MySQL集群:主从模式
目录
1、mysql主从复制用途
2、主从部署必要条件
3、主从模式实现原理
3.1、主从复制
3.2、半同步复制
3.3、并行复制
3.3.1、MySQL5.6并行复制原理
3.3.2、MySQL5.7并行复制原理
3.3.3、MySQL5.8并行复制
3.3.4、并行复制配置与调优
3.3.5、并行复制监控
3.4、读写分离
3.4.1、主从同步延迟
3.4.2、读写分配机制
4、主从模式实战
4.1、主从复制
4.1.1、修改主库my.ini配置文件
4.1.2、在主库配置slave访问master的用户的ip权限
4.1.3、修改从库my.ini配置文件
4.1.4、从库配置关联主库
4.2、半同步复制
4.2.1、主库安装半同步复制插件semi
4.2.2、修改semi相关配置
4.2.3、从库安装半同步复制插件semi
4.3、并行复制
4.3.1、主库设置基于组提交的并行复制
4.3.2、从库设置并行复制(也可以直接在my.ini文件中进行配置)
数据可以从一个MySQL数据库主节点复制到多个从节点(异步复制)。
1、mysql主从复制用途
- 实时灾备,用于故障切换(高可用)
- 读写分离,提供查询服务(读扩展)
- 数据备份,避免影响业务(高可用)
2、主从部署必要条件
- 从库服务器能连通主库
- 主库开启binlog日志(设置log-bin参数)
- 主从server-id不同
3、主从模式实现原理
3.1、主从复制

主从复制主要有以下三大步骤:
- 主库将数据库的变更操作记录到Binlog日志文件中
- 从库读取主库中的Binlog日志文件信息写入到从库的Relay Log中继日志中
- 从库读取中继日志信息在从库中进行Replay,更新从库数据信息
以上三个步骤,分别涉及主库的BinlogDump Thread和从库的IO Thread、SQL Thread,其中:
- Master服务器对数据库更改操作记录在Binlog中,BinlogDump Thread接到写入请求后,读取Binlog信息推送给Slave的I/O Thread。
- Slave的I/O Thread将读取到的Binlog信息写入到本地中继日志Relay Log中。
- Slave的SQL Thread检测到Relay Log的变更请求,解析relay log中内容在从库上执行。
在主库的binlogDump Thread将binlog信息推送给从库的IO Thread后,从库进行异步处理,存在数据延迟的情况。

3.2、半同步复制

MySQL让Master在某一个时间点等待Slave节点的 ACK消息,接收到ACK消息后才进行事务提交,可降低数据丢失的问题。
3.3、并行复制
目的是解决从库复制延迟的问题。
从库在复制主库数据时,主要是依赖IO Thread和SQL Thread两个线程,而这两个都是单线程,所以存在延迟问题。我们可通过使用SQL Thread多线程来加强从库复制,减少从库复制延迟。
3.3.1、MySQL5.6并行复制原理
基于数据库的并行复制,每个数据库使用一个单独的SQL Thread。但无法解决单库多表的从库复制延迟问题。也无法处理事务并行处理的执行顺序。
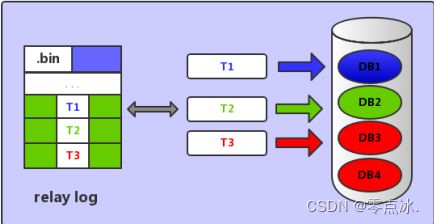
如下所示:事务T1、T2、T3,分别操作数据库DB1、DB2、DB3,三个事务互不影响,因此在Mysql5.6就会有三个SQL Thread线程,分别执行三个事务的写入操作。
3.3.2、MySQL5.7并行复制原理
InnoDb事务提交为两阶段提交:一个阶段是prepare,一个阶段是commit。
基于组提交的并行复制,多个事务如果能同时提交成功,说明这些事务是没有冲突的,可以并行提交,那么就把这些事务分为一组,在主库上的二进制日志中添加组提交信息。在从库上就可以并行复制了。
MySQL 5.7的并行复制基于一个前提,即所有已经处于prepare阶段的事务,都是可以并行提交的。
MySQL5.7配置复制方式:
变量slave-parallel-type,其可以配置的值有:DATABASE(默认值,基于库的并行复制方式)、LOGICAL_CLOCK(基于组提交的并行复制方式)
从库复制时如何从binlog日志中,判断哪些事务是可以并行复制的?
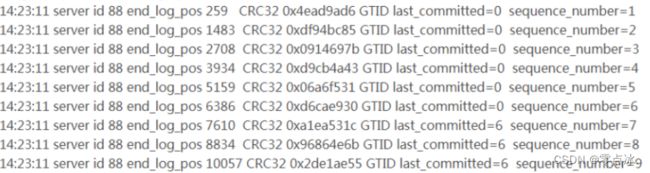 last_committed表示事务提交时,上次事务提交的编号。相同的为同一组,可以进行并行复制。
last_committed表示事务提交时,上次事务提交的编号。相同的为同一组,可以进行并行复制。
3.3.3、MySQL5.8并行复制
基于write-set的并行复制,并行颗粒度为行记录。MySQL会有一个集合变量来存储事务修改的记录信息(主键哈希值),所有已经提交的事务所修改的主键值经过hash后都会与那个变量的集合进行对比,来判断该行是否与其冲突,并以此来确定依赖关系,没有冲突即可并行。这样的粒度,就到了row级别了,此时并行的粒度更加精细,并行的速度会更快。
3.3.4、并行复制配置与调优
- binlog_transaction_dependency_history_size
用于控制集合变量的大小。
- binlog_transaction_depandency_tracking
用于控制binlog文件中事务之间的依赖关系,即last_committed值。
COMMIT_ORDERE: 基于组提交机制
WRITESET: 基于写集合机制
WRITESET_SESSION: 基于写集合,比writeset多了一个约束,同一个session中的事务last_committed按先后顺序递增
- transaction_write_set_extraction
用于控制事务的检测算法,参数值为:OFF、 XXHASH64、MURMUR32
- master_info_repository
开启MTS(并行复制)功能后,务必将参数master_info_repostitory设置为TABLE,这样性能可以有50%~80%的提升。这是因为并行复制开启后对于元master.info这个文件的更新将会大幅提升,资源的竞争也会变大。
- slave_parallel_workers
若将slave_parallel_workers设置为0,则MySQL 5.7退化为原单线程复制,但将slave_parallel_workers设置为1,则SQL线程功能转化为coordinator线程,但是只有1个worker线程进行回放,也是单线程复制。然而,这两种性能却又有一些的区别,因为多了一次coordinator线程的转发,因此slave_parallel_workers=1的性能反而比0还要差。
- slave_preserve_commit_order
MySQL 5.7后的MTS可以实现更小粒度的并行复制,但需要将slave_parallel_type设置为LOGICAL_CLOCK,但仅仅设置为LOGICAL_CLOCK也会存在问题,因为此时在slave上应用事务的顺序是无序的,和relay log中记录的事务顺序不一样,这样数据一致性是无法保证的,为了保证事务是按照relay log中记录的顺序来回放,就需要开启参数slave_preserve_commit_order。
3.3.5、并行复制监控
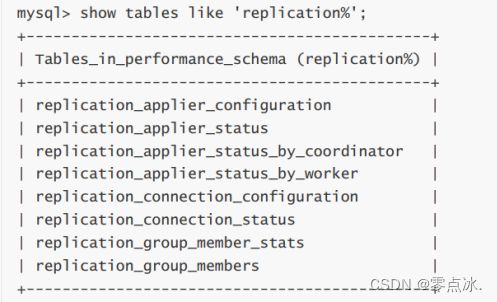
在使用了MTS(并行复制)后,复制的监控依旧可以通过SHOW SLAVE STATUS\G,但是MySQL 5.7在performance_schema库中提供了很多元数据表,可以更详细的监控并行复制过程。
3.4、读写分离
读写分离首先需要将数据库分为主从库,一个主库用于写数据,多个从库完成读数据的操作,主从库之间通过主从复制机制进行数据的同步。

在应用中可以在从库追加多个索引来优化查询,主库这些索引可以不加,用于提升写效率。
读写分离架构也能够消除读写锁冲突从而提升数据库的读写性能。使用读写分离架构需要注意:主从同步延迟和读写分配机制问题。
3.4.1、主从同步延迟
主从同步具有延迟性,数据一致性会受到影响,可通过以下方式解决:
- 写后一段时间读主库
在写入数据库后,某个时间段内读操作就去主库,之后读操作访问从库。
- 二次查询
先去从库读取数据,找不到时就去主库进行数据读取。该操作容易将读压力返还给主库,为了避免恶意攻击,建议对数据库访问API操作进行封装,有利于安全和低耦合。
- 根据业务特殊处理
根据业务特点和重要程度进行调整,比如重要的,实时性要求高的业务数据读写可以放在主库。对于次要的业务,实时性要求不高可以进行读写分离,查询时去从库查询。
3.4.2、读写分配机制
该机制用于控制何时去主库写,何时去从库读,有以下两种方案实现:
- 基于编程和配置实现
代码中进行多数据源配置,根据操作类型进行路由分配,增删改时操作主库,查询时操作从库。
缺点是需要开发人员来实现,运维人员无从下手,如果其中一个数据库宕机了,就需要修改配置重启项目。
- 基于服务器端代理实现
在应用和数据库之间做一个代理服务器,应用不直接访问数据库,而是访问代理服务器,由代理服务器根据路由规则决定走master还是slave。常见的数据库中间件有MySQL Proxy,MyCat。

4、主从模式实战
4.1、主从复制
4.1.1、修改主库my.ini配置文件
- 开启bin log日志功能
- 设置server-id
- 指定需要同步的数据库

4.1.2、在主库配置slave访问master的用户的ip权限
grant replication slave on *.* to 'root'@'%' identified by 'root';
grant all privileges on *.* to 'root'@'%' identified by 'root';

show master status;

4.1.3、修改从库my.ini配置文件
在配置文件中指定唯一id:server-id
4.1.4、从库配置关联主库
change master to master_host='主库ip', master_port=主库端口号, master_user='主库用户名', master_password='主库密码', master_log_file='主库日志文件名',master_log_pos=主库position;
示例:
change master to master_host='192.168.159.132', master_port=3306, master_user='slave', master_password='123456', master_log_file='mysql-bin.000030',master_log_pos=730;
show slave status;

4.2、半同步复制
4.2.1、主库安装半同步复制插件semi
## Linux安装插件取名时使用.so
install plugin rpl_semi_sync_master soname 'semisync_master.so';
## Windows安装插件取名时使用.dll
install plugin rpl_semi_sync_master soname 'semisync_master.dll';
4.2.2、修改semi相关配置
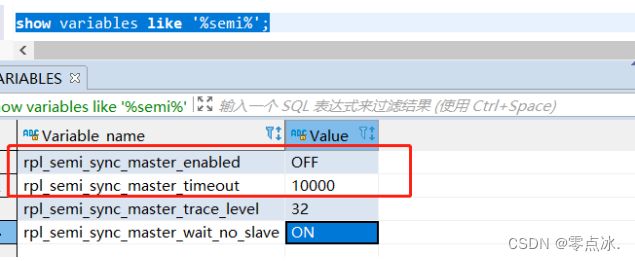
show variables like '%semi%';
set global rpl_semi_sync_master_enabled=1;
set global rpl_semi_sync_master_timeout=1000;
4.2.3、从库安装半同步复制插件semi
install plugin rpl_semi_sync_slave soname 'semisync_slave.dll';
set global rpl_semi_sync_slave_enabled=1;
4.3、并行复制
4.3.1、主库设置基于组提交的并行复制
show variables like '%binlog_group%';
set global binlog_group_commit_sync_delay=1000;
set global binlog_group_commit_sync_no_delay_count=100;
4.3.2、从库设置并行复制(也可以直接在my.ini文件中进行配置)
show variables like '%slave%';
stop slave;
set global slave_parallel_type='LOGICAL_CLOCK';
##线程数
set global slave_parallel_workers=8;
##从库中继日志
show variables like '%relay_log%';
set global relay_log_recovery=1;
set global relay_log_info_repository='TABLE';
start slave;
以上内容为个人学习理解,如有问题,欢迎在评论区指出。
部分内容截取自网络,如有侵权,联系作者删除。