Kaggle入门实战:Titanic - Machine Learning from Disaster
Kaggle入门实战:Titanic - Machine Learning from Disaster
- Titanic项目
-
- 关于数据
-
- 数据概括
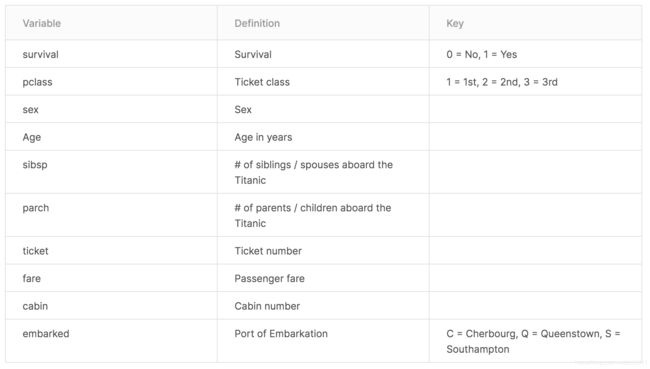
- 数据字段描述
- 官方教程代码
- 数据分析
-
- 总体思路
- 初步分析
-
- 数值型数据
- 属性型数据
- 特征工程
- 模型准备
- 不同模型对比 CV
-
- Naive Bayes
- Logistic Regression
- Decision Tree
- K Nearest Neighbor
- Random Forest
- Support Vector Classifier
- Xtreme Gradient Boosting
- Soft Voting Classifier
- 模型调参
-
- GridSearchCV(网格搜索)
- RandomizedSearch (随机搜索)
- 不同属性的重要性
- 基于调参后的模型进行集成学习
-
- 调整模型权重
- 预测结果并存储
- 写在最后
Titanic项目
Use machine learning to create a model that predicts which passengers survived the Titanic shipwreck.
基于机器学习建立模型预测泰坦尼克号灾难中哪些乘客得以生存。
p.s.本次练习主要在于熟悉数据分析项目流程、思考方式与实际操作,并未以达到最高准确率为目标
Kaggle入门项目:Titanic overview
参考分析视频:Beginner Kaggle Data Science Project Walk-Through (Titanic)
参考分析笔记:Titanic Project Example Walk Through
关于数据
数据概括
训练数据(training set):
含有关于乘客生存信息的数据,用来建立机器学习模型。建立模型模型时应基于训练数据中关于乘客年龄、客舱等级、亲属数等的属性(详情见数据字段描述)

测试数据(test set):
将模型运用于测试数据中并预测乘客生存与否,将根据上传的测试数据预测结果评判模型准确度
测试数据比训练数据只少了survived一列(需根据模型自行预测)
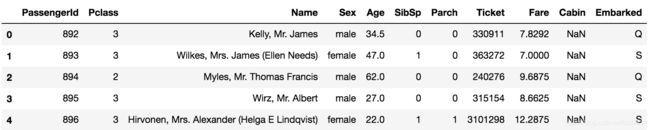
数据字段描述
官方教程代码
from sklearn.ensemble import RandomForestClassifier
y = train_data["Survived"]
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
predictions = model.predict(X_test)
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('my_submission.csv', index=False)
print("Your submission was successfully saved!")
按照上述代码运用随机森林得到的结果为0.77511
数据分析
总体思路
- 1.了解数据基本信息,使用 .info() .describe()
- 2.画图展现数据分布便于数据分析、特征分析 e.g.Histograms, boxplots
- 3.分析不同属性的值
- 4.分析不同属性之间的关联性
- 5.思考分析的主题,提出思考的问题
(例如对本次Titanic数据:生存与否与乘客性别有关?与乘客本人经济条件有关?与年龄有关?哪个港口登船的乘客更容易生存?) - 6.特征工程
- 7.处理缺失数据
- 8.整合训练数据和测试数据?
- 8.进行特征缩放 scaling?
- 9.建立模型
- 10.利用交叉验证 CV 对比模型效果
初步分析
import numpy as np
import pandas as pd
train_data = pd.read_csv('/kaggle/input/titanic/train.csv')
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
#查看训练数据相关信息
train_data.info()
训练数据信息如下:
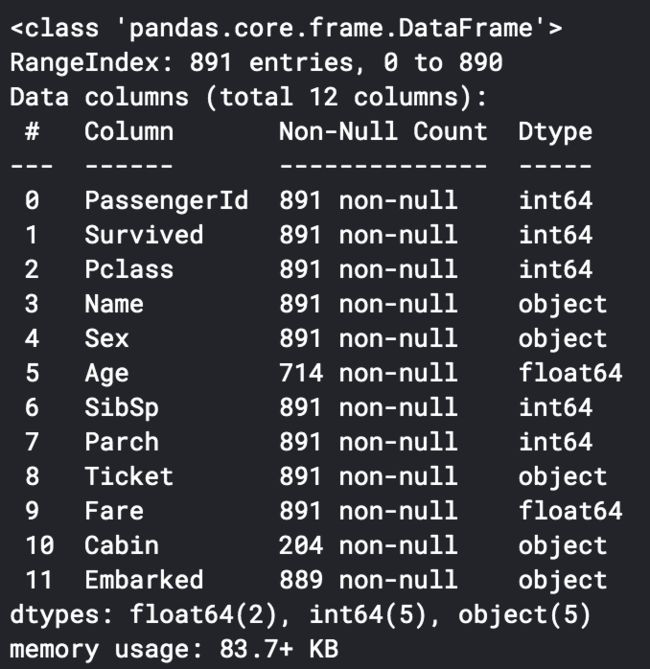
可以看出Age字段与Cabin字段有较多缺失数据,Embarked字段有2条缺失数据
#进一步查看数据的统计信息
train_data.describe()

数值型数据
针对数值型数据 (numeric data):
- 通过画矩形图了解数据分布情况(histogram)
- 画图探索不同数据的相关性
- 运用透视表比较生存率与不同变量之间的关系(pivot table)
import matplotlib.pyplot as plt
#提取数值型属性
df_num = train_data[['Age','SibSp','Parch','Fare']]
#画矩形图
for i in df_num.columns:
plt.hist(df_num[i])
plt.title(i)
plt.show()
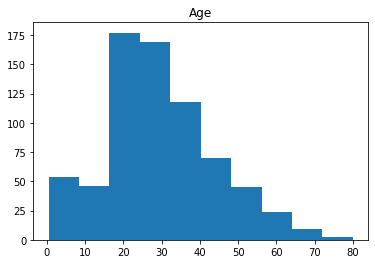



Age接近正态分布,其他三个属性无特殊分布。Fare属性值的分布较广,考虑在后期进行数据标准化(normalization)处理。
import seaborn as sns
# 画图探索不同数据的相关性
print(df_num.corr()) #相关系数
sns.heatmap(df_num.corr()) #使用热图查看相关系数分布情况
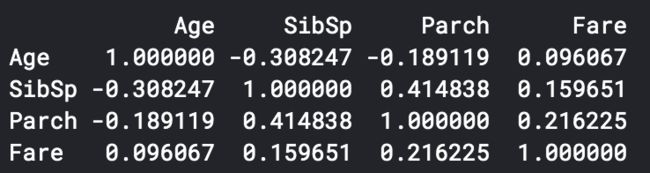

可以看出SibSp与Parch有一定的相关性,即家庭成员一起出游的可能性较大
(属性相关性分析在回归分析中很重要,因为要避免因为不同属性有较强相关性从而对模型造成影响)
# 用透视图观察存活率与同变量之间的关系
pd.pivot_table(train_data, index = 'Survived', values = ['Age','SibSp','Parch','Fare'])

对于Age属性,可以推测也许年轻的人有更大的概率生存
对于Fare属性,可以推测也许付钱更多的人有更大的概率生存
对于Parch属性,可以推测也许有父母小孩一同登船的人有更大概率生存
对于SibSp属性,可以推测也许有兄弟姐妹或配偶登船的人生存几率更小
补充:
关于pd.pivot_table 函数:pd.pivot_table(df,index=[“A”,“B”], values=[“C”])
按照index内的变量进行分组,再利用values定义关心的域,透视表默认计算列内数据的平均值
也可以通过(aggfunc= )函数列元素进行计数或求和:
pd.pivot_table(df,index=[“A”,“B”], values=[“C”], aggfunc=np.sum)
属性型数据
针对属性型数据( Categorical Data):
- 观察不同属性的分布情况(bar charts)
- 运用透视表比较生存率与不同变量之间的关系(pivot table)
df_cat = training[['Survived','Pclass','Sex','Ticket','Cabin','Embarked']]
#可以通过柱状图判断不同属性值的分布情况
for i in df_cat.columns:
sns.barplot(df_cat[i].value_counts().index,df_cat[i].value_counts()).set_title(i)
plt.show()
属性分布情况如下:
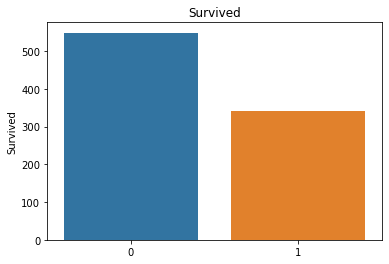

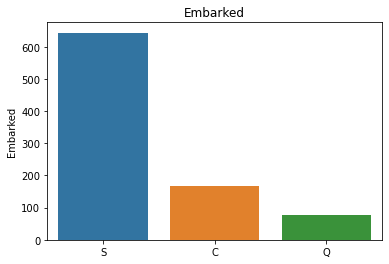
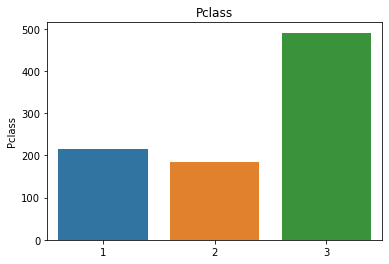


# 用透视图分析三个属性与是否生存之间的关系,此处使用了 aggfunc ='count' 方法
print(pd.pivot_table(train_data, index = 'Survived', columns = 'Pclass', values = 'Ticket' ,aggfunc ='count'))
print()
print(pd.pivot_table(train_data, index = 'Survived', columns = 'Sex', values = 'Ticket' ,aggfunc ='count'))
print()
print(pd.pivot_table(train_data, index = 'Survived', columns = 'Embarked', values = 'Ticket' ,aggfunc ='count'))
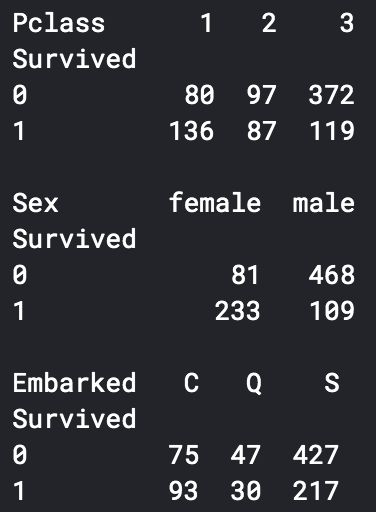
可以看出一等舱的乘客生存概率更大,女性生存概率更大,在S处登船的乘客生存概率更大
特征工程
1.对于Cabin属性:可以分析Cabin属性内值的个数(购票数)、Cabin属性的字母值(舱位号)与生存率之间是否有关联
df_cat.Cabin
#分析Cabin内值的个数,0代表Cabin属性为空,1代表有1个值,2代表有2个值
train_data['cabin_multiple'] = train_data.Cabin.apply(lambda x: 0 if pd.isna(x) else len(x.split(' ')))
train_data['cabin_multiple'].value_counts()
结果如下:
0 687
1 180
2 16
3 6
4 2
#运用透视表分析Cabin值的个数与存活率的关系
pd.pivot_table(train_data, index = 'Survived', columns = 'cabin_multiple', values = 'Ticket' ,aggfunc ='count')

#增加cabin_adv属性表示Cabin字母值
train_data['cabin_adv'] = train_data.Cabin.apply(lambda x: str(x)[0])
print(train_data.cabin_adv.value_counts())
结果如下:其中n代表值为null,此处将缺失值(null)作为一类进行进行分析
n 687
C 59
B 47
D 33
E 32
A 15
F 13
G 4
T 1
#利用透视表分析Cabin字母值与存活率的关系
pd.pivot_table(train_data,index='Survived',columns='cabin_adv', values = 'Name', aggfunc='count')

可以看出没有Cabin值的多数乘客未能生存,有特定Cabin值的乘客存活率更高
2.对于Ticket属性:分为单纯数字的票号和非数字(含字母)的票号:
#纯数字的票号numeric_ticket=1
train_data['numeric_ticket'] = train_data.Ticket.apply(lambda x: 1 if x.isnumeric() else 0)
train_data['numeric_ticket'].value_counts()
结果如下:
1 661
0 230
3.对于Ticket属性:分为单纯数字的票号和非数字(含字母)的票号:
模型准备
1.选取保留的属性(去除姓名、乘客编号),更改进行特征工程时分析的属性,保留属性:‘Pclass’, ‘Sex’,‘Age’, ‘SibSp’, ‘Parch’, ‘Fare’, ‘Embarked’, ‘cabin_adv’, ‘cabin_multiple’, ‘numeric_ticket’
2.对训练和测试数据进行特征转换(只用于此次Kaggle比赛项目,实际操作中不建议训练与测试数据一起)
3.删除Embarked中含缺失值的数据(从前面分析已知只有两条数据)
4.填充缺失值
5.对数据进行标准化处理
操作代码如下:
#合并训练和测试数据为 all_data,用Na填充测试数据的Survived属性
train_data['train_test'] = 1
test_data['train_test'] = 0
test_data['Survived'] = np.NaN
all_data = pd.concat([train_data,test_data])
#对训练和测试数据进行特征转换(进行特征工程时使用的属性)
all_data['cabin_multiple'] = all_data.Cabin.apply(lambda x: 0 if pd.isna(x) else len(x.split(' ')))
all_data['cabin_adv'] = all_data.Cabin.apply(lambda x: str(x)[0])
all_data['numeric_ticket'] = all_data.Ticket.apply(lambda x: 1 if x.isnumeric() else 0)
#删除Embarked中含缺失值的两条数据
all_data.dropna(subset=['Embarked'],inplace = True)
#用均值填充Age Fare中的缺失值
all_data.Age = all_data.Age.fillna(train_data.Age.mean())
all_data.Fare = all_data.Fare.fillna(train_data.Fare.mean())
#对Fare属性进行log函数转换,转换后的值分布接近正态分布
all_data['norm_fare'] = np.log(all_data.Fare+1)
all_data['norm_fare'].hist()
all_data.Pclass = all_data.Pclass.astype(str)
#created dummy variables from categories (also can use OneHotEncoder)
all_dummies = pd.get_dummies(all_data[['Pclass','Sex','Age','SibSp','Parch','norm_fare','Embarked','cabin_adv','cabin_multiple','numeric_ticket','train_test']])
#Split to train test again
X_train = all_dummies[all_dummies.train_test == 1].drop(['train_test'], axis =1)
X_test = all_dummies[all_dummies.train_test == 0].drop(['train_test'], axis =1)
y_train = all_data[all_data.train_test==1].Survived
#Scale Data
from sklearn.preprocessing import StandardScaler
scale = StandardScaler()
all_dummies_scaled = all_dummies.copy()
all_dummies_scaled[['Age','SibSp','Parch','norm_fare']]= scale.fit_transform(all_dummies_scaled[['Age','SibSp','Parch','norm_fare']])
#.fit_transform 不仅计算训练数据的均值和方差,还会基于计算出来的均值和方差来转换训练数据,从而把数据转换成标准的正太分布
X_train_scaled = all_dummies_scaled[all_dummies_scaled.train_test == 1].drop(['train_test'], axis =1)
X_test_scaled = all_dummies_scaled[all_dummies_scaled.train_test == 0].drop(['train_test'], axis =1)
y_train = all_data[all_data.train_test==1].Survived
不同模型对比 CV
from sklearn.model_selection import cross_val_score
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import LogisticRegression
from sklearn import tree
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
对几种模型进行交叉验证判断准确率,但是交叉验证的结果并不代表模型用于测试数据时的准确率结果
Naive Bayes
#naive bayes
gnb = GaussianNB()
cv = cross_val_score(gnb,X_train_scaled,y_train,cv=5)
print(cv)
print(cv.mean())
#[0.67977528 0.6741573 0.71910112 0.73595506 0.79096045]
#0.7199898432044689
Logistic Regression
# logistic regression
lr = LogisticRegression(max_iter = 2000)
cv = cross_val_score(lr,X_train,y_train,cv=5)
print(cv)
print(cv.mean())
#[0.78651685 0.80337079 0.78089888 0.79775281 0.82485876]
#0.7986796165809688
lr = LogisticRegression(max_iter = 2000)
cv = cross_val_score(lr,X_train_scaled,y_train,cv=5)
print(cv)
print(cv.mean())
#[0.78089888 0.80337079 0.78089888 0.79775281 0.82485876]
#0.7975560210753507
Decision Tree
# decision tree
dt = tree.DecisionTreeClassifier(random_state = 1)
cv = cross_val_score(dt,X_train,y_train,cv=5)
print(cv)
print(cv.mean())
#[0.73033708 0.76966292 0.83146067 0.74157303 0.84180791]
#0.7829683234939376
dt = tree.DecisionTreeClassifier(random_state = 1)
cv = cross_val_score(dt,X_train_scaled,y_train,cv=5)
print(cv)
print(cv.mean())
#[0.7247191 0.76404494 0.83146067 0.74157303 0.83615819]
#0.7795911889798768
K Nearest Neighbor
#k nearest neighbor
knn = KNeighborsClassifier()
cv = cross_val_score(knn,X_train,y_train,cv=5)
print(cv)
print(cv.mean())
#[0.78089888 0.78651685 0.74719101 0.79775281 0.82485876]
#0.787443661524789
knn = KNeighborsClassifier()
cv = cross_val_score(knn,X_train_scaled,y_train,cv=5)
print(cv)
print(cv.mean())
#[0.76404494 0.79213483 0.79775281 0.80337079 0.83050847]
#0.7975623690725576
Random Forest
#random forest
rf = RandomForestClassifier(random_state = 1)
cv = cross_val_score(rf,X_train,y_train,cv=5)
print(cv)
print(cv.mean())
#[0.79213483 0.80898876 0.85393258 0.74157303 0.84180791]
#0.8076874246175331
rf = RandomForestClassifier(random_state = 1)
cv = cross_val_score(rf,X_train_scaled,y_train,cv=5)
print(cv)
print(cv.mean())
#[0.79213483 0.80898876 0.85393258 0.74719101 0.84180791]
#0.8088110201231512
Support Vector Classifier
#Support Vector Classifier
svc = SVC(probability = True)
cv = cross_val_score(svc,X_train_scaled,y_train,cv=5)
print(cv)
print(cv.mean())
#[0.81460674 0.82022472 0.82022472 0.80337079 0.84180791]
#0.8200469751793309
Xtreme Gradient Boosting
#Xtreme Gradient Boosting
from xgboost import XGBClassifier
xgb = XGBClassifier(random_state =1)
cv = cross_val_score(xgb,X_train_scaled,y_train,cv=5)
print(cv)
print(cv.mean())
#[0.76404494 0.80337079 0.87078652 0.82022472 0.82485876]
#0.8166571446708563
Soft Voting Classifier
#Soft Voting Classifier - All Models
#Voting classifier takes all of the inputs and averages the results. For a "hard" voting classifier each classifier gets 1 vote "yes" or "no" and the result is just a popular vote.
#A "soft" classifier averages the confidence of each of the models. If a the average confidence is > 50% that it is a 1 it will be counted as such
from sklearn.ensemble import VotingClassifier
voting_clf = VotingClassifier(estimators = [('lr',lr),('knn',knn),('rf',rf),('gnb',gnb),('svc',svc),('xgb',xgb)], voting = 'soft')
cv = cross_val_score(voting_clf,X_train_scaled,y_train,cv=5)
print(cv)
print(cv.mean())
#[0.8258427 0.81460674 0.8258427 0.79775281 0.84745763]
#0.8223005141877738
模型调参
一般主要使用GridSearch 网格搜索和 RandomizedSearch 随机搜索方法进行调参
GridSearchCV(网格搜索)
进行自动调参,输入参数后,将通过尝试所有参数得出最优化的结果和参数
缺点:适用于较小数据集,不一定得到全局最优解,耗时较久
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCV
def clf_performance(classifier, model_name):
print(model_name)
print('Best Score: ' + str(classifier.best_score_))
print('Best Parameters: ' + str(classifier.best_params_))
#对各个模型进行网格搜索
#LR
lr = LogisticRegression()
param_grid = {'max_iter' : [2000],
'penalty' : ['l1', 'l2'],
'C' : np.logspace(-4, 4, 20),
'solver' : ['liblinear']}
clf_lr = GridSearchCV(lr, param_grid = param_grid, cv = 5, verbose = True, n_jobs = -1)
best_clf_lr = clf_lr.fit(X_train_scaled,y_train)
clf_performance(best_clf_lr,'Logistic Regression')
#Logistic Regression
#Best Score: 0.8009204595949978
#Best Parameters: {'C': 0.08858667904100823, 'max_iter': 2000, 'penalty': 'l2', 'solver': 'liblinear'}
#KNN
knn = KNeighborsClassifier()
param_grid = {'n_neighbors' : [3,5,7,9],
'weights' : ['uniform', 'distance'],
'algorithm' : ['auto', 'ball_tree','kd_tree'],
'p' : [1,2]}
clf_knn = GridSearchCV(knn, param_grid = param_grid, cv = 5, verbose = True, n_jobs = -1)
best_clf_knn = clf_knn.fit(X_train_scaled,y_train)
clf_performance(best_clf_knn,'KNN')
#KNN
#Best Score: 0.8166698406652702
#Best Parameters: {'algorithm': 'auto', 'n_neighbors': 9, 'p': 2, 'weights': 'uniform'}
#SVC
svc = SVC(probability = True)
param_grid = tuned_parameters = [{'kernel': ['rbf'], 'gamma': [.1,.5,1,2,5,10],
'C': [.1, 1, 10, 100, 1000]},
{'kernel': ['linear'], 'C': [.1, 1, 10, 100, 1000]},
{'kernel': ['poly'], 'degree' : [2,3,4,5], 'C': [.1, 1, 10, 100, 1000]}]
clf_svc = GridSearchCV(svc, param_grid = param_grid, cv = 5, verbose = True, n_jobs = -1)
best_clf_svc = clf_svc.fit(X_train_scaled,y_train)
clf_performance(best_clf_svc,'SVC')
#SVC
#Best Score: 0.8223132101821875
#Best Parameters: {'C': 1, 'degree': 2, 'kernel': 'poly'}
RandomizedSearch (随机搜索)
Random Forest、 XGBoost 有较多参数,先使用RandomizedSearch,随机选取参数并找到最优参数,可以节省时间
# RF RandomizedSearch
rf = RandomForestClassifier(random_state = 1)
param_grid = {'n_estimators': [100,500,1000],
'bootstrap': [True,False],
'max_depth': [3,5,10,20,50,75,100,None],
'max_features': ['auto','sqrt'],
'min_samples_leaf': [1,2,4,10],
'min_samples_split': [2,5,10]}
clf_rf_rnd = RandomizedSearchCV(rf, param_distributions = param_grid, n_iter = 100, cv = 5, verbose = True, n_jobs = -1)
best_clf_rf_rnd = clf_rf_rnd.fit(X_train_scaled,y_train)
clf_performance(best_clf_rf_rnd,'Random Forest')
#RF GridSearch
rf = RandomForestClassifier(random_state = 1)
param_grid = {'n_estimators': [400,450,500,550],
'criterion':['gini','entropy'],
'bootstrap': [True],
'max_depth': [15, 20, 25],
'max_features': ['auto','sqrt', 10],
'min_samples_leaf': [2,3],
'min_samples_split': [2,3]}
clf_rf = GridSearchCV(rf, param_grid = param_grid, cv = 5, verbose = True, n_jobs = -1)
best_clf_rf = clf_rf.fit(X_train_scaled,y_train)
clf_performance(best_clf_rf,'Random Forest')
#Random Forest
#Best Score: 0.8279311877102774
#Best Parameters: {'bootstrap': True, 'criterion': 'gini', 'max_depth': 25, 'max_features': 10, 'min_samples_leaf': 3, 'min_samples_split': 2, 'n_estimators': 450}
#XGB
xgb = XGBClassifier(random_state = 1)
param_grid = {
'n_estimators': [20, 50, 100, 250, 500,1000],
'colsample_bytree': [0.2, 0.5, 0.7, 0.8, 1],
'max_depth': [2, 5, 10, 15, 20, 25, None],
'reg_alpha': [0, 0.5, 1],
'reg_lambda': [1, 1.5, 2],
'subsample': [0.5,0.6,0.7, 0.8, 0.9],
'learning_rate':[.01,0.1,0.2,0.3,0.5, 0.7, 0.9],
'gamma':[0,.01,.1,1,10,100],
'min_child_weight':[0,.01,0.1,1,10,100],
'sampling_method': ['uniform', 'gradient_based']
}
clf_xgb_rnd = RandomizedSearchCV(xgb, param_distributions = param_grid, n_iter = 1000, cv = 5, verbose = True, n_jobs = -1)
best_clf_xgb_rnd = clf_xgb_rnd.fit(X_train_scaled,y_train)
clf_performance(best_clf_xgb_rnd,'XGB')
#XGBoost GridSearch
xgb = XGBClassifier(random_state = 1)
param_grid = {
'n_estimators': [450,500,550],
'colsample_bytree': [0.75,0.8,0.85],
'max_depth': [None],
'reg_alpha': [1],
'reg_lambda': [2, 5, 10],
'subsample': [0.55, 0.6, .65],
'learning_rate':[0.5],
'gamma':[.5,1,2],
'min_child_weight':[0.01],
'sampling_method': ['uniform']
}
clf_xgb = GridSearchCV(xgb, param_grid = param_grid, cv = 5, verbose = True, n_jobs = -1)
best_clf_xgb = clf_xgb.fit(X_train_scaled,y_train)
clf_performance(best_clf_xgb,'XGB')
#XGB
#Best Score: 0.847032311305783
#Best Parameters: {'colsample_bytree': 0.8, 'gamma': 1, 'learning_rate': 0.5, 'max_depth': None, 'min_child_weight': 0.01, 'n_estimators': 550, 'reg_alpha': 1, 'reg_lambda': 10, 'sampling_method': 'uniform', 'subsample': 0.65}
#XGB准确率较高,保存至csv文件:
y_hat_xgb = best_clf_xgb.best_estimator_.predict(X_test_scaled).astype(int)
xgb_submission = {'PassengerId': test_data.PassengerId, 'Survived': y_hat_xgb}
submission_xgb = pd.DataFrame(data=xgb_submission)
submission_xgb.to_csv('xgb_submission3.csv', index=False)
# 提交后得分0.76794,并不高,说明模型可能存在过训练的问题
不同属性的重要性
best_rf = best_clf_rf.best_estimator_.fit(X_train_scaled,y_train)
feat_importances = pd.Series(best_rf.feature_importances_, index=X_train_scaled.columns)
feat_importances.nlargest(20).plot(kind='barh')

根据结果可以对输入属性进行选择、调整
基于调参后的模型进行集成学习
best_lr = best_clf_lr.best_estimator_
best_knn = best_clf_knn.best_estimator_
best_svc = best_clf_svc.best_estimator_
best_rf = best_clf_rf.best_estimator_
best_xgb = best_clf_xgb.best_estimator_
voting_clf_hard = VotingClassifier(estimators = [('knn',best_knn),('rf',best_rf),('svc',best_svc)], voting = 'hard')
voting_clf_soft = VotingClassifier(estimators = [('knn',best_knn),('rf',best_rf),('svc',best_svc)], voting = 'soft')
voting_clf_all = VotingClassifier(estimators = [('knn',best_knn),('rf',best_rf),('svc',best_svc), ('lr', best_lr)], voting = 'soft')
voting_clf_xgb = VotingClassifier(estimators = [('knn',best_knn),('rf',best_rf),('svc',best_svc), ('xgb', best_xgb),('lr', best_lr)], voting = 'soft')
print('voting_clf_hard :',cross_val_score(voting_clf_hard,X_train,y_train,cv=5))
print('voting_clf_hard mean :',cross_val_score(voting_clf_hard,X_train,y_train,cv=5).mean())
print('voting_clf_soft :',cross_val_score(voting_clf_soft,X_train,y_train,cv=5))
print('voting_clf_soft mean :',cross_val_score(voting_clf_soft,X_train,y_train,cv=5).mean())
print('voting_clf_all :',cross_val_score(voting_clf_all,X_train,y_train,cv=5))
print('voting_clf_all mean :',cross_val_score(voting_clf_all,X_train,y_train,cv=5).mean())
print('voting_clf_xgb :',cross_val_score(voting_clf_xgb,X_train,y_train,cv=5))
print('voting_clf_xgb mean :',cross_val_score(voting_clf_xgb,X_train,y_train,cv=5).mean())
#voting_clf_hard : [0.76404494 0.79213483 0.78089888 0.79213483 0.83050847]
#voting_clf_hard mean : 0.7919443915444677
#voting_clf_soft : [0.76966292 0.79213483 0.88202247 0.80337079 0.84180791]
#voting_clf_soft mean : 0.8133054021456232
#voting_clf_all : [0.78089888 0.82022472 0.86516854 0.79775281 0.83615819]
#voting_clf_all mean : 0.820040627182124
#voting_clf_xgb : [0.78089888 0.83146067 0.87640449 0.82022472 0.85310734]
#voting_clf_xgb mean : 0.8335428172411605
#最后一个模型效果最好,但实际提交后此模型不是最佳模型
调整模型权重
调整soft voting classifier中的不同模型的权重值,观察最终模型变化
params = {'weights' : [[1,1,1],[1,2,1],[1,1,2],[2,1,1],[2,2,1],[1,2,2],[2,1,2]]}
vote_weight = GridSearchCV(voting_clf_soft, param_grid = params, cv = 5, verbose = True, n_jobs = -1)
best_clf_weight = vote_weight.fit(X_train_scaled,y_train)
clf_performance(best_clf_weight,'VC Weights')
voting_clf_sub = best_clf_weight.best_estimator_.predict(X_test_scaled)
#VC Weights
#Best Score: 0.8245477051990097
#Best Parameters: {'weights': [2, 1, 1]}
预测结果并存储
#Make Predictions
voting_clf_hard.fit(X_train_scaled, y_train)
voting_clf_soft.fit(X_train_scaled, y_train)
voting_clf_all.fit(X_train_scaled, y_train)
voting_clf_xgb.fit(X_train_scaled, y_train)
#得到预测结果
best_rf.fit(X_train_scaled, y_train)
y_hat_vc_hard = voting_clf_hard.predict(X_test_scaled).astype(int)
y_hat_rf = best_rf.predict(X_test_scaled).astype(int)
y_hat_vc_soft = voting_clf_soft.predict(X_test_scaled).astype(int)
y_hat_vc_all = voting_clf_all.predict(X_test_scaled).astype(int)
y_hat_vc_xgb = voting_clf_xgb.predict(X_test_scaled).astype(int)
#转化为 dataframe 格式
final_data = {'PassengerId': test_data.PassengerId, 'Survived': y_hat_rf}
submission = pd.DataFrame(data=final_data)
final_data_2 = {'PassengerId': test_data.PassengerId, 'Survived': y_hat_vc_hard}
submission_2 = pd.DataFrame(data=final_data_2)
final_data_3 = {'PassengerId': test_data.PassengerId, 'Survived': y_hat_vc_soft}
submission_3 = pd.DataFrame(data=final_data_3)
final_data_4 = {'PassengerId': test_data.PassengerId, 'Survived': y_hat_vc_all}
submission_4 = pd.DataFrame(data=final_data_4)
final_data_5 = {'PassengerId': test_data.PassengerId, 'Survived': y_hat_vc_xgb}
submission_5 = pd.DataFrame(data=final_data_5)
final_data_comp = {'PassengerId': test_data.PassengerId, 'Survived_vc_hard': y_hat_vc_hard, 'Survived_rf': y_hat_rf, 'Survived_vc_soft' : y_hat_vc_soft, 'Survived_vc_all' : y_hat_vc_all, 'Survived_vc_xgb' : y_hat_vc_xgb}
comparison = pd.DataFrame(data=final_data_comp)
可以对不同模型的预测结果进行比较,如果两个模型相异的预测结果较少,则保留其中一个模型即可,结果比较代码如下:
#track differences between outputs
comparison['difference_rf_vc_hard'] = comparison.apply(lambda x: 1 if x.Survived_vc_hard != x.Survived_rf else 0, axis =1)
comparison['difference_soft_hard'] = comparison.apply(lambda x: 1 if x.Survived_vc_hard != x.Survived_vc_soft else 0, axis =1)
comparison['difference_hard_all'] = comparison.apply(lambda x: 1 if x.Survived_vc_all != x.Survived_vc_hard else 0, axis =1)
comparison.difference_hard_all.value_counts()
0 405
1 13
存储csv文件
submission.to_csv('submission_rf.csv', index =False)#0.77511
submission_2.to_csv('submission_vc_hard.csv',index=False)#0.78708
submission_3.to_csv('submission_vc_soft.csv', index=False)#0.77511
submission_4.to_csv('submission_vc_all.csv', index=False)#0.77033
submission_5.to_csv('submission_vc_xgb2.csv', index=False) #0.76315
写在最后
- 此次项目实践旨在熟悉数据分析基本步骤、机器学习模型的运用及基础优化,从模型效果看,在官方教程中直接运用随机森林建立模型的效果甚至优于经过优化过的一个模型,在建立模型时可以从尝试基础简单模型开始,逐渐优化尝试训练效果最好的模型。
- 第一次尝试Kaggle项目,了解到了基本的方法、步骤,后续将继续系统学习机器学习算法及Scikit-learn库的使用。