SparkSQL 数据的读取和保存
一、通用的加载和保存方式
SparkSQL提供了通用的保存数据和数据加载的方式。这里的通用指的是使用相同的API,根据不同的参数读取和保存不同格式的数据,SparkSQL默认读取和保存的文件格式为parquet。
1)加载数据
spark.read.load是加载数据的通用方法
scala> spark.read.
csv format jdbc json load option options orc parquet schema table text textFile
如果读取不同格式的数据,可以对不同的数据格式进行设定
➢format("…"):指定加载的数据类型,包括"csv"、“jdbc”、“json”、“orc”、“parquet"和"textFile”。
➢load("…"):在"csv"、“jdbc”、“json”、“orc”、“parquet"和"textFile"格式下需要传入加载数据的路径。
➢option(”…"):在"jdbc"格式下需要传入JDBC相应参数,url、user、password和dbtable我们前面都是使用read API 先把文件加载到DataFrame然后再查询,其实,我们也可以直接在文件上进行查询: 文件格式.文件路径
1、读取本地parquet文件
scala> val df = spark.read.load("examples/src/main/resources/users.parquet")
res2: org.apache.spark.sql.DataFrame = [name: string, favorite_color: string ... 1 more field]
scala> df.show
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
2、保存parquet文件(默认)
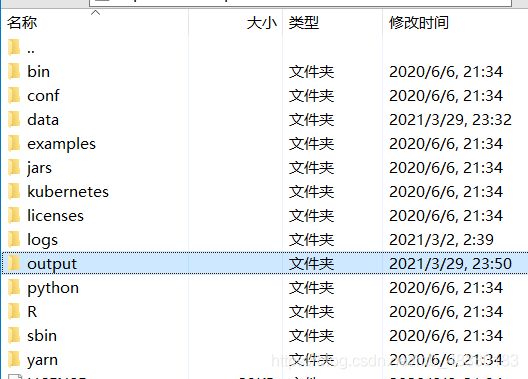
scala> df.write.save("output")
刷新,会多出一个output文件出来
3、读取json文件
scala> val df = spark.read.format("json").load("data/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
scala> df.show
+---+-------------+
|age| username|
+---+-------------+
| 30|zhangxiaoming|
| 24| zhouxiaolian|
| 23| lixiaohua|
| 26| wangxiaoli|
| 22| chenxiaoyan|
+---+-------------+
或者
scala> val df = spark.read.json("data/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
scala> df.show
+---+-------------+
|age| username|
+---+-------------+
| 30|zhangxiaoming|
| 24| zhouxiaolian|
| 23| lixiaohua|
| 26| wangxiaoli|
| 22| chenxiaoyan|
+---+-------------+
//又或者
scala> spark.sql("select * from json.`/opt/module/spark-local/data/user.json`").show
21/03/30 00:35:50 WARN ObjectStore: Failed to get database json, returning NoSuchObjectException
+---+-------------+
|age| username|
+---+-------------+
| 30|zhangxiaoming|
| 24| zhouxiaolian|
| 23| lixiaohua|
| 26| wangxiaoli|
| 22| chenxiaoyan|
+---+-------------+
4、保存json文件
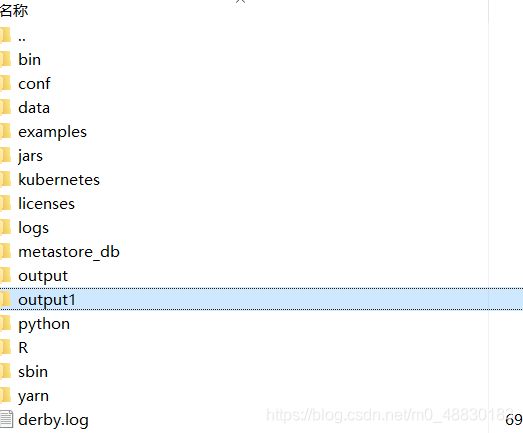
scala> df.write.format("json").save("output1")
 2)保存数据df.write.save是保存数据的通用方法
2)保存数据df.write.save是保存数据的通用方法
scala>df.write.csv jdbc json orc parquet textFile… …
如果保存不同格式的数据,可以对不同的数据格式进行设定
scala>df.write.format("…")[.option("…")].save("…")
➢format("…"):指定保存的数据类型,包括"csv"、“jdbc”、“json”、“orc”、“parquet"和"textFile”。
➢save ("…"):在"csv"、“orc”、“parquet"和"textFile"格式下需要传入保存数据的路径。
➢option(”…"):在"jdbc"格式下需要传入JDBC相应参数,url、user、password和dbtable保存操作可以使用SaveMode, 用来指明如何处理数据,使用mode()方法来设置。有一点很重要: 这些SaveMode 都是没有加锁的, 也不是原子操作。
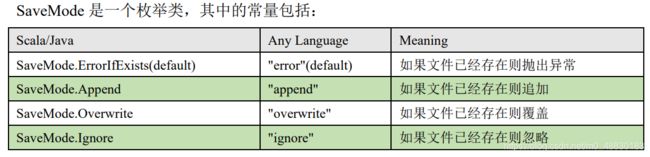
scala>df.write.mode("append").json("/opt/module/data/output")
//追加在后面
scala> df.write.format("json").mode("append")save("output")
//覆盖掉
scala> df.write.format("json").mode("overwrite")save("output")
//忽略已存在的
scala> df.write.format("json").mode("ignore")save("output")
5、json
Spark SQL 能够自动推测JSON数据集的结构,并将它加载为一个Dataset[Row]. 可以通过SparkSession.read.json()去加载JSON 文件。
1)导入隐式转换
import spark.implicits._
6、CSV
Spark SQL可以配置CSV文件的列表信息,读取CSV文件,CSV文件的第一行设置为数据列。
scala> val df1 = spark.read.format("csv").option("sep", ";").option("inferSchema", "true").option("header", "true").load("examples/src/main/resources/people.csv")
df1: org.apache.spark.sql.DataFrame = [name: string, age: int ... 1 more field]
scala> df1.show
+-----+---+---------+
| name|age| job|
+-----+---+---------+
|Jorge| 30|Developer|
| Bob| 32|Developer|
+-----+---+---------+