Relation-Aware Collaborative Learning for Unified Aspect-Based Sentiment Analysis(ACL 2020)
目录
标题翻译:面向统一方面情感分析的关系感知协同学习
原文链接:https://aclanthology.org/2020.acl-main.340.pdf
摘要
1 引言
2 相关工作
3 方法
3.1 任务定义
3.2 模型架构
3.3关系感知合作学习
3.4 堆叠RACL到多层
3.5 训练过程
4 实验
4.1数据集和设置
4.2 对比结果
5 分析
5.1 Ablation Study
5.2 超参数的影响
5.3 案例研究
5.4 计算成本分析
6 总结
7 致谢
标题翻译:面向统一方面情感分析的关系感知协同学习
原文链接:https://aclanthology.org/2020.acl-main.340.pdf
摘要
基于方面的情感分析(ABSA)包括三个子任务,即方面词提取、意见词提取和方面级情感分类。现有的大多数研究只关注其中一个子任务。最近的一些研究尝试用统一的框架解决完整的ABSA问题。但是,三个子任务之间的交互关系还没有充分挖掘。我们认为这种关系编码了不同子任务之间的协作信号。例如,当评价词是“美味的”时,方面词必须是“食物”而不是“地方”。为了充分利用这些关系,我们提出了一个关系感知协作学习(RACL)框架,该框架允许子任务在堆叠的多层网络中通过多任务学习和关系传播机制协调工作。在三个真实数据集上的大量实验表明,对于完整的ABSA任务,RACL显著优于最先进的方法。
1 引言
基于方面的情感分析(ABSA)是一种细粒度的任务,旨在总结用户对句子中特定方面的意见。ABSA通常包括三个子任务,即方面词提取(AE)、意见词提取(OE)和方面级情感分类(SC)。举个例子,给你一个评价,“这个地方又小又挤,但是食物很好吃。, AE的目的是提取一组方面术语{“地方”,“食物”}。OE旨在提取一组意见术语{“小”,“局促”,“美味”}。同时,希望SC在“地方”和“食物”方面分别赋予“消极”和“积极”的情感极性。
现有的大多数工作将ABSA视为包含AE和SC的两步任务,他们为每个子任务开发了一种单独的方法(Tang et al, 2016;徐等,2018;李等,2018a;Hu et al, 2019),或将OE作为AE的辅助任务(Wang et al, 2017;Li等,2018b)。为了在实际应用中执行ABSA,需要将单独的方法绑在一起。最近,一些研究试图在统一框架下求解ABSA (Wang et al, 2018a;Li等,2019;He et al, 2019;Luo等人,2019)。
尽管它们的有效性,我们认为,这些方法并不足以为完整的ABSA任务产生令人满意的性能。关键原因是现有的研究在很大程度上忽略了不同子任务之间的交互关系。这些关系传递了协作信号,可以以相互的方式增强子任务。例如,观点术语“美味”可以作为方面术语“食物”的证据,反之亦然。在下面,我们首先分析了不同子任务之间的交互关系,然后介绍了我们的RACL框架,该框架是为利用这些关系而开发的。详细的关系概括在图1(左)中,每个箭头表示一种特定的关系Ri。

→R1表示AE与OE的成对关系。在实践中,方面术语必须是意见的对象,这表明大多数方面术语如“地方”只能用相应的意见术语如“小”和“局促”来修改,而不能用“美味”这样的术语来修改。因此,AE和OE可能彼此都有信息线索。
→R2表示SC与R1的三元关系。SC中的一个关键问题是确定方面与其上下文之间的依赖关系。例如,语境“小和局促”在预测“地方”的极性方面起着重要作用。这种依赖关系与强调方面术语和意见术语之间交互的R1高度一致。因此,SC和R1可以帮助彼此完善选择过程。
→R3表示SC与OE之间的二元关系。具体的意见术语通常传达具体的两极。例如,“fantastic”通常是积极的。OE中提取的意见术语在预测SC中的情绪极性时应多加注意。
→R4表示SC与AE的二元关系。在完整的ABSA任务中,方面术语是未知的,SC将为每个词分配一个极性。方面词,如“地方”、“食物”,有其相应的极性,而其他词则被认为是背景词,没有感情。也就是说,AE的结果应该有助于监督SC的训练。
在回顾有关ABSA任务的文献时,我们发现现有的单独方法要么不利用任何关系,要么只利用R1,将OE作为AE的辅助任务。同时,统一方法最多显式地利用R3和R4。鉴于此,我们提出了一种新的关系感知协作学习(RACL)框架,以充分利用整个ABSA任务中的交互关系。我们将我们的模型与现有的方法进行比较,通过它们在表1中利用交互关系的能力。

RACL是一个多层多任务学习框架,通过关系传播机制相互增强子任务的性能。对于多任务学习,RACL采用共享私有方案(Collobert and Weston, 2008;Liu et al, 2017)。子任务AE、OE和SC首先联合训练低级的共享特性,然后各自独立训练高级的私有特性。这样,共享特征和私有特征可以分别嵌入任务不变知识和面向任务的知识。对于关系传播,RACL通过在三个子任务之间交换信息线索来提高模型的能力。此外,RACL可以堆叠到多个层次,在不同的语义层次上进行协作学习。我们在三个数据集上进行了广泛的实验。结果表明,对于单个子任务和完整的ABSA任务,RACL都明显优于最先进的方法。
2 相关工作
基于方面的情感分析(ABSA)最早由Hu和Liu(2004)提出,近年来得到了广泛的研究(Zhang et al, 2018)。我们组织现有的研究如何执行子任务,并结合执行ABSA。
单独的方法 现有的大多数研究将ABSA视为包含方面项提取(AE)和基于方面的情感分类(SC)的两步任务,并开发了单独的方面项提取方法(Popescu and Etzioni, 2005;吴等,2009;Li等,2010;邱等,2011;刘等,2012;Chen et al, 2014;Chernyshevich, 2014;Toh and Wang, 2014;Vicente等人,2015;刘等,2015,2016;Yin等,2016;Wang等,2016;Li和Lam, 2017;Clercq等人,2017;He et al, 2017;徐等,2018;Yu et al, 2019), SC (Jiang et al, 2011;Mohammad et al, 2013;Kiritchenko等人,2014;董等,2014;Vo和Zhang, 2015;Ma等,2017;王等,2018b;朱倩,2018;Chen和Qian, 2019;Zhu等,2019)。有的采用辅助任务意见项提取(OE),利用它们之间的关系来提高AE的性能。对于完整的ABSA任务,必须以管道方式将两个步骤的结果合并在一起。这样完全忽略了AE/OE与SC之间的关系,上游AE/OE的误差会传播到下游SC。对于流水线方法来说,ABSA任务的整体性能不太理想。
统一的方法 近年来,一些研究试图在统一的框架下求解ABSA任务。统一的方法分为两种:折叠标记(Mitchell et al, 2013;Zhang等,2015;王等,2018a;Li et al, 2019)和联合训练(He et al, 2019;Luo等人,2019)。前者将AE和SC的标签组合在一起,构造出{B-senti, I-senti, O}等折叠标签。子任务需要毫无区别地共享所有可训练的特征,这很可能会混淆学习过程。此外,子任务之间的关系不能为这种类型的方法显式建模。同时,后者构建了一个多任务学习框架,每个子任务都有独立的标签,可以共享和私有特征。这使得不同子任务之间的交互关系可以为联合训练方法显式建模。然而,现有的研究都没有充分利用这种关系的力量。
我们的工作与上述方法的区别在于,我们提出了一个统一的框架,利用子任务之间的所有二元和三元关系来增强学习能力。
3 方法
3.1 任务定义
给定一个句子Se = {w1,…, wi,…, wn},我们将子任务AE、OE和SC定义为三个序列标记问题。如下图所示:

3.2 模型架构
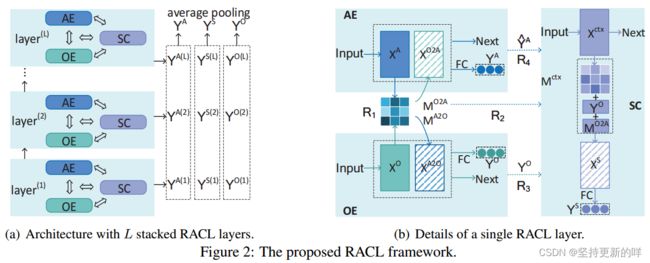
我们提出的RACL是一个统一的多任务学习框架,它允许传播交互关系(表示为相同的R1..R4(如图1所示),可以提高ABSA的性能,并且可以堆叠到多个层,在不同的语义级别上与子任务交互。我们在图2(a)中展示了RACL的整体架构,在图2(b)中展示了单个层的详细信息。
特别是,单个RACL层包含三个模块: AE, OE, SC,其中每个模块是为相应的子任务设计的。这些模块接收输入句子的共享表示,然后对其面向任务的特征进行编码。之后,它们传播关系R1..R4的协作学习,通过交换信息线索,进一步增强任务导向的特征。最后,三个模块将根据增强的特征对对应的标签序列![]() 、
、![]() 、
、![]() 进行预测。
进行预测。
在下面,我们首先在一个层中说明了关系感知协作学习,然后展示了整个RACL的堆叠和训练。
3.3关系感知合作学习
输入词向量 给定一个句子Se,我们可以用预训练的词嵌入(例如GloVe)或预训练的语言编码器(例如BERT)映射Se中的单词序列,以生成单词向量E = {e1,…, ei,…,en}∈![]() ,其中dw为词向量的维数。我们将在实验中检验这两种类型的词向量的影响。
,其中dw为词向量的维数。我们将在实验中检验这两种类型的词向量的影响。
共享-私有方案的多任务学习 为了进行多任务学习,不同的子任务应该关注共享训练样本的不同特征。受共享-私人方案的启发(科洛伯特和韦斯顿,2008;Liu等,2017),我们提取共享和私有特征,为AE、OE和SC模块嵌入任务不变和面向任务的知识。
为了对共享的任务不变特征进行编码,我们简单地将E中的每个ei送入一个全连接层,并生成一个转换后的向量hi∈![]() 。然后我们得到一个共享向量序列H={h1,…,hi,……,hn}∈
。然后我们得到一个共享向量序列H={h1,…,hi,……,hn}∈![]() ,每个句子将由所有子任务联合训练。
,每个句子将由所有子任务联合训练。
在共享任务不变特征H的基础上,AE、OE和SC模块将为相应的子任务编码面向任务的私有特征。我们选择一个简单的CNN作为编码器函数F,因为它的计算效率很高。
对于子任务AE和OE,确定方面词和意见词存在的关键特征是原始词和相邻词的表示。因此,我们构造了两个编码器来提取局部面向AE的特征![]() 和面向OE的特征
和面向OE的特征 :
:
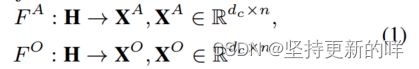
子任务SC的特征生成过程与AE/OE不同。为了确定一个方面术语的情感极性,我们需要从它的上下文中提取相关的语义信息。SC中的关键问题是确定方面术语与其上下文之间的依赖关系。此外,在完整的ABSA任务中,方面项在SC中是未知的,需要为Se中的每个词分配一个极性。基于这些观察,我们首先从H中编码上下文特征![]() :
:
![]()
然后我们将共享向量hi作为查询方面,利用注意机制计算查询与上下文特征之间的语义关系:

其中![]() 表示第i个查询词与第j个上下文词之间的依赖强度,
表示第i个查询词与第j个上下文词之间的依赖强度,![]() 是
是![]() 的归一化注意权重。我们根据两个单词之间的绝对距离添加一个系数log这部分。其基本原理是相邻的上下文单词应该更有助于情绪的极性。最后,对于方面查询wi,我们可以通过所有上下文特征(wi除外)的加权和得到全局面向SC的特征:
的归一化注意权重。我们根据两个单词之间的绝对距离添加一个系数log这部分。其基本原理是相邻的上下文单词应该更有助于情绪的极性。最后,对于方面查询wi,我们可以通过所有上下文特征(wi除外)的加权和得到全局面向SC的特征:![]()

协作学习的传播关系 在对面向任务的特征进行编码后,我们在子任务之间传播交互关系(R1..R4),以相互增强AE、OE和SC模块。
(1)R1为AE与OE的成对关系,表明AE与OE之间可能存在信息线索。为了对R1建模,我们希望面向AE的特征![]() 和面向OE的特征根据它们的语义关系交换有用的信息。以子任务AE为例,AE中单词与OE中单词的语义关系定义如下:
和面向OE的特征根据它们的语义关系交换有用的信息。以子任务AE为例,AE中单词与OE中单词的语义关系定义如下:

对于AE中的wi,我们可以对OE中的所有单词(wi本身除外)进行语义关系加权和,从OE中得到有用的线索![]() ,即:
,即:

然后我们将原始的面向AE的特征![]() 和OE中有用的线索
和OE中有用的线索![]() 连接起来作为AE的最终特征,并将它们输入到一个全连接层中来预测方面项的标签:
连接起来作为AE的最终特征,并将它们输入到一个全连接层中来预测方面项的标签:

其中![]() 为变换矩阵,
为变换矩阵,![]() 为AE的预测标记序列。
为AE的预测标记序列。
对于子任务OE,我们使用Eq. 5中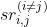 的转置矩阵来计算相应的
的转置矩阵来计算相应的![]() 。这样,AE和OE之间的语义关系就不受方向的影响而保持一致。那么我们可以从AE中得到有用的线索
。这样,AE和OE之间的语义关系就不受方向的影响而保持一致。那么我们可以从AE中得到有用的线索![]() ,并以类似的方式生成预测的标签序列
,并以类似的方式生成预测的标签序列![]() ,即:
,即:
![]()
另外,每个wi不能同时是方面项和意见项,因此我们增加了一个正则化铰链损失来约束![]() 和
和![]() :
:
![]()
其中,P为给定条件下的概率。
(2)R2是SC和R1之间的三元关系。请记住,方面项及其上下文之间的依赖关系对于子任务SC是至关重要的,并且我们已经使用标准化注意力权重![]() 计算了这种依赖关系。因此,我们可以通过将R1传播到
计算了这种依赖关系。因此,我们可以通过将R1传播到![]() 来模拟R2。我们用
来模拟R2。我们用![]() 作为R1的代表,加在
作为R1的代表,加在![]() 上表示R1对SC的影响,更正式的定义R2为:
上表示R1对SC的影响,更正式的定义R2为:

实际上,![]() 从词提取的角度表征了方面词与上下文的依赖关系,而
从词提取的角度表征了方面词与上下文的依赖关系,而![]() 从情感分类的角度表征了方面词与上下文的依赖关系。双视图关系R2有助于细化抽取子任务和分类子任务的选择过程。
从情感分类的角度表征了方面词与上下文的依赖关系。双视图关系R2有助于细化抽取子任务和分类子任务的选择过程。
(3)R3为SC与OE的二元关系,表明提取的意见项在预测情绪极性时应多加注意。为了建模R3,类似于R2的方法,我们使用OE中生成的标签序列![]() 更新SC中的:
更新SC中的: ![]()

通过这样做,意见术语可以在注意机制中获得更大的权重。因此,它们将对情绪极性的预测做出更大贡献。
在得到![]() 的交互值后,我们可以相应地重新计算公式4中面向SC的特征
的交互值后,我们可以相应地重新计算公式4中面向SC的特征![]() 。然后我们将H和
。然后我们将H和![]() 连接起来作为SC的最终特征,并将它们馈送到一个完全连接的层中,以预测候选方面项的情感极性:
连接起来作为SC的最终特征,并将它们馈送到一个完全连接的层中,以预测候选方面项的情感极性:

其中![]() 为变换矩阵,
为变换矩阵,![]() 为SC的预测标记序列。
为SC的预测标记序列。
(4)R4为SC和AE的二元关系,说明AE的结果有助于监督SC的训练。显然,只有方面词具有情感极性。虽然SC需要为每个单词分配一个极性,但在训练过程中,我们知道AE中的ground truth方面术语。因此,我们直接使用地面实况标记序列![]() 的AE完善标记过程。具体来说,只有对真方面项的预测标签才会被计算在训练过程中:
的AE完善标记过程。具体来说,只有对真方面项的预测标签才会被计算在训练过程中:

如果wi是方面项,![]() 等于1,如果不是,则等于0。注意,这种方法只在训练过程中使用。
等于1,如果不是,则等于0。注意,这种方法只在训练过程中使用。
3.4 堆叠RACL到多层
当使用单个RACL层时,AE、OE和SC模块仅在较低的语言水平上提取相应的特征,可能不足以作为标记每个单词的证据。因此,我们将RACL堆叠到多层,获得子任务的高级语义特征,这有助于进行深度协作学习。

其中T∈{A, O, S}表示具体的子任务,L为层数。这种类似快捷方式的体系结构可以使底层的特征具有意义和信息,从而帮助高层做出更好的预测。
3.5 训练过程
在为句子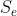 生成标记序列
生成标记序列![]() 、
、![]() 和
和![]() 之后,我们计算每个子任务的交叉熵损失:
之后,我们计算每个子任务的交叉熵损失:
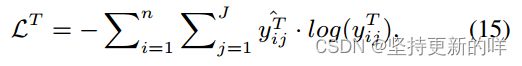
其中T∈{A, O, S}表示子任务,n为Se的长度,J为标签的类别,![]() 和
和![]() 为预测标签和ground truth标签。
为预测标签和ground truth标签。
RACL的最终损失L是子任务损失和正则化损失的组合,即下图,其中λ是一个系数。然后我们用反向传播训练所有参数。
4 实验
4.1数据集和设置
数据集 我们在SemEval 2014 (Pontiki et al, 2014)和2015 (Pontiki et al, 2015)的三个真实ABSA数据集上评估RACL,其中包括来自两个领域的评论:餐厅和笔记本电脑。原始数据集只有方面术语和相应的情感极性的ground truth标签,而观点术语的标签由之前的两个作品注释(Wang et al, 2016,2017)。所有数据集都有固定的训练/测试分割。我们进一步随机抽取20%的训练数据作为开发集来调优超参数,只使用剩下的80%进行训练。表2总结了数据集的统计数据。

设置 我们用两种类型的词向量来检查RACL:预训练的词嵌入和预训练的语言编码器。在词嵌入实现方面,我们遵循了之前的研究(Xu et al, 2018;He et al, 2019;Luo等人,2019),并使用两种类型的嵌入,即通用和特定领域的嵌入。前者来自具有840B令牌的GloVe向量(Pennington et al, 2014),后者使用fastText在大型领域特定语料库上训练,并由Xu等人发布(2018)。两种类型的嵌入连接为词向量。在语言编码器实现中,我们跟随Hu等人(2019)使用BERTLarge (Devlin等人,2019)作为骨干,并在训练过程中对其进行微调。我们将这两个实现分别表示为RACLGloVe和RACL-BERT。
对于RACL-GloVe,我们设置维数dw=400, dh=400, dc=256,系数λ=1e-5。其他超参数在开发集中进行调优。对于三个数据集,CNN的内核大小K和层数L分别设置为{3,3,5}和{4,3,4}。我们使用Adam优化器(Kingma and Ba, 2015)训练固定时间的模型,学习率为1e-4,批处理大小为8。对于RACLBERT,我们将dw设置为1024,将学习率设置为1e-5用于微调BERT,其他超参数直接继承自RACL-GloVe。
我们使用四个指标进行评估,即AE-F1, OE-F1, SC-F1和ABSA-F1。前三个表示每个子任务的f1得分,而最后一个衡量完成ABSA的整体表现。在计算ABSA-F1时,只有AE和SC结果都正确时,才会认为方面项的结果是正确的。在开发集上实现最小损失的模型用于测试集上的评估。
基线 为了演示RACL对完整ABSA任务的有效性,我们将其与以下流水线和统一基线进行比较。基线超参数设置为他们论文中报道的最优值。
→{CMLA, DECNN}+ {TNet, TCap}: CMLA (Wang et al, 2017)和DECNN (Xu et al, 2018)是最先进的AE方法,而TNet (Li et al, 2018a)和T(rans)Cap (Chen and Qian, 2019)是性能最好的SC方法。然后我们通过组合构建四个pipeline基线。
→MNN (Wang et al, 2018a):是对AE和SC使用折叠标记方案的统一方法。
→E2E-ABSA (Li et al, 2019):是对AE和SC使用折叠标记方案的统一方法,在没有显式交互的情况下引入辅助OE任务。
→DOER (Luo et al, 2019):是一种联合训练AE和SC的多任务统一方法,明确地对关系R4进行建模。
→IMN-D(He et al, 2019):是一种针对AE和SC进行单独标签联合训练的统一方法。OE任务被融合到AE中,构建5类标签。它显式地模拟关系R3和R4。
→SPAN-BERT (Hu et al, 2019):是一种使用BERTLarge作为主干的pipeline方法。AE采用多目标提取器,SC采用极性分类器。
→IMN-BERT:是带BERTLarge的最佳统一基线IMN-D的扩展。通过这样做,我们希望对bert风格的方法进行令人信服的比较。IMN-BERT的输入维数和学习率与我们的RACL-BERT相同,其他超参数继承自IMN-D。
4.2 对比结果
各种方法的比较结果如表3所示。这些方法分为三组:M1 ~ M4是基于glove的流水线方法,M5 ~ M9是基于glove的统一方法,M10 ~ M12是基于bert的方法。
首先,在所有基于glove的方法中(M1 ~ M9),我们可以观察到RACL-GloVe在总体指标ABSA-F1方面始终优于所有基线,并且在三个数据集上的最强基线上获得了2.12%,2.92%和2.40%的绝对收益。研究结果表明,联合训练各子任务并对交互关系进行综合建模是提高ABSA任务整体性能的关键。此外,RACL-GloVe还在所有子任务上获得最佳或次优结果。这进一步说明了协同学习可以增强每个子任务的学习过程。从M1 ~ M9中还发现,unified方法(M5 ~ M9)比pipeline方法(M1 ~ M4)性能更好。
其次,在基于glove的统一方法中,RACL-GloVe、IMN-D和DOER总体上优于MNN和E2E-TBSA。这可能是由于前三种方法显式地模拟子任务之间的交互关系,而后两种方法没有。我们注意到DOER的SC-F1分数很低。原因可能是它利用了一个辅助的情感词汇来增强具有“积极”和“消极”情感的词汇。实干者很难处理“中性”情绪的词语,这导致SC-F1得分较低。
第三,基于bert的方法(M10 ~ M12)利用预先训练的BERTLarge主干中编码的大规模外部知识,获得了比基于glove的方法更好的性能。具体来说,SPAN-BERT通过多目标提取器减少搜索空间,是子任务AE的强大基线。然而,由于没有子任务之间的相互作用,它无法捕获AE中提取的方面项与SC中意见项之间的依赖关系,因此在SC上的性能下降了很多。IMN-BERT在OE和SC上得分较高,但在没有R1和R2关系的指导下,在AE上的表现是三者中最差的。相比之下,在所有三个数据集上,RACL-BERT的总体得分明显高于SPAN-BERT和IMN-BERT。这再次显示了我们的RACL框架通过使用所有交互关系来完成ABSA任务的优越性。

5 分析
5.1 Ablation Study
为了研究不同关系对RACL-GloVe/-BERT的影响,我们进行了以下消融研究。我们依次去除每个交互关系,得到四个简化的变量。
正如预期的那样,表4中的所有简化变体都有ABSA-F1的性能下降。结果清楚地证明了所提出的关系的有效性。此外,我们发现这些关系在小型数据集上比在大型数据集上发挥更重要的作用。原因可能是在小数据集上训练复杂的模型很难,关系可以吸收来自其他子任务的外部知识。

5.2 超参数的影响
在我们的模型中有两个关键的超参数:CNN编码器的内核大小K和层数L。为了研究它们的影响,我们首先在[1,9]步进2的范围内改变K,同时将L固定为4.1节中的值,然后在[1,7]步进1的范围内改变L,同时固定K。
我们只在图3中展示了RACLGloVe的ABSA-F1结果,因为RACL-BERT的超参数是继承自RACL-GloVe的。

在图3(a)中,K=1产生的性能非常差,因为原始特征仅由当前单词生成。将K增加到3或5可以扩大接受野,并显著提高性能。然而,当K进一步增加到7或9时,许多不相关的单词被添加为噪声,从而降低了性能。在图3(b)中,增加L可以在一定程度上扩展学习能力,实现高性能。然而,过多的层次引入过多的参数,使学习过程过于复杂。
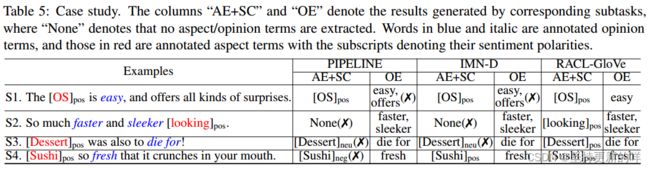
5.3 案例研究
本节以案例研究为例,详细分析了几个例子的结果,采用不同的方法。我们选择CMLA+TCap(记为PIPELINE)、IMN-D和RACL-GloVe作为三个竞争对手。我们没有包括基于bert的方法,因为我们希望在没有外部资源的情况下研究模型的功能。
S1和S2验证关系R1的有效性。在S1中,由于连词“and”的存在,两条基线错误地将“offers”作为意见术语提取为“easy”。相比之下,RACLGloVe可以通过使用R1成功过滤掉OE中的“offers”。原因是在训练集中“offers”从未作为意见项与方面项“OS”共同出现,连接AE子任务和OE子任务的R1会将它们视为不相关的术语。该信息将在测试阶段传递给OE子任务。类似地,在S2中,两个基线都不能将“looking”识别为方面术语,因为它可能是“look”的现在分词,没有意见信息。相反,RACL-GloVe正确地将其标记为R1,从意见术语“faster”和“sleeker”中提供了有用的线索。
S3显示了R2关系的优越性,R2关系是连接三个子任务的关键,但在以往的研究中从未使用过。这两个基线都成功地提取了AE和OE的“甜点”和“为之而死”,但即使IMN-D强调了意见术语,也分配了不正确的“中性”情绪极性。原因是这两个项在训练样本中并没有同时出现,SC很难识别它们的依赖关系。相反,由于“Dessert”和“die for”是AE和OE中的典型单词,因此RACL-GloVe能够在R1中编码它们的依赖关系。通过使用R2将R1传播到SC, RACL-GloVe可以为“甜点”分配正确的极性。为了仔细观察,我们将图4中所有层的平均预测结果(左)和注意力权重(右)可视化。显然,“Dessert”最初的关注点![]() 并不是“die for”。经
并不是“die for”。经![]() 和OE增强后,
和OE增强后,![]() 成功高亮意见词,SC做出正确预测。
成功高亮意见词,SC做出正确预测。

S4显示了关系R3的好处。IMN-D和RACL-GloVe在SC中对“Sushi”给予了正确的极性,因为他们都得到了OE中“fresh”的指导,而PIPELINE在上下文中迷失了方向,在没有意见术语的帮助下做出了错误的预测。请注意,S1 ~ S4同时证明了R4的必要性,因为RACL-GloVe不受背景词的影响,并且可以在所有示例中做出正确的情绪预测。
5.4 计算成本分析
为了证明我们的RACL模型不会产生很高的计算成本,我们将其与两个强基线DOER和IMN-D在参数数量和运行时间方面进行了比较。我们在一个1080Ti GPU中使用相同批处理大小为8的Restaurant 2014数据集运行三个模型,结果如表6所示。显然,我们提出的RACL与IMN-D具有相似的计算复杂度,并且它们都比DOER简单得多。

6 总结
在本文中,我们强调了交互关系在完成ABSA任务中的重要性。为了利用这些关系,我们提出了一个具有多任务学习和关系传播技术的关系感知协作学习(RACL)框架。在三个真实数据集上的实验表明,对于完整的ABSA任务,我们的RACL框架及其两个实现优于最先进的pipeline和unified基线。