《手摸手带你学ClickHouse》之ReplacingMergeTree表引擎
本文同步发表于我的微信公众号,扫一扫文章底部的二维码或在微信搜索 chaodev 即可关注。
文章目录
-
-
- 1、基本使用
- 2、删除数据版本控制
-
推荐阅读:
《手摸手带你学ClickHouse》之安装部署
《手摸手带你学ClickHouse》之访问接口
《手摸手带你学ClickHouse》之导入导出数据
《手摸手带你学ClickHouse》之MergeTree系列表引擎
前面的文章详细介绍了ClickHouse单机的安装部署、ClickHouse监听端口、访问接口、设置允许其他ip访问、可视化的客户端、数据的导入导出以及MergeTree表引擎。本文主要内容为ClickHouse的另外一个表引擎 ReplacingMergeTree。
1、基本使用
ReplacingMergeTree这个引擎区别于MergeTree的是增加了 分区内删除重复数据(按ORDER BY排序键为基准,而不是主键) 的功能,注意是分区内。但是去重只在数据合并时,而合并是后台自动在未知时间内进行,因此不保证没有重复数据的出现。
建表如下:
create table tb_replacing_mergetree(
uid UInt8,
name String,
birthday Date,
city String
)engine = ReplacingMergeTree()
partition by city
primary key uid
order by (uid ,name);
这里使用city字段来进行分区,主键为uid,排序字段为uid和name
插入数据
insert into tb_replacing_mergetree values(1,'zhangsan',toDate(now()),'BJ'),
(1,'lisi',toDate(now()),'KM'),
(1,'wanger ','1996-01-01','BJ'),
(1,'mazi ','1996-01-01','KM'),
(1,'mazi ','2000-11-11','KM');
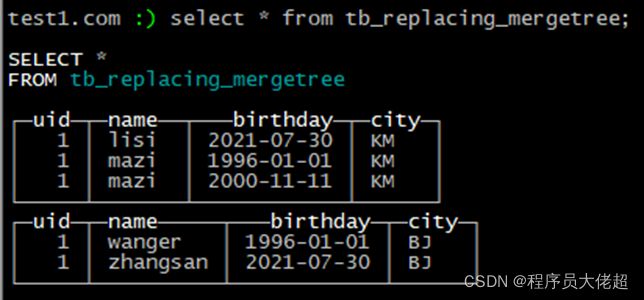
接下来进行合并操作
optimize table tb_replacing_mergetree final;
合并后数据如下:
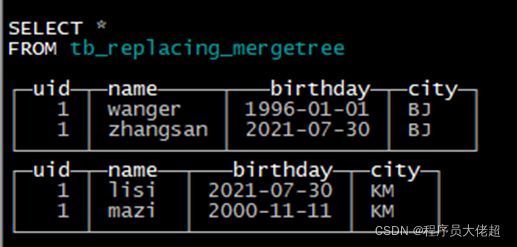
可以看到KM这个分区里uid和name重复的数据已经被合并。
2、删除数据版本控制
由于被删掉的数据默认按插入顺序来,保留的是最新插入的一条,这样就会有一个问题,可能老数据在新数据后插入,合并时就会删除那条新数据。
要解决这个问题,只需要在声明引擎时指定某个字段,就会默认保留该字段最大的那条数据。
例如:
create table tb_replacing_mergetree2(
uid UInt8,
name String,
age UInt8,
city String,
version UInt8
)engine = ReplacingMergeTree(version)
partition by city
primary key uid
order by (uid ,age);
insert into tb_replacing_mergetree2 values(1,'newname',25,'BJ',3),
(1,'wanger',26,'BJ',2),
(1,'mazi',26,'KM',2),
(1,'mazi',26,'KM',1),
(1,'oldname',25,'BJ',1);

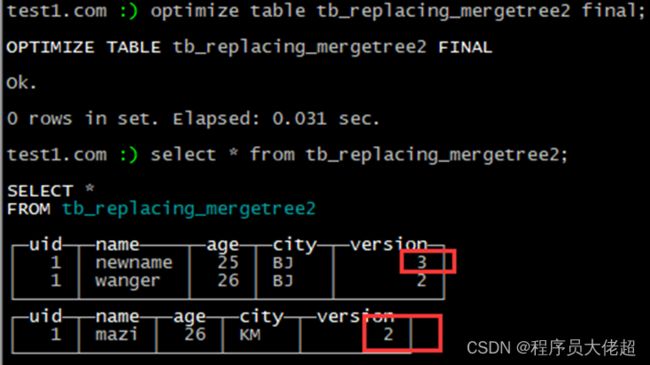
合并后
optimize table tb_replacing_mergetree2 final;
可以看到,分区内指定的version字段最大的值被保留。
后续将继续更新该系列,大佬超手摸手带你学ClickHouse,敬请关注!!!
觉得有帮助点个赞吧!!!
原创不易,转载请注明出处。
微信扫一扫下方二维码即可关注我的公众号
