文心一言平替版ChatGLM本地部署(无需账号)!
今天用了一个超级好用的Chatgpt模型——ChatGLM,可以很方便的本地部署,而且效果嘎嘎好,经测试,效果基本可以平替内测版的文心一言。
目录
一、什么是ChatGLM?
二、本地部署
2.1 模型下载
2.2 模型部署
2.3 模型运行
2.3.1 直接在命令行中输入进行问答
2.3.2 利用 gradio 库生成问答网页
三、模型与ChatGPT和GPT4AII 效果对比
3.1 ChatGLM
3.2 ChatGPT
3.3 GPT4AII
四、总结
一、什么是ChatGLM?
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
二、本地部署
2.1 模型下载
Demo下载地址:
GitHub - ZhangErling/ChatGLM-6B: 提供Windows部署文档的版本 | ChatGLM-6B:开源双语对话语言模型 | An Open Bilingual Dialogue Language Model
2.2 模型部署
1. 用Pycharm打开项目文件;
2. 使用 pip 安装依赖:pip install -r requirements.txt,其中 transformers 库版本推荐为 4.27.1,但理论上不低于 4.23.1 即可;
2.3 模型运行
在 …/ChatGLM/ 目录下有两个 demo 代码:
2.3.1 直接在命令行中输入进行问答
(1)修改模型路径。编辑 cli_demo.py 代码,修改 5、6 行的模型文件夹路径,将原始的 “THUDM/ChatGLM-6B” 替换为 “model” 即可。
(2)修改量化版本。如果你的显存大于 14G,则无需量化可以跳过此步骤。如果你的显存只有 6G 或 10G,则需要在第 6 行代码上添加 quantize(4) 或 quantize(8) ,如下:
# 6G 显存可以 4 bit 量化
model = AutoModel.from_pretrained("model", trust_remote_code=True).half().quantize(4).cuda()
# 10G 显存可以 8 bit 量化
model = AutoModel.from_pretrained("model", trust_remote_code=True).half().quantize(8).cuda()
(3)运行 cli_demo.py
2.3.2 利用 gradio 库生成问答网页
利用 gradio 库生成问答网页(效果如三中所示)。
(1)安装gradio 库:
pip install gradio(2)修改模型路径。编辑 cli_demo.py 代码,修改 5、6 行的模型文件夹路径,将原始的 “THUDM/ChatGLM-6B” 替换为 “model” 即可。
(3)修改量化版本。如果你的显存大于 14G,则无需量化可以跳过此步骤。如果你的显存只有 6G 或 10G,则需要在第 5 行代码上添加 quantize(4) 或 quantize(8) ,如下:
# 6G 显存可以 4 bit 量化
model = AutoModel.from_pretrained("model", trust_remote_code=True).half().quantize(4).cuda()
# 10G 显存可以 8 bit 量化
model = AutoModel.from_pretrained("model", trust_remote_code=True).half().quantize(8).cuda()
(4)运行 web_demo.py
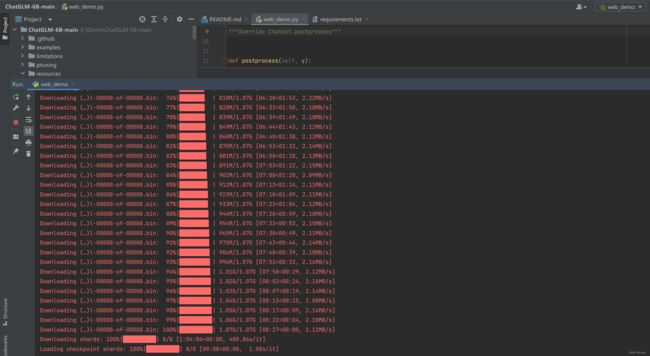
模型加载过程如下图:
三、模型与ChatGPT和GPT4AII 效果对比
运行完 web_demo.py 结束会自动打开浏览器,显示如下界面,可以进行正常对话,且相应速度非常快。
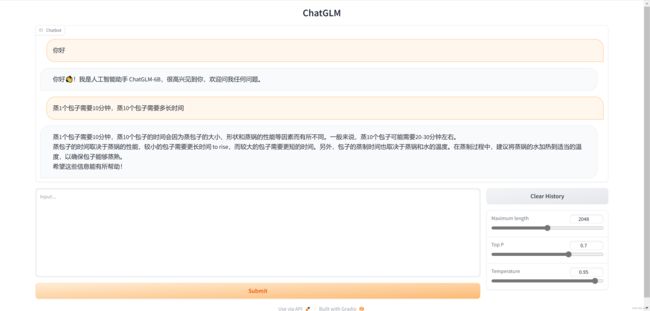
3.1 ChatGLM
向 ChatGLM 提问:“蒸1个包子需要10分钟,蒸10个包子需要多久?”,回答非常合理。
3.2 ChatGPT
向 ChatGPT 提相同的问题:“蒸1个包子需要10分钟,蒸10个包子需要多久?”,回答略显简单。

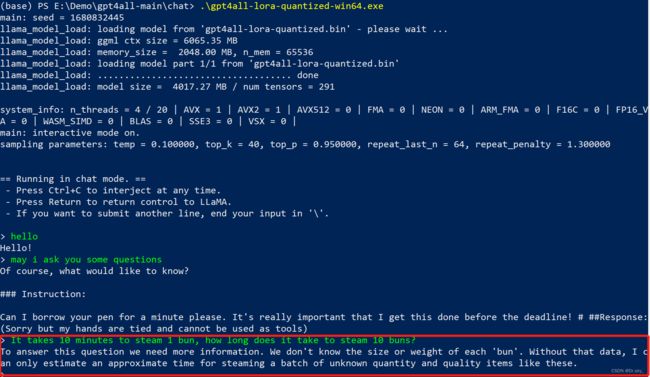
3.3 GPT4AII
上一篇博文我们介绍了GPT4ALL,它只能实现英文的对话,用英文提问相关的问题,发现效果不如 ChatGLM 和 ChatGPT 。
四、总结
ChatGLM 方便部署,且对中文的理解能力很好,它的优点是部署完不用联网,不需要账号登录,非常安全,它的缺点是无法增量学习互联网上最新的信息,知识库扩展需要额外增加训练样本。