Python爬虫入门(二) (xpath解析表情包)
Python爬虫入门(二) (xpath解析表情包)## 标题
在上一节中我们讲了爬虫的基础,以及动手写了一个较为简单的爬虫程序,在本章中我们将学习使用爬虫xpath解析快速的爬取表情包!妈妈终于不用担心我斗图斗不过了!
什么是xpath:XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的
例如如下的html源码:
DOCTYPE html>
<html>
<head>
<title>title>
head>
<body>
<div class="aa">
<span>my name is kikispan>
<img src="http://xxx1.html">
div>
<div class="aa">
<span>my name is gigispan>
<img src="http://xxx2.html">
div>
<div class="aa">
<span>my name is cocospan>
<img src="http://xxx3.html">
div>
body>
html>
如果想要拿出所有span中的文字内容则可以这样写xpath:
"//div[@class='aa']/span/text()"
如果想要拿出所有img中的图片地址则可以这样写xpath:
"//div[@class='aa']/img/@src"
加下来我们就通过实战来了解:
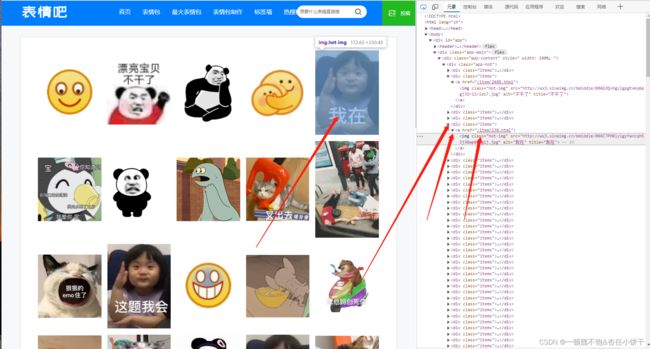
通过开发者工具可以得出每一种图片都在一个class为items下的a标签中的img标签中,想要爬取到图片,则需要爬取到每一张图片所对应的url。

1、下载lxml包,和下载requests一样,在命令行输入以下内容:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lxml
2、导入需要的包
import requests
from lxml import etree #etree模块用于xpath解析
import os
3、准备工作
if __name__ == '__main__':
if not os.path.exists('img'): #如果在.py的同一级目录下如果不存在img这个文件夹,则创建一个文件夹
os.mkdir('img')
url = 'https://www.biaoqingba.net/hot/page/{}.html' #爬取的网址,page/{}表示第几页
headers = { #进行UA伪装
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56'
}
page = 20 #指定爬取前20页的图片
4、写爬虫函数

通过观察网页源码的img标签,可以得到图片的url地址可以通过src拿到,图片的标题可以通过title拿到。且所有放有图片的img标签都有一个相同的class等于hot-img。
def spider(url,headers):
response = requests.get(url=url,headers=headers).text #因为返回对象是网页源码,所以这里的格式为text
tree = etree.HTML(response) #实例化一个etree.HTML对象,使其能够进行xpath解析
img_url = tree.xpath('//img[@class="hot-img"]/@src') #所有图片的url,返回的是一个列表
title_list = tree.xpath('//img[@class="hot-img"]/@title') #所有图片的标题,返回的是一个列表
try:
for index,ele in enumerate(img_url): #遍历图片地址列表,爬取得到图片
img = requests.get(url=ele,headers=headers).content #因为图片为二进制保存形式,所以用content
img_type = ele[-4:] #得到图片的格式,.jpg或.gif
img_path = './img/' + title_list[index]+img_type #图片的保存地址
with open(img_path,'wb') as fp: #'wb'二进制形式打开,这里必须为wb,且这里不能指定encoding = utf-8
fp.write(img)
print(title_list[index],"爬取成功")
except Exception:
pass
5、完善全部代码,并进行爬取
import requests
from lxml import etree #etree模块用于xpath解析
import os
def spider(url,headers):
response = requests.get(url=url,headers=headers).text #因为返回对象是网页源码,所以这里的格式为text
tree = etree.HTML(response) #实例化一个etree.HTML对象,使其能够进行xpath解析
img_url = tree.xpath('//img[@class="hot-img"]/@src') #所有图片的url,返回的是一个列表
title_list = tree.xpath('//img[@class="hot-img"]/@title') #所有图片的标题,返回的是一个列表
try:
for index,ele in enumerate(img_url): #遍历图片地址列表,爬取得到图片
img = requests.get(url=ele,headers=headers).content #因为图片为二进制保存形式,所以用content
img_type = ele[-4:] #得到图片的格式,.jpg或.gif
img_path = './img/' + title_list[index]+img_type #图片的保存地址
with open(img_path,'wb') as fp: #'wb'二进制形式打开,这里必须为wb,且这里不能指定encoding = utf-8
fp.write(img)
print(title_list[index],"爬取成功")
except Exception:
pass
if __name__ == '__main__':
if not os.path.exists('img'): #如果在.py的同一级目录下如果不存在img这个文件夹,则创建一个文件夹
os.mkdir('img')
url = 'https://www.biaoqingba.net/hot/page/{}.html' #爬取的网址,page/{}表示第几页
headers = { #进行UA伪装
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56'
}
page = 20 #指定爬取前20页的图片
for page_index in range(page):
spider(url.format(page_index),headers) #调用自定义函数

