2019_ICDM_DeepTrust: A Deep User Model of Homophily Effect for Trust Prediction
[论文阅读笔记]2019_ICDM_DeepTrust: A Deep User Model of Homophily Effect for Trust Prediction
论文下载地址: 10.1109/ICDM.2019.00072
发表期刊:ICDM
Publish time: 2019
作者及单位:
- Qi Wang∗, Weiliang Zhao∗, Jian Yang∗, Jia Wu∗, Wenbin Hu†, and Qianli Xing∗
- ∗Department of Computing, Faculty of Science and Engineering, Macquarie University, Sydney, Australia
- †School of Computer , Wuhan University, Wuhan, China
- Email: [email protected], {weiliang.zhao, jian.yang, jia.wu}@mq.edu.au,
- [email protected], [email protected]
数据集: 正文中的介绍
- Epinions
- Ciao
代码:
其他:
其他人写的文章
简要概括创新点: (1)同时用rating和review (2)task是 Trust Prediction
- we propose a novel deep user model for trust prediction based on user similarity measurement. (提出了一种基于用户相似性度量的深度用户信任预测模型。)
- It is a comprehensive data sparsity insensitive model that combines a user review behavior and the item characteristics that this user is interested in. (它是一个综合的数据稀疏性不敏感模型,结合了用户评论行为和该用户感兴趣的项目特征。)
- With this user model, we firstly generate a user’s latent features mined from user review behavior and the item properties that the user cares. (在这个用户模型中,我们首先从用户的评论行为和用户关心的项目属性中挖掘出用户的潜在特征。)
- Then we develop a pair-wise deep neural network to further learn and represent these user features. (然后我们开发了一个成对的深层神经网络来进一步学习和表示这些用户特征。)
- Finally, we measure the trust relations between a pair of people by calculating the user feature vector cosine similarity. (最后,我们通过计算用户特征向量的余弦相似度来度量两个人之间的信任关系。)
Abstract
- Trust prediction in online social networks is crucial for information dissemination, product promotion, and decision making. (在线社交网络中的信任预测对于信息传播、产品推广和决策至关重要。)
- Existing work on trust prediction mainly utilizes the network structure or the low-rank approximation of a trust network. (现有的信任预测工作主要利用信任网络的网络结构或低阶近似。)
- These approaches can suffer from the problem of data sparsity and prediction accuracy. (这些方法可能会遇到数据稀疏性和预测准确性的问题。)
- Inspired by the homophily theory, which shows a pervasive feature of social and economic networks that trust relations tend to be developed among similar people, (受同质性理论的启发,该理论显示了社会和经济网络的普遍特征,即信任关系往往在相似的人之间发展,)
- we propose a novel deep user model for trust prediction based on user similarity measurement. (提出了一种基于用户相似性度量的深度用户信任预测模型。)
- It is a comprehensive data sparsity insensitive model that combines a user review behavior and the item characteristics that this user is interested in. (它是一个综合的数据稀疏性不敏感模型,结合了用户评论行为和该用户感兴趣的项目特征。)
- With this user model, we firstly generate a user’s latent features mined from user review behavior and the item properties that the user cares. (在这个用户模型中,我们首先从用户的评论行为和用户关心的项目属性中挖掘出用户的潜在特征。)
- Then we develop a pair-wise deep neural network to further learn and represent these user features. (然后我们开发了一个成对的深层神经网络来进一步学习和表示这些用户特征。)
- Finally, we measure the trust relations between a pair of people by calculating the user feature vector cosine similarity. (最后,我们通过计算用户特征向量的余弦相似度来度量两个人之间的信任关系。)
- Extensive experiments are conducted on two real-world datasets, which demonstrate the superior performance of the proposed approach over the representative baseline works. (在两个真实数据集上进行了大量实验,结果表明,与典型的基线工作相比,该方法具有更高的性能。)
Index Terms
Trust prediction, Online social networks, User modeling
I. INTRODUCTION
-
(1) Having an effective way to predict trust relations among people in social media can support products marketing, awareness promoting, and decisions making. (有一种有效的方法来预测社交媒体中人们之间的信任关系,可以支持产品营销、提高意识和决策。)
- For example, evidence shows that users on the product review site Epinions are more likely to accept suggestions from their trusted users to decide on the products to purchase [1]. (例如,有证据表明,产品评论网站Epinions上的用户更有可能接受其信任用户的建议,以决定购买哪些产品[1]。)
- Trust prediction, which aims to predict unobserved trust relations between online users becomes crucially important in predicting user preference and behavior tendencies. (信任预测旨在预测在线用户之间未观察到的信任关系,在预测用户偏好和行为倾向方面变得至关重要。)
- However, in reality, explicit trust relations in social networks are often extremely rare. (然而,在现实中,社交网络中的显性信任关系往往极为罕见。)
- Online trust relations normally follow a power-law distribution, which indicates that very few users are trusted by many users, and most users only specify very few trust relations [1]. (在线信任关系通常遵循幂律分布,这表明很少有用户受到多个用户的信任,大多数用户只指定很少的信任关系[1]。)
- The sparsity in available trust relations makes trust prediction a big challenge that has drawn attention from the research community [1]–[3]. (现有信任关系的稀疏性使得信任预测成为一个巨大的挑战,引起了研究界的关注[1]–[3]。)
-
(2) In recent years, there have been a few trust prediction works reported in the literature, which can be roughly categorized into two groups: (近年来,文献中报道了一些信任预测工作,大致可分为两类:)
- (1) trust network structure based approaches (基于信任网络结构的方法)
- and (2) low-rank approximation based approaches. (基于低秩近似的方法。)
- Trust network structure based approaches, such as trust propagation [4], evaluate the trust value from a source user to a target user along a path between them. (基于信任网络结构的方法,如信任传播[4],沿着源用户与目标用户之间的路径评估源用户与目标用户之间的信任值。)
- However, such approaches heavily depend on the existing trust connections among users, it failed to predict trust relations for those pairs without any paths between them. (然而,这种方法严重依赖于用户之间现有的信任关系,无法预测没有任何路径的用户对之间的信任关系。)
- On the other hand, low-rank approximation based approaches factorize a trust matrix into the low-rank representation of users and their correlations to approximate the original trust network [5], which do not have to evaluate trust along a path. (另一方面,基于低秩近似的方法将信任矩阵分解为用户及其相关性的低秩表示,以近似原始信任网络[5],该网络不必沿路径评估信任。)
- In addition, low-rank approximation based approaches can obtain better prediction accuracy by incorporating various prior knowledge or additional user property as regularization [1]–[3], [6]. (此外,基于低秩近似的方法可以通过将各种先验知识或附加用户属性合并为正则化[1]–[3],[6]来获得更好的预测精度。)
- Nevertheless, these approaches still heavily rely on existing trust relations, which suffer severely from the data sparsity problem. (尽管如此,这些方法仍然严重依赖于现有的信任关系,而信任关系严重受到数据稀疏问题的影响。)
-
(3) As a social concept, the issue of trust has been extensively studied in social science. (信任作为一个社会概念,在社会科学中得到了广泛的研究。)
- Homophily is one of the most important social science theories that investigate why people establish trust relations with each other [7], [8]. (同质性是研究人们为什么建立信任关系的最重要的社会科学理论之一[7],[8]。)
- Homophily theory shows a pervasive feature of social networks that people with similar experience and background tend to share common opinions and attitudes towards certain things. (同质性理论显示了社交网络的一个普遍特征,即具有相似经历和背景的人倾向于对某些事情分享共同的观点和态度。)
- Intuitively speaking, trust relationships tend to be developed among similar people. (直观地说,信任关系往往是在相似的人之间发展起来的。)
- The work in [9] also points out that there is a strong and significant correlation between trust and user similarity based on real-world data analysis. ([9]中的工作还指出,基于真实世界的数据分析,信任和用户相似性之间存在着强烈而显著的相关性。)
- Tang et al. exploit the homophily effect as regularization for trust prediction by modeling the homophily effect as rating similarity in [1]. Unfortunately, it only considers ratings as user features in measuring user similarity. (Tang等人在[1]中通过将同质效应建模为评分相似性,利用同质效应作为信任预测的正则化。不幸的是,它只将评分视为衡量用户相似性的用户特征。)
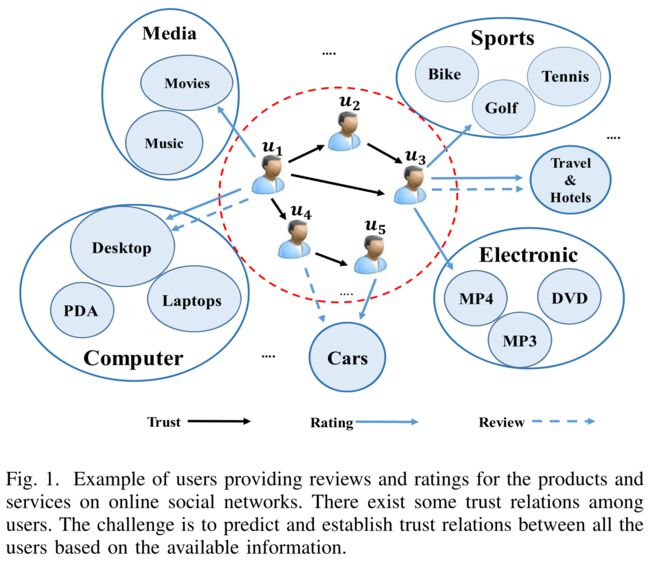
Fig. 1. Example of users providing reviews and ratings for the products and services on online social networks. There exist some trust relations among users. The challenge is to predict and establish trust relations between all the users based on the available information. (图1。在在线社交网络上为产品和服务提供评论和评级的用户示例。用户之间存在一定的信任关系。挑战在于根据可用信息预测并建立所有用户之间的信任关系。)
-
(4) As can be seen in Fig.1, a user can express her/his opinion on an item by providing ratings and writing reviews on social media. (如图1所示,用户可以通过在社交媒体上提供评分和撰写评论来表达自己对某个项目的看法。)
- Studies show that review texts can reveal the characteristics of a user and an item. (研究表明,评论文本可以揭示用户和项目的特征。)
- It is especially useful for modeling users and items with very few ratings [10]. (它特别适用于为评分很少的用户和项目建模[10]。)
- A user can express his/her attitudes and preference in review text, which is a good resource supplement of rating for better understanding a user [11], [12]. (用户可以在评论文本中表达自己的态度和偏好,这是一个很好的评级资源补充,有助于更好地理解用户[11],[12]。)
- In addition, the latent factors behind an item that attract the user’s attention can also be considered as useful representative features of a user. (此外,吸引用户注意力的项目背后的潜在因素也可以被视为用户有用的代表性特征。)
- For example, a user who bought a set of professional training tool can somehow indicate that the user is a sports lover. (例如,购买了一套专业培训工具的用户可以以某种方式表明该用户是体育爱好者。)
- Therefore, a user’s online reviews/comments together with their ratings and the features of the items that the user is interested in actually reveal this user’s social characteristics, which can be used as a basis for user similarity measurement. (因此,用户的在线评论/评论以及他们的评分和用户感兴趣的项目的特征实际上揭示了该用户的社会特征,这可以作为用户相似性度量的基础。)
- However, the existing works on trust prediction have not provided a comprehensive user modeling approach to cover all the aforementioned aspects as user features when comes to user similarity measurement. (然而,现有的信任预测研究还没有提供一种全面的用户建模方法,在用户相似性度量方面,将上述所有方面都作为用户特征来涵盖。)
-
(5) The advancement of deep learning technologies has shown great success in many application areas such as neural language processing [13], [14], recommendation systems [15]–[17]. (深度学习技术的进步在许多应用领域取得了巨大成功,如神经语言处理[13]、[14]、推荐系统[15]–[17]。)
- The significant learning capability of deep neural network in processing complex relations and correlations can provide a deep revelation of users’ behaviors. (深层神经网络在处理复杂关系和相关性方面的显著学习能力可以提供用户行为的深层揭示。)
- But, how to effectively develop the deep learning technology for trust prediction remains an under-explored area that almost none of the existing work has investigated. (但是,如何有效地开发用于信任预测的深度学习技术仍然是一个探索不足的领域,几乎没有现有的工作进行过研究。)
-
(6) In order to tackle the challenges discussed above, we develop a novel deep user model that has the following features: (为了应对上述挑战,我们开发了一种新的深度用户模型,该模型具有以下特点:)
- (1) For user modeling, we consider the features of both the user review behavior and the item that the user is interested. The features of user review behavior are mined from their reviews and ratings. Item features are mined and considered as part of user features since items rated and reviewed by a user naturally reflect this users taste; (对于用户建模,我们考虑用户评论行为和用户感兴趣的项目的特征。用户评论行为的特征是从他们的评论和评分中挖掘出来的。项目特征被挖掘出来,并被视为用户特征的一部分,因为用户对项目进行评级和评论自然反映了用户的品味;)
- (2) We develop a pair-wise deep neural network to further capture and represent user latent features based on 1; (我们开发了一个基于1的成对深层神经网络来进一步捕获和表示用户的潜在特征;)
- (3) Trust relation is measured based on the latent user feature similarity. (基于潜在用户特征相似度度量信任关系。)
-
(7) The main contributions of this paper are summarized as follows. (本文的主要贡献总结如下)
- A comprehensive user model for trust prediction based on the integration of user review behavior and item features; (基于用户评论行为和项目特征的综合用户信任预测模型;)
- The first trust prediction model based on the deep neural network with a mixture of sparse existing trust relations and unknown relations; (第一个基于深度神经网络的信任预测模型,混合了稀疏的现有信任关系和未知关系;)
- Experiments on real-world datasets demonstrate: (在真实数据集上的实验表明:)
- (1) the superior performance of the proposed trust prediction model in terms of prediction accuracy over both classic and state-of-the-art approaches; (所提出的信任预测模型在预测精度方面优于经典和最先进的方法)
- and (2) the proposed model is trust relation sparsity insensitive that is different from the existing works in this space. (该模型对信任关系稀疏性不敏感,不同于现有的信任关系稀疏性模型。)
-
(8) The rest of the paper is structured as follows. Section 2 discusses the related work. Section 3 formulates the trust prediction problem. Section 4 proposes our deep trust prediction framework. Section 5 explains the experiments conducted and analyses the result. Finally Section 6 concludes the work. (论文的其余部分结构如下。第2节讨论了相关工作。第3节阐述了信任预测问题。第4节提出了我们的深度信任预测框架。第5节解释了进行的实验并分析了结果。最后,第6节总结了本文的工作。)
II. RELA TED WORK
- In this section, we mainly review the existing trust prediction approaches in two categories: (在本节中,我们主要从两个方面回顾现有的信任预测方法:)
- (1) trust network structure based approaches and (基于信任网络结构的方法及应用)
- (2) low-rank approximation based approaches. (基于低秩近似的方法。)
A. Trust Network Structure based Trust Prediction Approaches (基于信任网络结构的信任预测方法)
-
(1) Trust network structure has been widely exploited by existing trust prediction methods as it is the most important available resource. (信任网络结构作为最重要的可用资源,已被现有的信任预测方法广泛利用。)
- The study in [4] utilizes the transitivity property of trust to propagate trust values from a source user to a target user along a path between them and treats all the propagation paths equally. ([4]中的研究利用信任的传递性,沿着源用户和目标用户之间的路径将信任值从源用户传播到目标用户,并平等对待所有传播路径。)
- Later on, researchers find that shorter propagation paths and paths with higher trust values produce more accurate trust evaluations [18]. ()后来,研究人员发现,较短的传播路径和信任值较高的路径会产生更准确的信任评估[18]。
- By averaging the trust values along social paths, algorithms for inferring the trust relations between users that are not directly connected are proposed in [19]. ([19]中提出了通过沿社交路径平均信任值来推断非直接连接用户之间信任关系的算法。)
- In addition to the above propagation-based approaches, the neighborhood structure of a trust network is considered in some studies. (除了上述基于传播的方法外,一些研究还考虑了信任网络的邻域结构。)
- The trust value between a pair of user ( u i , u j ) (u_i, u_j) (ui,uj) is aggregated according to the suggestions from u i u_i ui’s neighbours. (一对用户 ( u i , u j ) (u_i, u_j) (ui,uj)之间的信任值,根据 u i u_i ui邻居的建议进行聚合。)
- In details, the stronger u i u_i ui trusts her/his trustees, the higher weighs these trustees carry when aggregating their suggestions [18], [20]. (在细节上,更强的 u i u_i ui信任她/他的受托人,这些受托人在汇总其建议时的权重越高[18],[20]。)
- Furthermore, a reputation-based trust supporting framework, which includes a coherent adaptive trust model for quantifying and comparing the trustworthiness of users is proposed in [21]. (此外,文献[21]提出了一个基于声誉的信任支持框架,其中包括一个一致的自适应信任模型,用于量化和比较用户的可信度。)
- Robust and scalable P2P reputation system for trust computation is developed by leveraging the powerlaw feedback characteristics in [22]. (利用[22]中的幂律反馈特性,开发了用于信任计算的健壮且可扩展的P2P信誉系统。)
-
(2) However, trust network structure based approaches normally suffer from the data sparsity problem since the number of trust relations may not be sufficiently enough to guarantee the success of such approaches. (然而,基于信任网络结构的方法通常会遇到数据稀疏问题,因为信任关系的数量可能不足以保证此类方法的成功。)
B. Low-rank Approximation based Trust Prediction Approaches (基于低秩近似的信任预测方法)
-
(1) Low-rank approximation based method is widely employed in various applications such as collaborative filtering [23], [24] and document clustering [5], [25]. (基于低秩近似的方法广泛应用于各种应用,如协同过滤[23]、[24]和文档聚类[5]、[25]。)
- The basic idea of the low-rank approximation based approaches is that a few latent factors can influence the establishment of trust relations. (基于低秩近似的方法的基本思想是,一些潜在因素会影响信任关系的建立。)
- In addition, most of the existing trust relation matrix are sparse and low-rank since users usually establishes trust relations with a small number of users in a given network. (此外,由于用户通常与给定网络中的少数用户建立信任关系,现有的大多数信任关系矩阵都是稀疏的、低秩的。)
- Therefore, users should have a more accurate representation in the low-rank space [26]. (因此,用户应该在低秩空间中有更准确的表示[26]。)
- Matrix Factorization (MF) is the most widely employed low-rank approximation model to generate the low-rank representations of users and their correlations by factorizing a trust matrix [5]. (矩阵分解(MF)是最广泛使用的低秩近似模型,通过分解信任矩阵来生成用户及其相关性的低秩表示[5]。)
- Furthermore, by incorporating prior knowledge and additional user-generated content, the performance of low-rank approximation based approaches can be further improved. (此外,通过结合先验知识和额外的用户生成内容,可以进一步提高基于低秩近似的方法的性能。)
- Homophily effect is studied and incorporated as the rating similarity regularization to matrix factorization [1]. (研究了同质效应,并将其作为评级相似性正则化纳入矩阵分解[1]。)
- The transitivity, multi-aspect and trust bias properties of trust networks are explored to enhance matrix factorization [6]. (研究了信任网络的传递性、多方面性和信任偏差特性,以增强矩阵分解[6]。)
- Social status regularized matrix factorization, which is based on the assumption that the users with lower social status are more likely to trust the users with higher status is proposed in [2]. ([2]提出了社会地位正则化矩阵分解**,该分解基于社会地位较低的用户更可能信任地位较高的用户的假设。)
- Besides, Emotional information for trust/distrust prediction by regularizing the finding that users with positive/negative emotions are more likely to have trust/distrust relations with others is also investigated [27]. (此外,还研究了通过规范化具有积极/消极情绪的用户更有可能与他人建立信任/不信任关系的发现来预测信任/不信任的情绪信息[27]。)
- Recently, a power-law distribution aware trust prediction model is proposed under the framework of matrix factorization [3]. (最近,在矩阵分解的框架下,提出了一种幂律分布感知的信任预测模型[3]。)
- There also have been studies on matrix completion in recent years by explicitly seeking a matrix with the exact rank to guarantee the low-rank of the recovery matrix [28], [29]. (近年来也有关于矩阵完备的研究,通过显式地寻找具有精确秩的矩阵来保证恢复矩阵的低秩[28],[29]。)
-
(2) Different from the trust network structure based approaches, the low-rank approximation based approaches do not have to rely on the paths between users. However, all the aforementioned low-rank approximation based models still significantly suffer from the data sparsity problem since these approaches conduct factorization directly on the sparse trust relation matrix. (与基于信任网络结构的方法不同,基于低秩近似的方法不必依赖于用户之间的路径。然而,由于这些方法直接在稀疏信任关系矩阵上进行因子分解,所有上述基于低秩近似的模型仍然显著地受到数据稀疏性问题的影响。)
III. PROBLEM FORMULATION (问题表述)
-
(1) As presented in most of the product review websites, there usually exists Users, Items, User to User interaction and User to Item interaction. The goal here is to predict the trust degree between these users based on their similarities in relation to the items which they rated or commented on. For the preparation of similarity calculation and trust prediction, we specify the elements and their relationships used in the calculation as follows: (如大多数产品评论网站所示,通常存在用户、项目、用户对用户的交互和用户对项目的交互。这里的目标是根据这些用户与他们评分或评论的项目的相似性来预测他们之间的信任度。为了准备相似性计算和信任预测,我们将计算中使用的元素及其关系指定如下:)
- U = { u 1 , ⋅ ⋅ ⋅ , u m } U = \{ u_1, ··· , u_m \} U={u1,⋅⋅⋅,um} denotes the set of m m m users. (m个用户的集合)
- V = { v 1 , ⋅ ⋅ ⋅ , v n } V = \{v_1,··· , v_n \} V={v1,⋅⋅⋅,vn} denotes the set of n n n items.(n个项目的集合)
- T m × m T_{m×m} Tm×m is the trust relation matrix representing the trust relation between users. (是表示用户之间信任关系的信任关系矩阵)
- t i j t_{ij} tij is an element in T T T, which denotes the trust value of user i i i on user j j j, (是 T T T中的一个元素,表示用户 i i i对用户 j j j的信任值)
- t i j = 1 t_{ij} = 1 tij=1 if there exists trust relation between u i u_i ui and u j u_j uj, and t i j = 0 t_{ij} = 0 tij=0 otherwise. ( u i u_i ui 和 u j u_j uj之间存在信任关系)
- R m × n R_{m×n} Rm×n denotes the rating matrix of users to items, where r i j r_{ij} rij is the rating value of user i i i on item j j j. (表示用户对项目的评分矩阵,其中 r i j r_{ij} rij是用户 i i i对项目 j j j的评分值。)
- – R i w , i = 1... m R^w_i, i = 1... m Riw,i=1...m denotes the i i ith row of R R R, R i w R^w_i Riw is user u i u_i ui’s ratings for all the items. (表示 R R R的第 i i i行, R i w R^w_i Riw是用户 u i u_i ui对所有项目的评分。)
- – R j c , j = 1... n R^c_j,j = 1...n Rjc,j=1...n denotes the j j jth column of R R R, R j c R^c_j Rjc is the ratings item v j v_j vj received. (表示 R R R的第 j j j列, R j c R^c_j Rjc是 v j v_j vj收到的评级项目)
- R E m × n RE_{m×n} REm×n denotes the review matrix of users to items, where r e i j re_{ij} reij is the piece of review text of user i i i written for item j j j. ( R E m × n RE_{m×n} REm×n表示用户对项目的评论矩阵,其中 r e i j re_{ij} reij是用户 i i i为项目 j j j编写的评论文本。)
- == R E i w , i = 1... m RE^w_i, i = 1...m REiw,i=1...m denotes the i i ith row of R E RE RE, R E i w RE^w_i REiw is u i u_i ui’s reviews written for all the items. (表示 R E RE RE的第 i i i行, R E i w RE^w_i REiw是为所有项目编写的 u i u_i ui评论)
- – R E j c , j = 1... n RE^c_j, j = 1...n REjc,j=1...n denotes the j j jth column of R E RE RE, R E j c RE^c_j REjc is all the reviews item v j v_j vj received. (表示 R E RE RE的第 j j j列, R E j c RE^c_j REjc是项目 v j v_j vj收到的所有评论。)
-
(2) As discussed before, we will consider the features of both users’ review behaviors and items that the users have provided ratings and reviews. (如前所述,我们将考虑用户的评论行为和用户提供评分和评论的项目的特征。)
- The features of user review behavior include this user’s rating features and review features. (用户评论行为的特征包括该用户的评级特征和评论特征。)
- The properties of an item that users rated/reviewed can be obtained from the ratings and reviews the item received. (用户评分/评论的项目的属性可以从收到的项目的评级和审查中获得。)
- Here we introduce two functions Matrix Factorization(MF) and Doc2vec to map the raw data into latent representation. (在这里,我们引入了两个函数矩阵分解(MF)和Doc2vec来将原始数据映射到潜在表示中。)
- The two functions are specified as follows: (这两个函数指定如下)
- MF(R ): MF is applied on matrix R R R to obtain a user latent matrix P P P and item latent matrix Q Q Q. (MF应用于矩阵 R R R,以获得用户潜在矩阵 P P P和项目潜在矩阵 Q Q Q)
- For each user u i u_i ui, for simplicity, P i P_i Pi is used to represent user u i u_i ui’s rating vector. (对于每个用户 u i u_i ui, 为了简单起见, P i P_i Pi用于表示用户 u i u_i ui’s评级向量。)
- For each item v j v_j vj, for simplicity, Q j Q_j Qj is used to represent item v j v_j vj’s received rating vector. (对于每个项目 v j v_j vj, 为了简单起见, Q j Q_j Qj用于表示 v j v_j vj项’s收到评分向量。)
- Doc2vec( R E i w RE^w_i REiw): for each user i i i, Doc2vec is applied on u i u_i ui’s reviews written for all the items to obtain user u i u_i ui’s review feature vector denoted as R E i U RE^U_i REiU. (对于每个用户 i i i,Doc2vec应用于为所有项目编写的 u i u_i ui评论,以获取用户 u i u_i ui的评论特征向量,表示为 R E u U i RE^uUi REuUi)
- Doc2vec( R E j c RE^c_j REjc): for each item j j j, Doc2vec is applied on v j v_j vj’s received reviews written by all the users to obtain item v j v_j vj’s review feature vector denoted as R E j I RE^I_j REjI. (对于每个 j j j项目,Doc2vec应用于所有用户编写的 v j v_j vj收到的评论,以获得项目 v j v_j vj的评论特征向量,表示为 R E j I RE^I_j REjI。)
- MF(R ): MF is applied on matrix R R R to obtain a user latent matrix P P P and item latent matrix Q Q Q. (MF应用于矩阵 R R R,以获得用户潜在矩阵 P P P和项目潜在矩阵 Q Q Q)
-
(3) Now we concatenate these features: P i Pi Pi, Q j Qj Qj, R E i U RE^U_i REiU, R E j I RE^I_j REjI as user u i u_i ui’s features, denoted as F u i F_{u_i} Fui. (现在我们将这些特性连接起来: P i Pi Pi, Q j Qj Qj, R E i U RE^U_i REiU, R E j i RE^i_j REji作为用户 U i U_i Ui的特性,表示为 F U i F_{U_i} FUi。)
- Then we feed it into a fully connected deep neural network to further learn and represent the latent feature vector L A u i LA_{u_i} LAui. (然后我们将其输入一个完全连接的深度神经网络,进一步学习和表示潜在的特征向量 L A u i LA_{u_i} LAui。)
- For each pair of user ( u i , u j ) (u_i, u_j) (ui,uj), we can get the similarity between their latent feature vector ( L A u i , L A u j ) (LA_{u_i}, LA_{u_j}) (LAui,LAuj) by cosine similarity calculation, which is denoted as S u i , u j S_{u_i, u_j} Sui,uj. Finally, the trust degrees between pairs of users are measured by their similarity scores. (对于每一对用户 ( u i , u j ) (u_i, u_j) (ui,uj),我们可以通过余弦相似性计算得到其潜在特征向量 ( L A u i , L A u j ) (LA_{u_i}, LA_{u_j}) (LAui,LAuj)之间的相似性,表示为 S u i , u j S_{u_i, u_j} Sui,uj。最后,用户对之间的信任度由他们的相似性分数来衡量。)
IV . THE DEEP TRUST FRAMEWORK (深度信任框架)
- In this section, we first investigate the existing of homophily effect in trust establishment. (在这一部分中,我们首先研究了同质效应在信任建立中的存在)
- Then we introduce the proposed framework, deepTrust, which is based on the homophily theory. (然后,我们介绍了基于同质理论的deepTrust框架。)
- The overview of the proposed framework is illustrated as Fig. 2. (拟议框架的概述如图2所示)
- Our deepTrust framework mainly consists of three components: (我们的deepTrust框架主要由三个组件组成)
- (1) User modeling. We first model users’ features from available data including users’ ratings, reviews and item properties; (用户建模。我们首先根据可用数据对用户的特征进行建模,包括用户的评分、评论和项目属性;)
- (2) Pair-wise multi-layer projection. We develop a pair-wise deep neural network to further project user features into a common low-dimensional space; (成对多层投影。我们开发了一个成对的深层神经网络,将用户特征进一步投射到一个公共的低维空间中)
- (3) Trust measurement. We measure the trust degrees between pairs of users according to the similarities between their low dimensional vectors. (信任测量。我们根据低维向量之间的相似性来度量用户对之间的信任度。)
- As far as we know, this is the first work that develops a deep learning-based model for trust prediction. (据我们所知,这是第一项开发基于深度学习的信任预测模型的工作。)
4.1 A. Analysis of Homophily Theory in Trust Prediction (信任预测中的同质理论分析)
-
(1) Homophily theory is the most important social science theory that indicates trust relations are more likely to establish between similar users, which is widely observed in social networks [30]. (同质理论是最重要的社会科学理论,表明相似用户之间更容易建立信任关系,这在社交网络中被广泛观察[30]。)
- In this section, we investigate this theory by studying the correlation between users’ similarity and trust relations via significance test. (在这一部分中,我们通过显著性检验来研究用户相似性和信任关系之间的相关性来研究这一理论。)
- Significance test is a widely used method to detect whether there is a difference between the experimental group and the control group in the scientific experiment and whether the difference is significant. (显著性检验是一种广泛使用的方法,用于检测实验组和对照组在科学实验中是否存在差异,以及差异是否显著。)
- The basic idea of significance test is to make a hypothesis about the scientific data first and then use the test to check if the hypothesis is right. (显著性检验的基本思想是先对科学数据做出假设,然后用该检验来检验假设是否正确。)
- In general, the hypothesis to be tested is called the null hypothesis, which is denoted as H0, while the hypothesis opposite to H0is called the alternative hypothesis, which is denoted as H1. (一般来说,要测试的假设称为无效假设,表示为H0,而与H0相反的假设称为替代假设,表示为H1。)
- Following the investigation in [1], we study homophily theory in trust relation on dataset Epinions by investigating the following questions: (在[1]中的研究之后,我们通过研究以下问题,研究了数据集上信任关系中的同质理论:)
- Whether the users with higher similarity are more likely to establish trust relations compared with those with lower similarity or not? (与相似性较低的用户相比,相似性较高的用户是否更容易建立信任关系?)
- Whether the users with trust relations are more similar in terms of the similarity of their features compared with those without or not? (有信任关系的用户与没有信任关系的用户在特征相似性方面是否更相似?)
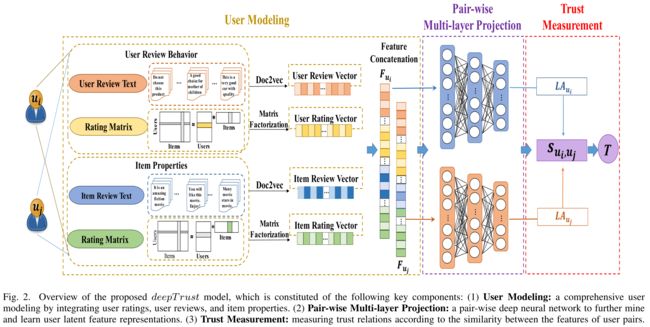
Fig. 2. Overview of the proposed deepTrust model, which is constituted of the following key components: (1) User Modeling: a comprehensive user modeling by integrating user ratings, user reviews, and item properties. (2) Pair-wise Multi-layer Projection: a pair-wise deep neural network to further mine and learn user latent feature representations. (3) Trust Measurement: easuring trust relations according to the similarity between the features of user pairs. (图2。提出的deepTrust模型概述,该模型由以下关键组件组成:(1)用户建模:通过集成用户评分、用户评论和项目属性的综合用户建模。(2) 成对多层投影:一种用于进一步挖掘和学习用户潜在特征表示的成对深层神经网络。(3) 信任度量:根据用户对特征之间的相似性来度量信任关系。)
-
(2) We firstly decide to measure users’ similarity by their rating vector cosine similarity to answer the above questions. (我们首先决定通过用户的评分向量余弦相似度来衡量用户的相似度,以回答上述问题。)
- Therefore, for the first question, we explore if high-similarity users at time T T T are more likely to establish trust relations at time T + 1 T +1 T+1 compared with low-similarity users. (因此,对于第一个问题,我们探讨了与低相似性用户相比,在 T T T时间段的高相似性用户是否更有可能在 T + 1 T+1 T+1时间段建立信任关系。)
- The Epinions dataset is divided into two groups according to the timestamp.
- T i T_i Ti contains the data before timestamp T i T_i Ti while T i + 1 T_{i+1} Ti+1 contains the data from time T i T_i Ti to T i + 1 T_{i+1} Ti+1. ( T i T_i Ti包含时间戳 T i T_i Ti之前的数据, T i + 1 T_{i+1} Ti+1包含时间 T i T_i Ti到 T i + 1 T_{i+1} Ti+1之间的数据。)
- Firstly, all the user pairs with unobserved trust relations before timestamp T i T_i Ti are ranked in descending order in terms of rating vector cosine similarity. (首先,所有在时间戳 T i T_i Ti之前具有未观察到的信任关系的用户对按照评分向量余弦相似性降序排列。)
- Then the first x x x% of users are selected from the top, which forms a high-similarity group denoting as G h i G^i_h Ghi. (然后从顶部选择第一个 x x x%的用户,这形成了一个高度相似的组,表示为 G h i G^i_h Ghi。)
- Similarly, the last x x x% from the bottom are selected to form a low-similarity group G l i G^i_l Gli. (同样,从底部选择最后的 x x x%以形成一个低相似性组 G l i G^i_l Gli。)
- Finally, we check whether the pairs of users in the high-similarity group G h i G^i_h Ghi are more likely to establish trust relations at T i + 1 T_{i+1} Ti+1 compared with those in the low-similarity group G l i G^i_l Gli. (最后,我们检查 高相似性组 G h i G^i_h Ghi 中的用户对是否比低相似性组 G l i G^i_l Gli中的用户对更有可能在 T i + 1 T_{i+1} Ti+1处建立信任关系。)
- Let h i ( x ) h_i (x) hi(x) and l i ( x ) l_i(x) li(x) denote the percentages of user pairs that establish trust relations in G h i G^i_h Ghi and G l i G^i_l Gli at T i + 1 T_{i+1} Ti+1, respectively. (让 h i ( x ) h_i(x) hi(x)和 l i ( x ) l_i(x) li(x)分别表示在 T i + 1 T_{i+1} Ti+1中,在 G h i G^i_h Ghi和 G l i G^i_l Gli中建立信任关系的用户对的百分比。)
- With an incremental number of 0.0001, x x x varies from 0.0001 to 0.01 due to the sparsity of trust relations. (由于信任关系的稀疏性,增量为0.0001, x x x从0.0001到0.01不等。)
- Finally, we can get two vectors, h = [ h 0.0001 , . . . , h 0.01 ] h = [h_{0.0001}, ..., h_{0.01}] h=[h0.0001,...,h0.01] and l = [ l 0.0001 , . . . , l 0.01 ] l = [l_{0.0001}, ..., l_{0.01}] l=[l0.0001,...,l0.01], where we conduct a significance test on them to verify the answer for the first question. (最后,我们可以得到两个向量, h = [ h 0.0001 , … , h 0.01 ] h=[h_{0.0001},…,h_{0.01}] h=[h0.0001,…,h0.01]和 l = [ l 0.0001 , … , l 0.01 ] l=[l_{0.0001},…,l_{0.01}] l=[l0.0001,…,l0.01],我们对它们进行显著性检验,以验证第一个问题的答案。)
- The null hypothesis for our first question is H 0 : h = l H_0 : h = l H0:h=l, which means that there is no difference between high similarity and trust relation establishment. (第一个问题的无效假设是 H 0 : H = l H_0:H=l H0:H=l,这意味着高度相似性和建立信任关系之间没有区别。)
- While the alternative hypothesis is H 1 : h > l H_1: h \gt l H1:h>l, which has the opposite meaning with the null hypothesis H 0 H_0 H0. (而另一种假设是 H 1 : h > l H_1: h \gt l H1:h>l,这与无效假设 H 0 H_0 H0的含义相反)
- According to the calculation, null hypothesis is rejected with p − p- p−value is 8.29 e − 41 8.29e − 41 8.29e−41 when α = 0.01 \alpha = 0.01 α=0.01. This result shows that users with higher rating similarity are more likely to establish trust relations compared with those with lower similarity. (根据计算,零假设被拒绝,当 p − p- p−value 是 8.29 e − 41 8.29e − 41 8.29e−41, α = 0.01 \alpha = 0.01 α=0.01。这一结果表明,与相似性较低的用户相比,评分相似性较高的用户更容易建立信任关系。)
-
(3) To answer the second question, we calculate users with explicit trust relations in two groups. (为了回答第二个问题,我们计算了两组具有明确信任关系的用户。)
- In details, for each pair of trusted users ( u i , u j ) (u_i, u_j) (ui,uj), the first group calculates the rating similarity between them, which is denoted as t s t_s ts. (具体来说,对于每对受信任用户 ( u i , u j ) (u_i, u_j) (ui,uj),第一组计算它们之间的评分相似性,表示为 t s t_s ts。)
- While the second group calculates the rating similarity between uiand a randomly selected user, which is denoted as t r t_r tr. (而第二组则计算UIA和随机选择的用户之间的评分相似性,即 t r t_r tr。)
- We can finally obtain two sets of similarity-based vectors S t S_t St and S r S_r Sr, which contain all trust similarities t s t_s ts and t r t_r tr, respectively. (我们最终可以得到两组基于相似性的向量 S t S_t St和 S r S_r Sr,它们分别包含所有信任相似性 t S t_S tS和 t r t_r tr。)
- Then as indicated in [1], we conduct a significance test on S t S_t St and S r S_r Sr to detect whether there is a significant difference between these two sets. (然后,如[1]所示,我们对 S t S_t St和 S r S_r Sr进行显著性测试,以检测这两组数据之间是否存在显著差异。)
- The null hypothesis for our second question is H 0 : S t = S r H_0 : S_t = S_r H0:St=Sr, which denotes that there isn’t a difference between trust relations and user similarity. (第二个问题的零假设是 H 0 : S t = S r H_0:S_t=S_r H0:St=Sr,这表示信任关系和用户相似性之间没有区别。)
- The alternative hypothesis is H 1 : S t > S r H_1 : S_t > S_r H1:St>Sr. (另一种假设是 H 1 : S t > S r H_1:S_t \gt S_r H1:St>Sr)
- According to the calculation, the null hypothesis is rejected with p p p-value is 4.81 e − 62 4.81e − 62 4.81e−62 when α = 0.01 \alpha = 0.01 α=0.01 by significance test, thus the result shows that users with trust relations have higher rating similarity compared with those without trust relations. (根据计算,无效假设被拒绝, 通过显著性检验,当 p p p-value 是 4.81 e − 62 4.81e − 62 4.81e−62 , α = 0.01 \alpha = 0.01 α=0.01,因此结果表明,与没有信任关系的用户相比,有信任关系的用户具有更高的评分相似性。)
-
(4) According to the above investigation, positive answers to both questions verify the existence of the homophily effect in trust relations. (根据上述调查,对这两个问题的肯定回答证实了信任关系中的同质效应的存在。)
- Based on this theory, we then introduce how we model this effect in a comprehensive manner for a deep trust prediction between pairs of users. (基于这一理论,我们接着介绍了如何以一种全面的方式对这种影响进行建模,以预测用户对之间的深度信任。)
4.2 B. User Modeling (用户建模)
-
(1) In this section, we describe how to leverage a user’s comprehensive features to model his/her characteristics. We mainly consider a user’s review behavior and the properties of the items related to the user. (在本节中,我们将介绍如何利用用户的全面的特点来模拟其特征。我们主要考虑用户的评论行为和与用户相关的项目的属性。)
-
(2) Modeling User Review Behavior: On a product review website such as Epinions, a user’s review behavior usually includes ratings and reviews, which both indicate a user’s characteristics in different forms. (建模用户评论行为:在Epinions等产品评论网站上,用户的评论行为通常包括评分和评论,这两种行为都以不同的形式表示用户的特征。)
-
(3) To obtain the information of a user’s features delivered from his/her review behavior, we use Matrix Factorization(MF) [31] and Doc2Vec [32] to process ratings and reviews respectively. (为了从用户的评论行为中获得用户特征的信息,我们分别使用矩阵分解(MF)[31]和 Doc2Vec [32]来处理评分和评论。)
- Matrix Factorization is the most popular collaborative filtering methods which is based on low-dimensional factor models. (矩阵分解是目前最流行的基于低维因子模型的协同过滤方法。)
- The basic idea behind such models is that a user’s attitudes or preference are determined by k k k unobserved latent factors, thus both users and items can be mapped to a joint latent space of dimension k k k. (这种模型背后的基本思想是,用户的态度或偏好由 k 个 k个 k个未观察到的潜在因素决定,因此用户和项目都可以映射到 k k k维度的联合潜在空间。)
- Therefore, for each u i u_i ui, to obtain the information of user latent features in rating matrix, we factorize the rating matrix R m × n R^{m\times n} Rm×n into user latent matrices P m × k P^{m\times k} Pm×k and item latent matrices Q n × k Q^{n\times k} Qn×k respectively, which is represented as R m × n → P m × k ∗ Q n × k ⊤ R^{m\times n} \rightarrow P^{m×k} ∗ Q^{\top}_{n×k} Rm×n→Pm×k∗Qn×k⊤.
- k k k is the dimension of latent factors. ( k k k是潜在因素的维度)
- P m × k P^{m\times k} Pm×k denotes the relations between m m m users and k k k latent factors, (表示 m m m用户和 k k k潜在因素之间的关系)
- where P i P_i Pi denotes u i u_i ui’s feature vector learned from user rating matrix. (其中, P i P_i Pi表示从用户评分矩阵中学习的 u i u_i ui特征向量)
-
(4) Doc2vec learns k-dimension vector representations for variable length pieces of reviews. (Doc2vec学习可变长度评论的k维向量表示。)
- Then the vector representations of reviews can be used for calculation. (然后,可以使用评论的向量表示进行计算。)
- For each user u i u_i ui, u i u_i ui usually has a list of reviews R E i w RE^w_i REiw which is the i i ith row of the review matrix R E RE RE. (对于每个用户 u i u_i ui, u i u_i ui通常有一个评论列表 R E i w RE^w_i REiw,这是评论矩阵 R E RE RE的第 i i i行。)
- Therefore, for each u i u_i ui, we process this review set R E i w RE^w_i REiw that u i u_i ui has written by doc2vec to get a user review feature vector R E i U RE^U_i REiU. (因此,对于每个 u i u_i ui,我们处理 u i u_i ui由doc2vec编写的评论集 R E i w RE^w_i REiw,以获得 用户评论特征向量 R E i u RE^u_i REiu。)
-
(5) In our model, we set k = 32 k = 32 k=32 in MF and doc2vec due to the preliminary experiment results. (在我们的模型中,根据初步实验结果,我们在MF和doc2vec中设置了 k = 32 k=32 k=32。)
- In details, we conduct experiments which tune k k k in the range of { 8 , 16 , 32 , 64 } \{8, 16, 32, 64\} {8,16,32,64}. (具体来说,我们进行了实验,将 k k k调谐在{8,16,32,64}的范围内。)
- When k = 32 k = 32 k=32, both MF and doc2vec get the best preliminary results. (当 k = 32 k=32 k=32时,MF和doc2vec都获得了最好的初步结果。)
- Therefore, the combination features U i U_i Ui of u i u_i ui learned from his/her review behavior are represented as follows: (因此,从他/她的评论行为中学到的 U i U_i Ui组合特征如下所示:)
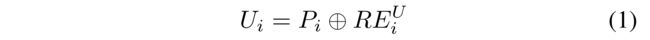
- where ⊕ \oplus ⊕ is the concatenation operator of two sets. (是两个集合的串联运算符)
Modeling Item Properties: (为项目属性建模)
-
(1) Items rated and reviewed by a user naturally reflect the interest of the user, thus the properties lie behind an item should be treated as a part of user features. (用户评分和评论的项目自然反映了用户的兴趣,因此项目背后的属性应被视为用户功能的一部分。)
- It is worth mentioning that we are the first work considering item’s properties as part of user features. (值得一提的是,我们是第一个将物品属性作为用户功能一部分考虑的工作。)
- In reality, an item v j v_j vj can receive both ratings and reviews, which reflect an item’s features in different forms. (实际上,一个项目 v j v_j vj可以接受评分和评论,以不同的形式反映项目的特征。)
- For an item, its all received reviews and ratings are associated with its features. (对于一个项目,它所有收到的评论和评级都与它的特性相关联。)
- For all the ratings given to v j v_j vj, we factorize the rating matrix R R R into user latent matrix P m × k P^{m\times k} Pm×k and item latent matrix Q n × k Q^{n\times k} Qn×k respectively, where k k k is the dimension of latent factors. (对于给定给 v j v_j vj的所有评分,我们将评分矩阵 R R R分解为用户潜在矩阵 P m × k P^{m\times k} Pm×k和项目潜在矩阵 Q n × k Q^{n\times k} Qn×k,其中 k k k是潜在因素的维度。)
- Q n × k Q^{n \times k} Qn×k is the item latent matrix, which represents the relation between items and latent factors. (是项目潜在矩阵,表示项目和潜在因素之间的关系。)
- Then Q j Q_j Qj denotes the latent factor vector of item v j v_j vj learned from rating matrix. (然后, Q j Q_j Qj表示从评分矩阵中学习到的 v j v_j vj项的潜在因子向量。)
- Then for each item v j v_j vj, all its received reviews set R E j c RE^c_j REjc is the j j jth column of R E RE RE. (然后,对于每个 v j v_j vj项目,其所有收到的评论集 R E j c RE^c_j REjc都是 R E RE RE的第 j j j列。)
- To learn the item features R E j I RE^I_j REjI from the received reviews, we employ doc2vec to deal with all the received reviews R E j c RE^c_j REjc. (为了从收到的评论中了解商品的特点 R E j I RE^I_j REjI,我们使用了doc2vec 来处理 所有收到的评论 R E j c RE^c_j REjc。)
- Finally, the item v j v_j vj’s features V j V_j Vj are represented as the combination of these two parts as follows: (最后, v j v_j vj项的功能 v j v_j vj表示为这两部分的组合,如下所示:)
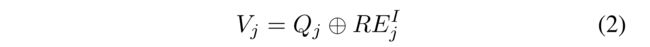
-
(2) In real world, a user uiusually rates/reviews a list of items, denoting as { v 1 , . . . , v j } \{v_1, ..., v_j\} {v1,...,vj}, and thus there is { V 1 , . . . , V j } \{V_1, ..., V_j\} {V1,...,Vj}. (在现实世界中,用户通常会对项目列表进行评分/审核,表示为 { v 1 , … , v j } \{v_1,…,v_j\} {v1,…,vj},因此有 { V 1 , . . . , V j } \{V_1, ..., V_j\} {V1,...,Vj}。)
-
In order to obtain the representative item features related to u i u_i ui, we average all the items’ features related to u i u_i ui as follows: (为了获得与 u i u_i ui相关的代表性项目特征,我们对与 u i u_i ui相关的所有项目特征进行平均,如下所示:)
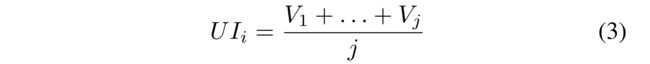
Feature Concatenation: (特征拼接)
-
(1) According to the aforementioned user modeling steps, the items’ properties are mined from all the received ratings and reviews, and then they are considered as a part of user features. Together with user review behavior features, the user feature F u i F_{ui} Fui is calculated as: (根据上述用户建模步骤,从所有收到的评分和评论中挖掘项目的属性,然后将其视为用户特征的一部分。与用户评论行为特征一起,用户特征 F u i F_{ui} Fui计算如下:)
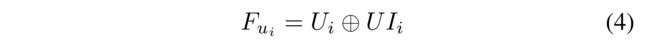
- where F u i F_{u_i} Fui has covered both user review behavior features and item features. (涵盖了用户评论行为特征和项目特征。)
-
(2) We want to mention that the concatenation vector obtained from pre-trained MF and doc2vec guarantees the accuracy of the input for the following pair-wise deep neural network, which contributes to the final superior performance. (我们想指出的是,从预先训练的MF和doc2vec获得的串联向量保证了以下成对深层神经网络输入的准确性,这有助于最终获得优异的性能。)
-
(2) To the best of our knowledge, this is the first comprehensive user modeling method which considers and integrates all the above features. (据我们所知,这是第一个综合考虑并集成了上述所有功能的用户建模方法。)
4.3 C. Pair-wise Multi-layer Projection (成对的MLP)
-
(1) After user feature modeling, we feed the concatenation user feature representations of pairs of users into a pair-wise deep neural network to further capture and represent users’ characteristics, which provides a deep understanding of user. (在用户特征建模之后,我们将成对用户的串联用户特征表示输入到一个成对的深度神经网络中,进一步捕获和表示用户的特征,从而提供对用户的深入理解。)
-
(2) The pair-wise deep neural network has a multi-layer perception unit and a similarity calculation unit. The input of the deep neural network are pairs ( F u i , F u j ) (F_{u_i}, F_{u_j}) (Fui,Fuj) for each pair of ( u i , u j ) (u_i, u_j) (ui,uj). The similarity calculation unit then calculates the similarity between the user pair ( u i , u j ) (u_i, u_j) (ui,uj). (成对深层神经网络具有 多层感知单元 和 相似性计算单元 。深度神经网络的输入是每对 ( u i , u j ) (u_i,u_j) (ui,uj)的对 ( F u i , F u j ) (F_{u_i},F_{u_j}) (Fui,Fuj)。然后,相似性计算单元计算用户对 ( u i , u j ) (u_i,u_j) (ui,uj)之间的相似性。)

-
(3) Formally, for a deep neural network, if we denote the input vector as x x x, the final output latent representation vector as y y y, the output of intermediate hidden layers by l i , i = 1 , . . . , N − 1 l_i, i = 1,...,N − 1 li,i=1,...,N−1, the i t h i_{th} ith weight matrix by W i W_i Wi, and the i t h i_{th} ith bias term by b i b_i bi, we have (形式上,对于深度神经网络,如果我们将输入向量表示为 x x x,最终输出潜在表示向量表示为 y y y,中间隐藏层的输出表示为 l i , i = 1 , . . . , N − 1 l_i, i = 1,...,N − 1 li,i=1,...,N−1)

- where we use RELU as the activation function f f f at hidden layers and the output layer as: (其中,我们将RELU用作隐藏层的激活函数 f f f,将输出层用作:)

- where we use RELU as the activation function f f f at hidden layers and the output layer as: (其中,我们将RELU用作隐藏层的激活函数 f f f,将输出层用作:)
-
(4) Therefore, for each trusted pair of users u i u_i ui and u j u_j uj, the features F u i F_{u_i} Fui and F u j F_{u_j} Fuj are finally mapped to a low-dimensional vector in a latent space through our pair-wise deep neural network as shown in Equation 7. (因此,对于每个受信任的用户 u i u_i ui和 u j u_j uj对,特征 F u i F_{u_i} Fui和 F u j F_{u_j} Fuj最终通过我们的成对深层神经网络映射到潜在空间中的低维向量,如式子7所示)
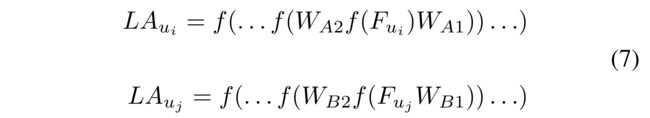
- where ( L A u i , L A u j ) (LA_{u_i}, LA_{u_j}) (LAui,LAuj) is the output of the multi-layer perception unit, W A 1 W_{A1} WA1 and W B 1 W_{B1} WB1 are the first layer weighting matrices for u i u_i ui and u j u_j uj, and W A 2 W_{A2} WA2 and W B 2 W_{B2} WB2 for the second layer, and so on. (其中 ( L A u i , L A u j (LA_{u_i},LA_{u_j} (LAui,LAuj是多层感知单元的输出, W A 1 W_{A1} WA1和 W B 1 W_{B1} WB1是 u i u_i ui和 u j u_j uj的第一层加权矩阵,以及 W A 2 W_{A2} WA2和 W B 2 W_{B2} WB2的第二层加权矩阵,依此类推。)
4.4 D. Trust measured by cosine similarity (用余弦相似性度量信任度)
-
(1) According to the user latent features learned from the deep neural network, we then calculate the similarity between user latent features. Finally, the similarity value will be used to measure the trust relations between pairs of users. In this paper, we employ cosine similarity to calculate the similarity between uiand uj, which is calculated as: (根据从深度神经网络中学习到的用户潜在特征,计算用户潜在特征之间的相似度。最后,相似度值将用于衡量用户对之间的信任关系。在本文中,我们使用余弦相似性来计算Ui和uj之间的相似性,计算公式如下:)

-
(2) For optimization, our model is trained with the squared loss function L s q r L_{sqr} Lsqr, which is widely used in existing work: (为了优化,我们的模型用平方损失函数 L s q r L_{sqr} Lsqr训练, 在现有工作中广泛使用:)
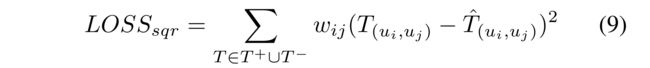
- where w i j w_{ij} wij is the parameter to control the threshold of training loss. (是控制训练损失阈值的参数)
- T + T^+ T+ denotes the explicit trust relations (表示显式信任关系)
- and T − T^− T− denotes the unobserved trust relations, (表示未观察到的信任关系)
- we use T + ∪ T − T^+ \cup T^− T+∪T− as the training set. (训练集)
- T ^ ( u i , u j ) \hat{T}_{(u_i, u_j)} T^(ui,uj) is the label of user pairs.
- The label of a trusted pair is 1. (受信任对的标签为1)
- We want to mention that the trust label 1 here is different from the binary classification label 1. (我们想提到的是,这里的信任标签1不同于二进制分类标签1。)
- In fact, the output of our deep neural network is the trust value ranging from 0 to 1. Therefore, our deep Trust model is totally different from the binary classification problem from both the original idea and the training process. (事实上,我们的深度神经网络的输出是0到1之间的信任值。因此,我们的深度信任模型从最初的想法和训练过程上都与二进制分类问题完全不同。)
- The choice of the different loss function is not in the discussion of our work, we can explore the influence of different loss functions in future work. (不同损失函数的选择不在我们工作的讨论中,我们可以在未来的工作中探索不同损失函数的影响。)
- For training the parameters of weight matrix on each layer, we use backpropagation to update the model parameters with batches. Algorithm 1 implements the training process. (为了在每一层上训练权重矩阵的参数,我们使用反向传播来批量更新模型参数。算法1实现了训练过程。)
-
(3) Finally, all the testing pairs are ranked in decreasing order as a list according to the calculated similarity score. (最后,根据计算出的相似度得分,将所有测试对按降序排列为一个列表。)
- In this paper, we select the pairs of users whose similarity scores are larger than 0.5 as the final predicted trust pairs. (在本文中,我们选择相似度得分大于0.5的用户对作为最终预测的信任对。)
- To the best of our knowledge, this is the first work to directly model user features as the input of deep neural network for measuring trust relations, which is different from the existing works and provides a brand new perspective for trust prediction. (据我们所知, 这是首次将用户特征直接建模为深度神经网络的输入 ,用于测量信任关系,这与现有的工作不同,为信任预测提供了一个全新的视角。)
V. EXPERIMENTS AND ANALYSIS (实验与分析)
We carry out a set of experiments against two real-world datasets to answer the following questions: (我们针对两个真实数据集进行了一系列实验,以回答以下问题:)
- Q1: How does our proposed method perform in comparison with the state-of-the-art approaches in terms of trust prediction accuracy? (问题1:与最先进的方法相比,我们提出的方法在信任预测准确性方面表现如何?)
- Q2: How do different parameters affect the performance of our method? (问题2:不同的参数如何影响我们方法的性能?)
- Q3: How is our method sensitive to the sparsity of the existing trust relations? (问题3:我们的方法对现有信任关系的稀疏性如何敏感?)
- Q4: How do reviews, ratings, and item properties in our user modeling contribute to the trust prediction, respectively? (问题4:我们的用户建模中的评论、评分和项目属性分别对信任预测有何贡献?)
5.1 A. Experimental Settings
1) Datasets for Evaluation:
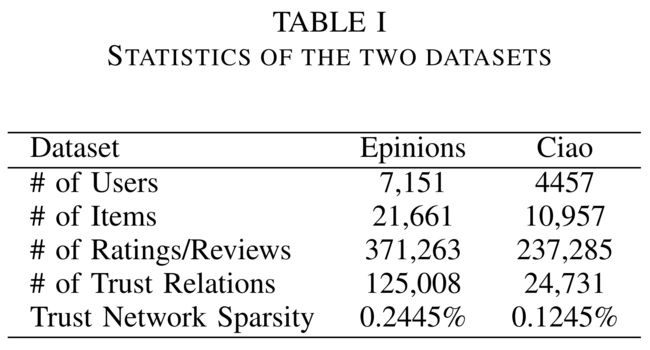
- We evaluate our method against two widely used real-world datasets Epinions and Ciao, which are publicly accessible [1]. (我们将我们的方法与两个广泛使用的现实世界数据集Epinion和Ciao进行对比评估,这两个数据集是可公开访问的[1]。)
- Epinions and Ciao are two knowledge-sharing websites which contain several kinds of information. (Epinions和Ciao是两个知识共享网站,包含多种信息。)
- The user to item interaction information, which includes the items a user have rated/reviewed. Also, there is rating value ranging from 1 to 5, which denotes an overall preference that a user to an item. (用户对项目的交互信息,包括用户已评分/评论的项目。此外,评分值从1到5不等,表示用户对某个项目的总体偏好。)
- Besides, there are reviews which contain sufficient user attitude and preference in text. In addition, these datasets contain explicit trust relations between users since the user in these websites can maintain a trust list. (此外,还有一些评论包含了足够的用户态度和偏好。此外,这些数据集包含用户之间明确的信任关系,因为这些网站中的用户可以维护信任列表。)
- Thus, Epinions and Ciao are ideal datasets that have been used widely for trust prediction. (因此,Epinions和Ciao是广泛用于信任预测的理想数据集。)
- Most of the existing works mainly focus on the trust relation matrix while ignoring the abundant other available information when predicting trust relations. (现有的研究大多集中在 信任关系矩阵 上,而在预测信任关系时忽略了丰富的其他可用信息。)
- For these two datasets, we retain the users with at least 15 rating/reviews and items with at least 5 ratings/reviews. (对于这两个数据集,我们保留了至少有15个评级/评论的用户和至少有5个评级/评论的项目。)
- The statistics of the two datasets are summarized in Table I. In this work, we adopt the widely used prediction accuracy as the evaluation metric. (表一总结了这两个数据集的统计数据。在这项工作中,我们采用了广泛使用的预测精度作为评估指标。)
2) Implementation:
- We implement our proposed model on Tensorflow1.
- When training our model, the ratio of trust pairs and unobserved negative user pairs is 1 : 5. (在训练我们的模型时,信任对和未观察到的负用户对的比率为1:5。)
- For the deep neural network, we set the hidden layer number d as 4, when d > 4, the performance of our model has almost no change. (对于深层神经网络,我们将隐层数d设置为4,当d>4时,我们的模型的性能几乎没有变化。)
- The latent factor in our experiments is k k k and we set k k k as 32. (我们实验中的潜在因素是 k k k,我们将 k k k设为32。)
- In our model, we get 4 sets of latent features learned in user modeling, thus the input dimension of our deep neural network is k ∗ 4 k ∗ 4 k∗4. We set the output dimension of our model as k ∗ 4 2 \frac{k∗4} {2} 2k∗4.
- Following [17], we initialize the network weights with uniform distribution in the range between − 6 / ( i n s i z e + o u t s i z e ) − \sqrt{6/(insize + outsize)} −6/(insize+outsize) and
6 / ( i n s i z e + o u t s i z e ) \sqrt{6/(insize + outsize)} 6/(insize+outsize), where insize and outsize are the numbers of input and output units, respectively. - The parameters are updated based on gradient descent optimizer algorithm with the learning rate of 0.005 and the decay factor of 1 e − 3 1e − 3 1e−3. (参数更新基于梯度下降优化算法,学习率为0.005,衰减因子为1e− 31e−3.)
- We set the training batch size to 1000. (我们将训练批量设置为1000。)
- For each result, the experiments are conducted 5 times and the average result is reported. (对于每个结果,进行5次实验,并报告平均结果。)
5.2 B. Effectiveness of Our Model
To illustrate the performance of our model to answer question Q1, we compare our proposed deepTrust prediction model with six baseline approaches including both classical and the state-of-the-art methods, which are introduced in details as follows: (为了说明我们的模型在回答问题Q1时的性能,我们将我们提出的deepTrust预测模型与六种基线方法进行了比较,包括经典方法和最先进的方法,详细介绍如下:)
-
Random: This is a basic baseline approach that randomly selects trust relations among the pairs of users. (这是一种基本的基线方法,随机选择用户对之间的信任关系。)
-
TP: Trust propagation evaluates trust relations along a path between users, which is the most typical trust network structure based trust prediction approach [4]. 信任传播沿着用户之间的路径评估信任关系,这是最典型的基于信任网络结构的信任预测方法[4]。()
-
RS: Rating similarity predicts trust values between users by calculating the similarity of their ratings [33]. (评级相似性通过计算用户评级的相似性来预测用户之间的信任值[33]。)
-
MF: Matrix Factorization is a classical low-rank approximation based trust prediction approach, which performs matrix factorization on the matrix representation of trust relations [5]. (矩阵分解是一种经典的 基于低秩近似的信任预测 方法,它对信任关系的矩阵表示进行矩阵分解[5]。)
-
hTrust: hTrust adds rating similarity as regularization to trust matrix factorization for trust prediction [1]. It is a state-of-the-art trust prediction approach combining the additional knowledge and the low-rank approximation model. (hTrust将评级相似性作为正则化添加到信任预测的信任矩阵分解中[1]。它是一种结合了附加知识和低秩近似模型的最先进的信任预测方法。)
-
Power-Law: Power-Law distribution aware trust prediction approach is a state-of-the-art low-rank approximation based approach, which models the power-law distribution property of trust relations in online social networks by learning both the low-rank and the sparse part of a trust network [3]. (幂律分布感知信任预测方法是一种基于低秩近似的最新方法,它通过学习信任网络的低秩和稀疏部分来模拟在线社交网络中信任关系的幂律分布特性[3]。)
-
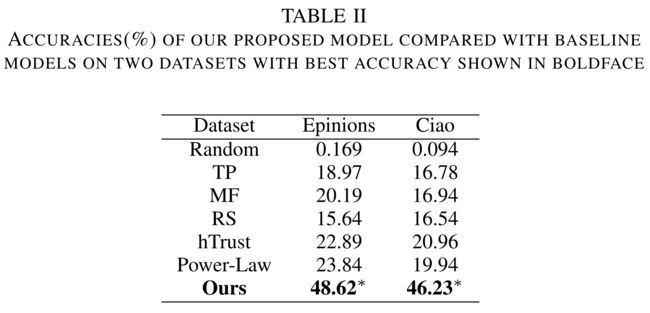
The best trust prediction accuracy of our model and baseline models are summarized in Table II. The ratio of training size and testing size is 80% : 20%. There are N labeled trust relations, M pairs of them are predicted as trust relations, the trust prediction accuracy is calculated as M/N ×100%. (表II总结了我们的模型和基线模型的最佳信任预测精度。培训规模与考试规模之比为80%:20%。有N个标记的信任关系,其中M对被预测为信任关系,信任预测精度计算为M/N×100%。)
-
As can be seen in Table II, our proposed method performs the best and it outperforms the six comparison approaches clearly by an average of 31%, ranging from 25% to 47%. In addition, our model is significantly better than power-law, hTrust and MF, while power-law, MF and hTrust are generally better than TP . This result indicates that our novel deep trust prediction model is better than the low-rank approximation based models and the low-rank approximation based models are better than the trust network structure based models, which shows that our new deep prediction model has a superior performance compared with the existing works. (如表二所示,我们提出的方法表现最好,明显优于六种比较方法,平均为31%,从25%到47%不等。此外,我们的模型明显优于幂律、hTrust和MF,而幂律、MF和hTrust通常优于TP。这一结果表明,我们新的深度信任预测模型优于基于低秩近似的模型,基于低秩近似的模型优于基于信任网络结构的模型,这表明我们新的深度信任预测模型具有优于现有模型的性能。)
-
As can be seen in Table II, hTrust achieves better performance than MF by incorporating rating similarity as regularization, which shows that user similarities play an important role in trust prediction. Power-Law distribution aware trust prediction approach achieves much better results compared with other baseline approaches. It also shows that considering the sparsity problem in trust network is quite helpful to improve trust prediction accuracy. These results clearly confirm that incorporating the similarity between users features will alleviate the data sparsity problem and can improve the accuracy of trust prediction. (从表2中可以看出,hTrust通过将评级相似性作为正则化来实现比MF更好的性能,这表明用户相似性在信任预测中起着重要作用。与其他基线方法相比,幂律分布感知信任预测方法取得了更好的结果。研究还表明,考虑信任网络中的稀疏性问题有助于提高信任预测的准确性。这些结果清楚地证实,结合用户特征之间的相似性将缓解数据稀疏性问题,并可以提高信任预测的准确性。)
-
Therefore, we believe that the reasons for our better performance comparing existing approaches are: (因此,我们认为,与现有方法相比,我们的绩效更好的原因是:)
- (1) the comprehensive user modeling which captures more details of user features to affect the accuracy of similarity measurement. (全面的用户建模,捕捉用户特征的更多细节,从而影响相似性度量的准确性。)
- (2) the pairwise deep learning networks provide a powerful tool to mine features in the latent space and are helpful for improving the accuracy of similarity easurement. (两两深度学习网络为挖掘潜在空间中的特征提供了强有力的工具,有助于提高相似性度量的准确性。)
- (3) our method can alleviate the suffering from the data sparsity problem. (我们的方法可以减轻数据稀疏问题带来的痛苦。)
5.3 C. Impact of Training Size (培训规模的影响)
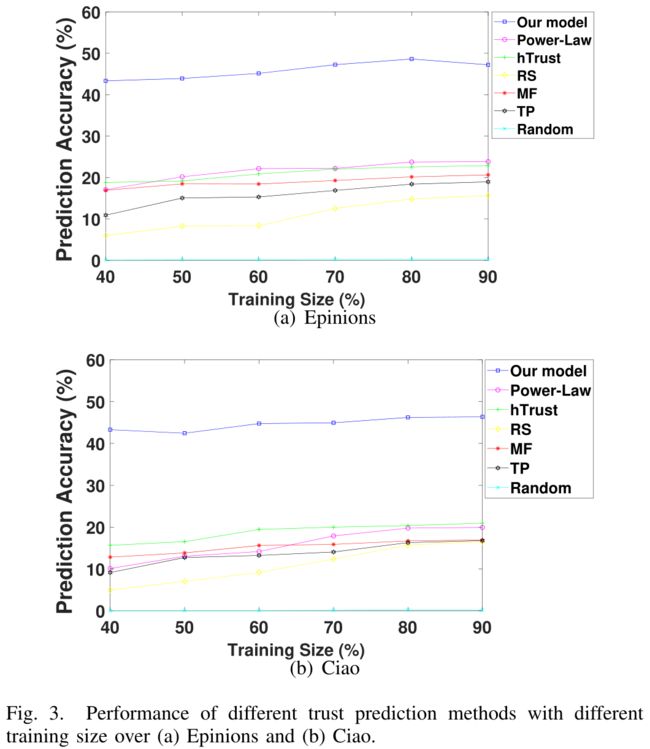
- To further answer the question Q1, we conduct experiments on different training set sizes to verify the stable ability of our model. The user pairs are sorted in chronological order in terms of the time when they establish trust relations. (为了进一步回答问题Q1,我们在不同大小的训练集上进行了实验,以验证我们模型的稳定性。用户对按照建立信任关系的时间顺序进行排序。)
- We choose the first x% as the training set and the remaining ( 1 − x ) (1− x) (1−x)% as the testing set.
- x x x% is varied as {40,50,60,70,80,90} over two datasets. (在两个数据集上变化为{40,50,60,70,80,90}。)
- The results are shown in Fig.3(a) for Epinions and Fig.3(b) for Ciao, respectively. (结果分别显示在图3(a)中的Epinions和图3(b)中的Ciao。)
- As can be seen from these two figures, our model significantly outperforms the baseline models among all the training size by an average prediction accuracy of 27%. (从这两个数字可以看出,在所有训练规模中,我们的模型显著优于基线模型,平均预测准确率为27%。)
- As the training size varies from 40% to 90%, our model always achieves prediction accuracy higher than 40% and the performance is stable over both datasets. (由于训练规模在40%到90%之间变化,我们的模型的预测精度始终高于40%,并且在两个数据集上的性能都是稳定的。)
- When the training size is 80%, our model achieves the best trust prediction accuracy performance at 48.62% and 46.23% over these two datasets respectively. (当训练规模为80%时,我们的模型在这两个数据集上的信任预测准确率分别达到48.62%和46.23%。)
- These results show that the performance of our proposed model is not only superior but also robust at different training size settings. (这些结果表明,在不同的训练规模设置下,我们提出的模型不仅性能优越,而且具有鲁棒性。)
 )
)
5.4 D. Impact of Parameters (参数的影响)
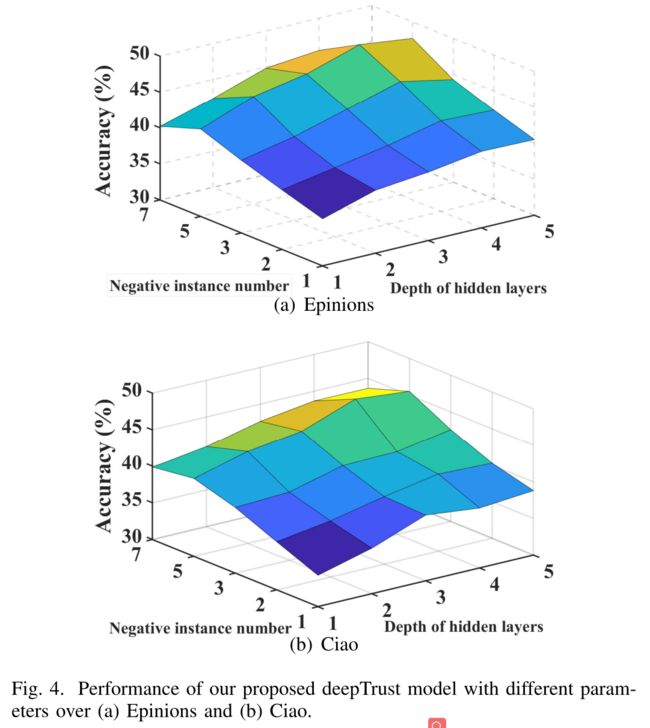
In this section, we mainly illustrate the influence of two important parameters, namely, negative instance number and the network hidden layer number to answer question Q2. The results over the two datasets are shown in Fig.4 (a) Epinions and Fig.4 (b) Ciao respectively. (在这一部分中,我们主要说明两个重要参数,即负实例数和网络隐藏层数对回答问题Q2的影响。这两个数据集的结果分别如图4(a)和图4(b)所示。)
1) Number of Negative Instances: (负面实例的数量)
- As mentioned in Algorithm 1, for per trusted user pair, we need to generate user pairs with unobserved trust relations as negative instances for deep neural network training. (如算法1所述,对于每个可信用户对,我们需要生成具有未观察到的信任关系的用户对,作为深入神经网络训练的负面实例。)
- We conduct experiments by setting different negative instances to observe the performance variance over the two datasets. (我们通过设置不同的负实例来进行实验,以观察两个数据集的性能差异。)
- As can be seen in the figures, the performance of our model increases with the negative instance number from 1 to 5. (从图中可以看出,我们模型的性能随着负实例数从1增加到5而增加。)
- Then when the negative instance number increases to 7, the performance begins to decrease. (然后,当负实例数增加到7时,性能开始下降。)
- This is because the proper number of negative instances are helpful for training model parameters while too many unobserved negative instances may introduce noises since the unobserved negative instances include not only the distrust pairs but also the pairs that haven’t established trust relations. (这是因为适当数量的负实例有助于训练模型参数,而太多未观察到的负实例可能会引入噪声,因为未观察到的负实例不仅包括不信任对,还包括未建立信任关系的对。)
- In our model, the optimal negative instances number is 5, which is consistent with the previous research literature [34]. (在我们的模型中,最佳负面实例数为5,这与之前的研究文献[34]一致。)
2) Depth of Layers in Deep Neural Network: (深层神经网络中的层深度)
- We map user pair’s features into low-dimensional representations through the neural network with multiple deep hidden layers in our
model. (我们通过神经网络将用户对的特征映射为低维表示,在我们的模型中有多个深隐藏层。) - Thus we conduct experiments to investigate the influence of different hidden layers. (因此,我们进行实验来研究不同隐藏层的影响。)
- The number of hidden layers is represented as d, in our experiments, d varies from 1 to 5. (隐藏层的数量表示为d,在我们的实验中,d从1到5不等。)
- In general, the performance of our model increases with the increase of deep neural network layers from 1 to 4, which indicates that more deep neural network layers are more efficient for latent feature learning. (总的来说,我们的模型的性能随着深度神经网络层从1层增加到4层而提高,这表明更深层的神经网络层对于潜在特征学习更有效。)
- However, when the deep neural network layer d > 4, there is no much further improvement in the performance. (然而,当深度神经网络层d>4时,性能没有进一步改善。)
- The optimal depth of layers in our pair-wise deep neural network is 4. (我们的成对深度神经网络的最佳层深度为4。)
- The results also show that different depths of layers in our pair-wise deep neural network influence the trust prediction accuracy by influencing the final feature representation. (结果还表明,在我们的成对深度神经网络中,不同的层深度通过影响最终的特征表示来影响信任预测精度。)
- Deeper layers of the deep neural network are more effective to capture complex user features and thus more efficient for measuring trust relations. (更深层次的深层神经网络更有效地捕捉复杂的用户特征,从而更有效地测量信任关系。)
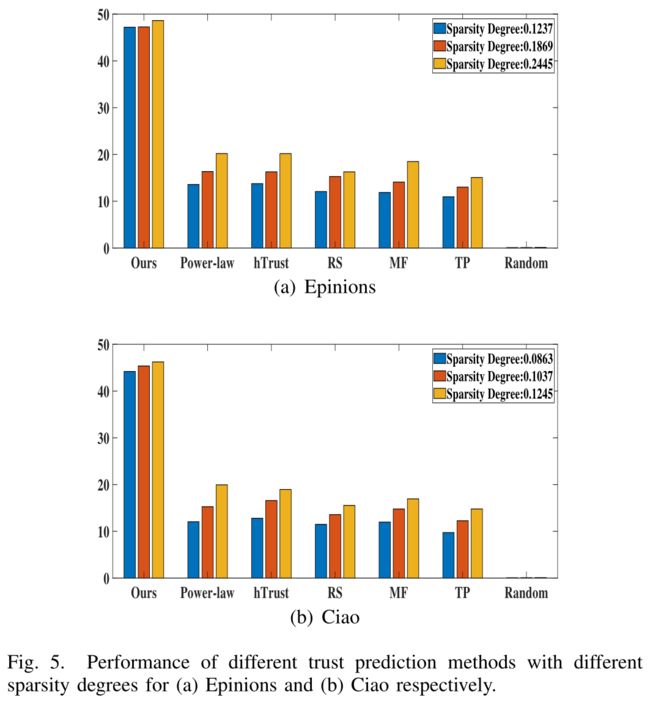
5.5 E. Impact of Data Sparsity Degree (数据稀疏度的影响)
-
To answer question Q3, we conduct experiments on different trust relation sparsity degree to show that our model is insensitive to the sparsity degree of trust relations. In reality, online social networks are usually very sparse, and how to overcome the data sparsity problem has been a long-standing challenge. (为了回答问题3,我们对不同的信任关系稀疏度进行了实验,结果表明我们的模型对信任关系的稀疏度不敏感。实际上,在线社交网络通常非常稀疏,如何克服数据稀疏问题一直是一个长期的挑战)
-
For a dataset with m users, if there exists trtrust relations, then the trust relation sparsity degree is ( t r / m ∗ m ) (t_r / m ∗ m) (tr/m∗m). Sparsity degree indicates how sparse the dataset is. The smaller the sparsity degree is, the sparser the trust relations. (对于具有m个用户的数据集,如果存在trust关系,则信任关系稀疏度为 ( t r / m ∗ m ) (t_r / m ∗ m) (tr/m∗m) 。稀疏度表示数据集的稀疏程度。稀疏度越小,信任关系越稀疏。)
-
Keeping the same number of ratings/reviews for each user, we process Epinions and Ciao datasets with different sparsity degree 0.2445%,0.1869%,0.1237% and 0.1245%,0.1037%,0.0863%, respectively. (在保持每个用户的评分/评论数相同的情况下,我们分别以0.2445%、0.1869%、0.1237%和0.1245%、0.1037%和0.0863%的稀疏度处理Epinions和Ciao数据集。)
- As can be seen in Fig.5, our model has a stable prediction accuracy (about 46%) regardless of the changes of the trust relation sparsity degree. (如图5所示,无论信任关系稀疏度如何变化,我们的模型都具有稳定的预测精度(约46%)。)
- In contrast, the prediction accuracy with baseline models declines rapidly when the dataset becomes sparser. (相比之下,当数据集变得稀疏时,基线模型的预测精度会迅速下降。)
- It is because that these typical trust prediction works mainly calculate trust relations relying on the trust relation matrix, thus the prediction accuracy will be directly influenced by the change of the number of explicit trust relations. (这是因为这些典型的信任预测工作主要依靠信任关系矩阵来计算信任关系,因此显式信任关系数量的变化将直接影响预测精度。)
- Different from these existing methods, our model measures trust relations between users according to their feature similarities, which does not only rely on the density of trust relations. (与现有的方法不同,我们的模型根据用户之间的特征相似性来度量用户之间的信任关系,而不仅仅依赖于信任关系的密度。)
- Our model is more sparsity insensitive and alleviates the suffering from the trust relation sparsity problem. (我们的模型对稀疏性更不敏感,并且减轻了信任关系稀疏性问题带来的痛苦)
- Our method provides a better solution to tackle the challenge in trust prediction compared with existing works. (与现有方法相比,我们的方法为解决信任预测的挑战提供了更好的解决方案)
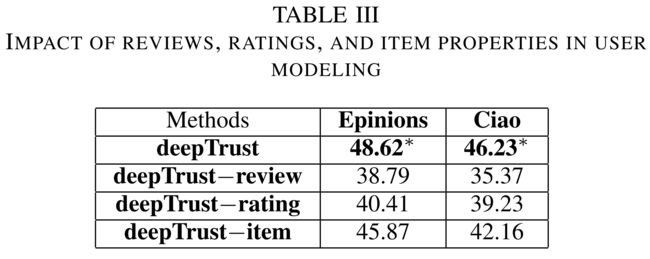
5.6 F . Impact of Reviews, Ratings, and Item properties in User Modeling (用户建模中评论、评分和项目属性的影响)
-
In the proposed deep Trust method, user modeling includes three parts: user reviews, user ratings, and item properties. (在提出的深度信任方法中,用户建模包括三个部分:用户评论、用户评分和项目属性。)
- To answer question Q4 on the significance of including these three parts, we conduct experiments on different configurations of the deep Trust model by reducing each part as shown in Table III. (为了回答关于包含这三个部分的重要性的问题Q4,我们对深度信任模型的不同配置进行了实验,减少了每个部分,如表III所示。)
- For convenience, let deepTrust−review, deepTrust−rating, deepTrust−item represent the customized methods of deepTrust without reviews, ratings and item properties respectively. (为了方便起见,让我们相信−回顾,深度信任−评级,深度信任−item分别代表deepTrust的定制方法,无需审查、评级和项目属性。)
-
As can be seen in Table III, compared with the deepTrust, the prediction accuracy is decreased by about 10%, 7%, and 3% in deepTrust-review, deepTrust-rating, deepTrust-item respectively. (从表三可以看出,与deepTrust相比,deepTrust review、deepTrust rating和deepTrust item的预测准确率分别降低了约10%、7%和3%。)
- These results demonstrate how important these reviews, ratings and item properties affect the trust prediction accuracy. (这些结果表明,这些评论、评分和项目属性对信任预测准确性的影响是多么重要。)
- The results in Table III show that reviews are more important than ratings and item properties in trust prediction [11]. (表三的结果表明,在信任预测中,评价比评分和项目属性更重要[11]。)
- But reviews, ratings and item properties all have their contributions and should be considered together in trust prediction between people. (但是评论、评分和物品属性都有各自的贡献,在预测人与人之间的信任时应该一并考虑)
VI. CONCLUSION
-
(1) In this paper, we propose a novel deep user modeling framework deep Trust for trust prediction between people based on the homophily theory. (在本文中,我们提出了一个新的深度用户建模框架deepT-trust,用于基于同质理论的人与人之间的信任预测。)
- The proposed deepT rust provides comprehensive user modeling by utilizing user reviews, user ratings, items, and existing trust relations between users. (提出的deepT-rust通过利用用户评论、用户评级、项目和用户之间现有的信任关系,提供全面的用户建模。)
- The user features are further mapped into latent space by a pair-wise deep neural network. (通过一对深度神经网络将用户特征进一步映射到潜在空间。)
- The trust relations between pairs of users are measured by their latent feature similarities. (用户对之间的信任关系是通过潜在的特征相似性来衡量的。)
- The experiments results on two real-world datasets demonstrate the superior performance of the Deep Trust method and its sparsity insensitive property. (在两个真实数据集上的实验结果证明了深度信任方法的优越性能及其稀疏性不敏感特性。)
- It further demonstrates the existence of the social homophily theory that users with similar interest, taste, and experience are indeed more likely to develop trust relationships. (它进一步证明了社会同质理论的存在,即具有相似兴趣、品味和经验的用户确实更有可能发展信任关系。)
-
(2) We mainly focus on the networks extracted from Epinions and Ciao in this paper. (本文主要研究从Epinions和Ciao中提取的网络。)
- However, the proposed approach can be applied to any social networks with comments, ratings, and social interactions such as follow, like, retweet. (然而,所提出的方法可以应用于任何带有评论、评级和社交互动(如follow、like、retweet)的社交网络。)
- In future work, we will extend the current model to work on social media such as Twitter and apply it in various application areas, such as trust-aware recommendation, influence maximization. (在未来的工作中,我们将把当前的模型扩展到Twitter等社交媒体上,并将其应用于各种应用领域,如信任感知推荐、影响力最大化。)