ElasticSearch集群
5.2 IK分词器简介
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出 了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为 面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
IK分词器3.0的特性如下:
1)采用了特有的“正向迭代最细粒度切分算法“,具有60万字/秒的高速处理能力。
2)采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
3)对中英联合支持不是很好,在这方面的处理比较麻烦.需再做一次查询,同时是支持个人词条的优化的词典存储,更小的内存占用。
4)支持用户词典扩展定义。
5)针对Lucene全文检索优化的查询分析器IKQueryParser;采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。
5.3 ElasticSearch集成IK分词器
5.3.1 IK分词器的安装
1)下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
课程资料也提供了IK分词器的压缩包:

2)解压,将解压后的elasticsearch文件夹拷贝到elasticsearch-5.6.8\plugins下,并重命名文件夹为analysis-ik

3)重新启动ElasticSearch,即可加载IK分词器
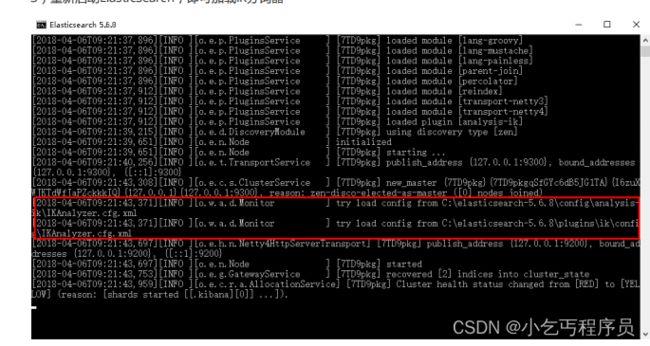
5.3.2 IK分词器测试
IK提供了两个分词算法ik_smart 和 ik_max_word
其中 ik_smart 为最少切分,ik_max_word为最细粒度划分
我们分别来试一下
1)最小切分:在浏览器地址栏输入地址
http://127.0.0.1:9200/_analyze?analyzer=ik_smart&pretty=true&text=我是程序员
输出的结果为:
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "程序员",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
2)最细切分:在浏览器地址栏输入地址
http://127.0.0.1:9200/_analyze?analyzer=ik_max_word&pretty=true&text=我是程序员
输出的结果为:
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "程序员",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "程序",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "员",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 4
}
]
}
5.4 修改索引映射mapping
5.4.1 重建索引
删除原有blog1索引
DELETE localhost:9200/blog1
创建blog1索引,此时分词器使用ik_max_word
PUT localhost:9200/blog1
{
"mappings": {
"article": {
"properties": {
"id": {
"type": "long",
"store": true,
"index":"not_analyzed"
},
"title": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"ik_max_word"
},
"content": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"ik_max_word"
}
}
}
}
}
创建文档
POST localhost:9200/blog1/article/1
{
"id":1,
"title":"ElasticSearch是一个基于Lucene的搜索服务器",
"content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。"
}
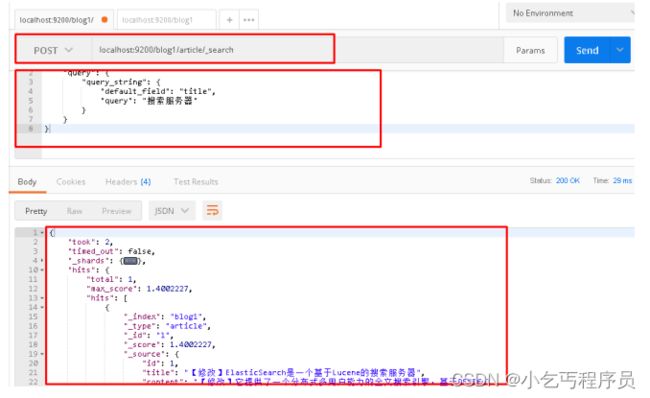
5.4.2 再次测试queryString查询
请求url:
POST localhost:9200/blog1/article/_search
请求体:
{
"query": {
"query_string": {
"default_field": "title",
"query": "搜索服务器"
}
}
}
postman截图:
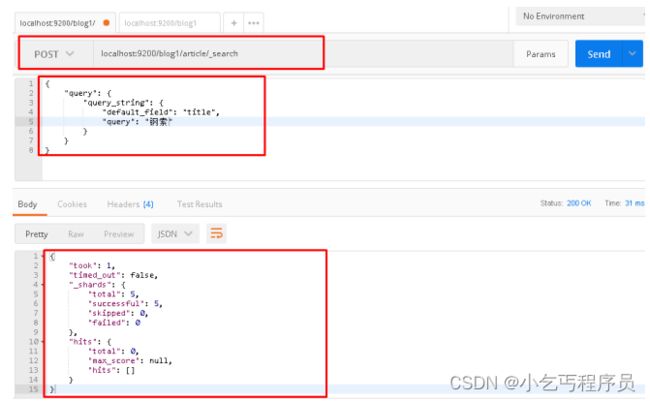
将请求体搜索字符串修改为"钢索",再次查询:
{
"query": {
"query_string": {
"default_field": "title",
"query": "钢索"
}
}
}
postman截图:
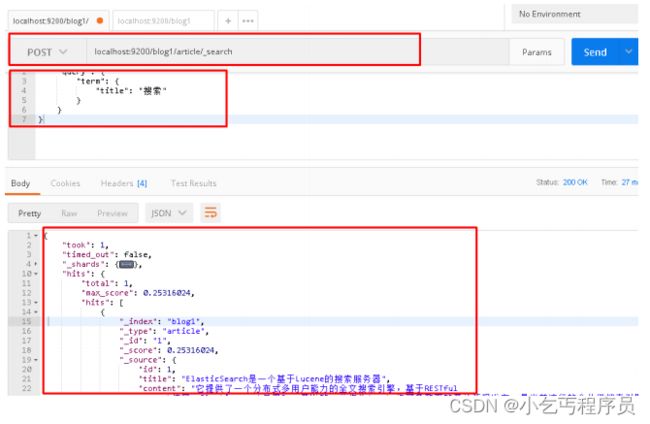
5.4.3 再次测试term测试
请求url:
POST localhost:9200/blog1/article/_search
请求体:
{
"query": {
"term": {
"title": "搜索"
}
}
}
postman截图:
第六章 ElasticSearch集群
ES集群是一个 P2P类型(使用 gossip 协议)的分布式系统,除了集群状态管理以外,其他所有的请求都可以发送到集群内任意一台节点上,这个节点可以自己找到需要转发给哪些节点,并且直接跟这些节点通信。所以,从网络架构及服务配置上来说,构建集群所需要的配置极其简单。在 Elasticsearch 2.0 之前,无阻碍的网络下,所有配置了相同 cluster.name 的节点都自动归属到一个集群中。2.0 版本之后,基于安全的考虑避免开发环境过于随便造成的麻烦,从 2.0 版本开始,默认的自动发现方式改为了单播(unicast)方式。配置里提供几台节点的地址,ES 将其视作 gossip router 角色,借以完成集群的发现。由于这只是 ES 内一个很小的功能,所以 gossip router 角色并不需要单独配置,每个 ES 节点都可以担任。所以,采用单播方式的集群,各节点都配置相同的几个节点列表作为 router 即可。
集群中节点数量没有限制,一般大于等于2个节点就可以看做是集群了。一般处于高性能及高可用方面来考虑一般集群中的节点数量都是3个及3个以上。
6.1 集群的相关概念
6.1.1 集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群
6.1.2 节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
6.1.3 分片和复制 shards&replicas
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。分片很重要,主要有两方面的原因:
1)允许你水平分割/扩展你的内容容量。
2)允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
6.2 集群的搭建
6.2.1 准备三台elasticsearch服务器
创建elasticsearch-cluster文件夹,在内部复制三个elasticsearch服务
6.2.2 修改每台服务器配置
修改elasticsearch-cluster\node*\config\elasticsearch.yml配置文件
node1节点:
#节点1的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-1
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9200
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9300
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
node2节点:
#节点2的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-2
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9201
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9301
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
node3节点:
#节点3的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-3
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9202
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9302
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
6.2.3 启动各个节点服务器
双击elasticsearch-cluster\node*\bin\elasticsearch.bat
启动节点1:
启动节点2:
启动节点3:
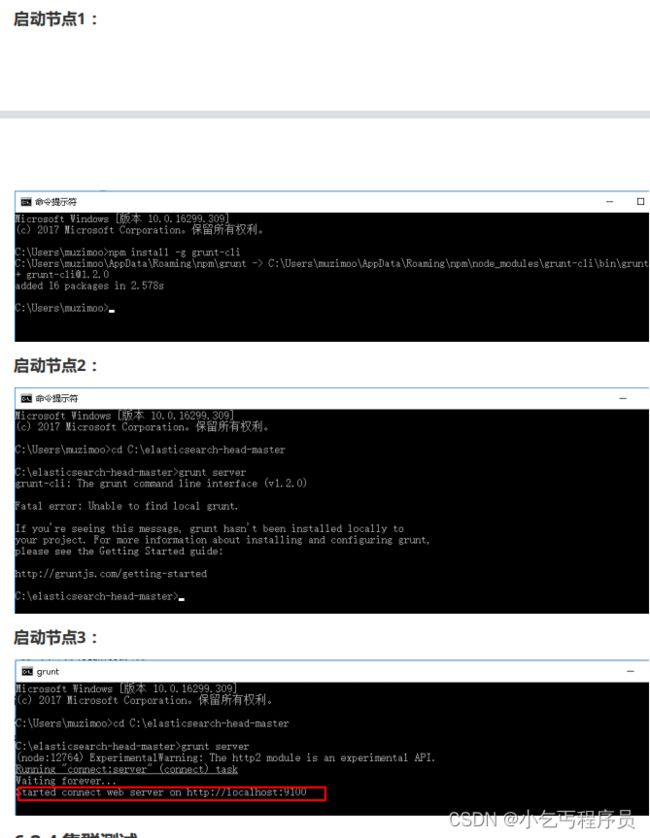
6.2.4 集群测试
添加索引和映射
PUT localhost:9200/blog1
{
"mappings": {
"article": {
"properties": {
"id": {
"type": "long",
"store": true,
"index":"not_analyzed"
},
"title": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"standard"
},
"content": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"standard"
}
}
}
}
}
添加文档
POST localhost:9200/blog1/article/1
{
"id":1,
"title":"ElasticSearch是一个基于Lucene的搜索服务器",
"content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。"
}
使用elasticsearch-header查看集群情况
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mC0bXgiC-1680890079753)(image\62.png)]