全链路日志追踪系统介绍与思考
文章目录
- 什么是全链路日志追踪
- 为什么需要分布式调用链
- 如何实现
-
- 开源框架
- 其他框架
- 个人思考的实现思路
-
- 基础框架代码部分实现思路
-
- 唯一id生成策略
-
- Snowflake算法
- ObjectId
- Redis
- http请求及rpc请求拦截与日志实现
- 日志收集组件考虑及选型
-
- Elasticsearch与Click house的对比及选择
什么是全链路日志追踪
谷歌的一篇论文,论述了相关的概念。论文讲述了谷歌的大规模分布式系统全链路日志追踪基础设施Dapper。
论文下载地址
全链路日志追踪主要应用于大规模的、复杂的分布式系统之中。其中,有几个主要的概念:
-
trace_id:分布式全局唯一id标识,由系统第一个被调起的模块生成,并在各个span间传递;
-
span_id:区分模块用id,通过span_id和trace_id可以定位到具体的模块的一次请求;
-
parent_span_id:调用当前模块的父级模块span_id;
-
Cs CLIENT_SEND:客户端发起请求;
-
Cr CLIENT_RECIEVE:客户端收到响应;
-
Sr SERVER_RECIEVE:服务端收到请求;
-
Ss SERVER_SEND:服务端发送结果;
另外,有些实现,会产生rpc_id去记录下一次完整rpc调用的链路;
根据采集到的数据,可以还原一次调用链路的树状图,可以通过该树状图明确的看出各个服务间调用的情况,响应时间等数据,如下图所示:

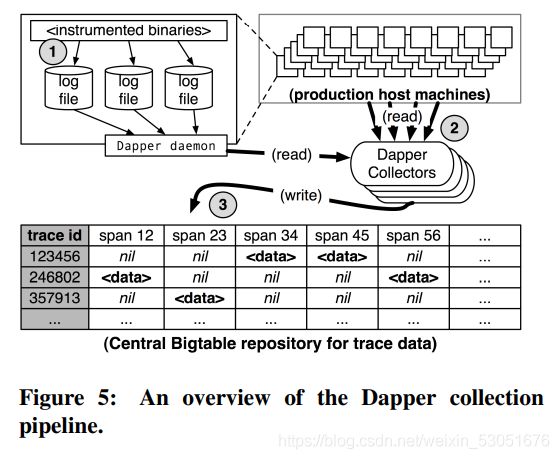
通过论文的阅读可以知道,Dapper的实现思路是:
- 产生日志;
- 采集日志;
- 写表;
调用链的基本要求:
- 低开销;
- 应用层透明;
- 可扩展;
- 收集及时。
为什么需要分布式调用链
大规模的,复杂的分布式应用,大多会采用集群部署,一个服务会有多个服务器同时运行,而服务与服务间会相互调用。如论文中的这幅图,一个用户的请求,请求A,A通过调用B后,A又调用C,而C又需要调用D、E后返回。

一般一个请求,会请求不同的服务器,由不同的服务器完成各种的业务,而如果其中有一个服务产生问题,那么将会导致整个请求链路发生问题,对于工程师而言,需要及时定位并且解决线上问题,而线上哪台服务器出现故障、出现了什么故障是极难定位的,而且工程师无法熟悉每一个服务的情况。
所以需要一个监控,去监控线上各个服务的运行情况,记录下每一个请求从用户发起到最终响应的调用链路。报错的情况下,能够记录下对于报错的节点。
如何实现
开源框架
zipkin
开源地址
通过拦截器在请求前后分别埋点,但是曾经使用这个框架写过一个dome工程,引入该框架后,启动会变得很慢且卡,不过也可能只是个人使用不当的原因。
其他框架
-
Google的Drapper
-
阿里-鹰眼
-
大众点评——CAT
-
京东-hydra
个人思考的实现思路
现在大多数的公司的实现思路基本上也与Dapper相类似,只不过各自实现不同。整体架构上,由基础架构实现各类id生成,日志记录等相关功能,由ELK/ELKB或者其他日志收集系统进行日志的采集,最终由日志分析系统分析对于的数据生成拓扑图,各种分析数据列表。
采用ELK/ELKB进行日志采集相对来说会比较简单,而且除了采集全链路日志外,而且网上有比较多的资料和实现方案,也是在实际工作中有遇到过的解决方案之一。然后,就像,其中ELK架构也不是一成不变的,其中各个部分都是可以采用其他组件进行对应的替代。例如Elasticsearch可以采用Hbase、HDFS、Click house等进行代替,Kafka采用redis、pulsar等进行替换,Logstash、Beats可以采用flume等进行替换,Kibana一般是需要根据实际需求去进行开发替代、二开或者一起用。
而该方案也不止可以用于采集全链路日志,Logstash可以对推送数据进行正则匹配后,将日志分发出去,如果要采样埋点数据,安全检查数据,sql执行数据等,都可以采用该方案进行实现。
基础框架代码部分实现思路
唯一id生成策略
Snowflake算法
Twitter开源的分布式ID生成算法,结果为一个long型id,其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID,12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。
该算法简单高效,生成速度快;时间戳在高位,自增序列在低位,整个ID是趋势递增的,按照时间有序递增;灵活度高,可以根据业务需求,调整bit位的划分,满足不同的需求。
ObjectId
MongoDB的ObjectID生成策略 MongoDB官方文档 ObjectID
Redis
采用Redis的原子操作来生成唯一id。
http请求及rpc请求拦截与日志实现
这两个相对简单,http采用Filter过滤器进行拦截,rpc如果采用的是dubbo框架进行实现(后面默认采用dubbo),则可以采用对应的Filter过滤器进行拦截,但是这两个过滤器是不同的,分属于不同的包。
而trace_id的传递,http可以通过InheritableThreadLocal进行传递,而rpc则需要通过上下文进行传递。
日志收集组件考虑及选型
Elasticsearch与Click house的对比及选择
Elasticsearch和Click house都是分布式设计的,Elasticsearch是底层是基于Lucenc,ClickHouse是基于MPP架构的分布式ROLAP(关系OLAP)分析引擎。
Click house在开发上,上手速度更快,因为其语法与SQL基本一致;在性能上,不管是写入还是查询的性能都及其优秀。
但Click house在2016年进行开源,相关资料比较少,而且版本间的区别有时候比较混乱,有部分问题需要使用指定版本进行解决,例如曾经遇到的写入内存溢出问题,Click house提供了对应的解决方案,而相关配置项配置后,却无法生效,最后升级到某个指定版本后,才解决了该问题。而且采用http协议与tcp协议进行连接查询时候SQL会有一定的区别。
ClickHouse 是一个真正的列式数据库管理系统(DBMS)。在 ClickHouse 中,数据始终是按列存储的,包括矢量(向量或列块)执行的过程。只要有可能,操作都是基于矢量进行分派的,而不是单个的值,这被称为«矢量化查询执行»,它有利于降低实际的数据处理开销。Clickhouse同时使用了日志合并树,稀疏索引和CPU功能(如SIMD单指令多数据)充分发挥了硬件优势,可实现高效的计算。Clickhouse 使用Zookeeper进行分布式节点之间的协调。
其优秀的性能也使得有些公司开始考虑将一些应用从ES切换到Clickhouse上。
相关参考:
Elasticsearch和Clickhouse基本查询对比 - 知乎 (zhihu.com)
分布式调用链路与Dapper论文阅读笔记 - 知乎 (zhihu.com)
36356.pdf (googleusercontent.com)
Welcome to Apache Flume — Apache Flume
ClickHouse 架构概述 | ClickHouse文档