请回答数据结构【布隆过滤器&位图】

请回答数据结构【布隆过滤器&位图】
-
- 位图
-
- 抛砖引玉
- bitset
- 模拟实现bitset
-
- 基本结构
- set
- reset
- test
- 位图应用
- 布隆过滤器
-
- Intro of BloomFilter
- 布隆过滤器实例
-
- 实例一
- 实例二
- 布隆过滤器思想
-
- 误判
- 什么时候会产生误判
- 多少位更好
- 删除支持吗?
- 实现Bloom filter
-
- 基本结构
- set
- test
- Hash
- 测试Bloom filter
- 布隆过滤器分析
-
- 优点
- 缺点
- 使用前提
- 位图
-
- 给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中
- 给定100亿个整数,设计算法找到只出现一次的整数?
- 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
- 1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
- 海量数据处理(非常规数据结构)
-
- 给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法
-
- 精确算法
- 近似算法
- 如何扩展BloomFilter使得它支持删除元素的操作
- 哈希切割
-
- 想法
- 给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
- 与上题条件相同,如何找到top K的IP?
布隆过滤器和位图都是哈希的一些应用
位图
抛砖引玉
通过一道面试题引出位图
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。【腾讯】
想法:
⚡️ 遍历,时间复杂度O(N)
⚡️ 排序(O(NlogN)),利用二分查找: logN
问题在于40亿个数据的话,内存放不下。总共16G,效率还可以,但是内存消耗不可
⚡️ 放到set或者是unordered_set,再查找
红黑树消耗更大,这不太合适,一下子膨胀了五倍,一堆指针的消耗都不合适,效率还可以,但是内存消耗不可
⚡️ 位图解决
数据是否在给定的整形数据中,结果是在或者不在,刚好是两种状态,那么可以使用一个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,代表存在,为0代表不存在。
比如:这样的话用一个位映射一个位置,一个无符号整数,注意一定要是无符号整数,那么一个五五好整数就是4个字节,32个位,那如果我们用232个位进行映射的话,相当于内存就是500MB,所以说这个情况不仅省内存而且是极快的,是一个直接定址法

bitset
位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的。

bitset 是一个 bool 数组,但每个布尔值不是单独存储的,而是 bitset 优化空间,使得每个 bool 只占用 1 位空间,因此bitset bs 占用的空间小于 bool bs[N] 和vector bs(N)。但是,bitset 的一个限制是,N 必须在编译时已知,即一个常数(vector和动态数组不存在此限制)
bitset是一种直接定址法的Hash
模拟实现bitset

这里面为了实现可以定制不确定长度的bitset,我们使用了模板中放一个N,然后用vector作为底层结构
基本结构
template<size_t N>
class bitset
{
public:
bitset()
{
_bits.resize(N / 32 + 1, 0);//向上取整
}
private:
vector<int> _bits;
};
set
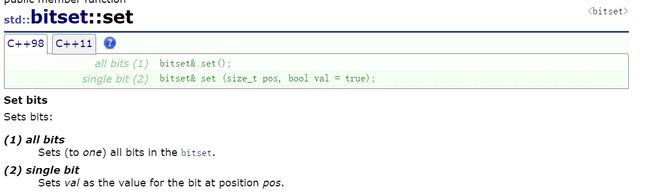
和1或就是强制将该位置变为1,那就是其他位置和0或,目标位置和1或
//把映射的位标记成1
void Set(size_t x)
{
assert(x < N);
// 算出x映射的位在第i个整数
// 算出x映射的位在这个整数的第j个位
size_t i = x / 32;
size_t j = x % 32;
//_bits[i] 的第j位标记成1
_bits[i] |= (1 << j);
}
reset
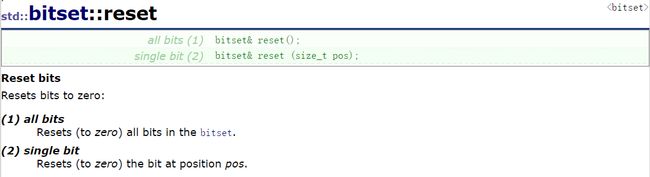
和0与就是强制将该位置变为0,那就是其他位置和1与,目标位置和0与
void Reset(size_t x)
{
assert(x < N);
// 算出x映射的位在第i个整数
// 算出x映射的位在这个整数的第j个位
size_t i = x / 32;
size_t j = x % 32;
//_bits[i] 的第j位标记成0
_bits[i] &= (~(1<<j));
}
test

探测某一位是1就返回真,是0就返回假,那就是其他位置和0与,目标位置和1与
bool Test()
{
assert(x < N);
size_t i = x / 32;
size_t j = x % 32;
//只判断不改变
// 如果第j位是1,结果是非0,非0就是真
// 如果第j为是0,结果是0,0就是假
return _bits[i] & (1 << j);
}
位图应用
- 快速查找某个数据是否在一个集合中
- 排序 + 去重
- 求两个集合的交集、并集等
- 操作系统中磁盘块标记
布隆过滤器
Intro of BloomFilter
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
实际上就是一个位图的变形和延申,位图的优点就是节省空间和快,但是缺点是只能处理整形,所以说布隆过滤器就是解决了这个问题,可以针对字符串等等更加复杂的类型,又快又节省空间
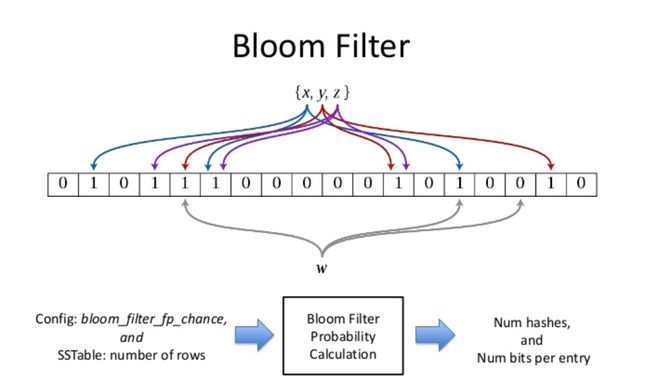
布隆过滤器实例
实例一
假设您正在 Github 上创建一个帐户,您想输入一个很酷的用户名,您输入它并收到一条消息,“用户名已被占用”。您在用户名中添加了您的出生日期,然而运气不佳,还是重名。现在你也添加了你的学号,却仍然得到“用户名已经被占用”。这真的很令人沮丧,不是吗?
但是你有没有想过 Github 通过搜索数百万注册的用户名来检查用户名的可用性有多快。
其实有很多方法可以完成这个需求
⚡️ 线性搜索:坏主意!
⚡️ Binary Search:按字母顺序存储所有用户名,并将输入的用户名与列表中的中间一个进行比较,如果匹配,则取用户名,否则计算输入的用户名是在中间名之前还是之后,如果在之后,忽略所有在中间之前的用户名。并重复这个过程,直到你得到一个匹配或没有匹配的搜索结束。这种技术更好,更有前途,但仍然需要多个步骤。
⚡️ 而Bloom Filter是一种可以完成这项工作的数据结构,而且更好
实例二
来自于StackOverflow的例子
假设我在 Chrome 团队中为 Google 工作,我想向浏览器添加一个功能,如果他输入的 URL 是恶意 URL,它会通知用户。所以我有一个包含大约 100 万个恶意 URL 的数据集,这个文件的大小约为 25MB。由于大小相当大(与浏览器本身的大小相比很大),我将这些数据存储在远程服务器上。
⚡️ 我使用带有哈希表的哈希函数。我决定使用一个高效的Hash函数,并通过Hash函数运行所有 100 万个 url 以获取散列键。然后,我制作了一个哈希表(一个数组),其中哈希键将为我提供放置该 URL 的索引。所以现在一旦我散列并填充了Hash表,我检查它的大小。我已将所有 100 万个 URL 及其密钥存储在哈希表中。所以大小至少为 25 MB。这个哈希表,由于它的大小,将存储在远程服务器上。当用户出现并在地址栏中输入 URL 时,我需要检查它是否是恶意的。因此,我通过哈希函数运行 URL(浏览器本身可以执行此操作)并获得该 URL 的哈希键。我现在必须使用该哈希键向我的远程服务器发出请求,检查我的哈希表中的特定 URL 是否与用户输入的相同。如果是,那么它是恶意的,如果不是,那么它不是恶意的。因此,每次用户输入 URL 时,都必须向远程服务器发出请求以检查它是否是恶意 URL。这将花费大量时间,从而使我的浏览器变慢。
⚡️ 我使用布隆过滤器。100 万个 URL 的整个列表使用多个散列函数通过布隆过滤器运行,并且各自的位置标记为 1,在一个巨大的 0 数组中。假设我们想要 1% 的误报率,使用布隆过滤器计算器 ,我们得到所需的布隆过滤器大小仅为 1.13 MB。这个小尺寸是预期的,因为即使数组的大小很大,我们也只存储 1 或 0,而不像哈希表那样存储 URL。这个数组可以被视为一个位数组。也就是说,由于我们只有两个值 1 和 0,我们可以设置单个位而不是字节。这将使占用的空间减少 8 倍。这个 1.13 MB 的布隆过滤器,由于其体积小,可以存储在网络浏览器本身!因此,当用户出现并输入 URL 时,我们只需应用所需的哈希函数(在浏览器本身中),并检查布隆过滤器(存储在浏览器中)中的所有位置。任何位置的值 0 都告诉我们此 URL 绝对不在恶意 URL 列表中,用户可以自由继续。因此,我们没有调用服务器,从而节省了时间。值 1 告诉我们该 URL 可能在恶意 URL 列表中。在这些情况下,我们调用远程服务器,在那里我们可以像第一种情况一样使用带有哈希表的其他哈希函数来检索并检查 URL 是否实际存在。由于大多数情况下,一个 URL 不太可能是恶意 URL,浏览器中的小型布隆过滤器会发现这一点,从而通过避免调用远程服务器来节省时间。只有在某些情况下,如果布隆过滤器告诉我们 URL 可能是恶意的,只有在这些情况下,我们才会调用服务器。这个“可能”是 99% 正确的。在这些情况下,我们调用远程服务器,在那里我们可以像第一种情况一样使用带有哈希表的其他哈希函数来检索并检查 URL 是否实际存在。由于大多数情况下,一个 URL 不太可能是恶意 URL,浏览器中的小型布隆过滤器会发现这一点,从而通过避免调用远程服务器来节省时间。只有在某些情况下,如果布隆过滤器告诉我们 URL 可能是恶意的,只有在这些情况下,我们才会调用服务器。这个“可能”是 99% 正确的。在这些情况下,我们调用远程服务器,在那里我们可以像第一种情况一样使用带有哈希表的其他哈希函数来检索并检查 URL 是否实际存在。由于大多数情况下,一个 URL 不太可能是恶意 URL,浏览器中的小型布隆过滤器会发现这一点,从而通过避免调用远程服务器来节省时间。只有在某些情况下,如果布隆过滤器告诉我们 URL 可能是恶意的,只有在这些情况下,我们才会调用服务器。这个“可能”是 99% 正确的。浏览器中的小布隆过滤器可以解决这个问题,因此通过避免调用远程服务器来节省时间。只有在某些情况下,如果布隆过滤器告诉我们 URL 可能是恶意的,只有在这些情况下,我们才会调用服务器。这个“可能”是 99% 正确的。浏览器中的小布隆过滤器可以解决这个问题,因此通过避免调用远程服务器来节省时间。只有在某些情况下,如果布隆过滤器告诉我们 URL 可能是恶意的,只有在这些情况下,我们才会调用服务器。这个“可能”是 99% 正确的。
因此,通过在浏览器中使用小型布隆过滤器,我们节省了大量时间,因为我们不需要为输入的每个 URL 进行服务器调用。
布隆过滤器思想
误判
针对字符串和复杂类型的话,如何实现?
使用BKDR法可以将字符串转换为Hash,但是还是可能会产生哈希冲突,也就是不同的字符串转成了相同的整形,那么就会产生误判
例如,检查用户名的可用性是设置成员资格问题,其中设置是所有注册用户名的列表。我们为效率付出的代价是它本质上是概率性的,这意味着可能会有一些误报结果。误报意味着,它可能表明给定的用户名已经被使用,但实际上并没有。
由此布隆解决出发点是,这个问题能不能降低误判概率呢?每个值映射一个位容易冲突,映射多位可能就不冲突了?
虽然减少了冲突但是,但是会造成不良后果
什么时候会产生误判
| Situation | 误判 | 准确与否 |
|---|---|---|
| 判断昵称用过 | ✔️ | 不准确 |
| 判断昵称没用过 | ❌ | 准确 |
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因为有些哈希函数存在一定的误判。
比如:在布隆过滤器中查找"言之命至"时,假设3个哈希函数计算的哈希值为:1、3、7,刚好和其他元素的比特位重叠,此时布隆过滤器告诉该元素存在,但是该元素是不存在的。
多少位更好
所以说有人专门计算了要开多少位才会合适一点https://zhuanlan.zhihu.com/p/43263751
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率
m = − n ln p ( ln 2 ) 2 k = m n ln 2 m=-\frac{n\ln p}{(\ln2)^2}\\k=\frac{m}{n}\ln2 m=−(ln2)2nlnpk=nmln2
我们这里估计一下ln2约等于0.7,k这里我们算成3个,m约等于4,相当于平均给一个数,我们要开4个位置,那么也就是说10亿个字符串,就开40亿个位
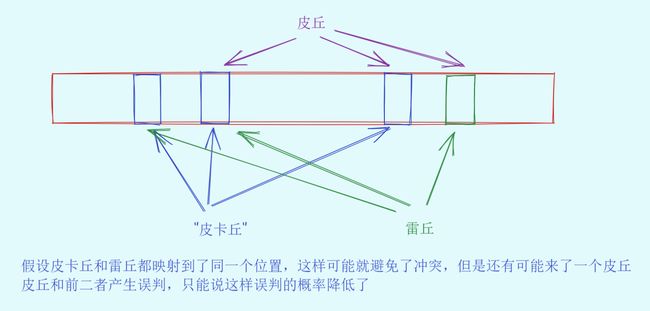
删除支持吗?
布隆过滤器不能直接支持删除工作(当然用到删除的地方确实也不是很多),因为在删除一个元素时,可能会影响其他元素。
比如:删除下图中"皮卡丘"元素,如果直接将该元素所对应的二进制比特位进行置0,“皮丘”元素和"雷丘元素"也被删除了,因为这两个元素在多个哈希函数计算出的比特位上刚好有重叠。
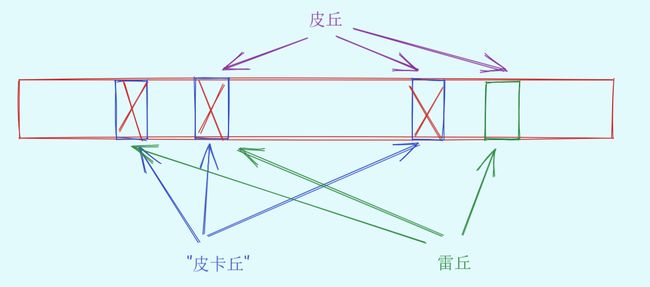
就是说皮卡丘删除了之后影响了雷丘和皮丘的公用位,从而产生了问题
一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。
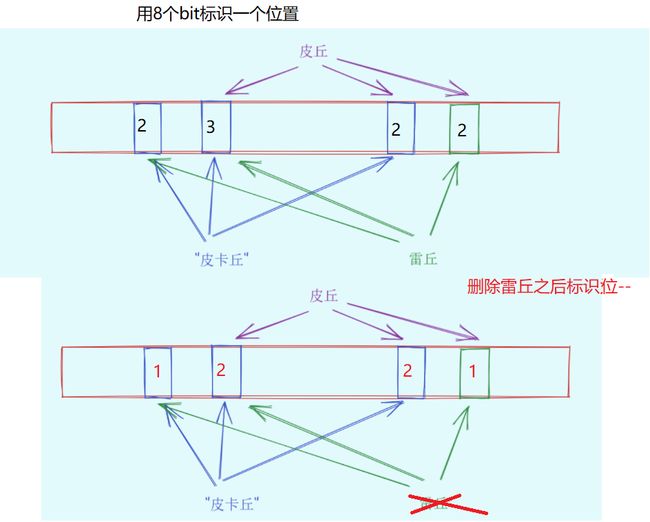
选用几个bit来表示一个位置是个玄学问题
缺陷:
- 无法确认元素是否真正在布隆过滤器中
- 存在计数回绕
实现Bloom filter
基本结构
Bloom filter需要之前写好的bitset
template<size_t N, class Hash1, class Hash2, class Hash3,class K = string>
class Bloomfilter
{
public:
private:
bitset<N> _bitset;
};
set
void Set(const K& key)
{
//Hash1 hf1;
//size_t i1 = hf1(key);
//两步合一步,直接用匿名对象写
size_t i1 = Hash1()(key) % N;
size_t i2 = Hash2()(key) % N;
size_t i3 = Hash3()(key) % N;
cout << i1 << " " << i2 << " " << i3 << endl;
//对一个key采用三种Hash函数进行映射,并放到位图中
_bitset.Set(i1);
_bitset.Set(i2);
_bitset.Set(i3);
}
test
bool Test(const K& key)
{
size_t i1 = Hash1()(key) % N;
if (_bitset.Test(i1) == false)
{
return false;
}
size_t i2 = Hash2()(key) % N;
if (_bitset.Test(i2) == false)
{
return false;
}
size_t i3 = Hash3()(key) % N;
if (_bitset.Test(i3) == false)
{
return false;
}
// 这里3个位都在,有可能是其他key占了,在是不准确的,存在即误判
// 不在是准确的
return true;
}
Hash
选取之前有大佬归纳和发明的高效率的三种Hash函数
struct HashBKDR
{
size_t operator()(const std::string& s)
{
// BKDR Hash
size_t value = 0;
for (auto ch : s)
{
value += ch;
value *= 131;
}
return value;
}
};
struct HashAP
{
size_t operator()(const std::string& s)
{
// AP Hash
register size_t hash = 0;
size_t ch;
for (long i = 0; i < s.size(); i++)
{
ch = s[i];
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ ch ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
}
return hash;
}
};
struct HashDJB
{
size_t operator()(const std::string& s)
{
// BKDR Hash
register size_t hash = 5381;
for (auto ch : s)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
到这里基本上布隆就写好了
测试Bloom filter
误判率高了就可以提高Bloom filter的大小,这样就会降低
首先为了制造冲突,我们采取如下方法,这里的输出肯定全是1
void TestBloomfilter()
{
Bloomfilter<500> bf;
size_t N = 100;
std::vector<std::string> v1;
//搞出一堆字符串
for (size_t i = 0; i < N; ++i)
{
std::string url = "https://blog.csdn.net/Allen9012?spm=1000.2115.3001.5343";
url += std::to_string(1234 + i);
v1.push_back(url);
}
//Set进去
for (auto& str : v1)
{
bf.Set(str);
}
//看在不在
for (auto& str : v1)
{
cout << bf.Test(str) << endl;
}
cout << endl << endl;
}
OK,下面继续操作一下,我们来一个vetcor v2,然后同样的前缀稍微修改一下后缀,Test一下只要出1的话就说明误判了,然后写一个看看相似字符串的误判率计算,最直观
std::vector<std::string> v2;
for (size_t i = 0; i < N; ++i)
{
std::string url = "https://blog.csdn.net/Allen9012?spm=1000.2115.3001.5343";
url += std::to_string(6789 + i);
v2.push_back(url);
}
size_t n2 = 0;
for (auto& str : v2)
{
if (bf.Test(str))
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
下面继续加码,用我的Github地址作为url,这次不是修改后缀,而是修改网址,作为不想死字符串的误判率
std::vector<std::string> v3;
for (size_t i = 0; i < N; ++i)
{
std::string url = "https://github.com/Allen9012";
url += std::to_string(6789 + i);
v3.push_back(url);
}
size_t n3 = 0;
for (auto& str : v3)
{
if (bf.Test(str))
{
++n3;
}
}
cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;

布隆过滤器分析
优点
增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
哈希函数相互之间没有关系,方便硬件并行运算
布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
使用同一组散列函数的布隆过滤器可以进行交、并、差运算
缺点
有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存储可能会误判的数据)
不能获取元素本身
一般情况下不能从布隆过滤器中删除元素
如果采用计数方式删除,可能会存在计数回绕问题
使用前提
能够容许误判
扫描恶意网站,需要快速判断
数据库有没有该数据(e.g. 系统所有用户的电话号码表)磁盘,需要快速判断(注册,在提交的时候需要提示手机号是否注册过)
1.如果这个手机号不在布隆过滤器中,那么他一定不在数据库中
2.如果怕这个手机号在布隆过滤器,那么可能存在误判,那就再查依次数据库复核(数据库中的遍历,效率不是很低,但是肯定没有布隆快)
##海量数据处理
位图
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中
此时再去尝试那道题目,先用我们的bitset开对应最大空间的量也就是4294967295,注意不是4294967296,如果实在记不住就写成-1,因为-1转成无符号数就是这个最大值
void Test_bitset()
{
//bitset<4294967295u> bs;
bitset<-1> bs;
/// 给定100亿个整数,设计算法找到只出现一次的整数?
位图的变形,map内存是不够的,现在的难题是需要标记的是
方法一:改造位图的存储方式为2位1标记
-
出现0次
-
出现1次
-
出现2次
| Situation | 标记 |
|---|---|
| 出现0次 | 00 |
| 出现1次 | 01 |
| 出现2次 | 10 |
把所有的位图的/32变成/16就可以把标记写成2位了
方法二:不用改造,用2个位图,给一个Set方法
void Set2_of_bitset(size_t x)
{
//00 -> 01
if (! _bs1.Test(x) && _bs1.Test(x))
{
_bs1.Set(x);
}
//01 -> 10
else if(!_bs1.Test(x) && _bs2.Test(x))
{
_bs1.Set(x);
_bs2.ReSet(x);
}
//10->10
else if (_bs1.Test(x) && !_bs2.Test(x))
{
//不处理
}
else
{//不可以有11
assert(false);
}
最后遍历位图就找到只出现一次的整数了
给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
暴力求解,把第一个文件中的所有整数标记映射到位图,100亿中有很多整数是重复的,所以空间是够的,再读取另一个文件的所有整数,判断在不在位图,在就是交集中的数,不在就不是
依次读取第一个文件的所有整数标记映射为位图1,依次读取第二个文件的所有整数标记映射为位图2,再对这两个位图与到一起(依次与位图中的整数),与完之后,还是1的位映射的整数就是交集
1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
| Situation | 标记 |
|---|---|
| 出现0次 | 00 |
| 出现1次 | 01 |
| 出现2次 | 10 |
| 出现3次及以上 | 11 |
还是和第二题一样的做法
void Set1_of_bitset(size_t x)
{
//00 -> 01
if (!_bs1.Test(x) && _bs1.Test(x))
{
_bs1.Set(x);
}
//01 -> 10
else if (!_bs1.Test(x) && _bs2.Test(x))
{
_bs1.Set(x);
_bs2.ReSet(x);
}
//10->111
else if (_bs1.Test(x) && !_bs2.Test(x))
{
_bs2.Set(x);
}
else
{
//do nothing
}
}
最后遍历位图就知道出现次数不超过2次的所有整数了
海量数据处理(非常规数据结构)
给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法
精确算法
见哈希切分
近似算法
近似算法就是允许一些误判
使用布隆过滤器,分别先把其中一个文件映射到布隆过滤器,然后用另外一个文件来看看在不在这个布隆过滤器中
如何扩展BloomFilter使得它支持删除元素的操作
这个删除之前有提到
哈希切割
之前出现的所有问题都可以用哈希切分来做,只不过没有位图和布隆效率那么高
想法
还是这道题目来看
给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法


只需要将这些如A0和B0之间互相找交集就可以了,就可以算出总共的交集了,那为什么这样能把所有的交集都给找出来呢?
因为哈希切分可以使得相同的query分别进入Ai和Bi等下标相同的小文件中
给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?

次数统计出来了,那么就已经找到出现次数最多的IP地址了
与上题条件相同,如何找到top K的IP?
找到出现次数前几次TopK问题,肯定是建K个数的小堆,然后后面的每一个数都比较一下,大的就进去替换最小的,然后依次比完,剩下的就是最大的几个数了
Github地址相关代码:
https://github.com/Allen9012/cpp/tree/main/%E9%AB%98%E9%98%B6%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/Bitset
https://github.com/Allen9012/cpp/tree/main/%E9%AB%98%E9%98%B6%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/BloomFilter