第九天 Python爬虫之Scrapy(框架工作原理 )
@作者 : SYFStrive
@博客首页 : HomePage
上一篇续文传送门
:个人社区(欢迎大佬们加入) :社区链接
:如果觉得文章对你有帮助可以点点关注 :专栏连接
: 感谢支持,学习累了可以先看小段由小胖给大家带来的街舞
:阅读文章

目录
- 简介
-
- Scrapy使用前准备
- 续Scrapy之简单练习
-
- 案例小总结
- Scrapy之工作原理
- 最后
简介
- Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据 (例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
- Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。
- 提示:Twisted 是一个基于事件驱动的网络引擎框架,同样采用 Python 实现。
Scrapy使用前准备
- 文档如
- 官网文档:链接
- C语言中文文档:链接
- 安装
- 安装语法:python -m pip install Scrapy
- 报错:使用pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn 加包名
续Scrapy之简单练习
获取数据:汽车的名字 && 价格
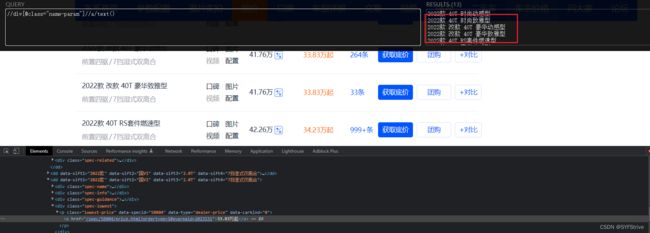
代码演示:
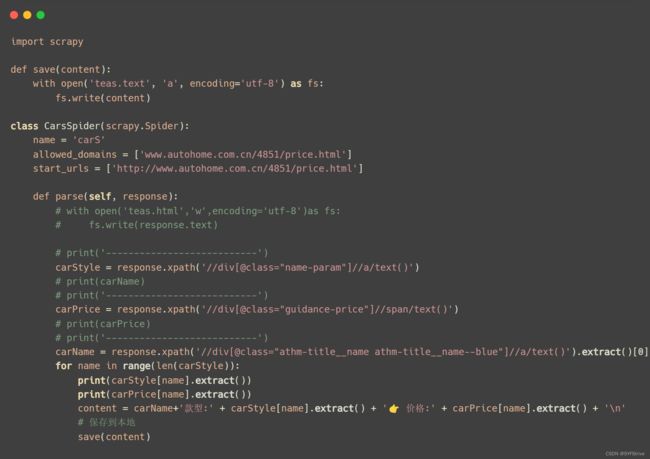
如下图(爬取成功):
案例小总结
注意⚠:遇到http://www.autohome.com.cn/4851/price.html/(html结尾的后面不能加 / )
Scrapy之工作原理
- 架构组成
- 引擎 自动运行,无需关注,会自动组织所有的请求对象,分发给下载器
- 下载器 从引擎处获取到请求对象后,请求数据
- spiders Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
- 调度器 有自己的调度规则,无需关注
- 管道(Item pipeline) 最终处理数据的管道,会预留接口供我们处理数据当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
- 原理图如下:

- 文字说明(麻将理解):由spiders(最开始打牌的选手) 发送给引擎 发送给调度器 (他碰了) 请求引擎 请求下载器(他碰了然后到互联网一顿操作(作弊)) 拿到了数据 发送到引擎(这条线相当于Response) spiders(一些列相关处理) 解析结果 (这里有两个去向)1. 如何解析的是数据那么存储到文件 2、如果是Uri那么从就从调度器开始又一次循环 ……
Response如下:
Spiders如下:
最后
Scrapy框架还未结束(待更),觉得不错的请给我专栏点点订阅,你的支持是我们更新的动力,感谢大家的支持,希望这篇文章能帮到大家
点击跳转到我的Python专栏

下篇文章再见ヾ( ̄▽ ̄)ByeBye
 `
`