LeCun力荐!哈佛博士分享用GPT-4搞科研,细到每个工作流程

来源:新智元 机器学习算法与自然语言处理
本文约2700字,建议阅读5分钟
本文分享了高效率用LLM工具的经验,还获得了LeCun的推荐。[ 导读 ] 用GPT-4搞科研未来或许成为每个人的标配,但是究竟如何高效利用LLM工具,还得需要技巧。近日,一位哈佛博士分享了自己的经验,还获得了LeCun的推荐。
GPT-4的横空出世,让许多人对自己的科研担忧重重,甚至调侃称NLP不存在了。
与其担忧,不如将它用到科研中,简直「换个卷法」。
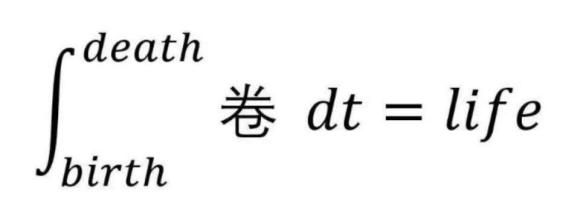
来自哈佛大学的生物统计学博士Kareem Carr称,自己已经用GPT-4等大型语言模型工具进行学术研究了。
他表示,这些工具非常强大,但是同样存在一些非常令人痛苦的陷阱。
他的关于LLM使用建议的推文甚至获得了LeCun的推荐。
一起来看看Kareem Carr如何利用AI利器搞科研。
第一原则:自己无法验证的内容,不要找LLM
一开始,Carr给出了第一条最重要的原则:
永远不要向大型语言模型(LLM)询问你无法自行验证的信息,或要求它执行你无法验证已正确完成的任务。
唯一的例外是它不是一项关键的任务,比如,向LLM询问公寓装饰的想法。
「使用文献综述的最佳实践,总结过去10年乳腺癌研究的研究」。这是一个比较差的请求,因为你无法直接验证它是否正确地总结了文献。而应当这么问「给我一份过去10年中关于乳腺癌研究的顶级评论文章的清单」。这样的提示不仅可以验证来源,并且自己也可以验证可靠性。
撰写「提示」小技巧
要求LLM为你编写代码或查找相关信息非常容易,但是输出内容的质量可能会有很大的差异。你可以采取以下措施来提高质量:
设定上下文:
明确告诉LLM应该使用什么信息
使用术语和符号,让LLM倾向正确的上下文信息
如果你对如何处理请求有想法,请告诉LLM使用的具体方法。比如「解这个不等式」应该改成「使用Cauchy-Schwarz定理求解这个不等式,然后应用完成平方」。
要知道,这些语言模型在语言方面上比你想象的要复杂得多,即使是非常模糊的提示也会有所帮助。
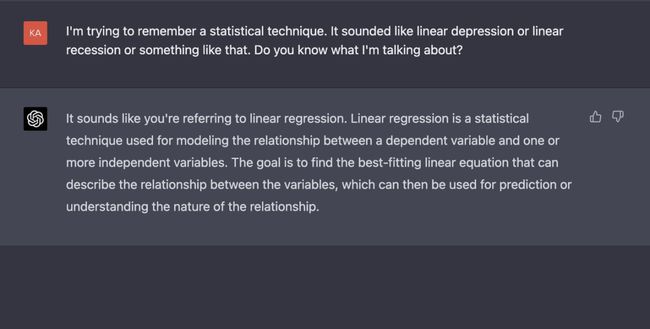
具体再具体:
这不是谷歌搜索,所以也不必担心是否有个网站在讨论你的确切问题。
「二次项的联立方程如何求解?」这个提示就不是明确的,你应该这样问:「求解 x=(1/2)(a+b) 和 y=(1/3)(a^2+ab+b^2) 关于a和b的方程组」。
定义输出格式:
利用LLMs的灵活性,将输出格式化为最适合你的方式,比如:
代码
数学公式
文章
教程
简明指南
你甚至可以要求提供生成以下内容的代码,包括表格、绘图、图表。
尽管你得到了LLM输出的内容,但这仅是一个开始。因为你需要对输出内容进行验证。这包括:
发现不一致之处
通过谷歌检索工具输出内容的术语,获取可支撑的信息源
在可能的情况下,编写代码自行测试
需要自行验证的原因是,LLM经常犯一些与其看似专业水平不一致的奇怪错误。比如,LLM可能会提到一个非常先进的数学概念,但却对简单的代数问题摸不着头脑。
多问一次:
大型语言模型生成的内容是随机的。有时,重新创建一个新窗口,并再次提出你的问题,或许可以为你提供更好的答案。
另外,就是使用多个LLM工具。Kareem Carr目前根据自己的需要在科研中使用了Bing AI,GPT-4,GPT-3.5和Bard AI。然而,它们各有自己的优缺点。
引用+生产力
引用
根据Carr经验,最好向GPT-4和Bard AI同时提出相同的数学问题,以获得不同的观点。必应AI适用于网络搜索。而GPT-4比GPT-3.5要聪明得多,但目前OpenAI限制了3个小时25条消息,比较难访问。
就引用问题,引用参考文献是LLM的一个特别薄弱的点。有时,LLM给你的参考资料存在,有时它们不存在。
此前,有个网友就遇到了同样的问题,他表示自己让ChatGPT提供涉及列表数学性质的参考资料,但ChatGPT生成了跟不不存在的引用,也就是大家所说的「幻觉」问题。

然而,Kareem Carr指出虚假的引用并非完全无用。
根据他的经验,捏造的参考文献中的单词通常与真实术语还有相关领域的研究人员有关。因此,再通过谷歌搜索这些术语,通常让你可以更接近你正在寻找的信息。
此外,必应在搜寻来源时也是一个不错的选择。
生产力
对于LLM提高生产力,有很多不切实际的说法,比如「LLM可以让你的生产力提高10倍,甚至100倍」。
根据Carr的经验,这种加速只有在没有对任何工作进行双重检查的情况下才有意义,这对作为学者的人来说是不负责任的。
然而,LLM对Kareem Carr的学术工作流程有很大改进,具体包括:
- 原型想法设计 - 识别无用的想法 - 加速繁琐的数据重新格式化任务 - 学习新的编程语言、包括概念 - 谷歌搜索.
借助当下的LLM,Carr称自己用在下一步该做什么上的时间更少了。LLM可以帮助他将模糊或不完整的想法推进到完整的解决方案中。
此外,LLM还减少了Carr花在与自己主要目标无关的副业上的时间。

我发现我进入了一种心流状态,我能够继续前进。这意味着我可以工作更长时间,而不会倦怠。
最后一句忠告:小心不要被卷入副业。这些工具突然提高生产力可能会令人陶醉,并可能分散个人的注意力。
关于ChatGPT的体验,Carr曾在领英上发表了一条动态分享了对ChatGPT使用后的感受:
作为一名数据科学家,我已经用OpenAI的ChatGPT做了几周的实验。它并不像人们想象的那样好。
尽管最初令人失望,但我的感觉是,类似ChatGPT的系统可以为标准数据分析工作流程增加巨大的价值。
在这一点上,这个价值在哪里并不明显。ChatGPT很容易在简单的事情上弄错一些细节,而且它根本无法解决需要多个推理步骤的问题。
未来每个新任务的主要问题仍然是评估和改进ChatGPT的解决方案尝试更容易,还是从头更容易开始。
我确实发现,即使是ChatGPT的一个糟糕的解决方案也倾向于激活我大脑的相关部分,而从头开始则不会。
就像他们总是说批评一个计划总是比自己想出一个计划更容易。

网友对于AI输出的内容需要进行验证,并称在大多数情况下,人工智能的正确率约为90%。但剩下10%的错误可能是致命的。
Carr调侃道,如果是100%,那我就没有工作了。
那么,为什么ChatGPT会生成虚假的参考文献?
值得注意的是,ChatGPT使用的是统计模型,基于概率猜测下一个单词、句子和段落,以匹配用户提供的上下文。
由于语言模型的源数据规模非常大,因此需要「压缩」,这导致最终的统计模型失去了精度。
这意味着即使原始数据中存在真实的陈述,模型的「失真」会产生一种「模糊性」,从而导致模型产生最「似是而非」的语句。
简而言之,这个模型没有能力评估,它所产生的输出结果等同于一个真实的陈述。
另外,该模型是基于,通过公益组织「Common Crawl」和类似来源收集的公共网络数据,进行爬虫或抓取而创建的,数据截止到21年。
由于公共网络上的数据基本上是未经过滤的,这些数据可能包含了大量的错误信息。

近日,NewsGuard的一项分析发现,GPT-4实际上比GPT-3.5更容易生成错误信息,而且在回复中的说服力更加详细、令人信服。
在1月份,NewsGuard首次测试了GPT-3.5,发现它在100个虚假新闻叙述中生成了80个。紧接着3月,又对GPT-4进行了测试,结果发现,GPT-4对所有100种虚假叙述都做出了虚假和误导性的回应。
由此可见,在使用LLM工具过程中需要进行来源的验证和测试。
参考资料:
https://twitter.com/kareem_carr/status/1640003536925917185
https://scholar.harvard.edu/kareemcarr/home
https://www.newsguardtech.com/misinformation-monitor/march-2023/
编辑:于腾凯
校对:邱婷婷
