Elasticsearch 集群
目录
- 1. 物理设计
-
- 1.1 节点和分片
- 1.2 主分片和副本分片
- 1.3 集群扩展
- 1.4 分布式索引和搜索
-
- 1.4.1 索引文档时
- 1.4.2 搜索索引时
- 2. 向集群中加入节点
-
- 2.1 单机集群(伪集群)
- 2.2 新增节点上的分片是如何运作
- 2.3 发现其他 ES 节点
- 2.4 选举主节点
- 3. 删除集群中的节点
-
- 3.1 停用节点
- 3.2 扩展策略
-
- 3.2.1 过度分片
- 3.2.2 将数据切分为索引和分片
- 4. 检查集群的健康状态
-
- 4.1 常用
- 4.2 使用_cat API
- 5. 路由
-
- 5.1 为什么使用路由
- 5.2 配置路由
Elasticsearch 1: 基本原理和概念
Elasticsearch 2: 管理索引和文档
Elasticsearch 3: 数据检索和分析
Elasticsearch 4: 相关性检索和组合查询
Elasticsearch 5: 聚集查询
Elasticsearch 6: 索引别名
Elasticsearch 集群
SpringBoot 整合 Elasticsearch
1. 物理设计
1.1 节点和分片
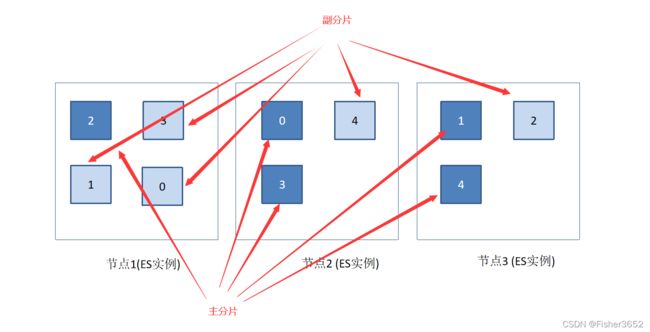
- Elasticsearch 创建索引时,默认情况下,每个索引由 5 个主要分片组成,而每份主要分片又有一个副本, 一共 10 份分片。副本分片对于可靠性和搜索性能很有益处。技术上而言,一份分片是一个目录中的文件,Lucene 用这些文件存储索引数据。分片也是 Elasticsearch 将数据从一个节点迁移到另一个节点的最小单位。
- 一个节点是一个 Elasticsearch 的实例。在服务器上启动 Elasticsearch 之后, 你就拥有了一个节点。如果在另一台服务器上启动 Elasticsearch, 这就是另一个节点。甚至可以通过启动多个 Elasticsearch 进程,在同一台服务器上拥有多个节点。
-
多个节点可以加入同一个集群。在多节点的集群上,同样的数据可以在多台服务器上传播。这有助于性能,因为 Elasticsearch 有了更多的资源;这同样有助于稳定性,如果每份分片至少有 1 个副本分片,那么任何一个节点都可以宕机, 而 Elasticsearch 依然可以进行服务,并返回所有数据。
-
对于使用 Elasticsearch 的应用程序,集群中有 1 个还是多个节点都是透明的。 默认情况下,可以连接集群中的任一节点并访问完整的数据集,就好像集群只有单独的一个节点。
-
尽管集群对于性能和稳定性都有好处,但它也有缺点:必须确定节点之间能够足够快速地通信,并且不会产生脑裂。
-
一份分片是 Lucene 的索引:一个包含倒排索引的文件目录。倒排索引的结构使得 Elasticsearch 在不扫描所有文档的情况下,就能告诉你哪些文档包含特定的词条 (单词) 。
-
Elasticsearch 索引被分解为多块分片。一份分片是一个 Lucene 的索引,所以 一个 Elasticsearch 的索引由多个 Lucene 的索引组成。
-
一个分片是一个 Lucene 索引(一个倒排索引)。它默认存储原始文档的内容,再加上一些额外的信息,如词条字典和词频,这些都能帮助到搜索。
-
词条字典将每个词条和包含该词条的文档映射起来。搜索的时候,Elastisearch 没有必要为了某个词条扫描所有的文档,而是根据这个字典快速地识别匹配的文档。
-
词频使得 Elasticsearch 可以快速地获取某篇文档中某个词条出现的次数。这对于计算结果的相关性得分非常重要。例如,如果搜索“denver",包含多个 “denver” 的文档通常更为相关。Elasticsearch 将给它们更高的得分,让它们出现在结果列表的更前面。
-
ES 中的节点类型:
-
Master-eligible nodes 与 Master node
每个节点启动后,默认就是一个 Master eligible 节点,可以通过设置 node.master:false 来改变,Master-eligible 节点可以参加选主流程,成为 Master 节点,每个节点都保存了集群的状态,但只有 Master 节点才能修改集群的状态信 息,主节点主要负责集群方面的轻量级的动作,比如:创建或删除索引,跟踪集 群中的节点,决定分片分配到哪一个节点,在集群再平衡的过程中,如何在节点间移动数据等。 -
Data Node
可以保存数据的节点,叫做 Data Node。负责保存分片数据。在数据扩展上起到了至关重要的作用,每个节点启动后,默认就是一个 Data Node 节点,可以通过设置 node.data:false 来改变。 -
Ingest Node
可以在文档建立索引之前设置一些 ingest pipeline 的预处理逻辑,来丰富和转换文档。每个节点默认启动就是 Ingest Node,可用通过 node.ingest = false 来禁用。 -
Coordinating Node
Coordinating Node 负责接收 Client 的请求,将请求分发到合适的节点,最终把 结果汇集到一起,每个节点默认都起到了 Coordinating Node 的职责,当然如果 把 master、Data、Ingest 全部禁用,那这个节点就仅是 Coordinating Node 节点了。 -
Machine Learning Node
用于机器学习处理的节点
1.2 主分片和副本分片
- 分片可以是主分片,也可以是副本分片,其中副本分片是主分片的完整副本, 副本分片可以用于搜索,或者是在原有主分片丢失后成为新的主分片。主分片是权威数据,写过程先写主分片,成功后再写副分片。
- Elasticsearch 索引由一个或多个主分片以及零个或多个副本分片构成。副本分片可以在运行的时候进行添加和移除,而主分片不可以。
- 可以在任何时候改变每个分片的副本分片的数量,因为副本分片总是可以被创建和移除。这并不适用于索引划分为主分片的数量,在创建索引之前,你必须决定主分片的数量。过少的分片将限制可扩展性,但是过多的分片会影响性能。默认设置主分片的数量是 5 份。
- 索引主分片的设置:
put test1
{
"settings": {
"index.number_of_shards": 3,
"index.codec": "best_compression"
}
}
- 索引副本分片的设置:
put test1/_settings
{
"index.number_of_replicas": 2
}
1.3 集群扩展
- 最简单的 Elasticsearch 集群只有一个节点: 一台机器运行着一个 Elasticsearch 进程。安装并启动 Elasticsearch 之后,就已经建立了一个拥有单节点的集群。随着越来越多的节点被添加到同一个集群中,现有的分片将在所有的节点中自动进行负载均衡。因此,那些分片上的索引和搜索请求都可以从额外增加的节点中获益。以这种方式进行扩展(在节点中加入更多节点)被称为水平扩展。此方式增加更多节点,然后请求被分发到这些节点上,工作负载就被分摊了。
- 水平扩展的另一个替代方案是垂直扩展,这种方式为 Elasticsearch 的节点增加更多硬件资源,可能是为虚拟机分配更多处理器,或是为物理机增加更多的内存。尽管垂直扩展几乎每次都能提升性能,它并非总是可行的或经济的。
1.4 分布式索引和搜索
- 多个节点的多个分片上如何进行索引和搜索
1.4.1 索引文档时
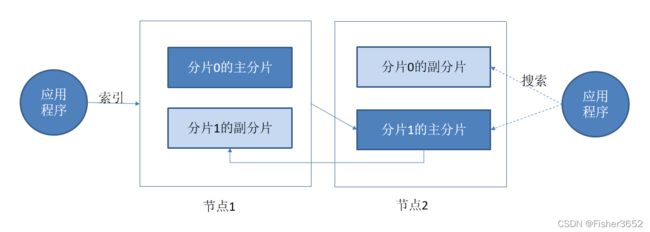
- 默认情况下,当索引一篇文档的时候,系统首先根据文档 ID 的散列值选择一个主分片,并将文档发送到该主分片。这份主分片可能位于另一个节点,不过对于应用程序这一点是透明的。
- 默认地,文档在分片中均匀分布:对于每篇文档,分片是通过其 ID 字符串的散列决定的。每份分片拥有相同的散列范围,接收新文档的机会均等。
- 一旦目标主分片确定,接受请求的节点将文档转发到该主分片所在的节点。 随后,索引操作在该主分片的所有副本分片中进行。在所有可用副本分片完成文档的索引后,索引命令就会成功返回。
- 这使得副本分片和主分片之间保持数据的同步。数据同步使得副本分片可以服务于搜索请求,并在原有主分片无法访问时自动升级为主分片。
1.4.2 搜索索引时
- 当搜索一个索引时,Elasticsearch 需要在该索引的完整分片集合中进行查找。 这些分片可以是主分片,也可以是副本分片,原因是对应的主分片和副本分片通常包含一样的文档。Elasticsearch 在索引的主分片和副本分片中进行搜索请求的负载均衡,使得副本分片对于搜索性能和容错都有所帮助。
- 在搜索的时候,接受请求的节点将请求转发到一组包含所有数据的分片。 Elasticsearch 使用 round-robin 的轮询机制选择可用的分片(主分片或副本分片), 并将搜索请求转发过去,Elasticsearch 然后从这些分片收集结果,将其聚集为单 一的回复,然后将回复返回给客户端应用程序。在默认情况下,搜索请求通过 round-robin 轮询机制选中主分片和副本分片。
2. 向集群中加入节点
2.1 单机集群(伪集群)
- 创建 Elasticsearch 集群的第一步, 是为单个节点加入另一个节点(或多个节点),组成节点的集群。
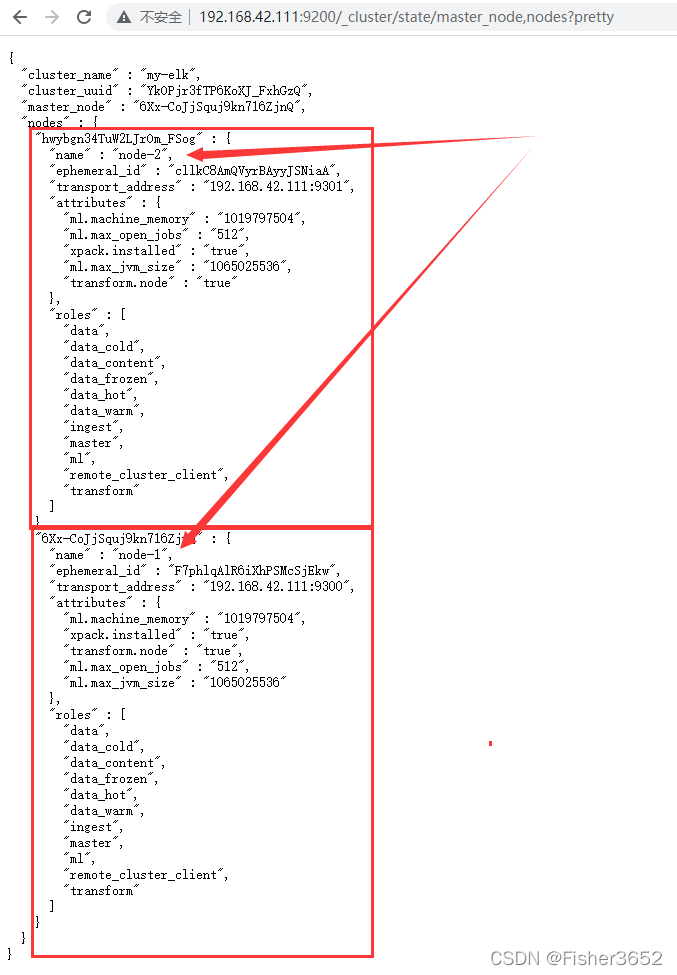
- 没有加入第二个节点前:
http://192.168.42.111:9200/_cluster/state/master_node,nodes?pretty
单机版安装参考Elasticsearch安装与配置
- 如何加入第二个节点:
1、解压缩压缩包 elasticsearch-7.14.0-linux-x86_64.tar.gz 到另外一个目录, 比如 elasticsearch-2,并且保证这个 es 中不包含任何数据;
2、修改配置文件
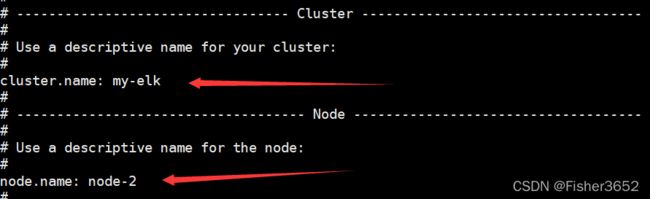
#将 cluster.name 改为和第一个节点一样
cluster.name: my-elk
#给第二个节点配置独立的名字
node.name: node-2
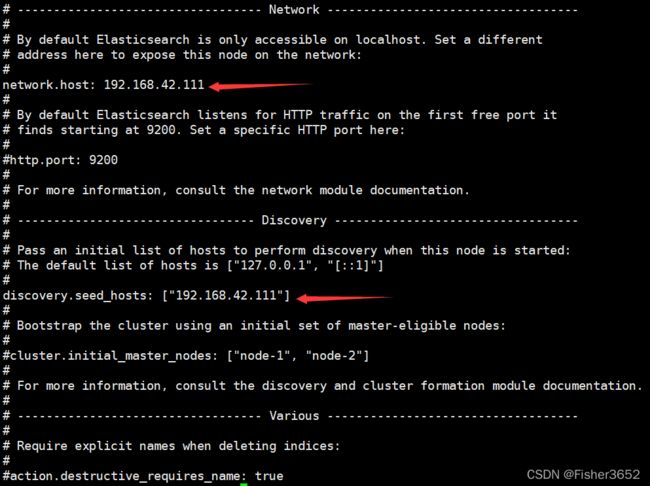
#network.host 改为本机地址
network.host: 192.168.42.111
#将 discovery.seed_hosts 改为本机地址
discovery.seed_hosts: ["192.168.42.111"]
- 如果第一个节点有插件,则也需要安装同样的插件。然后启动第二个节点即可。
- 现在有了第二个 Elasticsearch 节点加入了集群,可以再次
http://192.168.42.111:9200/_cluster/state/master_node,nodes?pretty
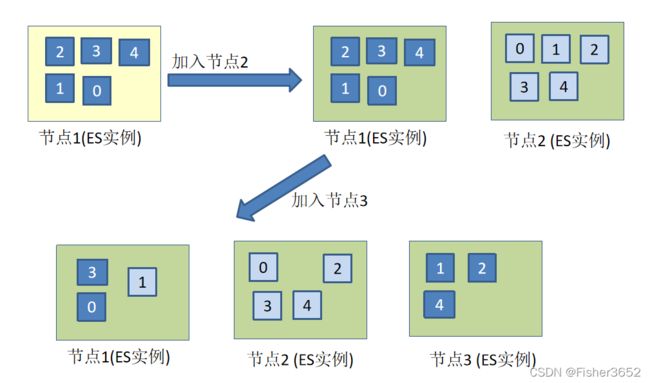
2.2 新增节点上的分片是如何运作
-
向集群增加一个节点前后,索引发生了些什么。在左端,索引的主分片全部分配到节点 Node1,而副本分片分配没有地方分配。在这种状态下,集群是黄色的,因为所有的主分片有了安家之处,但是副本分片还没有。
-
一旦第二个节点加入,尚未分配的副本分片就会分配到新的节点 Node2,这使得集群变为了绿色的状态。
-
当另一个节点加入的时候,Elasticsearch 会自动地尝试将分片在所有节点上进行均匀分配。
-
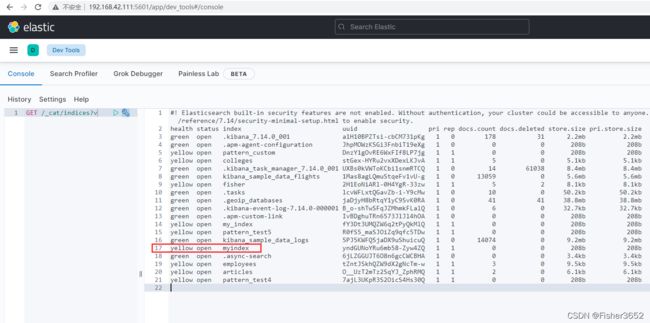
可以看到集群中有2个节点后,所有的索引都显示green
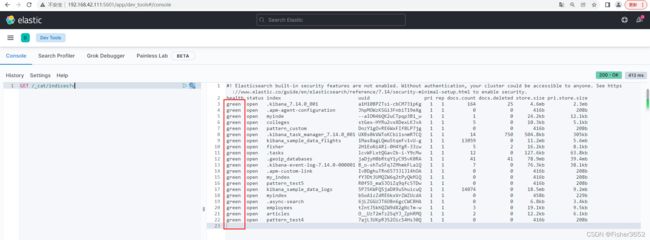
- 而单机版时,自己创建的索引显示yellow
- 如果更多的节点加入集群,Elasticsearch 将试图在所有的节点上均匀地配置分片数量,这样每个新加入的节点都能够通过部分数据(以分片的形式)来分担负载。
- 将节点加入 Elasticsearch 集群带来了大量的好处,主要的收益是高可用性和提升的性能。当副本分片是激活状态时(默认情况下是激活的),如果无法找到主分片, Elasticsearch 会自动地将一个对应的副本分片升级为主分片。这样,即使失去了索引主分片所在的节点,仍然可以访问副本分片上的数据。数据分布在多个节点上同样提升了性能,原因是主分片和副本分片都可以处理搜索和获取结果的请求。如此扩展还为整体集群增加了更多的内存,所以如果过于消耗内存的搜索和聚集运行了太长时间或致使集群耗尽了内存,那么加入更多的节点总是一个处 理更多更复杂操作的便捷方式。
2.3 发现其他 ES 节点
-
集群的第二个节点是如何发现第一个节点、并自动地加入集群的,或者在集群中有更多的节点的情况下,如何知道?
-
Elasticsearch 7.0 中引入的新集群协调子系统来处理这些事,采用的是单播机制,这种机制需要已知节点的列表来进行连接。
-
单播发现( unicast discovery )让 Elasticsearch 连接一系列的主机,并试图发现更多关于集群的信息。使用单播时,我们告诉 Elasticsearch 集群中其他节点的 IP 地址以及(可选的)端口或端口范围。
-
在 elasticsearch.yml 中通过 discovery.seed_hosts 配置种子地址列表,这样每个节点在启动时发现和加入集群的步骤就是:
1、去连接种子地址列表中的主机,如果发现某一个 Node 是 Master Eligible Node,那么该 Master Eligible Node 会共享它知道的 Master Eligible Node,这些共享的 Master Eligible Node 也会作为种子地址的一部分继续去试探;
2、直到找到某一个 seed addresss 对应的是 Master Node 为止;
3、如果第二步没有找到任何满足条件的 Node,ES 会默认每隔 1 秒后去重新尝试寻找,默认为 1 秒
4、重复第三步操作直到找到满足条件为止,也就是直到最终发现集群中的主节点,会发出一个加入请求给主节点
5、获得整个集群的状态信息。 -
为什么实例需要知道集群状态信息?例如,搜索必须被路由到所有正确的分片,以确保搜索结果是准确的。在索引或删除某些文档时,必须更新每个副本。 每个客户端请求都必须从接收它的节点转发到能够处理它的节点。每个节点都了解集群的概况,这样它们就可以执行搜索、索引和其他协调活动。
-
discovery.seed_hosts 中的节点地址列表,可以包括集群中部分或者全部集群节点,但是建议无论怎样都应该包含集群中 Master-eligible nodes 节点的部分或者全部。
2.4 选举主节点
- 一旦集群中的节点发现了彼此,它们会协商谁将成为主节点。一个集群有一个稳定的主节点是非常重要的,主节点是唯一一个能够更新集群状态的节点。主节点一次处理一个集群状态更新,应用所需的更改并将更新的集群状态发布到集群中的所有其他节点。
- Elasticsearch 认为所有的节点都有资格成为主节点,除非某个节点的 node.master 选项设置为 false,而 node.master 在不做配置的情况下,缺省为 true。
- 如果完全使用默认配置启动新安装的 Elasticsearch 节点,它们会自动查找在同一主机上运行的其他节点,并在几秒钟内形成集群。在生产环境或其他分布式环境中还不够健壮。现在还存在一些风险:节点可能无法及时发现彼此,可能会形成两个或多个独立的集群。从 Elasticsearch 7.0 开始,如果你想要启动一个全新的集群,并且集群在多台主机上都有节点,那么你必须指定该集群在第一次选举中应该使用的一组符合主节点条件的节点作为选举配置。这就是所谓的集群引导,也可以称为集群自举,只在首次形成集群时才需要。
- cluster.initial_master_nodes 这个参数就是用来设置一系列符合主节点条件的节点的主机名或 IP 地址来进行集群自举。集群形成后,不再需要此设置,并且会忽略它,也就是说,这个属性就只是在集群首次启动时有用。
- 在向集群添加新的符合主节点条件的节点时不再需要任何特殊的仪式,只需配置新节点,让它们可以发现已有集群,并启动它们。当有新节点加入时,集群将会自动地调整选举配置。
- 在主节点被选举出来之后,它会建立内部的 ping 机制来确保每个节点在集群中保持活跃和健康,这被称为错误识别( fault detection), 有两个故障检测进程在集群的生命周期中一直运行。一个是主节点的,ping 集群中所有的其他节点, 检查他们是否活着。另一种是每个节点都 ping 主节点,确认主节点是否仍在运行或者是否需要重新启动选举程序。
- 在 Elasticsearch7 以前的版本中,为了预防集群产生脑裂( split brain)的问题, Elasticsearch 6.x 及之前的版本使用了一个叫作 Zen Discovery 的集群协调子系统。往往会将 discovery.zen.minimum_master_nodes 设置为集群节点数除以 2 再加上 1。例如,3 个节点的集群 discovery.zen.minimum_master_nodes 要设置为 2,而对于 14 个节点的集群,最好将其设置为 8。
- 在 Elasticsearch 7 以后里重新设计并重建了的集群协调子系统,移除 minimum_master_nodes 参数,转而由集群自主控制。
- 什么是 Elasticsearch 的脑裂?
脑裂这个词描述了这样的场景:(通常是在重负荷或网络存在问题的情况 下)Elasticsearch 集群中一个或多个节点失去了和主节点的通信,开始选举新的主 节点,并且继续处理请求。这个时候,可能有两个不同的 Elasticsearch 集群相互独立地运行着,这就是“脑裂”一词的由来,因为单一的集群已经分裂成了两个不同的部分,和左右大脑类似。为了防止这种情况的发生,Elasticsearch 7 以前版本你需要根据集群节点的数量来设置 discovery. zen.minimum_master_nodes。 如果节点的数量不变,将其设置为集群节点的总数;否则将节点数除以 2 并加 1 是一个不错的选择,因为这就意味着如果一个或多个节点失去了和其他节点的通信, 它们无法选举新的主节点来形成新集群,因为对于它们不能获得所需的节点(可成为主节点的节点)数量(超过一半)。
3. 删除集群中的节点
- 假设节点 1 宕机了,那么在节点 1 的 3 个分片怎么办?
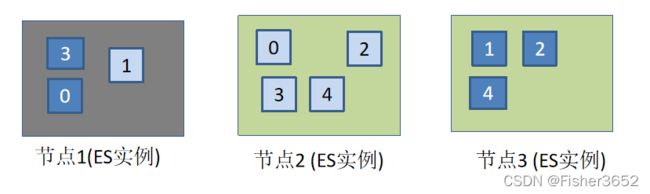
- Elasticsearch 所做的第 1 件事情是自动地将节点 2 上的 0 和 3 副本分片转为主分片,这是由于索引操作会首先更新主分片,所以 Elasticsearch 要尽力使索引的主 分片正常运作。Elasticsearch 可以选择任一个副本分片并将其转变为主分片。只是在本例中每个主分片仅有一个副本分片供选择,就是节点 Node2 上的副本分片。
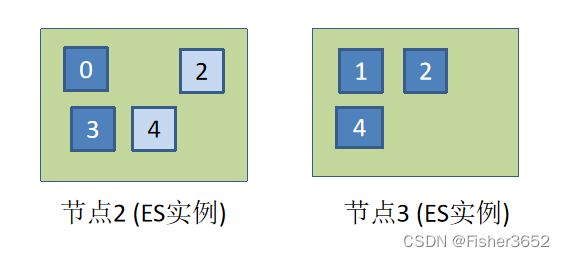
- 副本分片变为主分片之后,集群就会变为黄色的状态,这意味着某些副本分片尚未分配到某个节点。Elasticsearch 下一步需要创建更多的副本分片来保持索引的高可用性。由于所有的主分片现在都是可用的,节点 2 上 0 和 3 主分片的数据会复制到节点 3 上作为副本分片,而节点 3 上 1 主分片的数据会复制到节点 2。
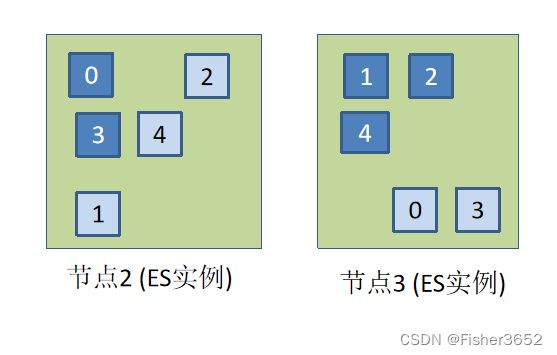
- 一旦副本分片被重新创建,并用于弥补损失的节点,那么集群将重新回归绿色的状态,全部的主分片及其副本分片都分配到了某个节点。在这个时间段内,整个集群都是可用于搜索和索引的,因为实际上没有丢失数据。
- 如果失去的节点多于 1 个,或者某个没有副本的主分片丢失了,那么集群就会变为红色的状态,这意味着某些数据永远地丢失了,你需要让集群重连拥有丟失数据的节点,或者对丢失的数据重新建立索引。
- 就副本分片的数量而言,你需要理解自己愿意承担多少风险,这一点非常重要。有 1 份副本分片意味着集群可以缺失 1 个节点而不丢失数据。如果有 2 个副本分片,可以缺失 2 个节点而不丢失数据,以此类推。所以,确保你选择了合适的副本数量来备份你的索引。
3.1 停用节点
- 当节点宕机时,让 Elasticsearch 自动地创建新副本分片是个很好的选择。可是,当集群进行例行维护的时候,如果希望关闭某个包含数据的节点,而同时不让集群进人黄色的状态。可以通过杀掉 Java 进程来停止节点,然后让 Elasticsearch 将数据恢复到其他节点,但是如果你的索引没有副本分片的时候怎么办?这意味着,如果不预先将数据转移,关闭节点就会让你丢失数据!
- Elasticsearch 有一种停用节点( decommission)的方式,告诉集群不要再分配任何分片到某个或 1 组节点上。在 3 个节点的情况中,假设节点 1、节点 2 和节点 3 的 IP 地址分别是 192.168.1.10、192.168.1.11 和 192.168.1.12。 如果你想关闭节点 1 的同时保持集群为绿色状态,可以先停用节点,这个操作会将待停用节点上的所有分片转移到集群中的其他节点。系统通过集群设置的临时修改,来为你实现节点的停用
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._name": "node-1"
}
}
- 或者
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._ip": "192.168.1.10"
}
}
- 一旦运行了这个命令,Elaticsearch 将待停用节点上的全部分片开始转移到集群中的其他节点上。
- 该过程可以重复,每次停止一个你想关闭的节点,或者也可以使用一个通过逗号分隔的 IP 地址列表,一次停止多个节点。请记住,集群中的其他节点必须有足够的磁盘和内存来处理分片的分配,所以在停止多个节点之前,做出相应的计划来确保你有足够的资源。
3.2 扩展策略
- Elasticsearch 的使用方式各有各的不同,所以需要根据如何索引和搜索数据, 为集群选择最佳的配置。通常来说,规划生产环境的 Elasticsearch 集群至少需要考虑:过度分片、将数据切分为索引和分片。
3.2.1 过度分片
- 过度分片( over-sharding )是指你有意地为索引创建大量分片,用于未来增加节点的过程。假设我们已经创建了拥有单一分片、 无副本分片的索引。但是,在增加了另外一个节点之后又会发生什么?
- 我们将得不到增加集群节点所带来的任何好处了。由于全部的索引和查询负载仍然是由拥有单一分片的节点所处理,所以即使增加了一个节点你也无法进行扩展。
- 因为分片是 Elasticsearch 所能移动的最小单位,所以确保你至少拥有和集群节点一样多的主分片总是个好主意。如果现在有一个 5 个节点、11 个主分片的集群,那么当你需要加入更多的节点来处理额外的请求时,就有成长的空间。使用同样的例子,如果你突然需要多于 11 个的节点,就不能在所有的节点中分发主分片,因为节点的数量将会超出分片的数量。
- 怎么办?创建一个有 10000 个主分片的索引? 一开始的时候,这看上去是个好主意,但是 Elasticsearch 管理每个分片都隐含着额外的开销。每个分片都是完整的 Lucene 索引,它需要为索引的每个分段创建一些文件描述符,增加相应的内存开销。如果索引有过多的活跃分片,可能会占用了本来支撑性能的内存,或者触及机器文件描述符或内存的极限。对数据的压缩也会有影响。
- 值得注意的是,没有对所有案例适用的完美分片索引比例。Elasticsearch 选择的默认设置是 5 个分片,对于普通的用例是不错的主意,但是考虑你的规划在将来是如何增长(或缩减)所建分片的数量,这总是很件重要的事情。
- 一旦包含某些数量分片的索引被创建,其主分片的数量永远是不能改变的。
- Elasticsearch 索引能处理多大的数据:
单一索引的极限取决于存储索引的机器之类型、你准备如何处理数据以及索引备份了多少副本。 - 如何评估 ES 中的数据量是否合适呢?有几个参考值
1、ES 官方推荐分片的大小是 20G - 40G,最大不能超过 50G。
2、每个节点上可以存储的分片数量与可用的堆内存大小成正比关系,但是 Elasticsearch 并未强制规定固定限值。这里有一个很好的经验法则:确保对于节点上已配置的每个 GB,将分片数量保持在 20 以下。如果某个节点拥有 3GB 的堆内存,那最多可有 60 个分片,那么有三个机器的集群,ES 可用总堆内存是 9GB,则最多是 180 个分片,注意这个数据是包含了主副分片的。但是在此限值范围内,设置的分片数量越少,效果就越好。
3、通常来说,一个 Lucene 索引(也就是一个 Elasticsearch 分片)不能处理多于 21 亿篇文档,或者多于 2740 亿的唯一词条, 但是在达到这个极限之前,你可能就已经没有足够的磁盘空间了。
举例:三个机器的集群,总内存是 9GB,准备 1 主 2 副,支持的总主分片数量最大不宜超过 60 个分片。
3.2.2 将数据切分为索引和分片
- 现在还没有方法让我们增加或者减少某个索引中的主分片数量,但是你总是可以对数据进行规划,让其横跨多个索引。这是另一种完全合理的切分数据的方式。
- 比如说以地理位置创建索引和分片,你可以为西藏索引创建 2 个主分片,而为上海索引创建 10 个主分片,或者可以将数据以日期来分段,为数据按年份创 建索引: 2020、 2021 和 2022 等。以这种方式将数据分段,对于搜索同样有所帮助,因为分段将恰当的数据放在恰当的位置。如果顾客只希望搜索 2021 年和 2022 年的活动或分组,你只需要搜索相应的索引,而不是整个数据集中检索。
- 使用索引进行规划的另一种方式是别名。别名( alias )就像指向某个索引或一组索引的指针。别名也允许你随时修改其所指向的索引。对于数据按照语义的方式来切分,这一点非常有用。你可以创建一个别名称为去年,指向 2021,当 2023 年 1 月 1 日到来,就可以将这个别名指向 2022 年的索引。
- 当索引基于日期的信息时(就像日志文件),这项技术是很常用的,如此一来数据就可以按照每月、每周、每日等日期来分段,而每次分段过时的时候,“当 前”的别名永远可用来指向应该被搜索的数据,而无须修改待搜索的索引之名称。 此外,别名拥有惊人的灵活性,而且几乎没有额外负载,所以值得尝试。
4. 检查集群的健康状态
4.1 常用
- 集群的健康 API 接口提供了一个方便但略有粗糙的概览,包括集群、索引和分片的整体健康状况。这通常是发现和诊断集群中常见问题的第一步。
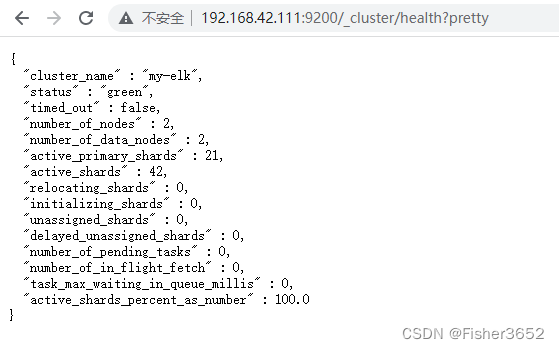
http://192.168.42.111:9200/_cluster/health?pretty从这个答复的表明信息,我们可以推断出很多关于集群整体健康状态的信息。
-
“cluster_name” : 集群名称
-
“status” :正常情况下,Elasticsearch 集群健康状态分为三种:
green 最健康得状态,说明所有的分片包括备份都可用; 这种情况 Elasticsearch 集群所有的主分片和副本分片都已分配, Elasticsearch 集群是 100% 可用的。
yellow 基本的分片可用,但是备份不可用(或者是没有备份); 这种情况 Elasticsearch 集群所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上 被弱化。如果更多的分片消失,你就会丢数据了。把 yellow 想象成一个需要及时调查的警告。
red 部分的分片可用,表明分片有一部分损坏。此时执行查询部分数据仍然可以查到,遇到这种情况,还是赶快解决比较好; 这种情况 Elasticsearch 集群至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。 -
“timed_out” : 是否有超时
-
“number_of_nodes” : 集群中的节点数量
-
“number_of_data_nodes” : 数据节点数
-
“active_primary_shards” : 指出你集群中的主分片数量
-
“active_shards” : 所有索引的_所有_分片的汇总值,即包括副本分片
-
“relocating_shards” : 大于 0 表示 Elasticsearch 正在集群内移动数据的分片,来提升负载均衡和故 障转移。这通常发生在添加新节点、重启失效的节点或者删除节点的时候,因此 出现了这种临时的现象
-
“initializing_shards” : 当用户刚刚创建一个新的索引或者重启一个节点的时候,这个数值会大于 0
-
“unassigned_shards” : 这个值大于 0 的最常见原因是有尚未分配的副本分片。在开发环境中,这个 问题很普遍,因为单节点的集群其索引默认有 5 个分片和 1 个副本分片。这种情 况下,由于无多余节点来分配副本分片,因此还有 5 个未分配的副本分片
-
“active_shards_percent_as_number” : 集群分片的可用性百分比,如果为 0 则表示不可用
-
集群健康 API 提供了更多的细粒度的操作,允许用户进一步地诊断问题。在这个例子中,可以通过添加 level 参数,深入了解哪些索引受到了分片未配置的影响,比如:
http://192.168.42.111:9200/_cluster/health?level=indices&pretty=true

- 除此之外与集群相关的 API 还有:
查看集群健康状态接口(_cluster/health)
查看集群状况接口(_cluster/state)
查看集群统计信息接口(_cluster/stats)
查看集群挂起的任务接口(_cluster/pending_tasks)
集群重新路由操作(_cluster/reroute)
更新集群设置(_cluster/settings)
节点状态(_nodes/stats)
节点信息(_nodes)
节点的热线程(_nodes/hot_threads)
关闭节点(_nodes/_master/_shutdown)
4.2 使用_cat API
- 有的时候可读性很重要,我们就需要更方便的_cat API 接口。这个_cat API 提供了很有帮助的诊断和调试工具,将数据以更好的可读性打印出来。
- _cat API 有很多特性,它们对于调试集群的各个方面都是很有帮助的。你可以运行
http://192.168.42.111:9200/_cat来查看所支持的_cat API 接口的完整清单。

allocation-展示分配到每个节点的分片数量。
count-统计整个集群或索引中文档的数量。 如:GET _cat/count/employees?v
health–展示集群的健康状态。
indices-展示现有索引的信息。
master—显示目前被选为主节点的节点。
nodes—显示集群中所有节点的不同信息。
recovery–显示集群中正在进行的分片恢复状态。
shards-展示集群中分片的数量、大小和名字。
plugins—展示已安装插件的信息。
5. 路由
- 知道文档是如何以通过分片形式来定位的。这个过程被称为路由 ( routing )文档。
- 当 Elasticsearch 散列文档的 ID 时就会发生文档的路由,来决定文档应该索引到哪个分片中,这可以由你指定也可以让 Elasticsearch 生成。
- 索引的时候,Elasticsearch 也允许你手动地指定文档的路由,使用父子关系实际上就是这种操作,因为子文档必须要和父文档在同一个分片。
5.1 为什么使用路由
- 假设你有一个 100 个分片的索引。当一个请求在集群上执行时会发生什么?
- 这个搜索的请求会被发送到一个节点
- 接收到这个请求的节点,将这个查询转到这个索引的每个分片上(可能是主分片,也可能是副本分片)
- 每个分片执行这个搜索查询并返回结果
- 结果在通道节点上合并、排序并返回给用户
- 因为默认情况下,Elasticsearch 使用文档的 ID(类似于关系数据库中的自增 ID),如果插入数据量比较大,文档会平均的分布于所有的分片上,这导致了 Elasticsearch 不能确定文档的位置,所以它必须将这个请求转到所有的 N 个分片上去执行,这种操作会给集群带来负担,增大了网络的开销;那么如何确定请求在哪个分片上执行呢?Elasticsearch 提供了一个 API 接口, 告诉我们一个搜索请求在哪些节点和分片上执行。
- _search_shards API
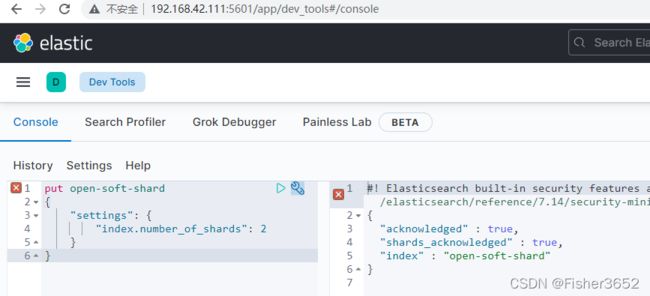
- 比如我们创建一个两分片的索引:
put open-soft-shard
{
"settings": {
"index.number_of_shards": 2
}
}
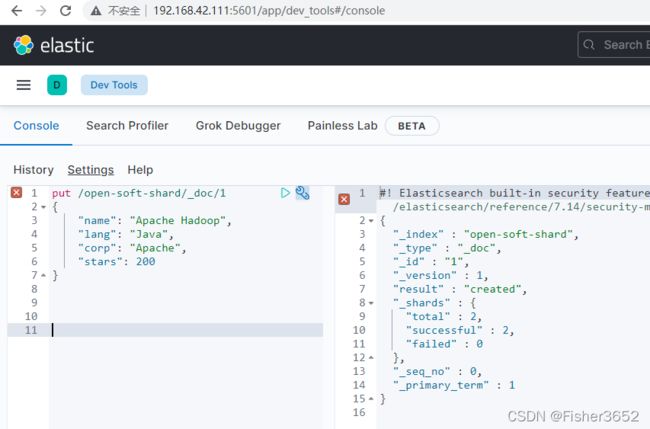
- 并放入数据:
put /open-soft-shard/_doc/1
{
"name": "Apache Hadoop",
"lang": "Java",
"corp": "Apache",
"stars": 200
}
- 多插入几条
put /open-soft-shard/_doc/2
{
"name": [
"Apache Activemq",
"Activemq Artemis"
],
"lang": "Java",
"corp": "Apache",
"stars": [
500,
200
]
}
put /open-soft-shard/_doc/3
{
"name": [
"Apache Kafka"
],
"lang": "Java",
"corp": "Apache",
"stars": [
500,
400
]
}
put /open-soft-shard/_doc/object
{
"name": [
"Apache ShardingSphere"
],
"lang": "Java",
"corp": "JingDong",
"stars": 400,
"address": {
"city": "BeiJing",
"country": "亦庄"
}
}
- 使用搜索分片( search shards ) 的 API 接口来查看请求将在哪些分片上执行。可以看到,会搜索全部的两个分片。
{
"nodes" : {
"hwybgn34TuW2LJrOm_FSog" : {
"name" : "node-2",
"ephemeral_id" : "cllkC8AmQVyrBAyyJSNiaA",
"transport_address" : "192.168.42.111:9301",
"attributes" : {
"ml.machine_memory" : "1019797504",
"ml.max_open_jobs" : "512",
"xpack.installed" : "true",
"ml.max_jvm_size" : "1065025536",
"transform.node" : "true"
},
"roles" : [
"data",
"data_cold",
"data_content",
"data_frozen",
"data_hot",
"data_warm",
"ingest",
"master",
"ml",
"remote_cluster_client",
"transform"
]
},
"6Xx-CoJjSquj9kn716ZjnQ" : {
"name" : "node-1",
"ephemeral_id" : "F7phlqAlR6iXhPSMcSjEkw",
"transport_address" : "192.168.42.111:9300",
"attributes" : {
"ml.machine_memory" : "1019797504",
"xpack.installed" : "true",
"transform.node" : "true",
"ml.max_open_jobs" : "512",
"ml.max_jvm_size" : "1065025536"
},
"roles" : [
"data",
"data_cold",
"data_content",
"data_frozen",
"data_hot",
"data_warm",
"ingest",
"master",
"ml",
"remote_cluster_client",
"transform"
]
}
},
"indices" : {
"open-soft-shard" : { }
},
"shards" : [
[
{
"state" : "STARTED",
"primary" : false,
"node" : "6Xx-CoJjSquj9kn716ZjnQ",
"relocating_node" : null,
"shard" : 0,
"index" : "open-soft-shard",
"allocation_id" : {
"id" : "PFQxVNY4SLGplOqICMXJpQ"
}
},
{
"state" : "STARTED",
"primary" : true,
"node" : "hwybgn34TuW2LJrOm_FSog",
"relocating_node" : null,
"shard" : 0,
"index" : "open-soft-shard",
"allocation_id" : {
"id" : "Ucj_fOFATYqUOBlye3nOUA"
}
}
],
[
{
"state" : "STARTED",
"primary" : true,
"node" : "6Xx-CoJjSquj9kn716ZjnQ",
"relocating_node" : null,
"shard" : 1,
"index" : "open-soft-shard",
"allocation_id" : {
"id" : "9FsKkjcSQOOiWhKI4CDxuA"
}
},
{
"state" : "STARTED",
"primary" : false,
"node" : "hwybgn34TuW2LJrOm_FSog",
"relocating_node" : null,
"shard" : 1,
"index" : "open-soft-shard",
"allocation_id" : {
"id" : "5bznRFT0Sr2beunL_BEbFA"
}
}
]
]
}
- 当我们
GET /open-soft-shard/_search_shards?pretty&routing=1
- 即使在索引中只有两个分片,当指定路由值 1 的时候,只有分片 shard 0 会被 搜索。对于搜索需要查找的数据,有效地切除了一半的数据量!
#! Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See https://www.elastic.co/guide/en/elasticsearch/reference/7.14/security-minimal-setup.html to enable security.
{
"nodes" : {
"hwybgn34TuW2LJrOm_FSog" : {
"name" : "node-2",
"ephemeral_id" : "cllkC8AmQVyrBAyyJSNiaA",
"transport_address" : "192.168.42.111:9301",
"attributes" : {
"ml.machine_memory" : "1019797504",
"ml.max_open_jobs" : "512",
"xpack.installed" : "true",
"ml.max_jvm_size" : "1065025536",
"transform.node" : "true"
},
"roles" : [
"data",
"data_cold",
"data_content",
"data_frozen",
"data_hot",
"data_warm",
"ingest",
"master",
"ml",
"remote_cluster_client",
"transform"
]
},
"6Xx-CoJjSquj9kn716ZjnQ" : {
"name" : "node-1",
"ephemeral_id" : "F7phlqAlR6iXhPSMcSjEkw",
"transport_address" : "192.168.42.111:9300",
"attributes" : {
"ml.machine_memory" : "1019797504",
"xpack.installed" : "true",
"transform.node" : "true",
"ml.max_open_jobs" : "512",
"ml.max_jvm_size" : "1065025536"
},
"roles" : [
"data",
"data_cold",
"data_content",
"data_frozen",
"data_hot",
"data_warm",
"ingest",
"master",
"ml",
"remote_cluster_client",
"transform"
]
}
},
"indices" : {
"open-soft-shard" : { }
},
"shards" : [
[
{
"state" : "STARTED",
"primary" : false,
"node" : "6Xx-CoJjSquj9kn716ZjnQ",
"relocating_node" : null,
"shard" : 0,
"index" : "open-soft-shard",
"allocation_id" : {
"id" : "PFQxVNY4SLGplOqICMXJpQ"
}
},
{
"state" : "STARTED",
"primary" : true,
"node" : "hwybgn34TuW2LJrOm_FSog",
"relocating_node" : null,
"shard" : 0,
"index" : "open-soft-shard",
"allocation_id" : {
"id" : "Ucj_fOFATYqUOBlye3nOUA"
}
}
]
]
}
- 所以当处理拥有大量分片的索引时,路由会很有价值,当然对于 Elasticsearch 的常规使用它并不是必需的
5.2 配置路由
- 路由也可以不使用文档的 ID,而是定制的数值进行散列。通过指定 URL 中的 routing 查询参数,系统将使用这个值进行散列,而不是 ID。
PUT /employees/_doc/2?routing=rountkey
{
......
}
- 在这个例子中,rountkey 这个由我们自己输入的值决定文档属于哪个分片的散列值,而不是文档的 ID 值 2。
- 由上可知,自定义路由的方式非常简单,只需要在插入数据的时候指定路由的 key 即可。虽然使用简单,但有细节需要注意。
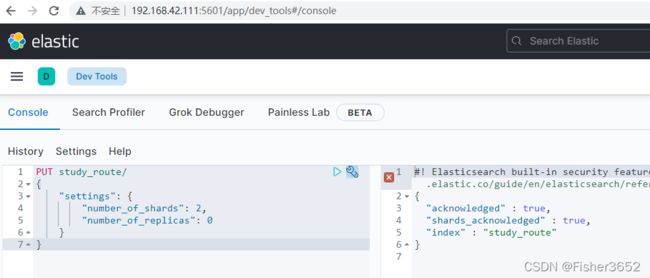
1、先创建一个名为 study_route 的索引,该索引有 2 个 shard,0 个副本
PUT study_route/
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 0
}
}
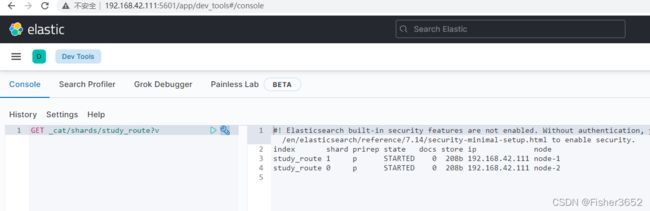
2、查看 shard
GET _cat/shards/study_route?v
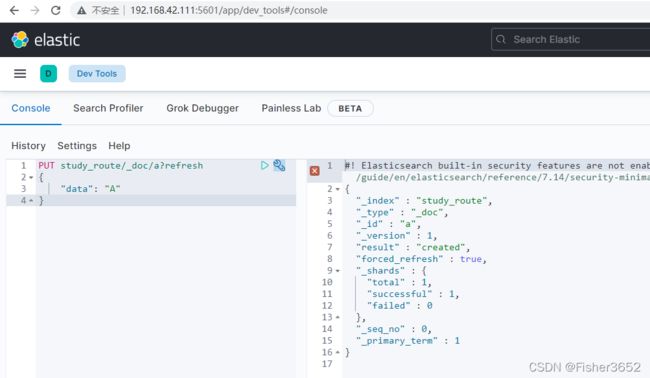
3、插入第 1 条数据
PUT study_route/_doc/a?refresh
{
"data": "A"
}
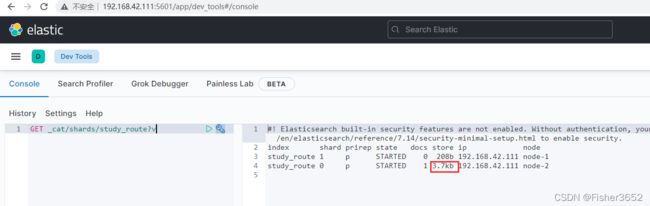
4、查看 shard
- 从208b变为3.7kb
GET _cat/shards/study_route?v
5、插入第 2 条数据
PUT study_route/_doc/b?refresh
{
"data": "B"
}
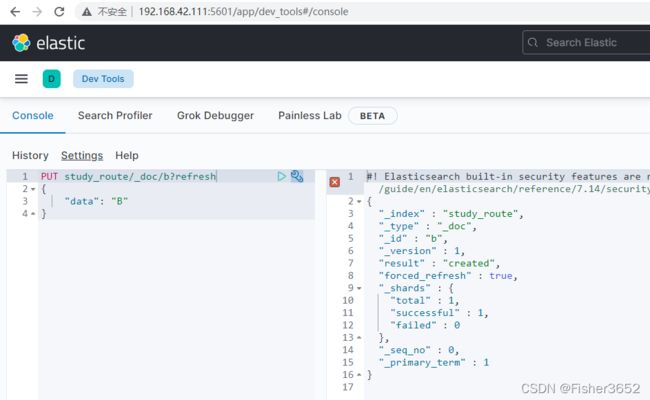
6、查看 shard
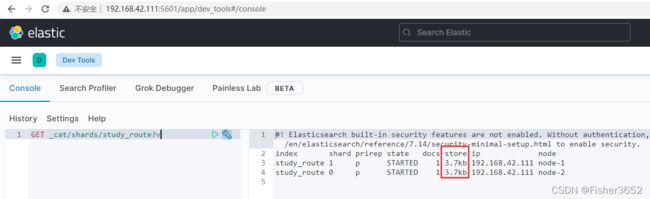
7、查看此时索引里面的数据
GET study_route/_search
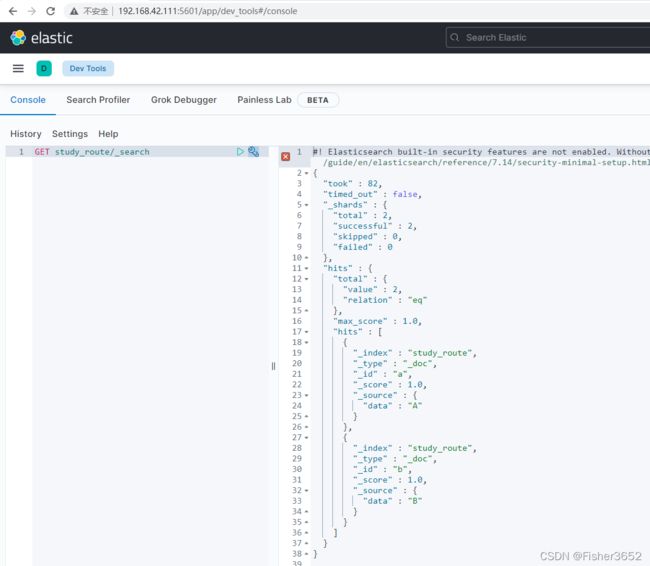
- 先创建了一个拥有 2 个 shard,0 个副本(为了方便观察)的索引 study_route 。创建完之后查看两个 shard 的信息,此时 shard 为空, 里面没有任何文档(docs 列为 0)。接着我们插入了两条数据,每次插完之后, 都检查 shard 的变化。通过对比可以发现 docid=a 的第一条数据写入了 0 号 shard, docid=b 的第二条数据写入了 1 号 shard。
- 接着,我们指定 routing,看看有什么变化。
8、插入第 3 条数据
PUT study_route/_doc/c?routing=key1&refresh
{
"data": "C"
}
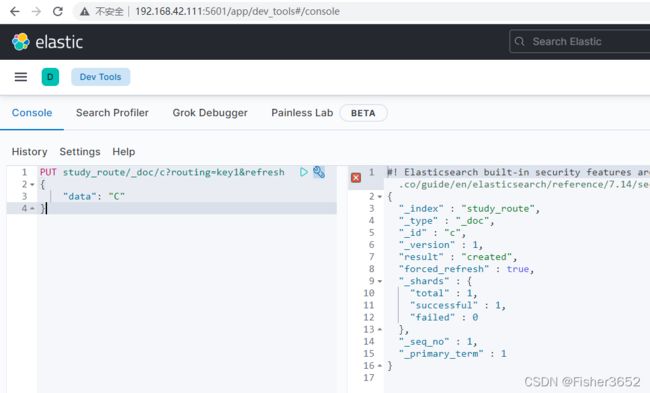
9、查看 shard
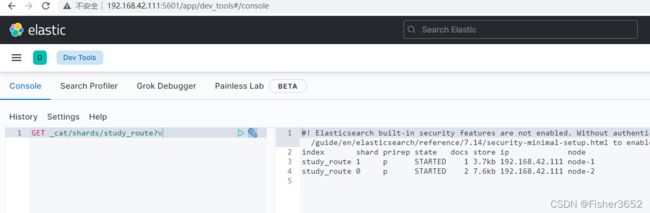
GET _cat/shards/study_route?v
10、查看索引数据
GET study_route/_search
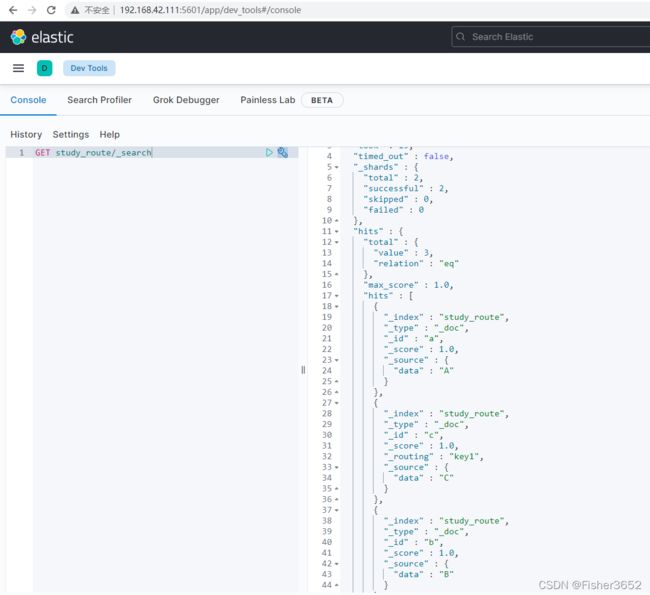
- 又插入了 1 条 docid=c 的新数据,但这次指定了路由,路由的值 是一个字符串"key1"。通过查看 shard 信息,能看出这条数据路由到了 0 号 shard。 也就是说用"key1"做路由时,文档会写入到 0 号 shard。
- 接着我们使用该路由再插入两条数据,但这两条数据的 docid 分别为之前使用过的 “a"和"b”,最终结果会是什么样?
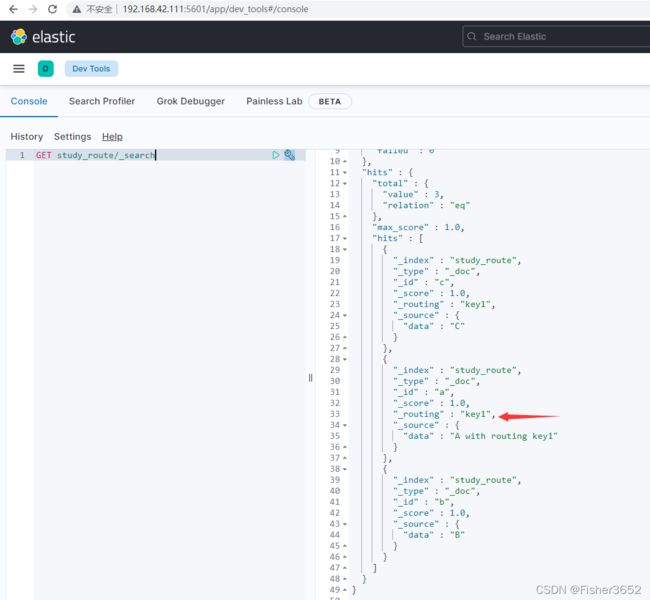
11、插入 docid=a 的数据,并指定 routing=key1
PUT study_route/_doc/a?routing=key1&refresh
{
"data": "A with routing key1"
}
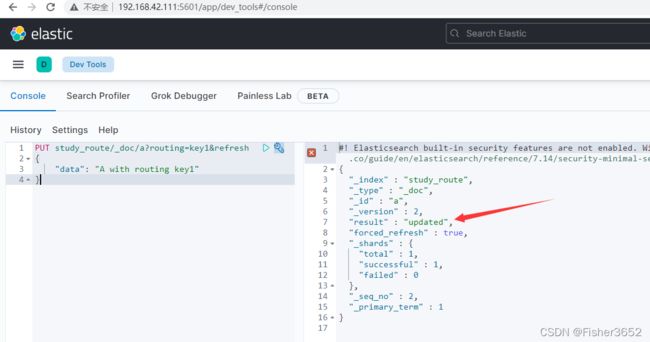
- es 的返回信息表明文档 a 是 updated
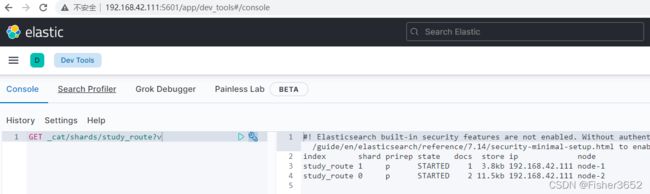
12、查看 shard
13、查询索引
14、插入 docid=b 的数据,使用 key1 作为路由字段的值
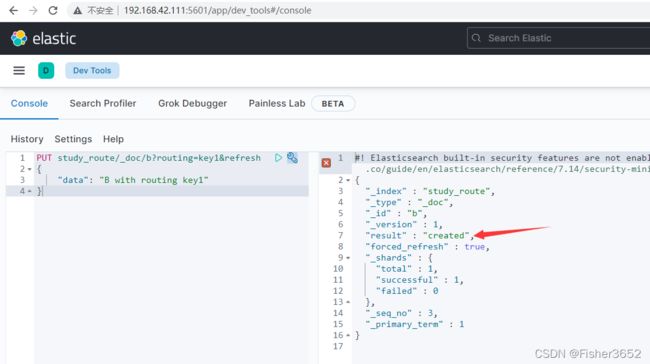
- es 返回的信息变成了 created
15、查看 shard 信息
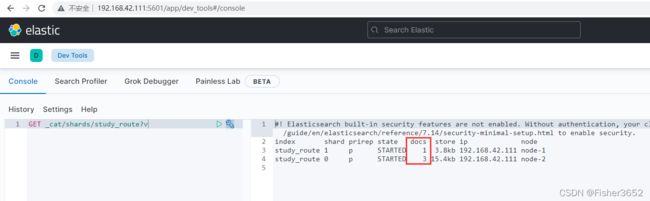
16、查询索引内容
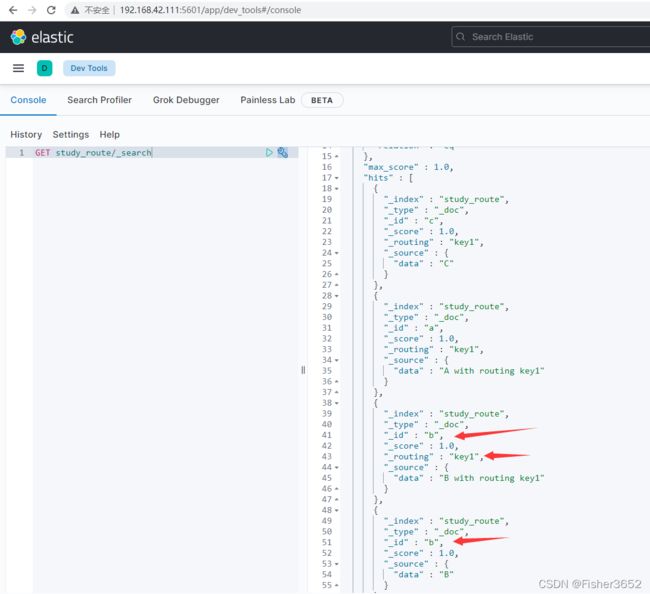
- 两个 id 为 b 的文档,其中一个比另一个多了一个字段"_routing"
- 和步骤 11 插入 docid=a 的那条数据相比,这次这个有些不同,我们来分析 一下。步骤 11 中插入 docid=a 时,es 返回的是 updated,也就是更新了步骤 2 中插入的 docid 为 a 的数据,步骤 12 和 13 中查询的结果也能看出,并没有新增 数据,route_test 中还是只有 3 条数据。
- 而步骤 14 插入 docid=b 的数据时,es 返回的是 created,也就是新增了一 条数据,而不是 updated 原来 docid 为 b 的数据,步骤 15 和 16 的确也能看出多了一条数据,现在有 4 条数据。而且从步骤 16 查询的结果来看,有两条 docid 为 b 的数据,但一个有 routing,一个没有。而且也能分析出有 routing 的在 0 号 shard 上面,没有的那个在 1 号 shard 上。
- 这个就是我们自定义 routing 后会导致的一个问题:docid 不再全局唯一。ES shard 的实质是 Lucene 的索引,所以其实每个 shard 都是一个功能完善的倒排索引。ES 能保证 docid 全局唯一是采用 docid 作为了路由,所以同样的 docid 肯定会路由到同一个 shard 上面,如果出现 docid 重复,就会 update 或者抛异常,从而保证了集群内 docid 唯一标识一个 doc。但如果我们换用其它值做 routing,那这个就保证不了了,如果用户还需要 docid 的全局唯一性,那只能自己保证了。 因为 docid 不再全局唯一,所以 doc 的增删改查 API 就可能产生问题,比如下面的查询:
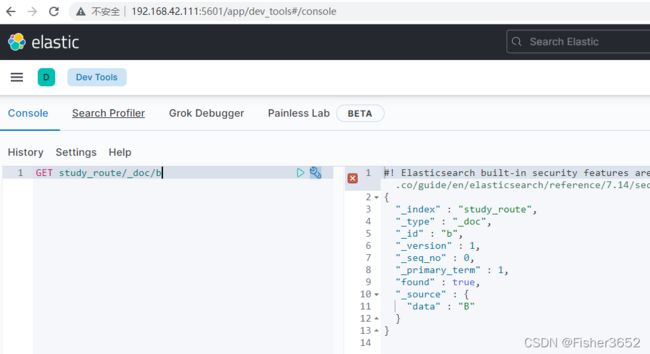
GET study_route/_doc/b
GET study_route/_doc/b?routing=key1
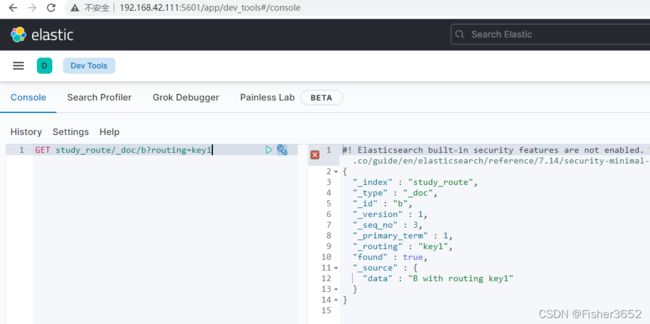
- 上面两个查询,虽然指定的 docid 都是 b,但返回的结果是不一样的。所以,如果自定义了 routing 字段的话,一般 doc 的增删改查接口都要加上 routing 参数以保证一致性。
- 为此,ES 在 mapping 中提供了一个选项,可以强制检查 doc 的增删改查接口是否加了 routing 参数,如果没有加,就会报错。设置方式如下:
PUT <索引名>
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 0
},
"mappings": {
"_routing": {
"required": true//设置为true,则强制检查;false则不检查,默认为false
}
}
}
- 比如:
PUT study_route1/
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 0
},
"mappings": {
"_routing": {
"required": true
}
}
}
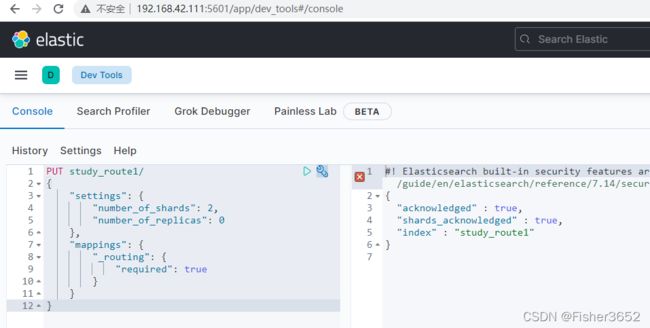
- 写入一条数据
PUT study_route1/_doc/b?routing=key1
{
"data": "b with routing"
}
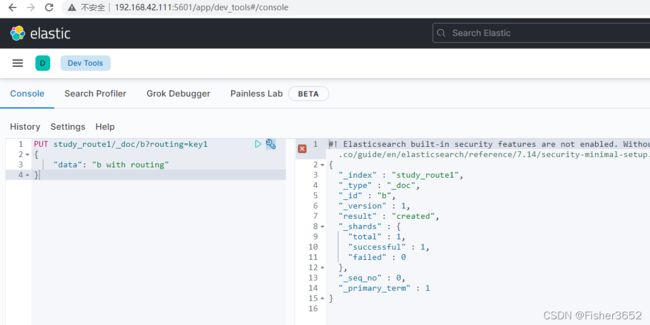
- 但是以下的增删改查都会抱错
GET study_route1/_doc/b
PUT study_route1/_doc/b
{
"data": "B"
}
DELETE study_route1/_doc/b
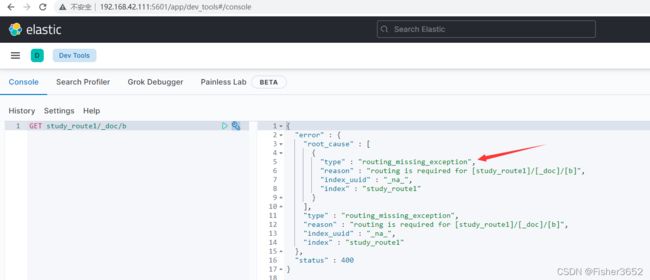
- 很多时候自定义路由是为了减少查询时扫描 shard 的个数,从而提高查询效率。默认查询接口会搜索所有的 shard,但也可以指定 routing 字段, 这样就只会查询 routing 计算出来的 shard,提高查询速度。
- 使用方式也非常简单,只需在查询语句上面指定 routing 即可,允许指定多 个:
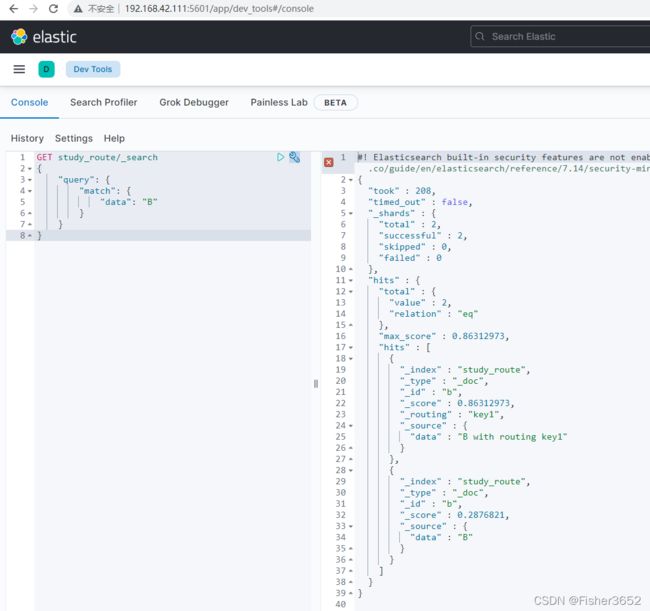
- 查询所有分区 GET study_route/
GET study_route/_search
{
"query": {
"match": {
"data": "B"
}
}
}
- 查询指定分区
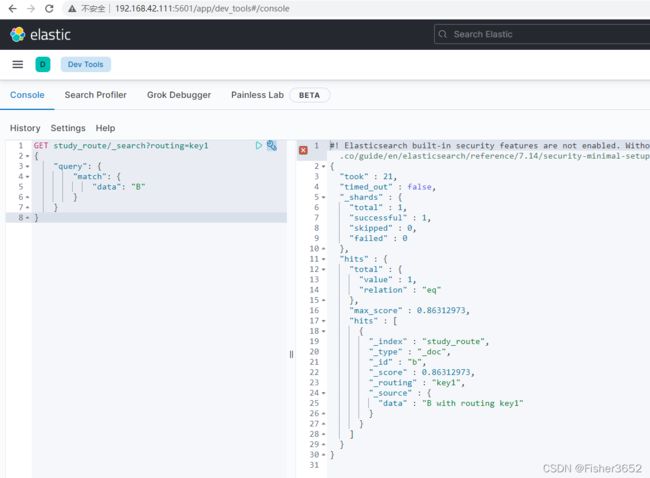
GET study_route/_search?routing=key1
{
"query": {
"match": {
"data": "B"
}
}
}