弱监督学习系列:Inter-Image Communication for Weakly Supervised Localization
原文链接 https://arxiv.org/pdf/2008.05096.pdf
https://arxiv.org/pdf/2008.05096.pdf
代码链接(ECCV2020) Inter-Image Communication for Weakly Supervised Localization - GitHub - xiaomengyc/I2C: (ECCV2020) Inter-Image Communication for Weakly Supervised Localization https://github.com/xiaomengyc/I2C
https://github.com/xiaomengyc/I2C
目录
一、文章主要想解决的问题:
二、基本思路:
三、解决方案:
四:实验:
四、本文优劣:
一、文章主要想解决的问题:
弱监督目标定位(WSOL,weakly supervised object localization)中的痛点问题:利用分类网络生成的定位热度图(localization maps) 总是倾向于关注最具判别性的区域,而不能覆盖整个目标物体区域。
二、基本思路:
对目标物体区域的像素特征进行限制,强制让同一个物体中各个位置的特征表达更加相似(欧式空间),这样就可以让他们在定位图中都突出。
三、解决方案:
3.1 提出两个一致性限制:
Stochastic consistency :分类网络训练过程中,同一个 batch 中,让同一类目标激活最大区域的像素特征尽量接近(欧式空间)。【同一类目标可能每次最大激活的区域不同,如图 1(b) 所示,有些时候鸟头最具判别性,有时候鸟翅膀最具判别性,这样一定程度能够拉平物体各个不同区域的特征表达】
Global consistency:同一类物体在整个数据集中设置一个特征中心,强制让同一类目标区域像素的特征靠近特征中心 【这样也一定程度上让目标物体所有部位的特征更加接近,从而缓解只激活最具判别性区域的问题】
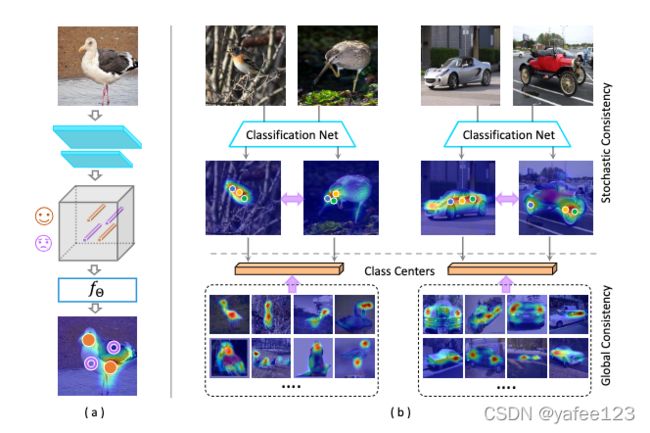 图 1
图 1
3.2 模型结构与工作流
 图 2 模型架构
图 2 模型架构
模型训练过程如图 2 所示,当同一类别图片输入分类网络,
1)获取backbone 的特征图 F 以及通过 CAM 获得定位热度图 M;
2)根据定位热度图 M 上激活值最高的像素区域,从 F 中获得这些像素的特征向量 V;
3)根据 SC loss 限制同类别特征向量的距离,同时最小化平均向量 a 与类别中心向量 w 的距离。4)每个 batch step 之后,利用 momentum 的方式更新类别中心向量。
模型推理 (与原始的 CAM 论文后处理方法相同):
1)利用 CAM 提取分类网络的定位热度图;
2)二值化热度图;
3)取联通区域后取最大外接矩形。
四:实验:
数据集还是 ILSVRC 和 CUB-200,首先在不同backbone 中对比了baseline CAM 和一些 SOTA 方法(HaS, ACoL,CutMix,SPG,ADL 等),在 Loc Err (Top-1, Top-5 和 GT-know)上均表现除了不错的效果。
然后进行 ablation study,这个部分比较有意思,回答了以下几个问题:
1. 对比度对模型定位性能的影响
2. 设计了子实验对比,baseline ,baseline + SC 以及 baseline + SC + GC的性能。比较有趣的是没有对比 baseline + GC 的效果,盲猜是效果不怎么好。
3. 部分超参数对模型性能的影响
其实上面除了第 2 项,1 & 3 都是调参过程,有点充字数的嫌疑 :)。
四、本文优劣:
优:
1) 文章结构清晰,行文很漂亮,写法上确实可以借鉴。
2)整个 motivation 与方法设计make sense。
不足:
强行让物体的不同部位的特征接近其实有点粗糙,会不会造成类内散度大的问题?是否可以不强制要求他们相似,但是建立他们之间的联系,让他们共同表达同一个物体?
这个缺点估计作者也预估到了,所以他们在intro中介绍了两个 observations:
1)卷积操作保持了输入和输出特征图的相对位置(这里为以下操作提供合理性:根据定位特征图M 中最大激活区域位置,从 F 中抽取特征向量表达)
2)同一个类别的特征倾向于聚为同一类,相似的特征输入将产生相似的输出,因此要让统一物体中所有的部分特征尽量相似。
但是,类内的散度确实还是一个没有解决的问题,后面可能可以基于这个问题进行优化。
--
以上为个人见解,如有问题,欢迎交流讨论。