「 Redis 」缓存过期策略及内存淘汰策略
「 Redis 」缓存过期策略及内存淘汰策略
Redis的过期策略和内存淘汰机制有什么区别 架构师成长之路
Redis 内存淘汰机制详解 架构师
理解Redis的内存回收机制和过期淘汰策略 hoohack
Redis 过期删除策略和内存淘汰策略有什么区别? xiaoLinCoding
文章目录
- 「 Redis 」缓存过期策略及内存淘汰策略
-
- 一、前言
- 二、缓存过期策略
-
- 惰性删除
- 定期删除
- 定时删除
- Redis 过期删除策略是什么
- 三、内存淘汰策略
-
- 不进行淘汰的策略
- 会进行淘汰的策略
- LRU算法
- LFU算法
- 为什么 Redis 有了 LRU 还需要 LFU
- 四、小结
一、前言
在计算机科学中,缓存是一种优化技术,用于提高系统的性能。通过将经常访问的数据存储在快速访问的介质(如快速内存)中,可以减少读取慢速存储介质(如硬盘)的次数,从而加快了程序的响应时间。
然而,缓存也带来一个问题:缓存中存储的数据可能会过期或变得不再有用。为了解决这个问题,我们需要使用缓存淘汰策略。这些策略控制着缓存中哪些数据应该被删除以及何时删除它们。
除了缓存淘汰策略之外,内存淘汰机制也是一个重要的概念。当缓存满了并且新数据需要被添加到缓存中时,缓存中的旧数据必须被替换。内存淘汰机制定义了哪些数据应该被替换,以及什么时候应该进行替换。这些策略通常根据数据的使用频率和最近的使用时间来确定哪些数据是最不重要的,并进行淘汰。
在本文中,我们将探讨不同的缓存过期策略和内存淘汰机制,以及它们如何影响系统的性能和可靠性。
二、缓存过期策略
我们在新增 Redis 缓存时可以设置缓存的过期时间,该时间保证了数据在规定的时间内失效,可以借助这个特性来实现很多功能。比如,存储一定天数的用户(登录)会话信息,这样在一定范围内用户不用重复登录了,但为了安全性,需要在一定时间之后重新验证用户的信息。因此,我们可以使用 Redis 设置过期时间来存储用户的会话信息。
对于已经过期的数据,Redis 将使用两种策略来删除这些过期键,它们分别是惰性删除和定期删除。
惰性删除
惰性删除是指 Redis 服务器不主动删除过期的键值,而是当访问键值时,再检查当前的键值是否过期,如果过期则执行删除并返回 null 给客户端;如果没过期则正常返回值信息给客户端。
它的优点是不会浪费太多的系统资源,只是在每次访问时才检查键值是否过期。缺点是删除过期键不及时,造成了一定的空间浪费。
惰性删除的源码位于 src/db.c 文件的 expireIfNeeded 方法中,如下所示:
int expireIfNeeded(redisDb *db, robj *key) {
// 判断键是否过期
if (!keyIsExpired(db,key)) return 0;
if (server.masterhost != NULL) return 1;
/* 删除过期键 */
// 增加过期键个数
server.stat_expiredkeys++;
// 传播键过期的消息
propagateExpire(db,key,server.lazyfree_lazy_expire);
notifyKeyspaceEvent(NOTIFY_EXPIRED,
"expired",key,db->id);
// server.lazyfree_lazy_expire 为 1 表示异步删除,否则则为同步删除
return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
}
// 判断键是否过期
int keyIsExpired(redisDb *db, robj *key) {
mstime_t when = getExpire(db,key);
if (when < 0) return 0;
if (server.loading) return 0;
mstime_t now = server.lua_caller ? server.lua_time_start : mstime();
return now > when;
}
// 获取键的过期时间
long long getExpire(redisDb *db, robj *key) {
dictEntry *de;
if (dictSize(db->expires) == 0 ||
(de = dictFind(db->expires,key->ptr)) == NULL) return -1;
serverAssertWithInfo(NULL,key,dictFind(db->dict,key->ptr) != NULL);
return dictGetSignedIntegerVal(de);
}
惰性删除的执行流程如下图所示:
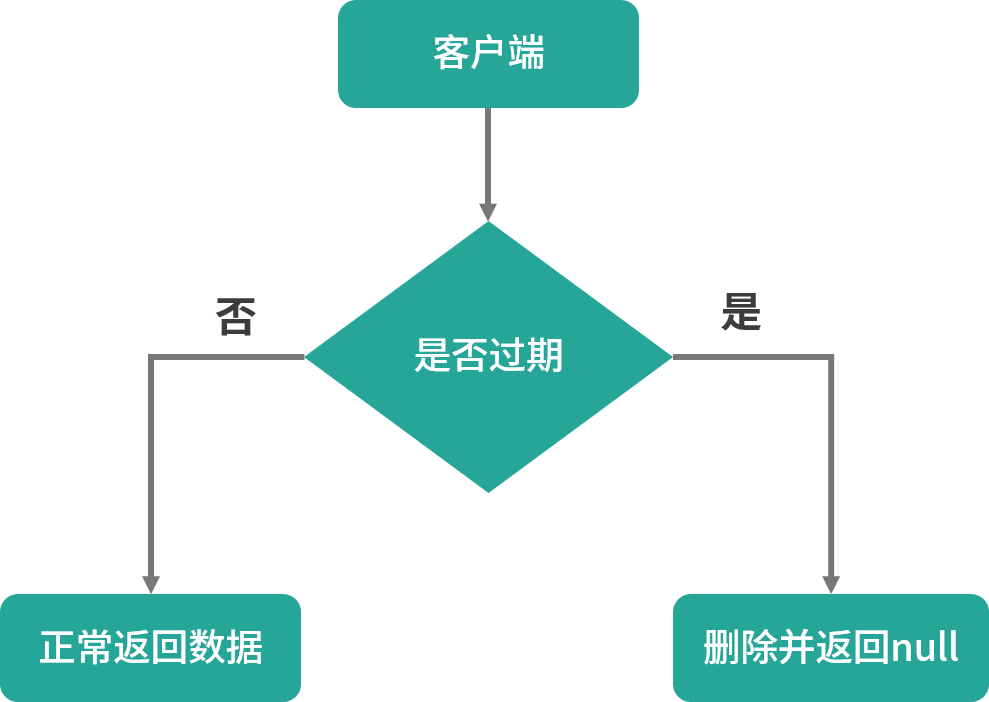
惰性删除策略的优点:
- 因为每次访问时,才会检查 key 是否过期,所以此策略只会使用很少的系统资源,因此,惰性删除策略对 CPU 时间最友好。
惰性删除策略的缺点:
- 如果一个 key 已经过期,而这个 key 又仍然保留在数据库中,那么只要这个过期 key 一直没有被访问,它所占用的内存就不会释放,造成了一定的内存空间浪费。所以,惰性删除策略对内存不友好。
定期删除
除了惰性删除之外,Redis 还提供了定期删除功能以弥补惰性删除的不足。
定期删除是指 Redis 服务器每隔一段时间会检查一下数据库,看看是否有过期键可以被清除。
默认情况下 Redis 定期检查的频率是每秒扫描 10 次,用于定期清除过期键。当然此值还可以通过配置文件进行设置,在 redis.conf 中修改配置“hz”即可,默认的值为“hz 10”。
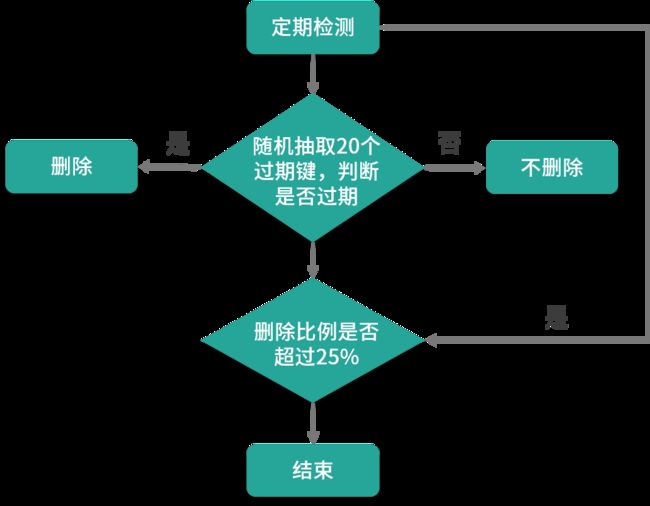
小贴士:定期删除的扫描并不是遍历所有的键值对,这样的话比较费时且太消耗系统资源。Redis 服务器采用的是随机抽取形式,每次从过期字典中,取出 20 个键进行过期检测,过期字典中存储的是所有设置了过期时间的键值对。如果这批随机检查的数据中有 25% 的比例过期,那么会再抽取 20 个随机键值进行检测和删除,并且会循环执行这个流程,直到抽取的这批数据中过期键值小于 25%,此次检测才算完成。
定期删除的源码在 expire.c 文件的 activeExpireCycle 方法中,如下所示:
void activeExpireCycle(int type) {
static unsigned int current_db = 0; /* 上次定期删除遍历到的数据库ID */
static int timelimit_exit = 0;
static long long last_fast_cycle = 0; /* 上次执行定期删除的时间点 */
int j, iteration = 0;
int dbs_per_call = CRON_DBS_PER_CALL; // 需要遍历数据库的数量
long long start = ustime(), timelimit, elapsed;
if (clientsArePaused()) return;
if (type == ACTIVE_EXPIRE_CYCLE_FAST) {
if (!timelimit_exit) return;
// ACTIVE_EXPIRE_CYCLE_FAST_DURATION 快速定期删除的执行时长
if (start < last_fast_cycle + ACTIVE_EXPIRE_CYCLE_FAST_DURATION*2) return;
last_fast_cycle = start;
}
if (dbs_per_call > server.dbnum || timelimit_exit)
dbs_per_call = server.dbnum;
// 慢速定期删除的执行时长
timelimit = 1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/server.hz/100;
timelimit_exit = 0;
if (timelimit <= 0) timelimit = 1;
if (type == ACTIVE_EXPIRE_CYCLE_FAST)
timelimit = ACTIVE_EXPIRE_CYCLE_FAST_DURATION; /* 删除操作花费的时间 */
long total_sampled = 0;
long total_expired = 0;
for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
int expired;
redisDb *db = server.db+(current_db % server.dbnum);
current_db++;
do {
// .......
expired = 0;
ttl_sum = 0;
ttl_samples = 0;
// 每个数据库中检查的键的数量
if (num > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP)
num = ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP;
// 从数据库中随机选取 num 个键进行检查
while (num--) {
dictEntry *de;
long long ttl;
if ((de = dictGetRandomKey(db->expires)) == NULL) break;
ttl = dictGetSignedInteger
// 过期检查,并对过期键进行删除
if (activeExpireCycleTryExpire(db,de,now)) expired++;
if (ttl > 0) {
ttl_sum += ttl;
ttl_samples++;
}
total_sampled++;
}
total_expired += expired;
if (ttl_samples) {
long long avg_ttl = ttl_sum/ttl_samples;
if (db->avg_ttl == 0) db->avg_ttl = avg_ttl;
db->avg_ttl = (db->avg_ttl/50)*49 + (avg_ttl/50);
}
if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */
elapsed = ustime()-start;
if (elapsed > timelimit) {
timelimit_exit = 1;
server.stat_expired_time_cap_reached_count++;
break;
}
}
/* 判断过期键删除数量是否超过 25% */
} while (expired > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4);
}
// .......
}
定期删除的执行流程,如下图所示:
小贴士:Redis 服务器为了保证过期删除策略不会导致线程卡死,会给过期扫描增加了最大执行时间为 25ms。
定期删除策略的优点:
- 通过限制删除操作执行的时长和频率,来减少删除操作对 CPU 的影响,同时也能删除一部分过期的数据减少了过期键对空间的无效占用。
定期删除策略的缺点:
- 内存清理方面没有定时删除效果好,同时没有惰性删除使用的系统资源少。
- 难以确定删除操作执行的时长和频率。如果执行的太频繁,定期删除策略变得和定时删除策略一样,对CPU不友好;如果执行的太少,那又和惰性删除一样了,过期 key 占用的内存不会及时得到释放。
定时删除
定时删除策略的做法是,在设置 key 的过期时间时,同时创建一个定时事件,当时间到达时,由事件处理器自动执行 key 的删除操作。
定时删除策略的优点:
- 可以保证过期 key 会被尽快删除,也就是内存可以被尽快地释放。因此,定时删除对内存是最友好的。
定时删除策略的缺点:
- 在过期 key 比较多的情况下,删除过期 key 可能会占用相当一部分 CPU 时间,在内存不紧张但 CPU 时间紧张的情况下,将 CPU 时间用于删除和当前任务无关的过期键上,无疑会对服务器的响应时间和吞吐量造成影响。所以,定时删除策略对 CPU 不友好。
Redis 过期删除策略是什么
前面介绍了三种过期删除策略,每一种都有优缺点,仅使用某一个策略都不能满足实际需求。
所以, Redis 选择「惰性删除+定期删除」这两种策略配和使用,以求在合理使用 CPU 时间和避免内存浪费之间取得平衡。
Redis 是怎么实现惰性删除的?
Redis 的惰性删除策略由 db.c 文件中的 expireIfNeeded 函数实现,代码如下:
int expireIfNeeded(redisDb *db, robj *key) {
// 判断 key 是否过期
if (!keyIsExpired(db,key)) return 0;
....
/* 删除过期键 */
....
// 如果 server.lazyfree_lazy_expire 为 1 表示异步删除,反之同步删除;
return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
}
Redis 在访问或者修改 key 之前,都会调用 expireIfNeeded 函数对其进行检查,检查 key 是否过期:
- 如果过期,则删除该 key,至于选择异步删除,还是选择同步删除,根据
lazyfree_lazy_expire参数配置决定(Redis 4.0版本开始提供参数),然后返回 null 客户端; - 如果没有过期,不做任何处理,然后返回正常的键值对给客户端;
Redis 是怎么实现定期删除的?
再回忆一下,定期删除策略的做法:每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。
1、这个间隔检查的时间是多长呢?
在 Redis 中,默认每秒进行 10 次过期检查一次数据库,此配置可通过 Redis 的配置文件 redis.conf 进行配置,配置键为 hz 它的默认值是 hz 10。
特别强调下,每次检查数据库并不是遍历过期字典中的所有 key,而是从数据库中随机抽取一定数量的 key 进行过期检查。
2、随机抽查的数量是多少呢?
我查了下源码,定期删除的实现在 expire.c 文件下的 activeExpireCycle 函数中,其中随机抽查的数量由 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP 定义的,它是写死在代码中的,数值是 20。
也就是说,数据库每轮抽查时,会随机选择 20 个 key 判断是否过期。
接下来,详细说说 Redis 的定期删除的流程:
- 从过期字典中随机抽取 20 个 key;
- 检查这 20 个 key 是否过期,并删除已过期的 key;
- 如果本轮检查的已过期 key 的数量,超过 5 个(20/4),也就是「已过期 key 的数量」占比「随机抽取 key 的数量」大于 25%,则继续重复步骤 1;如果已过期的 key 比例小于 25%,则停止继续删除过期 key,然后等待下一轮再检查。
可以看到,定期删除是一个循环的流程。
那 Redis 为了保证定期删除不会出现循环过度,导致线程卡死现象,为此增加了定期删除循环流程的时间上限,默认不会超过 25ms。
定期删除的流程
do {
//已过期的数量
expired = 0;
//随机抽取的数量
num = 20;
while (num--) {
//1. 从过期字典中随机抽取 1 个 key
//2. 判断该 key 是否过期,如果已过期则进行删除,同时对 expired++
}
// 超过时间限制则退出
if (timelimit_exit) return;
/* 如果本轮检查的已过期 key 的数量,超过 25%,则继续随机抽查,否则退出本轮检查 */
} while (expired > 20/4);
三、内存淘汰策略
在 Redis 4.0 版本之前有 6 种策略,4.0 增加了 2种,主要新增了 LFU 算法。
下图为 Redis 6.2.0 版本的配置文件:

其中,默认的淘汰策略是 noevition,也就是不淘汰
我们可以对 8 种淘汰策略可以分为两大类:
不进行淘汰的策略
noevition,此策略不会对缓存的数据进行淘汰,当内存不够了就会报错,因此,如果真实数据集大小大于缓存容量,就不要使用此策略了。
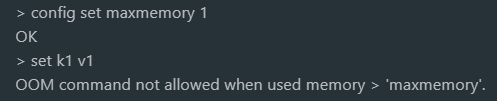
会进行淘汰的策略
在所有数据中筛选
- allkeys-random:随机删除
- allkeys-lru:使用 LRU 算法进行筛选删除
- allkeys-lfu:使用 LFU 算法进行筛选删除
在设置了过期时间的数据中筛选
- volatile-random:随机删除
- volatile-ttl:根据过期时间先后进行删除,越早过期的越先被删除
- volatile-lru:使用 LRU 算法进行筛选删除
- volatile-lfu:使用 LFU 算法进行筛选删除
以 volatile 开头的策略只针对设置了过期时间的数据,即使缓存没有被写满,如果数据过期也会被删除。
以 allkeys 开头的策略是针对所有数据的,如果数据被选中了,即使过期时间没到,也会被删除。当然,如果它的过期时间到了但未被策略选中,同样会被删除。
那么我们如何配置过期策略呢?
- 命令行
config set maxmemory-policy allkeys-lru
- 配置文件

LRU算法
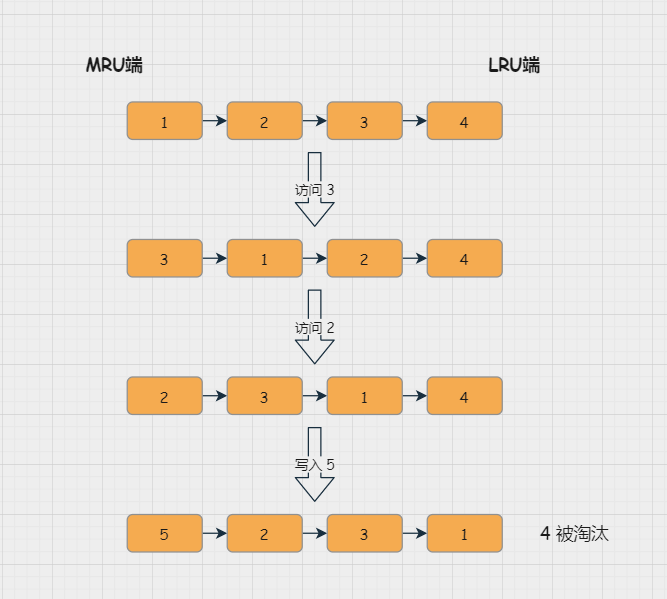
LRU 全称是 Least Recently Used,即最近最少使用,会将最不常用的数据筛选出来,保留最近频繁使用的数据。
LRU 会把所有数据组成一个链表,链表头部称为 MRU,代表最近最常使用的数据;尾部称为 LRU代表最近最不常使用的数据;
下图是一个简单的例子:
但是,如果直接在 Redis 中使用 LRU 算法也会有一些问题:
LRU 算法在实现过程中使用链表管理所有缓存的数据,这会给 Redis 带来额外的开销,而且,当有数据访问时就会有链表移动操作,进而降低 Redis 的性能。
于是,Redis 对 LRU 的实现进行了一些改变:
- 记录每个 key 最近一次被访问的时间戳(由键值对数据结构 RedisObject 中的 lru 字段记录)
- 在第一次淘汰数据时,会先随机选择 N 个数据作为一个候选集合,然后淘汰 lru 值最小的。(N 可以通过 config set maxmemory-samples 100 命令来配置)
- 后续再淘汰数据时,会挑选数据进入候选集合,进入集合的条件是:它的 lru 小于候选集合中最小的 lru。
- 如果候选集合中数据个数达到了 maxmemory-samples,Redis 就会将 lru 值小的数据淘汰出去。
LFU算法
LFU(Least Frequently Used)是根据数据的使用次数来进行缓存淘汰的,以此来保留常用的数据,同时淘汰不常使用的数据。
LFU 算法会维护一个使用次数列表,其中每个节点都是一个缓存对象。当对某个对象进行 get 操作时,该节点的使用次数会增加,因此需要更新节点在列表中的位置。当需要淘汰一个缓存对象时,LFU算法选择使用次数最少的缓存对象进行淘汰。
LFU算法的实现有两种方式:
- 一种是基于计数器的实现,即每次访问缓存对象时将计数器加一;
- 另一种是基于时间窗口的实现,即将每个缓存对象的访问时间存储下来,然后统计在一段时间窗口内访问次数最少的缓存对象进行淘汰。
LFU算法相对于LRU算法,能更好地反映缓存对象的使用次数和频率,因此在一些场景下,例如热点数据缓存、广告推荐系统等,LFU算法更能够提高缓存的命中率,并且可以更好地满足业务需求。但是,LFU算法的实现较为复杂,需要维护使用次数列表,并且计算复杂度较高。因此,需要根据具体业务场景来选择合适的缓存淘汰算法。
为什么 Redis 有了 LRU 还需要 LFU
虽然 LRU 算法在大多数应用场景下都可以提供良好的缓存效果,但有一些场景下 LRU 算法的效果可能不太好,这时就需要使用 LFU 算法。
LRU 算法假设最近使用过的数据是有可能在近期再次使用的,因此最近被访问的数据不会被淘汰。然而,对于那些虽然使用频率很小,但是其访问之间的时间跨度很长,依然会在链表的头部,一直没有被淘汰,降低了整个缓存的效率。这种缓存中一些生命周期比较长但访问频次比较低的数据叫做“历史遗留数据”,LFU算法就是为了更好地处理这些数据。
LFU 算法会把访问次数最少的数据从缓存中淘汰,因此更适用于那些依赖访问频次而不是访问时间的数据场景,例如一些热门商品的热度排行榜,如果以 LRU 算法进行缓存,那么当热点商品长时间没有被访问时,就会被淘汰掉,使得热度排行榜的效果大打折扣。而LFU算法能够根据热度排行榜中的商品访问频次来淘汰数据,更能够体现数据的热度,使得缓存效果更加精确。
综上所述,LRU算法和LFU算法各有优缺点,可以根据具体的业务场景来选择实现缓存逻辑。而Redis既支持LRU算法,也支持LFU算法,因此它可以根据不同的业务场景选择不同的算法实现,以提供更加高效、精准的缓存服务。
四、小结
缓存过期策略和内存淘汰策略都是在缓存中用来管理缓存空间的重要策略。
在实际应用中,我们需要根据具体情况来选择合适的缓存管理策略,以确保程序能够达到最佳性能。同时,我们需要注意缓存过期和内存占用等问题,及时清除过期的缓存数据和淘汰不必要的缓存数据,以避免这些问题对程序性能和用户体验造成负面影响。