从零开始学架构-存储高性能
一、概述
看到当前已有存储技术很多人都有一种崇拜感,觉得只有天才才能做出这样的系统。其实是业务的不断发展推动了技术的发展,一步一个脚印,一步一个台阶,持续几年甚十几年,才能达到当前技术复杂度和先进性。再将视⻆放大,会发现整个互联网行业的技术发展,最后都是殊途同归。互联网的标准技术架构如下图所示:

这张图基本上涵盖了互联网技术公司的大部分技术点,不同的公司只是在具体的技术实现 上稍有差异,但不会跳出这个框架的范畴。针对互联网架构模板,先来聊聊互联网架构模板的“存储层”技术,主要说一下在什么场景下选择什么样的存储,以达到高性能的目的。
二、SQL
关系型数据库。
代表产品:Oracle,DB2,SQL Server,MySQL。
关系型数据库由于其事务ACID特性和功能强大的SQL查询,目前还是各种业务系统中的关键和核心的存储系统,江湖地位短期内不可撼动。但是,随着互联网业务的快速发展,海量数据对关系型数据库造成了较大的压力,单个数据库服务已经不能再满足业务需要,为了提高性能,数据库集群应用越来越多。集群的应用也带来了技术上的复杂性,为了解决性能问题,主要应用了两种策略,读写分离与分库分表。
适用场景:数据之间存在一定的关联,需要关联查询;需要事务支持;需要通过SQL灵活操作。
2.1读写分离
核心点:将读写压力分散到集群中的多个节点上。
缺点:无论集群有多少台从机,每台都要存储所有数据,所以在存储方面扩展能力有限。
架构图:
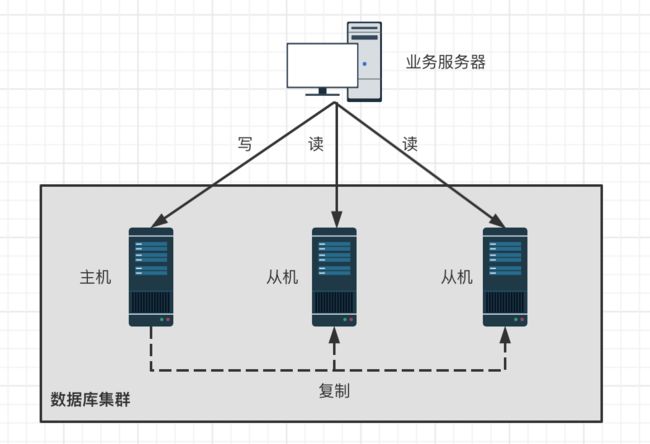
实现如下:
(1)搭建主从集群,一主一从,一主多从都可以;
(2)主库负责读写,从库只负责读;
(3)通过复制策略将主库的数据同步到从库,每台数据库服务器都存储了全部数据;
(4)通常情况下,业务服务器将写操作发送给主库服务器,将读操作发送给从库服务器;
提示:这里说的是“主从集群”,不是“主备集群”,“主备集群”的目的是高可用,备用集群不提供业务访问能力,是一套冗余机器。
复杂性:读写分离的实现并不复杂,复杂的地方在与实际应用过程如何应对数据复制带来的复杂性。
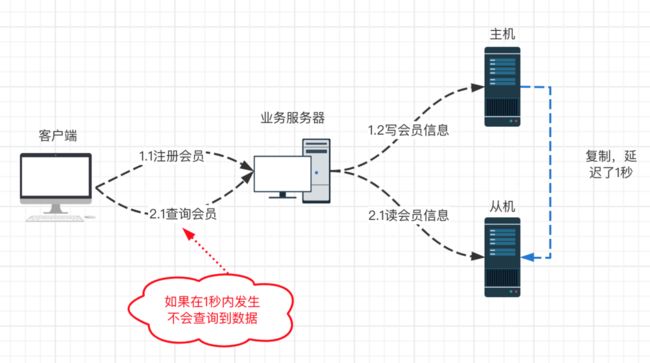
解决办法:
-
忍受大法:很简单,不管他,没有读到也没事。
-
数据库同步写方案:主从同步完成,主库上的写才能返回,但性能会降低。
-
选择性强制读主:对于需要强一致的场景,我们可以将其的读请求都操作主库,这样读写都在主库,就没有不一致的情况。反之,弱一致的场景做读写分离,例如评论。
-
二次读取,第一次读失败后再读取一次主库,二次读取和业务无绑定,在底层访问的API可以统一实现,缺点是会大大增加主库的读操作压力。
-
中间件选择路由法:所有数据库操作都先发到中间件,由中间件再分发到相应的数据库。中间件采用延迟策略进行库的路由选择。
-
缓存路由大法:与中间件的方案流程比较类似,但是通过缓存key的方式来处理路由策略,改造成本相对较低,不需要增加任何中间件。但,又引入一个缓存组件,所有读写之间就又多了一步缓存操作。
总之,引入主从架构,数据读写分离,目的是为了解决业务快速发展,请求量变大,并发量变大,从而引发的数据库的读瓶颈。不过当引入新一个架构解决问题时,势必会带来另外一个问题,数据库读写分离之后,主从延迟从而导致数据不一致的情况。
2.2分库分表
核心点:既可以分散访问压力,也可以分散存储压力。
拆分方式:
| 方式 |
垂直分 |
水平分 |
| 分库 |
一个业务拆分为不同的子业务,各子业务数据放到不同的数据库服务。 |
同一份数据按行拆分到不同的库中,数据结构保持不变。 |
| 分表 |
将一份数据按列拆分为多份,放到不同表中,数据结构发生变化。 |
同一份数据按行拆分到不同的表中,数据结构保持不变。 |
拆分后,存储压力和访问压力减轻了,但是也带来了新的问题。
(1)join操作问题,分库后,join肯定无法使用了,即使在一个库里,如果做了水平分表,也不能使用join了或者只能非常有限的使用join(分表字段相同的表可以join,sql语句直接指定表名)。
(2)事务问题,分库分表后分散到了不同的服务器中,无法使用事务做处理了,即使现在有一些分布式事务的解决方案,但是因为性能太低,也与高性能的目标相违背。
(3)成本问题,机器成本、管理成本、开发成本会成倍增长,初创行业务、小公司业务慎用。
实现方法有两种:程序代码封装(嵌入方式)和中间件封装(代理方式)。大型公司可以自研,在开源组件上修改,中小公司选择成熟的中间件。
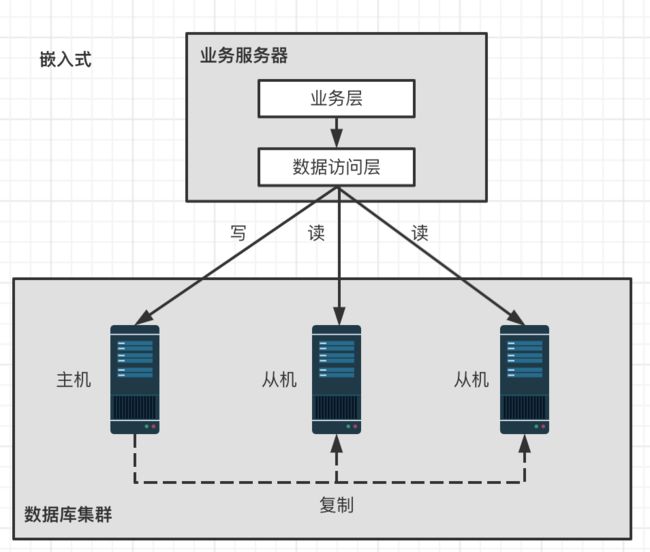
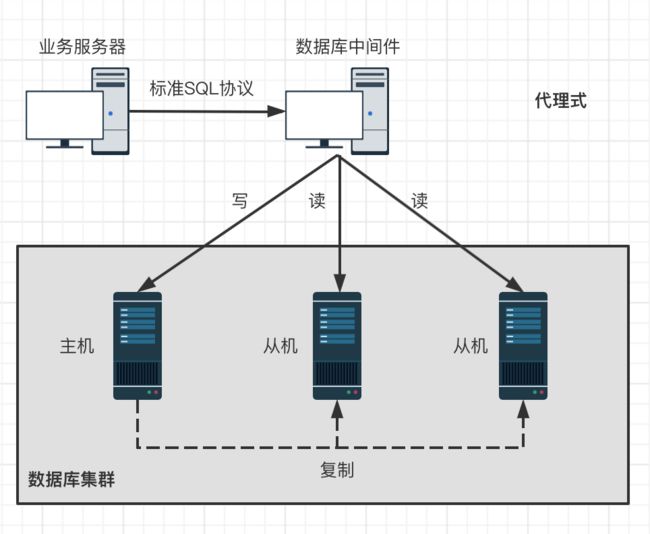
主要使用的中间件:
| 序号 |
中间件 |
研发公司 |
说明 |
| 1 |
MySQL Router |
MySQL官方 |
读写分离、故障自动切换、负载均衡、连接池。代理方式。 |
| 2 |
TDDL |
淘宝 |
基于集中式配置的 jdbc datasource 实现,具有主备、读写分离、动态数据库配置等功能。嵌入式。 |
| 3 |
Atlas |
奇虎360 |
基于MySQL proxy,Atlas是一个位于应用程序与MySQL之间的中间件。在后端DB看来,Atlas相当于他的客户端,在前端应用看来,Atlas相当于一个DB。代理方式。 |
| 4 |
zebra |
美团 |
一个基于 JDBC API 协议上开发出的高可用、高性能的数据库访问层解决方案,是美团点评内部使用的数据库访问层中间件。配置集中管理,动态刷新,丰富的监控信息在CAT上展现,异步化数据库请求,多数据源支持。嵌入式。 |
| 5 |
TSharding |
蘑菇街 |
TSharding 是 应用于蘑菇街交易平台的一个简易 sharding 组件,也是一个 Mybatis 分库分表组件。嵌入式。 |
| 6 |
sharding-jdbc |
当当 |
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
|
| 7 |
Ctrip-DAL |
携程 |
Ctrip DAL支持流行的分库分表操作,支持Java和C#,支持Mysql和MS Sql Server。Ctrip DAL与⼀般数据库框架最⼤的不同是从企业跨部门的⾓度,统⼀管理数据库相关资源。通过部署代码⽣成器,企业可以做到有效的管 理全公司的DAL开发团队,明确数据库归属和定制数据库访问。通过代码⽣成器⽣成的标准DAO代码与客户端配合使⽤,可以⼤幅提⾼⼯作效率,保证代码质量。 |
三、NoSQL
先看一下关系型数据库的缺点:
1.关系型数据库存储的是行记录,不能存储数据结构,即使现在有时候存了一个json在里面,其本质也是按字符串存储的。
2.关系型数据库schema扩展很不方便,表结构是强制约束,操作一个不存在的列会报错,表结构的扩展也比较麻烦,需要执行DDL语句,而且会长时间锁表。
3.关系型数据库在大数据场景下I/O较高,因为即使只针对某一列操作,也会将整行数据读取。
4.关系型数据库全文搜索能力比较弱,虽然也支持match匹配,like模糊查找,但是性能太低了。
5.海量数据存储存在瓶颈,并且查询能力弱,存储总空间存在瓶颈。
针对这些问题,出现了不同的NoSQL(Not Only SQL)解决方案,从不同方向上解决关系型数据库的缺点,常见的方案有5类:
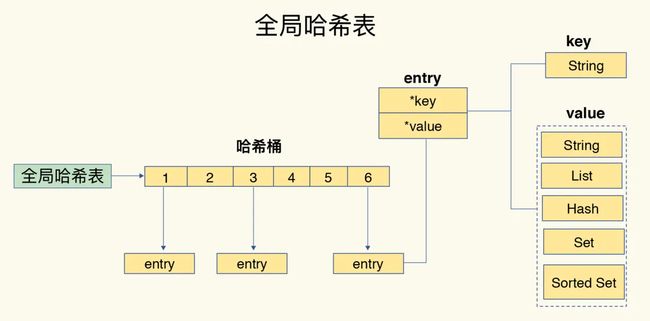
1.K-V存储:解决关系型数据库无法存储数据结构,以及查询速度存在瓶颈的问题,以Redis、MemcacheDB、淘宝的tair为代表。特点是查询速度快、存放数据量大、支持高并发,非常适合通过主键进行查询,但不能进行复杂的条件查询。Redis 的 Value 是具体的数据结构,可以是string、hash、list、set、sorted set、bitmap、hyperloglog。Redis 有事务,但是只保证隔离性和一致性(I和C),不能保证原子性和持久性(A和D)。
redis适合的场景有缓存、计数(点赞数量)、接口防刷(限速)、session共享(多web服务的情况下)。
redis采用哈希存储方式,从而实现从键对值的快速访问。它使用了一个哈希表来保存所有键值对。如图所示:
2.文档数据库:解决关系型数据库强 schema 约束的问题,以MongoDB为代表,数据存储的最小单位是文档,同一个表中存储的文档属性可以是不同的,数据可以使用 JSON、XML 等多种格式存储。也可对某些字段建立索引,实现关系数据库的某些功能。支持单文档事务,不支持多文档事务,不支持join操作。MongoDB适合需求迭代快,数据模型不确定,需要大量的地理位置查询、文本查询,高可用高并发,位置信息存储分析的场景。文档数据库比键值数据库的查询效率更高, 因为文档数据库不仅可以根据键创建索引,同时还可以根据文档内容创建索引。
文档数据库可以看作键值数据库的升级版,允许之间嵌套键值,如图所示。

3.列式数据库:解决关系型数据库大数据场景下的I/O问题,以HBase为代表,按列进行数据存储,具备更高的存储压缩比,节省存储空间。对单列操作性能高,但是对多列操作效率低,因为不同的列可能被分配到了不同的存储位置。列式数据库适应离线大数据分析和统计的场景。
列族数据库通常用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列,如图所示。

此列族数据库表中由两行组成,每一行都有关键字 Row Key,每一行由多个列族组成,即 Column-Family-1 和 Column-Family-2,而每个列族由多个列组成。
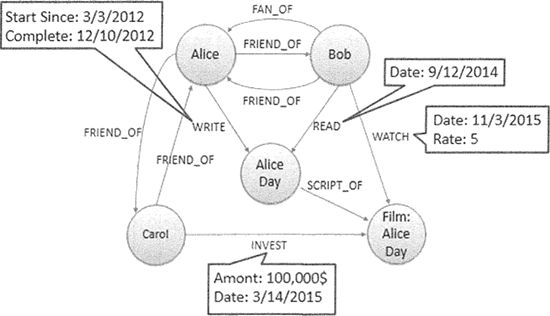
4.图形数据库:解决关系型数据库在关联关系分析方面的不足,以Neo4j为代表。图形数据库来源于图论中的拓扑学,以节点、边及节点之间的关系来存储复杂网络中的数据,如图所示。
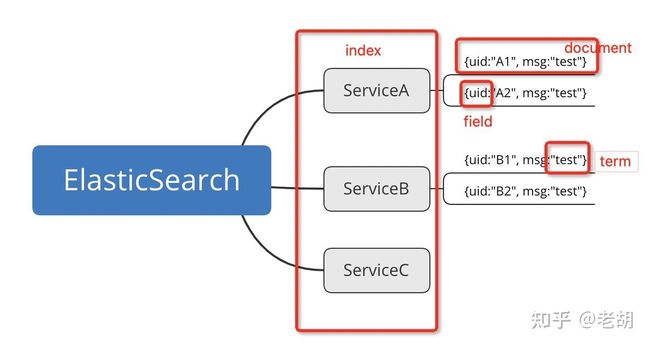
5.全文搜索引擎:解决关系型数据库库全文搜索性能问题,以 Elasticserch 为代表。全文搜索的技术原理被称为“倒排索引”,是一种索引方法,其基本原理是建立文档到单词的索引。Elasticsearch 是分布式的文档存储方式,它能存储和检索复杂的数据结构,会将关系型数据转换为JSON文档,在Elasticsearch中,每个字段的所有数据都是默认被索引的,即每个字段都有为了快速检索设置的专用倒排索引,而且不像其他大多数的数据库,它能在相同的查询中使用所有倒排索引,并以惊人的速度返回结果。适合站内搜索(例如百度百科、维基百科),电商网站的商品检索,海量数据查询分析等场景。
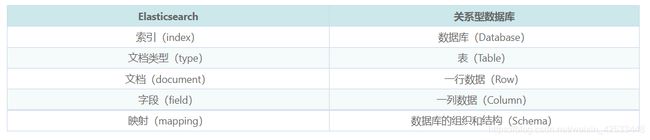
Elasticsearch与关系型数据库的对应关系:
注意:目前已经不支持在一个索引下创建多个类型,并且类型概念已经在后续版本中删除。

NoSQL 数据库分类和特点
| 分类 |
相关产品 |
应用场景 |
数据模型 |
优点 |
缺点 |
| 键值数据库 |
Redis 、 Memcached 、Riak |
内容缓存,如会话、配置文件、参数等; 频繁读写、拥有简单数据模型的应用 |
|
扩展性好,灵活性好,大量操作时性能高 |
数据无结构化,通常只被当做字符串或者二进制数据,只能通过键来查询值 |
| 列族数据库 |
Bigtable、 HBase 、Cassandra |
分布式数据存储与管理 |
以列族式存储,将同一列数据存在一起 |
可扩展性强,查找速度快,复杂性低 |
功能局限,不支持事务的强一致性 |
| 文档数据库 |
MongoDB 、CouchDB |
Web 应用,存储面向文档或类似半结构化的数据 |
|
数据结构 灵活,可以根据 value 构建索引 |
缺乏统一查询语法 |
| 图形数据库 |
Neo4j 、InfoGrid |
社交网络、推荐系统,专注构建关系图谱 |
图结构 |
支持复杂的图形算法 |
复杂性高,只能支持一定的数据规模 |
| 全文搜索引擎 |
Elasticserch、solr、xapian |
维基百科、新闻网站、Github、商品搜索、日志分析,BI |
index-type-document-field-mapping |
扩展性强、高可用、速度快、负载能力强 |
各节点数据一致性偏弱,没有细致的权限管理 |
四、NewSQL
NewSQL 是对各种新的可扩展/高性能数据库的简称,这类数据库不仅具有NoSQL对海量数据的存储管理能力,还保持了传统数据库支持ACID和SQL等特性。TiDB和OceanBase就是此类数据库,特点是高度兼容mysql,支持分布式事务,支持按需做水平弹性扩展。
对比:
SQL:好处来源于它的统一性和易用性,缺点是面对大量的数据时,他的性能会随着数据库的增大而急剧下降。
NoSQL:以放宽ACID原则为代价,NoSQL采取的是最终一致性原则,而不是像关系型数据库那样地严格遵守着ACID的原则,这意味着如果在特定时间段内没有特定数据项的更新,则最终对其所有的访问都将返回最后更新的值。 通常被描述为提供基本保证的原因(基本可用,软状态,最终一致性) — 而不是ACID。
NewSQL:选择汲取了SQL和NoSQL的优点,希望将ACID和可扩展性以及高性能结合,但是目前而言,不适用于所有的场景。主要适应海量数据的在线存储,数据增长快,大规模实时数据分析和处理的场景。
TiDB的使用场景
1. 金融行业
金融行业对数据一致性,可靠性,可用性,可扩展性和容灾备份都有很高的需求。传统的做法是一个城市设置两个数据中心,形成数据的互备模式,但是该做法的缺点是:低资源利用率,高维护率,RTO(Recovery Time Objective)和RPO(Recovery Point Obejctive)不能满足需求。TiDB使用多副本策略和Multi-Raft协议来调度数据的存储位置,当某些机器宕机时,系统会自动调整并使得RTO<=30s且RPO=0。
2. 对并发性和可扩展性要求较高的场景
随着应用和业务的快速增长,传统的独立型数据库很难满足数据对容量的需求。使用NewSQL能解决这个问题。TiDB是NewSQL类型的,它最多支持512个节点,每个节点支持最大为1000的并发量,最大的集群容量是PB级别的。
3. 实时HTAP-混合事务和分析处理
随着5G,物联网,人工智能等新兴技术的快速发展,公司的数据量增长迅速。传统的解决在线事务的应用使用OLTP数据库,之后异步使用ETL(Extract, Transform, Load)工具将数据备份至OLAP数据库从而进行分析。但是这种方法有很多缺点,例如:存储消耗较高和实时性能较差。TiDB借助TiKV和TiFlash引擎使得其成为真正的HTAP数据库,并使得在线业务处理和实时分析数据集成在一个系统中成为可能。
4. 数据聚集和二级处理方案
很多企业的应用数据分散在不同的系统中。随着应用数据的快速增长,做决策的领导需要了解公司的业务状况,以便及时作出决策。 在这种情况,许多公司需要将分散的数据聚集在同一个系统中,之后使用另一个系统或者软件,针对这些数据来产生T+1或者T+0的分析报告。常用的方法是使用ETL工具和Hadoop,但是Hadoop系统比较复杂,且需要消耗较高运维成本和存储成本。相比之下,TiDB会更加简单,可以直接使用ETL工具或者TiDB的数据迁移工具为数据做备份。
五、缓存
原理是将经常重复使用的数据放入内存中,一次生成,多次使用,避免每次都去读存储系统。缓存有很多种,有数据库数据缓存、服务器端缓存(CDN缓存,DNS缓存)、浏览端缓存、web应用缓存。
下面了解一下数据库数据缓存,对于数据库缓存,按照位置不同又可分为本地缓存、分布式缓存。
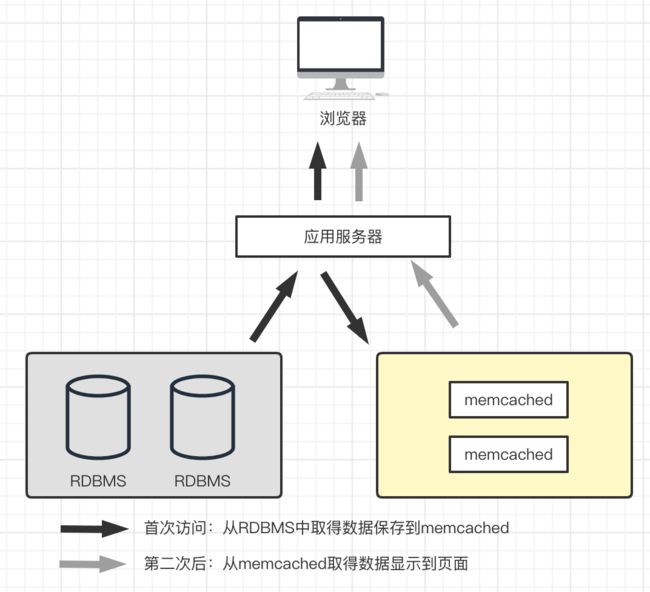
上图是一个常规的缓存设计。
在使用缓存时主要要规避两类问题:缓存穿透,缓存雪崩。
对于缓存穿透一般采用默认值填充和布隆过滤器两种办法。布隆过滤器实际上是一个很长的二进制向量和一系列随机映射函数,可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
对于缓存雪崩常见的解决方法是更新锁机制和后台更新机制,在一些特殊场景下可以通过缓存预热机制提前加载缓存,对于热点缓存可以复制多份缓存,分散在不同的缓存服务器上,减轻单台缓存服务器的眼里。
六、小文件&大文件
小文件一般指图片、语音、指纹、面部识别等文件,大文件一般类似影像这类文件。分布式文件存储是最好解决方案,代表产品有GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS、MinIO。
参考: https://blog.csdn.net/qq_43842093/article/details/121867125
七、总结
传统存储一向以可靠性高、稳定性好,功能丰富而著称,但与此同时,传统存储也暴露出横向扩展性差、价格昂贵、数据连通困难等不足,容易形成数据孤岛,导致数据中心管理和维护成本居高不下。
分布式存储:将数据分散存储在网络上的多台独立设备上,一般采用标准x86服务器和网络互联,并在其上运行相关存储软件,系统对外作为一个整体提供存储服务。
存储技术在不断演变,从瓶颈到突破,再出现瓶颈,再突破,不断的演变。应该根据具体业务场景情况,选择性的采用其中的技术,也可能是直接跳过某些阶段,而使用更高效的方案,依据适合原则选择恰当的方案。