上限,格式device_types:node_numbers operation operations_per_second
blkio.throttle.io_service_bytes:针对特定操作按每秒数据量设定上限,格式device_types:node_numbers operation bytes_per_second
统计与监控 以下内容都是只读的状态报告,通过这些统计项更好地统计、监控进程的 io 情况。
blkio.reset_stats:重置统计信息,写入一个 int 值即可。
blkio.time:统计 cgroup 对设备的访问时间,按格式device_types:node_numbers milliseconds读取信息即可,以下类似。
blkio.io_serviced:统计 cgroup 对特定设备的 IO 操作(包括 read、write、sync 及 async)次数,格式device_types:node_numbers operation number
blkio.sectors:统计 cgroup 对设备扇区访问次数,格式 device_types:node_numbers sector_count
blkio.io_service_bytes:统计 cgroup 对特定设备 IO 操作(包括 read、write、sync 及 async)的数据量,格式device_types:node_numbers operation bytes
blkio.io_queued:统计 cgroup 的队列中对 IO 操作(包括 read、write、sync 及 async)的请求次数,格式number operation
blkio.io_service_time:统计 cgroup 对特定设备的 IO 操作(包括 read、write、sync 及 async)时间 (单位为 ns),格式device_types:node_numbers operation time
blkio.io_merged:统计 cgroup 将 BIOS 请求合并到 IO 操作(包括 read、write、sync 及 async)请求的次数,格式number operation
blkio.io_wait_time:统计 cgroup 在各设备中各类型IO 操作(包括 read、write、sync 及 async)在队列中的等待时间(单位 ns),格式device_types:node_numbers operation time
__blkio.__recursive_*:各类型的统计都有一个递归版本,Docker 中使用的都是这个版本。获取的数据与非递归版本是一样的,但是包括 cgroup 所有层级的监控数据。
memory 控制选项
限额类
memory.limit_bytes:强制限制最大内存使用量,单位有k、m、g三种,填-1则代表无限制。
memory.soft_limit_bytes:软限制,只有比强制限制设置的值小时才有意义。填写格式同上。当整体内存紧张的情况下,task 获取的内存就被限制在软限制额度之内,以保证不会有太多进程因内存挨饿。可以看到,加入了内存的资源限制并不代表没有资源竞争。
memory.memsw.limit_bytes:设定最大内存与 swap 区内存之和的用量限制。填写格式同上。
报警与自动控制
memory.oom_control:改参数填 0 或 1, 0表示开启,当 cgroup 中的进程使用资源超过界限时立即杀死进程,1表示不启用。默认情况下,包含 memory 子系统的 cgroup 都启用。当oom_control不启用时,实际使用内存超过界限时进程会被暂停直到有空闲的内存资源。
统计与监控类
memory.usage_bytes:报告该 cgroup 中进程使用的当前总内存用量(以字节为单位)
memory.max_usage_bytes:报告该 cgroup 中进程使用的最大内存用量
memory.failcnt:报告内存达到在 memory.limit_in_bytes设定的限制值的次数
memory.stat:包含大量的内存统计数据。
cache:页缓存,包括 tmpfs(shmem),单位为字节。
rss:匿名和 swap 缓存,不包括 tmpfs(shmem),单位为字节。
mapped_file:memory-mapped 映射的文件大小,包括 tmpfs(shmem),单位为字节
pgpgin:存入内存中的页数
pgpgout:从内存中读出的页数
swap:swap 用量,单位为字节
active_anon:在活跃的最近最少使用(least-recently-used,LRU)列表中的匿名和 swap 缓存,包括 tmpfs(shmem),单位为字节
inactive_anon:不活跃的 LRU 列表中的匿名和 swap 缓存,包括 tmpfs(shmem),单位为字节
active_file:活跃 LRU 列表中的 file-backed 内存,以字节为单位
inactive_file:不活跃 LRU 列表中的 file-backed 内存,以字节为单位
unevictable:无法再生的内存,以字节为单位
hierarchical_memory_limit:包含 memory cgroup 的层级的内存限制,单位为字节
hierarchical_memsw_limit:包含 memory cgroup 的层级的内存加 swap 限制,单位为字节
cpu 控制选项
设定 CPU 使用周期使用时间上限
cpu.cfs_period_us:设定周期时间,必须与cfs_quota_us配合使用。
cpu.cfs_quota_us :设定周期内最多可使用的时间。这里的配置指 task 对单个 cpu 的使用上限,若cfs_quota_us是cfs_period_us的两倍,就表示在两个核上完全使用。数值范围为 1000 - 1000,000(微秒)。
cpu.stat:统计信息,包含nr_periods(表示经历了几个cfs_period_us周期)、nr_throttled(表示 task 被限制的次数)及throttled_time(表示 task 被限制的总时长)。
按权重比例设定 CPU 的分配
cpu.shares:设定一个整数(必须大于等于 2)表示相对权重,最后除以权重总和算出相对比例,按比例分配 CPU 时间。(如 cgroup A 设置 100,cgroup B 设置 300,那么 cgroup A 中的 task 运行 25% 的 CPU 时间。对于一个 4 核 CPU 的系统来说,cgroup A 中的 task 可以 100% 占有某一个 CPU,这个比例是相对整体的一个值。)
** RT 调度策略下的配置 实时调度策略与公平调度策略中的按周期分配时间的方法类似,也是在周期内分配一个固定的运行时间。**
cpu.rt_period_us :设定周期时间。
cpu.rt_runtime_us:设定周期中的运行时间。
cpuacct 控制选项
这个子系统的配置是cpu子系统的补充,提供 CPU 资源用量的统计,时间单位都是纳秒。
cpuacct.usage:统计 cgroup 中所有 task 的 cpu 使用时长
cpuacct.stat:统计 cgroup 中所有 task 的用户态和内核态分别使用 cpu 的时长
cpuacct.usage_percpu:统计 cgroup 中所有 task 使用每个 cpu 的时长
cpuset 控制选项
指定进程绑定cpu
cpuset.cpus:在这个文件中填写 cgroup 可使用的 CPU 编号,如0-2,16代表 0、1、2 和 16 这 4 个 CPU。
cpuset.mems:与 CPU 类似,表示 cgroup 可使用的memory node,格式同上
device 控制选项
** 设备黑 / 白名单过滤限制 task 对 device 的使用 **
devices.allow:允许名单,语法type device_types:node_numbers access type ;type有三种类型:b(块设备)、c(字符设备)、a(全部设备);access也有三种方式:r(读)、w(写)、m(创建)。
devices.deny:禁止名单,语法格式同上。
freezer 控制选项
暂停 / 恢复 cgroup 中的 task
层级(hierarchy)
控制组有层级关系,类似树的结构,子节点的控制组继承父控制组的属性(资源配额、限制等) 在父层级下创建文件夹就可以继承父层级的子系统,task除外
任务(task)
在cgroup中,任务就是一个进程。
安装与使用
注意:这里的总结都是基于ubuntu实现
基本使用方式
工具准备
cgroup是系统内核提供的功能无需额外安装,但需要一些工具来方便操作
- ubuntu cgroup工具安装: apt install cgroup-tools
- CentOS7 cgroup工具安装:yum install libcgroup libcgroup-tools
安装完成后就可以使用以下命令 (后面详解)
- cgclassify –将运行的任务移动到一个或者多个cgroup,例如:cgclassify -g cpu:yy [pid]
- cgclear --删除层级中的所有cgroup。
- cgconfigparser --解析cgconfig.conf文件和并挂载层级。
- cgcreate – cgcreate在层级中创建新cgroup。
- cgdelete – cgdelete命令删除指定的cgroup。
- cgexec – 这个命令是cgroup启动的cgexec命令在指定的cgroup中运行任务。例如:cgexec -g “cpu:demo” ./mydocker 如果不使用那就手动把进程号写入到tasks中
- cgget – cgget命令查看cgroup组里面设置的资源的限制。
- cgrulesengd --在 cgroup 中发布任务。
- cgset – cgset 命令为 cgroup 设定参数。路径相对于根的/cgroup,如果想设置根的参数使用gset命令。
- lscgroup --命令列出层级中的 cgroup。
- lssubsys --命令列出包含指定子系统的层级,使用-am参数可以看到未挂载的所有子系统
注意:后面的文章对以上命令详解
查看系统支持的cgroup
使用lssubsys --all 查看当前linux支持的cgroup 子系统 注意可能需要先安装 apt install cgroup-tools
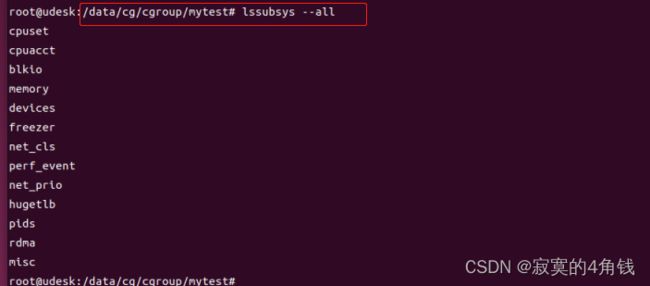
使用cgroup
1 使用默认挂载的cgroup
默认情况下linux会在启动后自动挂载group, 挂载的路径为/sys/fs/cgroup, docker就是直接使用的默认挂载的cgroup

一个简单的例子 本例子使用stress 压力测试工具 来实现控制cpu使用率为50%
安装stress
ubuntu apt-get install stress
centos yum install stress
**命令 stress -c 1 -t 60s **
开启一个进程不停做平方根60s 让cpu使用率飙升接近100%


创建自己的cgroup 控制层 mytest (系统从启后mytest自动删除)
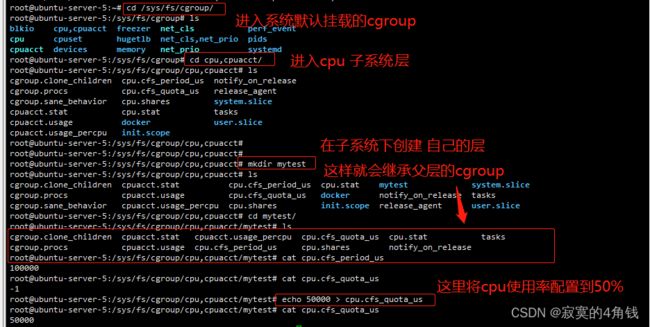
测试使用刚才创建的mytest
- 方法1 使用 cgexec
- 方法2 直接写pid 到 tasks
方法1 使用 cgexec 命令指定进程使用cgroup
cgexec -g cpu:mytest stress -c 1 -t 60s
-g cpu:mytest 表示使用cpu子系统中的mytest
![]()
cpu使用率 在50%

方法2 直接将pid 写入到 tasks
直接启动stress 程序 注意这次没有加cgexec

将stress 的pid 写入到 mytest文件夹下的 tasks
![]()
cpu使用率 在50%

2 挂载自定义cgroup
注意:挂载自定义的cgroup 重启系统后就自动删除挂载的cgroup 层级
在挂载前先使用 lssubsys -a 查看当前cgroup可以使用的子系统

注意:挂载cpu限制时需要使用 cpu,cpuacct 挂载网络限制的时候需要使用 net_cls,net_prio
Linux中可以使用mount命令挂载 cgroups 文件系统
格式为: mount -t cgroup -o 【cgroup子系统】【mount显示名称】【挂载的路径】
- mount -t cgroup 固定格式表示挂载的文件系统类型是 cgroup
- -o 后面是cgroup子系统名词 例如 -o cpu
- 【mount显示名称】 使用mount命令可以展示出挂载信息, 会显示挂载时指定的名称 。 注意:使用umount 名称可以删除挂载
- 【挂载的路径】将cgroup 层级挂载到硬盘哪个文件夹里
挂载自定义cgroup 流程
1 先规划好自定义挂载的文件夹路径
由于每个子系统只能挂载在一个文件夹下 所以先准备需要挂载子系统的文件夹
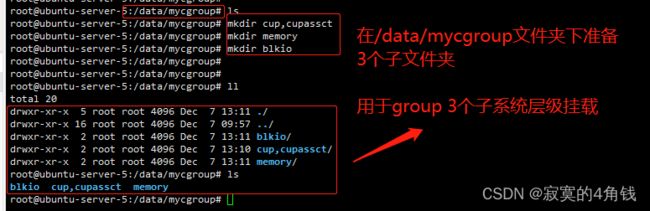
2 将不同的子系统挂载到对应的文件夹下

使用 mount | grep my 可以看到已经成功挂载
使用 mount my_cpu_mount 可以删除这个挂载

可以看到自定义挂载的cgroup 子系统层会继承父级的各种信息(包括在上一次测试中使用的mytest层级)
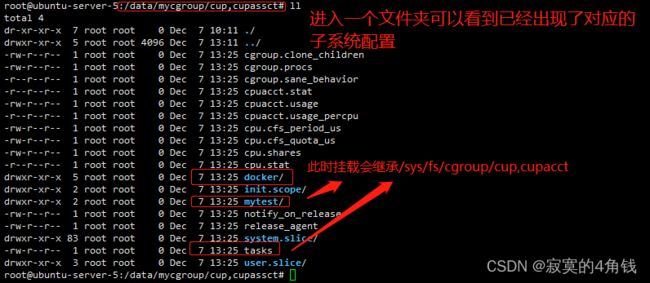
3 可以使用mkdir 创建自定义的层级,或者使用cgcreate
mkdir 的方式在上次的测试中已经使用,这次使用cgcreate 命名创建一个层级

4 测试使用控制进程cpu使用率为20%
将cpu使用率设为20% 并把stress运行时的进程号写入到tasks中 再使用top观察stress的cpu使用率

cgroup-tools 工具总结
cgclassify
cgclassify 命令将进程移动到 cgroup 中
命令各式: cgclassify -g subsystems:my_cgroup 【进程ids】
- subsystems 是用逗号分开的子系统列表,或者 * 启动与所有可用子系统关联的层级中的进程。请注意:如果在多个层级中有同名的 cgroup,则 -g 选项会将该进程移动到每个组群中。
- my_cgroup 是到其层级中的 cgroup 的路径
- 【进程ids】 是用空格分开的进程识别符(PID)列表 还可以在 pid 前面添加 – sticky 选项以保证所有子进程位于同一 cgroup 中。

cgclassify 命令类似 echo pid > tasks
gexec
cgexec 命令在 cgroup 中启动进程
命令各式: cgexec -g subsystems:my_cgroup【操作命令】
- subsystems 是用逗号分开的子系统列表,或者 * 启动与所有可用子系统关联的层级中的进程。请注意:如果在多个层级中有同名的 cgroup,则 -g 选项会将该进程移动到每个组群中。
- my_cgroup 是到其层级中的 cgroup 的路径
- 【操作命令】需要执行的程序

cgcreate cgdelete
cgcreate -g subsystems:my_cgroup
cgdelete 命令,比如要删除上述的 test 节点,可以使用 cgdelete -r cpu:test命令进行删除