HBASE RPC 源码实现及解析
HBASE RPC 详细解析
注:下面的图是作者随便画的,不怎么严格,大家能看懂就好。
由于篇幅所限,本文只是大略的讲解了一下RPC所涉及到的大概模块,较为模糊,有兴趣者可以继续深挖
RPC(远程过程调用协议)是不同主机进程间通讯的一种方式,协议采用客户机-服务器模式的架构,请求程序为客户机,服务提供程序为服务器,hbase在client与server通信上采用的也是RPC协议,并在client端与server端实现了具体的RPC协议内容,现在我们就从客户机,服务器两个角度看一下hbase的RPC是怎样实现的。
第一部分 hbase客户端实现
hbase客户端的源码在hbase工程的子工程hbase-client中,其实现借助了google开源的序列化框架protobuf(其实不论客户端还是服务器端,hbase的RPC协议都是借助于protobuf实现的),主要表现在序列化上采用protobuf序列化协议,在service层的设计上遵循了protobuf框架的设计结构,这一点大家需要记着,因为后续很多设计都是和这个架构相关,并且比较纠结。
下面我们从主要的三个功能点看一下hbase客户端的架构
1 service代理模块
对外提供简单的代理接口供程序调用,隐藏RPC实现细节。
2 对象序列化及数据压缩
对要发送的数据进行序列化到字节流和由字节流到对象的操作,并可选择的对字节流进行压缩及解压。
3 寻址模块
提供感知服务器地址的功能,实现客户端对服务器端的寻址。
4 网络通信模块
网络通信模块负责具体的网络通信任务,又可将其细分为下面两个小模块
(1)链接管理模块
负责管理所有客户端对服务器端的网络连接。
(2)数据传输模块
执行具体的数据发送及接收任务

下面将各个模块详细介绍
1 service代理模块:
RPC的起点是远程过程调用API,在hbase中,这个API的实现是使用protobuf生成的在描述文件中定义的接口BlockingInterface,这个接口的实现在客户端和服务器端各有一份,客户端的实现描述了service层的协议。
关于protobuf的RPC架构,可以用下面的一张图表示

由上图可以看到,BlockingInterface只实现了RPC接口及服务器端方法的寻找,至于RPC中的网络通信,完全委托给了BlockingRpcChannel接口,而这个接口是需要应用自己实现的。
ProtoBuf的RpcChannel接口分为两种:BlockingRpcChannel和RpcChannel,分别代表阻塞调用和非阻塞调用,在hbase客户端中,只实现了BlockingRpcChannel进行数据的通信操作,其是由RpcClient的一个内部类BlockingRpcChannelImplementation实现。最终的通信过程是由Rpcclient(数据通讯)和RegionLocator(寻址)共同实现。
在RPC API的上层,是业务逻辑对象转换及通信控制,我们平常调用的API最后都会通过调用这些API的方式和hbase服务器端通信。
2 对象序列化及数据压缩模块
这里面有两个概念:对象的序列化及序列化之后的压缩
序列化:
Hbase序列化分为两种:
(1) protobuf序列化方式
Probuf本身即是一个序列化的框架,hbase中排除数据库数据对象的对象所采用的序列化只能使用protobuf序列化的方式,数据库数据对象的序列化可选择protobuf序列化,也可以采用cellblock序列化,probuf序列化方式序列化后的数据在传输之前不能压缩。
客户端最上层的所有实体对象(Put,Result等)都有对应的protobuf序列化对象,在传递之前,会使用protobufUtil进行对象类型的转换,以供protobuf的代理层调用时使用。
(2) cellblock序列化方式
Cellblock是hbase在一次RPC调用中传输的数据段中的一段,这一段是可选的,如果启用,则会将传输的数据对象写入这一段,而不是protobuf序列化后的一段中。
Hbase由于只支持byte数据类型的存储,所以本身数据对象核心数据即为byte数组类型,这为cellblock序列化提供了方便。
其原理是将数据对象按照顺序拿出所有对象所存储的byte,写入输出流。此种方式可支持自定义数据压缩。
数据压缩:
在客户端大量put或者大量scan的时候,网络IO会非常大,客户端可以配置数据流的压缩,以减少网络的IO。
笔者所经历的项目中,就有网络流量将网卡全部打满,被DBA打电话的经历。
上面已经说到了只有cellblock序列化方式支持压缩,这里所说的数据压缩就是数据通过cellblock进行传输时的压缩,所以必须开启cellblock序列化方式才能压缩数据。
Hbase支持三种压缩方式:gzip,snappy,lzo。客户端可以将数据压缩好之后传输,也可以让数据库将数据进行压缩后传递过来。
3 寻址模块:
Hbase的RPC客户端实现较服务器端实现稍显复杂,主要体现在它必须实现寻址功能。
之所以将寻址模块单独拿出来,没有放到网络通信中,是因为寻址模块是业务相关的,客户端通过table name及rowkey寻找目标region所在服务器,然后将目标服务器及数据传递给网路通信模块。
接口RegionLocator定义了寻址方法,方法通过rowkey参数寻找regionServer的地址,地址由HRegionLocation定义。
RegionLocator只有一个实现类,即HTable,但HTable并不实现具体的寻址功能,所有的寻址实现HTable全部委托给HConnection类来实现。(作者注:此处设计并不好,HConnection的定义更能够囊括RegionLocator的定义)
HConnection寻址的具体实现
Hbase 客户端的寻址包括两部分
(1)Master的寻址
(2)RegionServer的寻址
下面我们详细讲解Master的寻址和RegionServer的寻址。
Master的寻址
HMaster的地址是放到zookeeper上面的。
当HMaster启动时,Master Server会将自己的机器网络地址注册到zookeeper的hbase节点下的 /master上,客户端通过MasterAddressTracker获得Master的地址,并将其缓存到本地缓存中。
当MASTER由于其他原因主备切换后,client会重新到Zookeeper中寻找Master位置,并将其缓存在客户端中。
Region寻址
(1) hbase如何管理region地址信息
Hbase通过META表管理所有REGION的地址信息,每一个Region都会将自己所在的server地址注册到HBase的META表中。
客户端通过在META表中按照Region Name进行检索,便可以得到region所在的server。
那也许有人需要问了,那么META表我们去哪里找它呢?
(2) META表如何寻址
同Master的地址一样,META表的地址也会注册到zookeeper的HBase节点下的meta-region-server节点中,客户端通过MetaTableLocator获得注册在zookeeoer中的META表地址,并从中根据RegionName得到RegionServer的地址。
(3)效率问题-客户端META表缓存
由于在每一次访问hbase的时候都需要得到所访问数据所在的服务器地址,这便需要检索META表,为了减轻客户端对META表的检索压力,客户端在获得Region的地址时,并不是每次都会去META表中请求地址,而是先检查缓存中是否已经缓存了所要查找的Region地址,如果缓存了,便不再请求META 表。
HConnection通过MetaCache类缓存Meta表信息。
懒加载:
当产生于region交互的RPC请求时,CLIENT会先在本地内存中寻找是否缓存了对应region的地址,如果没有,则发起请求,请求META表,并将请求结果缓存到本地,即懒加载方式。
缓存失效处理:
当客户端拿着缓存中获得的地址去请求regionserver时,如果这时region已经移动,则region会抛出WrongRegionServerException,客户端检测到错误之后,会使缓存失效,并重新从META表中获得地址缓存,重新请求。(在callable类的prepare方法中)
4 网络通信模块
(1)链接管理:
这里我们先说一下BlockingChannel类,然后再说一下链接管理。
Blockingchannel实现类
上面说了protobuf的API并不实现网络通信功能,所有的网络通信功能全部委托给定义的一个接口:BlockingChannel,BlockingChannel的实现类在RpcClientImpl中,是RpcClient的一个内部类,但它也是不实现最终通信功能,最终的通信功能被委托给RpcClient接口实现类RpcClientImpl。
RpcClientImpl中的链接管理。
RpcClientImpl实现了与hbase各个后端服务器的链接管理,在RpcClient中有一个对象PoolMap,这个对象里面缓存了所有与服务器的链接。
下面我们看一下这个对象的key和value
Key即每个链接对应的唯一ID,代表这个概念的是ConnectionId类。
这里面有三个主要的属性:
1 InetSocketAddress:代表了一个网络通信地址
2 User:用户及用户组
3 ServiceName:String类型,代表是哪一个probuf的Service,例如是AdminService还是ClientService。
客户端用这三个属性唯一确定一个Connection。
Value为Connection类,这个类主要实现了与hbase服务器的通信,在网络通信模块中我们会详细展开细说这个类。
链接管理:
PoolMap提供了三种从连接池中的到链接的策略,这些策略使用一个枚举类表示:
public enum PoolType {
Reusable, ThreadLocal, RoundRobin;
}
Reusable:可重复利用的链接池,继承ConcurrentLinkedQueue,实现了多线程重复利用链接。
ThreadLocal:一个线程一个链接。
RoundRobin:轮询方式管理链接,亦实现了多线程重复使用。
默认情况:
默认情况使用ROUNDROBIN方式选择与某一服务器的connection链接,
客户端与每个服务器默认只会缓存一个Connection链接。
所以如果不配置的话,每一个ConnectionId只对应着一个connection。
(2)数据传输模块:
RpcClient依托内部类Connection进行网络通信,这个Connection便是链接管理中所管理的Value对象。Connection类有两种使用方式,主要区别在是否启动单独的写线程,通过在Configuration中配置hbase.ipc.client.specificThreadForWriting配置项控制是否开启。笔者认为这是客户端为异步功能做准备。当然,这也只不过是自己的观点(看下hbase2.0中是否已经有了)
数据传输结构:
Connection对象的核心属性如下:
DataInputStream in:socket数据输入流
DataOutputStream out:socket数据输出流
ConcurrentSkipListMap calls:Call请求的暂存处
CallSender callSender:启动独立写的时候的独立写线程工作体
数据传输核心对象:
Call:RpcClient将所有请求都统一封装为一个Call对象,底层Connection从Call对象中得到参数并将服务器端返回结果回写到Call对象中。
Connection 对象线程体
独立写线程:
开启独立写线程的情况下,会启动这个线程,写任务交由这个线程进行,而不是工作线程
读线程:
从Socket中读取数据,并将数据返回结果写入Call对象。
客户端数据传输流程:
客户端使用BIO的方式与server端进行交互,写入读取线程在进行IO操作时都会阻塞。
写(Request):
(1)未开启独立写线程的情况下
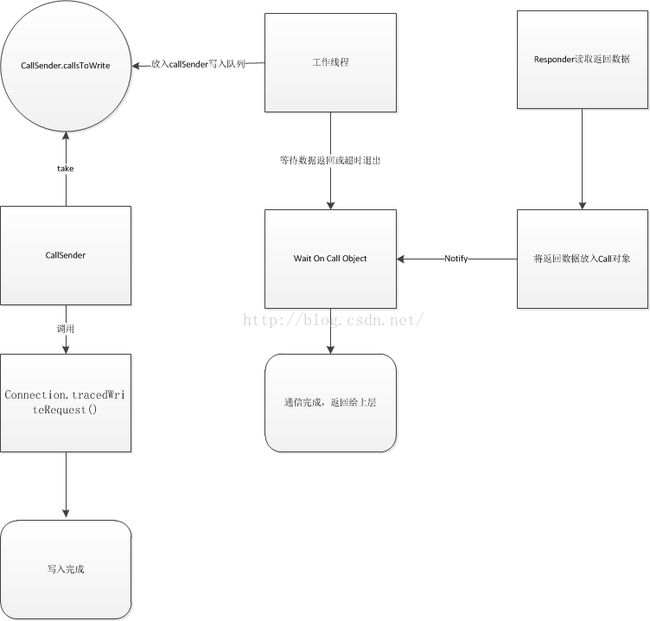
未开启独立写线程的情况下,RpcClient将封装好的Call对象直接调用Connection对象的tracedWriteRequest方法,工作线程进行写入,并阻塞直到写入完成。
(2)开启独立写线程的情况下
开启独立写线程的情况下,Call对象会直接被传递给CallSender对象,放入CallSender对象的写入队列中。独立写线程会从队列中拿出Call对象,并调用Connection的tracedWriteRequest方法,阻塞直到写入完成。
读(Response):
读是由单独线程进行处理的,处理工作体为Connnection对象的run方法。
读取线程会在socket的输入流上一直阻塞,直到有数据传递过来,下一步线程会进行数据的反序列化,并拿到Call对象的唯一标识CallId,从calls 表中得到Call对象,然后将结果写入Call对象,并将等待在此Call对象上的工作线程notify,继续进行下一次等待。
工作线程不管采取哪种方式写入之后,会在Call对象上执行wait方法等待,并循环检测Call的标志位done判断是否就绪,若数据正常返回,Connection的读线程会notify工作线程,这时工作线程会从Call中读取response属性得到返回结果;若超时,链接关闭,线程等待被打断,也会退出循环执行后续逻辑。
我们可以看到,客户端是使用同步阻塞IO进行网络通信,并没有使用NIO,读和写分离,每个socket链接有一个读线程,配置独立写线程时,还会有一个写线程负责写入,结果并不是按照请求顺序返回的,我们会在server端实现中详细解释。
下图是hbase在开启独立写线程的情况下,三个线程的协同图
第二部分 RPC 服务器端实现
服务器端由接受请求到处理请求,经过的模块有
1 网络传输模块:
负责接收请求并将处理结果发送回客户端。
2 数据反序列化与压缩:
同客户端序列化与压缩,
3 任务处理模块:
负责任务的分发及最终任务的实现。
1 网络传输模块:
RPC服务器端即Hbase服务器端,服务器端使用的是NIO架构,以提升服务器的处理能力。
RpcServer类实现了服务器端的网络传输,其中主要的内部属性为:
对象属性:
Connection对象:
代表与客户端的一个链接
Call:
代表一个客户端的请求
RpcScheduler:
业务逻辑处理分配器
线程执行体:
Listener:
负责监听OP_ACCEPT事件,处理链接请求并将一个客户端的链接分配给某一个Reader线程。
Reader:
负责监听OP_READ事件并通知Connection对象读取并处理数据。
Responder:
负责将最终的处理结果写入socket
Call实现:
Call代表一个客户端的请求,对应客户端的Call对象,其中亦包括callId,CellScanner,Message等属性,当然这个Call对象和客户端中的Call对象不是一个对象,这个对象中有很多服务器端所特有的属性,例如这个Call是属于哪个Connection链接的,负责将处理结果写回客户端的Responder是哪个(当然这里只有一个)?
Connection实现:
Connection代表和客户端启动的一个链接。对应客户端中的Connection对象,包括与客户端通信的socket,接收客户端发送过来数据的ByteBuffer对象等,同Call对象,这个和Call的Connection也不是一个对象。
RpcScheduler:
业务逻辑处理分配器,我们在后续的业务逻辑分级处理中讲解。
Listener的实现
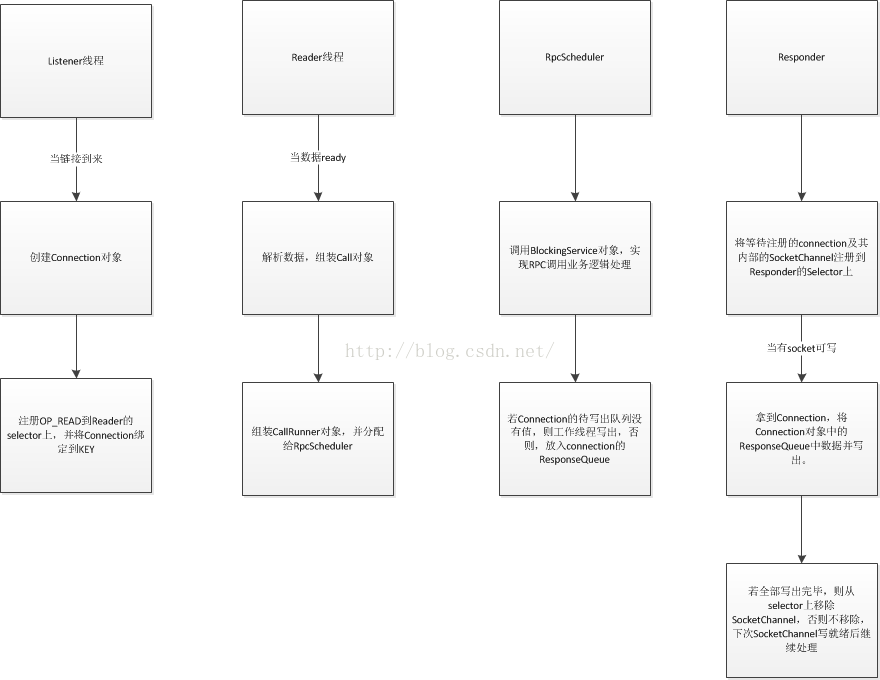
Listener在初始化时,会创建一个Selector对象,当Listener打开监听端口时,会将这个端口注册进Selector对象中,并注册OP_ACCEPT事件。
随后Listener线程启动,并在Selecotor对象的select方法阻塞。
当有链接请求过来时,listener会创建Connection对象,并将生成的Connection对象按照Round Robin的方式分配给Reader对象。
Listener线程在server端只有一个。
Reader的实现
Listener初始化的时候初始化了N个Reader对象,这些对象负责各个客户端的数据读取请求,当有客户端连接到监听端口上时,Listener会将生成的客户端连接分配给Reader对象,后续处理委托给Reader对象。
Reader线程初始化时也会创建独立的一个Selector,负责监听后续注册到这个Reader对象上的链接产生的OP_READ事件。
同Listener,线程运行时,会阻塞在这个Seletor的select方法上,当Selector监听到OP_READ事件时,Reader会得到相应的Connection对象,并将后续处理委托给Connection。
Reader线程在server端会有多个,通过hbase.ipc.server.read.threadpool.size
配置,默认为10。
Responder:
像上面的Listener,Reader一样,Responder同样有一个Selector,当RpcScheduler将业务逻辑处理完毕时,会将Connection对象放入Responder中的待写集合中,Responder会在业务循环中将这些connection所对应的SocketChannel全部注册到selector上面,监听所有SocketChannel的OP_WRITE事件,并在SocketChannel可写时将Call对象中的处理结果写入SocketChannel。
当SocketChannel注册到selector上之后,若需要写出的任务已经全部处理完毕,后续没有写出任务,selector会频繁触发OP_WRITE事件,所以在将现有任务全部写出之后,selector会将此SocketChannel从此Selector上删除,防止频繁无用的OP_WRITE事件,鉴于如此,我们在每次业务逻辑处理完成,并且业务线程没有将数据全部写出之后,都需要判断一下这个SocketChannel是否注册到Responder的selector上,若不是的话,会重新注册OP_WRITE事件。
Responder线程在server端只有一个。
现在我们将上面所有的对象和线程串联起来:
Listener线程负责监听客户端连接信息,一旦有连接进来,则创建Connection对象,并将后续处理交给Reader,Reader监听到有请求过来,则调用Connection中函数处理数据,将传递过来的数据包装成Call对象,并传递给RpcScheduler,RpcScheduler处理完业务逻辑,则将Call对象放入Connection对象的待写出队列,等待Responder处理,或者如果写出队列为空,则直接由RpcScheduler中的业务线程进行返回数据的写回处理。
2 数据的序列化及压缩:
数据的序列化及压缩由Connection对象完成,
对应客户端,序列化与反序列化仍然由两部分组成
(1) 非cellScanner使用protobuf序列化及反序列化
(2) cellScanner使用自定义的序列化及反序列化
压缩及解压:
和客户端一样,压缩及解压只能使用在cellScanner段。
服务器端的压缩及解压是由客户端决定的,即客户端cellScanner使用什么样的压缩方法传递数据,则服务器端必须使用同样的压缩方法将数据压缩后传递,支持的仍然是三类:GZIP,LZO,SNAPPY。
3 任务分发及处理
RPCScheduler:
RpcScheduler负责具体的任务分配,hbase在server端使用多线程执行客户端发送过来的调用请求,RpcScheduler便是将客户端的请求分配给不同的线程线程进行处理。
RpcScheduler有两个不同的实现类,FifoRpcScheduler和SimpleRpcScheduler,其中FifoRpcScheduler是为HMaster准备的,在1.0.1.1版本中已经没有使用了,这个版本全部使用的是SimpleRpcSchduler。
SimpleRpcSchduler实现了一个任务分级处理的线程池,在其内部,有三个RpcExecutor线程池对应不同的处理等级,分别是
priorityExecutor:负责优先级大于10的请求
replicationExecutor:负责优先级为5,即REPLICATION_QOS的请求
callExecutor:负责处理其余等级的请求
RpcExecutor及其执行体CallRunner
RpcExecutor有两个实现类,RWQueueRpcExecutor和BalancedQueueRpcScheduler。
RWQueueRpcExecutor实现了多队列,多线程的线程池,并且读,写,scan分离,任务由RandomQueryBalancer随机分配。
BalancedQueueRpcScheduler简单的实现了多队列,多线程(队列数和线程数不一定相等)的任务随机分配线程池,未实现读写的分离。
CallRunner为RpcExecutor的线程执行体,内部含有Call对象,在其run方法中执行了调用了最终的业务逻辑,将Call放入Connection的response队列,并将connection放入responseder的等待写出队列。
protobuf service协议实现层
在CallRunner中,会调用rpcServer.call方法,这个方法会按照方法的index调用BlockingInterface的server端实现,RegionServer端是RsRpcServices类,Master端是MasterRpcServices类。